二十三 Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
用命令创建自动爬虫文件
创建爬虫文件是根据scrapy的母版来创建爬虫文件的
scrapy genspider -l 查看scrapy创建爬虫文件可用的母版
Available templates:母版说明
basic 创建基础爬虫文件
crawl 创建自动爬虫文件
csvfeed 创建爬取csv数据爬虫文件
xmlfeed 创建爬取xml数据爬虫文件
创建一个基础母版爬虫,其他同理
scrapy genspider -t 母版名称 爬虫文件名称 要爬取的域名 创建一个基础母版爬虫,其他同理
如:scrapy genspider -t crawl lagou www.lagou.com
第一步,配置items.py接收数据字段
default_output_processor = TakeFirst()默认利用ItemLoader类,加载items容器类填充数据,是列表类型,可以通过TakeFirst()方法,获取到列表里的内容
input_processor = MapCompose(预处理函数)设置数据字段的预处理函数,可以是多个函数

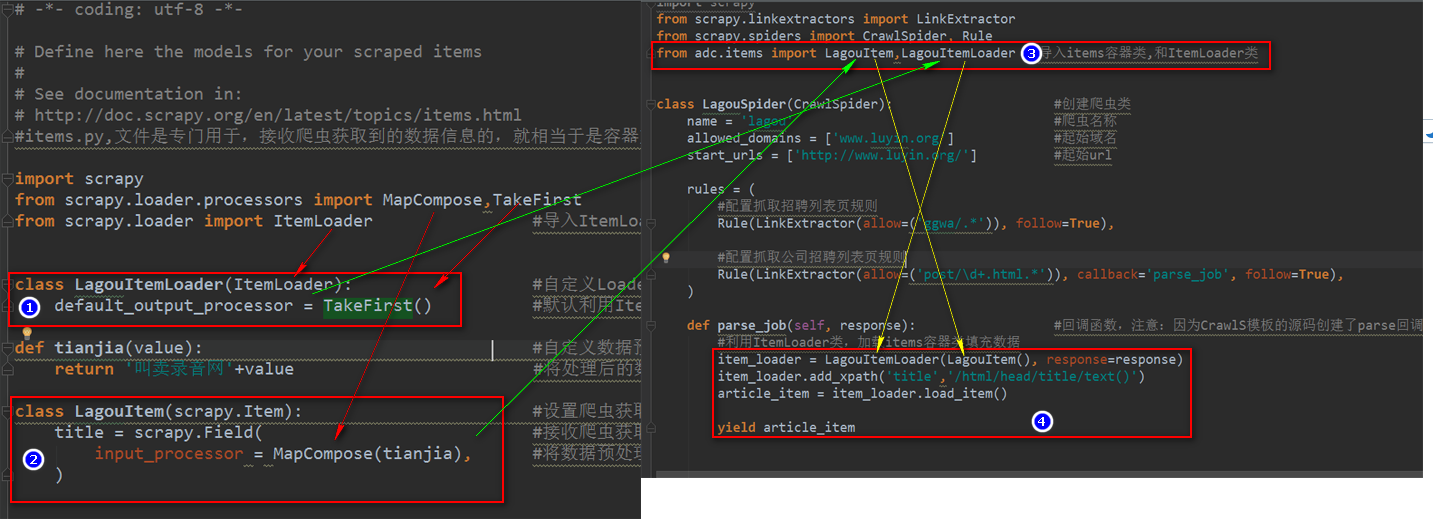
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
#items.py,文件是专门用于,接收爬虫获取到的数据信息的,就相当于是容器文件 import scrapy
from scrapy.loader.processors import MapCompose,TakeFirst
from scrapy.loader import ItemLoader #导入ItemLoader类也就加载items容器类填充数据 class LagouItemLoader(ItemLoader): #自定义Loader继承ItemLoader类,在爬虫页面调用这个类填充数据到Item类
default_output_processor = TakeFirst() #默认利用ItemLoader类,加载items容器类填充数据,是列表类型,可以通过TakeFirst()方法,获取到列表里的内容 def tianjia(value): #自定义数据预处理函数
return '叫卖录音网'+value #将处理后的数据返给Item class LagouItem(scrapy.Item): #设置爬虫获取到的信息容器类
title = scrapy.Field( #接收爬虫获取到的title信息
input_processor = MapCompose(tianjia), #将数据预处理函数名称传入MapCompose方法里处理,数据预处理函数的形式参数value会自动接收字段title
)
第二步,编写自动爬虫与利用ItemLoader类加载items容器类填充数据
自动爬虫
Rule()设置爬虫规则
参数:
LinkExtractor()设置url规则
callback='回调函数名称'
follow=True 表示在抓取页面继续深入
LinkExtractor()对爬虫获取到的url做规则判断处理
参数:
allow= r'jobs/' 是一个正则表达式,表示符合这个url格式的,才提取
deny= r'jobs/' 是一个正则表达式,表示符合这个url格式的,不提取抛弃掉,与allow相反
allow_domains= www.lagou.com/ 表示这个域名下的连接才提取
deny_domains= www.lagou.com/ 表示这个域名下的连接不提取抛弃
restrict_xpaths= xpath表达式 表示可以用xpath表达式限定爬虫只提取一个页面指定区域的URL
restrict_css= css选择器,表示可以用css选择器限定爬虫只提取一个页面指定区域的URL
tags= 'a' 表示爬虫通过a标签去寻找url,默认已经设置,默认即可
attrs= 'href' 表示获取到a标签的href属性,默认已经设置,默认即可
利用自定义Loader类继承ItemLoader类,加载items容器类填充数据
ItemLoader()实例化一个ItemLoader对象来加载items容器类,填充数据,如果是自定义Loader继承的ItemLoader同样的用法
参数:
第一个参数:要填充数据的items容器类注意加上括号,
第二个参数:response
ItemLoader对象下的方法:
add_xpath('字段名称','xpath表达式')方法,用xpath表达式获取数据填充到指定字段
add_css('字段名称','css选择器')方法,用css选择器获取数据填充到指定字段
add_value('字段名称',字符串内容)方法,将指定字符串数据填充到指定字段
load_item()方法无参,将所有数据生成,load_item()方法被yield后数据被填充items容器指定类的各个字段
爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from adc.items import LagouItem,LagouItemLoader #导入items容器类,和ItemLoader类 class LagouSpider(CrawlSpider): #创建爬虫类
name = 'lagou' #爬虫名称
allowed_domains = ['www.luyin.org'] #起始域名
start_urls = ['http://www.luyin.org/'] #起始url rules = (
#配置抓取列表页规则
Rule(LinkExtractor(allow=('ggwa/.*')), follow=True), #配置抓取内容页规则
Rule(LinkExtractor(allow=('post/\d+.html.*')), callback='parse_job', follow=True),
) def parse_job(self, response): #回调函数,注意:因为CrawlS模板的源码创建了parse回调函数,所以切记我们不能创建parse名称的函数
#利用ItemLoader类,加载items容器类填充数据
item_loader = LagouItemLoader(LagouItem(), response=response)
item_loader.add_xpath('title','/html/head/title/text()')
article_item = item_loader.load_item() yield article_item
items.py文件与爬虫文件的原理图
二十三 Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制的更多相关文章
- 第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制 用命令创建自动爬虫文件 创建爬虫文件是根据scrap ...
- 第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- 第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码 scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开 ...
- 五十 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- Python分布式爬虫打造搜索引擎完整版-基于Scrapy、Redis、elasticsearch和django打造一个完整的搜索引擎网站
Python分布式爬虫打造搜索引擎 基于Scrapy.Redis.elasticsearch和django打造一个完整的搜索引擎网站 https://github.com/mtianyan/Artic ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.e ...
随机推荐
- 闪回事务(Flashback Transaction)
到目前为止,介绍的所有功能均不会直接将数据恢复为“以前”的样子.闪回查询只是查看,闪回数据归档只是延伸了闪回查询的时间窗口,闪回事务查询虽然提供了撤销SQL,但是否执行及如何执行还需要管理员进一步手动 ...
- 20165324《Java程序设计》第五周
学号 2016-2017-2 <Java程序设计>第五周学习总结 教材学习内容总结 第七章:内部类与异常类 内部类:java支持在类中定义另一个类,这个类为内部类,包含内部类的类称为外嵌类 ...
- HTML5笔记——formData
注:formData中的数据在控制台上的console里面是打印不出来的,只能在控制台的network里面查看到具体的发送数据和发送选项 文章出处:梦想天空 XMLHttpRequest Level ...
- debian flam3 依赖文件
https://packages.debian.org/stable/graphics/flam3 package names descriptions source package ...
- Java 写文件实现换行
第一种: 写入的内容中利用\r\n进行换行 File file = new File("D:/text"); try { if(!file.exists()) file.creat ...
- idea打jar包-MapReduce作业提交到hadoop集群执行
https://blog.csdn.net/jiaotangX/article/details/78661862 https://liushilang.iteye.com/blog/2093173
- 斐讯面试记录—阻塞Socket和非阻塞Socket
文章出自:http://blog.csdn.net/VCSockets/ 1.TCP中的阻塞Socket和非阻塞Socket 阻塞与非阻塞是对一个文件描述符指定的文件或设备的两种工作方式. 阻塞的意思 ...
- Winter-2-STL-A Argus 解题报告及测试数据
Time Limit:2000MS Memory Limit:65536KB Description A data stream is a real-time, continuous, ord ...
- JVM基本配置与调优
JVM基本配置与调优 JVM调优,一般都是针对堆内存配置调优. 如图:堆内存分新生代和老年代,新生代又划分为eden区.from区.to区. 一.区域释义 JVM内存模型,堆内存代划分为新生代和老年代 ...
- 谷歌技术"三宝"之BigTable(转)
原文地址: http://blog.csdn.net/opennaive/article/details/7532589 2006年的OSDI有两篇google的论文,分别是BigTable和Ch ...