yolov3源码分析keras(二)损失函数计算
一、前言
损失函数计算主要分析两部分一部分是yolo_head函数的分析另一部分为ignore_mask的生成的分析。
二、重要细节分析
2.1损失函数计算具体代码及部分分析
def yolo_loss(args, anchors, num_classes, ignore_thresh=.5, print_loss=False):
#args前三个元素为yolov3输出的预测值,后三个维度为保存的label 值
'''Return yolo_loss tensor Parameters
----------
yolo_outputs: list of tensor, the output of yolo_body or tiny_yolo_body
y_true: list of array, the output of preprocess_true_boxes
anchors: array, shape=(N, 2), wh
num_classes: integer
ignore_thresh: float, the iou threshold whether to ignore object confidence loss Returns
-------
loss: tensor, shape=(1,) '''
num_layers = len(anchors)//3 # default setting
yolo_outputs = args[:num_layers]
y_true = args[num_layers:]
anchor_mask = [[6,7,8], [3,4,5], [0,1,2]] if num_layers==3 else [[3,4,5], [1,2,3]]
input_shape = K.cast(K.shape(yolo_outputs[0])[1:3] * 32, K.dtype(y_true[0])) #13*32=416 input_shape--->[416,416]
grid_shapes = [K.cast(K.shape(yolo_outputs[l])[1:3], K.dtype(y_true[0])) for l in range(num_layers)]#(13,13),(26,26),(52,52)
loss = 0
m = K.shape(yolo_outputs[0])[0] # batch size, tensor
mf = K.cast(m, K.dtype(yolo_outputs[0])) #mf为batchsize大小
#逐层计算损失
for l in range(num_layers):
object_mask = y_true[l][..., 4:5] # 取出置信度
true_class_probs = y_true[l][..., 5:]#取出类别信息
#yolo_head讲预测的偏移量转化为真实值,这里的真实值是用来计算iou,并不是来计算loss的,loss使用偏差来计算的
grid, raw_pred, pred_xy, pred_wh = yolo_head(yolo_outputs[l],
anchors[anchor_mask[l]], num_classes, input_shape, calc_loss=True) #anchor_mask[0]=[6,7,8]
pred_box = K.concatenate([pred_xy, pred_wh]) #anchors[anchor_mask[l]]=array([[ 116., 90.],
# [ 156., 198.],
# [ 373., 326.]])
# Darknet raw box to calculate loss.
raw_true_xy = y_true[l][..., :2]*grid_shapes[l][::-1] - grid #根据公式将boxes中心点x,y的真实值转换为偏移量
raw_true_wh = K.log(y_true[l][..., 2:4] / anchors[anchor_mask[l]] * input_shape[::-1])#计算宽高的偏移量
raw_true_wh = K.switch(object_mask, raw_true_wh, K.zeros_like(raw_true_wh)) # avoid log(0)=-inf(后边有详细解释为什么这么操作)
box_loss_scale = 2 - y_true[l][...,2:3]*y_true[l][...,3:4] #(2-box_ares)避免大框的误差对loss 比小框误差对loss影响大 # Find ignore mask, iterate over each of batch.
ignore_mask = tf.TensorArray(K.dtype(y_true[0]), size=1, dynamic_size=True)#定义一个size可变的张量来存储不含有目标的预测框的信息
object_mask_bool = K.cast(object_mask, 'bool')#映射成bool类型 1=true 0=false
def loop_body(b, ignore_mask):
true_box = tf.boolean_mask(y_true[l][b,...,0:4], object_mask_bool[b,...,0]) #剔除为0的行
iou = box_iou(pred_box[b], true_box) #一张图片预测出的所有boxes与所有的ground truth boxes计算iou 计算过程与生成label类似利用了广播特性这里不详细描述
best_iou = K.max(iou, axis=-1)#找出最大iou
ignore_mask = ignore_mask.write(b, K.cast(best_iou<ignore_thresh, K.dtype(true_box)))#当iou小于阈值时记录,即认为这个预测框不包含物体
return b+1, ignore_mask
_, ignore_mask = K.control_flow_ops.while_loop(lambda b,*args: b<m, loop_body, [0, ignore_mask])#传入loop_body函数初值为b=0,ignore_mask
ignore_mask = ignore_mask.stack()
ignore_mask = K.expand_dims(ignore_mask, -1) #扩展维度用来后续计算loss # K.binary_crossentropy is helpful to avoid exp overflow.
#仅计算包含物体框的x,y,w,h的损失
xy_loss = object_mask * box_loss_scale * K.binary_crossentropy(raw_true_xy, raw_pred[...,0:2], from_logits=True)
wh_loss = object_mask * box_loss_scale * 0.5 * K.square(raw_true_wh-raw_pred[...,2:4])
#置信度损失既包含有物体的损失 也包含无物体的置信度损失
confidence_loss = object_mask * K.binary_crossentropy(object_mask, raw_pred[...,4:5], from_logits=True)+ \
(1-object_mask) * K.binary_crossentropy(object_mask, raw_pred[...,4:5], from_logits=True) * ignore_mask
#分类损失只计算包含物体的损失
class_loss = object_mask * K.binary_crossentropy(true_class_probs, raw_pred[...,5:], from_logits=True)
#取平均值
xy_loss = K.sum(xy_loss) / mf
wh_loss = K.sum(wh_loss) / mf
confidence_loss = K.sum(confidence_loss) / mf
class_loss = K.sum(class_loss) / mf
loss += xy_loss + wh_loss + confidence_loss + class_loss
if print_loss:
loss = tf.Print(loss, [loss, xy_loss, wh_loss, confidence_loss, class_loss, K.sum(ignore_mask)], message='loss: ')
return loss
2.2 yolo_head代码分析
yolo_head主要作用是将预测出的数据转换为真实值。代码如下:
def yolo_head(feats, anchors, num_classes, input_shape, calc_loss=False):
"""Convert final layer features to bounding box parameters."""
num_anchors = len(anchors) # num_anchors = 3
# Reshape to batch, height, width, num_anchors, box_params.
anchors_tensor = K.reshape(K.constant(anchors), [1, 1, 1, num_anchors, 2])# [[[[[30., 61.]
grid_shape = K.shape(feats)[1:3] # height, width [62., 45.]
grid_y = K.tile(K.reshape(K.arange(0, stop=grid_shape[0]), [-1, 1, 1, 1]), # [59., 119.]]]]]
[1, grid_shape[1], 1, 1])
grid_x = K.tile(K.reshape(K.arange(0, stop=grid_shape[1]), [1, -1, 1, 1]),
[grid_shape[0], 1, 1, 1])
grid = K.concatenate([grid_x, grid_y])
grid = K.cast(grid, K.dtype(feats)) feats = K.reshape(
feats, [-1, grid_shape[0], grid_shape[1], num_anchors, num_classes + 5])#featuremap [N,13,13,3(20+5)]-->[N,13,13,3,(20+5)] # Adjust preditions to each spatial grid point and anchor size.
box_xy = (K.sigmoid(feats[..., :2]) + grid) / K.cast(grid_shape[::-1], K.dtype(feats))#grid 为偏移 ,将x,y相对于featuremap尺寸进行了归一化
box_wh = K.exp(feats[..., 2:4]) * anchors_tensor / K.cast(input_shape[::-1], K.dtype(feats))#real box_wh
box_confidence = K.sigmoid(feats[..., 4:5])
box_class_probs = K.sigmoid(feats[..., 5:])
if calc_loss == True:
return grid, feats, box_xy, box_wh
return box_xy, box_wh, box_confidence, box_class_probs
box真实值与预测值转换公式及示意图:
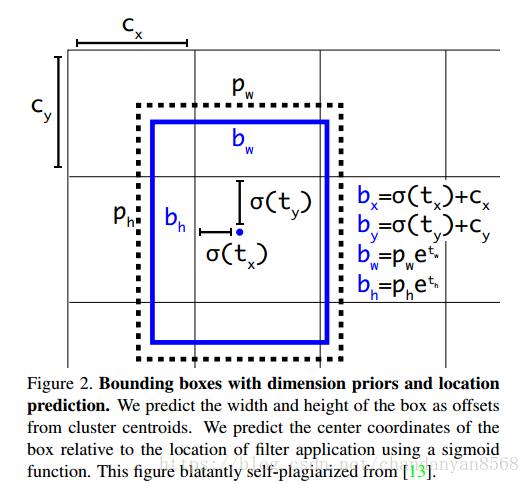
转换代码如下:
box_xy = (K.sigmoid(feats[..., :2]) + grid) / K.cast(grid_shape[::-1], K.dtype(feats))#grid 为偏移
box_wh = K.exp(feats[..., 2:4]) * anchors_tensor / K.cast(input_shape[::-1], K.dtype(feats))#real box_wh
对于初学者这个图也有一定的迷惑性质,可以把上图的每个网格想象成feature map上的一个点,则第一个像素对应的偏移为(0,0),第一行第二个偏移为(1,0)以此类推。图中标注的点偏移量为(1,1)。
yolo_head中转换为真实值时gride偏移相对于特征图尺寸做了归一化。
代码对于预测出的值进行了Sigmoid操作目的是为了让坐标值在0-1之间。
假设蓝色点为13*13的feature map 中的cell预测的中心点坐标为x,y,取sigmoid后其坐标为 (0.3, 0.5),则真实框在这个尺度上的中心点坐标值为(0.3+1, 0.5+1),映射到原图尺度为(1.3,1,5)*scale。
在这里scale=32。
其中grid为相对于feature map左上角的偏移量。以13*13的feature map为例来说明box 中心点x,y以及宽高w,h的计算过程。
K.arange(0, stop=grid_shape[0]) ---->[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
K.reshape(K.arange(0, stop=grid_shape[0]), [-1, 1, 1, 1]) ----> -1表示为变化的维度,放在第一维度表示第一位维是变化的则 shape=[13,1,1,1] 一共包含13行值分别为0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12。
具体形式如下:[ [ [ [ 0 ] ] ]
..........
[ [ [12 ] ] ] ]
grid_y = K.tile(K.reshape(K.arange(0, stop=grid_shape[0]), [-1, 1, 1, 1]), [1, grid_shape[1], 1, 1]) ----> 表示在第二个维度重复13次 shape=[13,13,1,1]
具体形式如下:[ [ [ [ 0 ] ]
...........
[ [ 0 ] ] 重复13次
[ [ [ 1 ] ]
............
[ [ 1 ] ] 重复13次
.............
.............
[ [ [ 12 ] ]
...............
[ [12 ] ] ] ]
同理可得到grid_x的具体形式:[ [ [ [ 0 ] ] shape=[13,13,1,1]
[ [ 1 ] ]
............
[ [12 ] ] ]
.............
.............
[ [ [ [ 0 ] ] 蓝色部分共重复了13次
[ [ 1 ] ]
............
[ [ 12 ] ] ]
grid最终形式为 [ [ [ [ 0 0 ] ] shape=[13,13,1,2]
[ [ 1 0 ] ]
................
[ [12 1 ] ] ]
[ [ [ 0 1 ] ]
[ [ 1 1 ] ]
................
[ [12 1] ] ]
..................
..................
[ [ [ 0 12 ] ]
[ [ 1 12 ] ]
................
[ [12 12] ] ]
三、有关损失函数的一些注意事项
ps: 损失函数计算的为偏移量的损失,作者将真实的标签宽高转换为对应特征图尺寸上宽高的偏移量,然后与预测出的宽高偏移量计算误差。并不是将预测出的偏移转换为真实值和标签计算误差。 即计算的为偏移量的误差不是真实值之间的误差。同理中心点误差计算也是特征图上的中心点坐标。
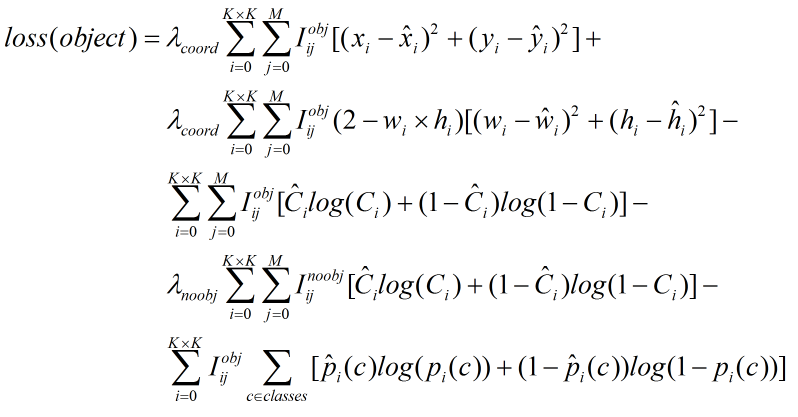
实际公式中xi,yi尖,为网络预测出的中心点值计算sigmoid之后的值。原版darknet计算中心点损失使用的是方差。keras作者使用的是交叉熵,这点有所不同。
yolov3源码分析keras(二)损失函数计算的更多相关文章
- yolov3源码分析keras(一)数据的处理
一.前言 本次分析的源码为大佬复现的keras版本,上一波地址:https://github.com/qqwweee/keras-yolo3 初步打算重点分析两部分,第一部分为数据,即分析图像如何做等 ...
- Zepto源码分析(二)奇淫技巧总结
Zepto源码分析(一)核心代码分析 Zepto源码分析(二)奇淫技巧总结 目录 * 前言 * 短路操作符 * 参数重载(参数个数重载) * 参数重载(参数类型重载) * CSS操作 * 获取属性值的 ...
- Unity时钟定时器插件——Vision Timer源码分析之二
Unity时钟定时器插件——Vision Timer源码分析之二 By D.S.Qiu 尊重他人的劳动,支持原创,转载请注明出处:http.dsqiu.iteye.com 前面的已经介绍了vp_T ...
- spark 源码分析之二十一 -- Task的执行流程
引言 在上两篇文章 spark 源码分析之十九 -- DAG的生成和Stage的划分 和 spark 源码分析之二十 -- Stage的提交 中剖析了Spark的DAG的生成,Stage的划分以及St ...
- DataTable源码分析(二)
DataTable源码分析(二) ===================== DataTable函数分析 ---------------- DataTable作为整个插件的入口,完成了整个表格的数据初 ...
- 一个普通的 Zepto 源码分析(二) - ajax 模块
一个普通的 Zepto 源码分析(二) - ajax 模块 普通的路人,普通地瞧.分析时使用的是目前最新 1.2.0 版本. Zepto 可以由许多模块组成,默认包含的模块有 zepto 核心模块,以 ...
- Koa源码分析(二) -- co的实现
Abstract 本系列是关于Koa框架的文章,目前关注版本是Koa v1.主要分为以下几个方面: Koa源码分析(一) -- generator Koa源码分析(二) -- co的实现 Koa源码分 ...
- Tomcat源码分析(二)------ 一次完整请求的里里外外
Tomcat源码分析(二)------ 一次完整请求的里里外外 前几天分析了一下Tomcat的架构和启动过程,今天开始研究它的运转机制.Tomcat最本质就是个能运行JSP/Servlet的Web ...
- Django之DRF源码分析(二)---数据校验部分
Django之DRF源码分析(二)---数据校验部分 is_valid() 源码 def is_valid(self, raise_exception=False): assert not hasat ...
随机推荐
- 关于select Count()的使用和性能问题
比如Count(*) FROM E_Table WHERE [date] > '2008-1-1' AND istrue = 0 由于操作的数据比较大(400万以上),所以使用了两个数据库,一个 ...
- query使用
1.row_array():返回查询结果中的第一条数据 include APP_PATH . "../mysql.class.php";$db = new mysql();$sql ...
- AJAX和DHTML
DHTML: (动态的html)本身不是一门新语言,而是一门新技术,包含以下 html . css . dom . js AJAX : 也是一门新技术包含 html . css. dom ...
- 斐波那契数列—java实现
最近在面试的时候被问到了斐波那契数列,而且有不同的实现方式,就在这里记录一下. 定义 斐波那契数列指的是这样一个数列 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, ...
- ThinkPhp数据缓存技术
1.缓存初始化 在 ThinkPHP 中,有一个专门处理缓存的类:Cache.class.php(在Thinkphp/Library/Think/cache.class.php,其他的各种缓存类也在这 ...
- 回归(regression)、梯度下降(gradient descent)
本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: 上次写过一篇 ...
- JavaScript语言精粹 笔记02 函数
函数函数对象函数字面量调用参数返回异常给类型增加方法递归作用域闭包回调模块级联套用记忆 函数 1 函数对象 在JS中函数就是对象.对象是“名/值”对的集合并拥有一个连接到原型对象的隐藏连接.对象字 ...
- 深入理解java虚拟机(十二) Java 语法糖背后的真相
语法糖(Syntactic Sugar),也叫糖衣语法,是英国计算机科学家彼得·约翰·兰达(Peter J. Landin)发明的一个术语.指的是,在计算机语言中添加某种语法,这些语法糖虽然不会对语言 ...
- 从swing分发线程机制上理解多线程[转载]
本文参考了 http://space.itpub.net/13685345/viewspace-374940,原文作者:javagui 在多线程编程当中,总会提到图形编程,比如java中的swing, ...
- Domino 迁移到Exchange 之 Domino Admin 安装!
双击Setup 安装: