Pytorch学习笔记(一)——简介
一、Tensor
Tensor是Pytorch中重要的数据结构,可以认为是一个高维数组。Tensor可以是一个标量、一维数组(向量)、二维数组(矩阵)或者高维数组等。Tensor和numpy的ndarrays相似。
import torch as t
构建矩阵:x = t.Tensor(m, n)
注意这种情况下只分配了空间,并没有初始化。
使用[0,1]均匀分布随机初始化矩阵:x = t.rand(m, n)
查看x的形状:x.size()
加法:
(1)x + y
(2)t.add(x, y)
(3)t.add(x, y, out = res)
(4)y.add(x) #不改变y的内容
(5)y.add_(x) #改变y的内容
注意,函数名后面带下划线_的函数会修改Tensor本身,而x.add(y)等则会返回一个新的Tensor,而x不变。
Tensor可以进行数学运算、线性代数、选择、切片等。而且Tensor与numpy的数组间互操作十分方便。对于Tensor不支持的操作可以先转为numpy处理,再转为Tensor。
a = t.ones(5)
b = a.numpy() # Tensor -> Numpy a = np.ones(5)
b = t.from_numpy(a) # Numpy -> Tensor
Tensor和numpy的对象是共享内存的,如果其中一个改变,那么另一个也会随之改变。
Tensor可以通过.cuda方法转为GPU的Tensor。GPU加速:
if t.cuda.is_available():
x = x.cuda()
y = y.cuda()
x + y
二、Autograd:自动微分
Pytorch的Autograd模块实现了求导功能,在Tensor上的所有操作,Autograd都能自动为它们提供微分。
autograd.Variable是Autograd的核心类,简单封装了Tensor,并几乎支持所有的Tensor操作。当Tensor被封装为Variable后,可以通过调用.backward实现反向传播,自动计算所有的梯度。
Variable包括三个属性:
(1)data:保存Variable包含的Tensor;
(2)grad:保存data对应的梯度,grad也是个Variable;
(3)grad_fn:指向一个Function对象,该Function用于反向传播计算输入的梯度。
from torch.autograd import Variable
x = Variable(t.ones(2, 2), requires_grad = True)
y = x.sum()
print(y.grad_fn)
y.backward()
print(x.grad)
y.backward()
print(x.grad)
注意,grad在反向传播中是累加的,也就是说每次运行反向传播时梯度都会累加之前的梯度,因此需要反向传播之前要把梯度清零。
x.grad.data.zero_() # inplace操作,把x的data对应的梯度值清零 Variable和Tensor的转换:
x = Variable(t.ones(4, 5))
y = t.cos(x)
x_tensor_cos = t.cos(x.data) # Variable x的data的cosine对应的Tensor
三、神经网络
torch.nn是专门为神经网络设计的模块化接口。nn.Module可以看做是一个网络的封装,包括网络各层的定义以及forward方法,调用forward(input)方法,可返回前向传播的结果。
LeNet网络结构如下图:
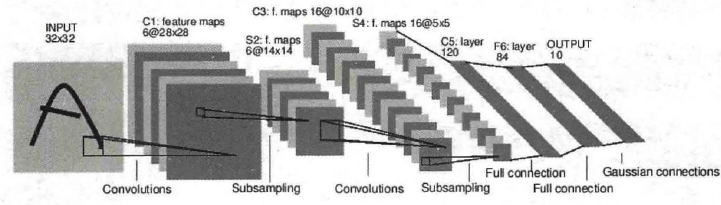
定义网络时,要继承nn.Module,并实现它的forward方法,把网络中具有可学习参数的层放在构造函数__init__中。如果某层不具有可学习的参数,则既可以放在构造函数中,也可以不放。
import torch.nn as nn
import torch.nn.functional as F class Net(nn.Module):
def __init__(self):
# nn.Module子类的函数必须在构造函数中执行父类的构造函数
# 下式等价于nn.Module.__init__(self)
super(Net, self).__init__()
# '1'表示输入图像为单通道,'6'表示输出通道数
# '5'表示卷积核大小为5*5
self.conv1 = nn.Conv2d(1, 6, 5)
# 卷积层
self.conv2 = nn.Conv2d(6, 16, 5)
# 仿射层/全连接层,y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10) def forward(self, x):
# 卷积 -> 激活 -> 池化
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
# reshape, '-1'表示自适应
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x) return x net = Net()
print(net)
运行结果:
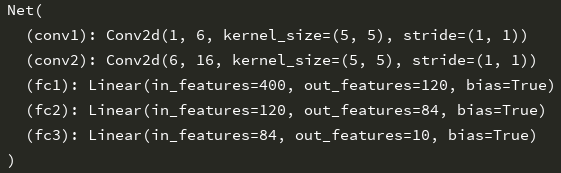
只要在nn.Module的子类中定义了forward函数,backward函数就会被自动实现。网络的可学习参数通过net.parameters()返回,而net.named_parameters可同时返回可学习的参数及名称。
params = list(net.parameters())
print(len(params)) for name, parameters in net.named_parameters():
print(name, ':', parameters.size())
运行结果:
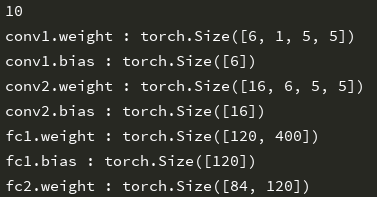
注意,输入和输出都必须是Variable。
torch.nn只支持mini-batches,不支持一次只输入一个样本,也就是说一次必须是一个batch。如果只想输入一个样本,那么要用input.unsqueeze(0)将batch_size设为1。
损失函数:
(1)nn.MSELoss用于计算均方误差
(2)nn.CrossEntropyLoss用于计算交叉熵损失
output = net(input)
target = Variable(t.arange(0, 10))
target = target.float()
criterion = nn.MSELoss()
loss = criterion(output, target)
在反向传播计算所有参数的梯度后,还需要使用优化方法更新网络的权重和参数,如SGD:
weight = weight - lr * gradient
手工实现如下:
lr = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * lr)
torch.optim中实现了深度学习中的绝大多数优化方法,如RMSProp、Adam、SGD等。 # 新建一个优化器,指定要调整的参数和学习率
optimizer = optim.SGD(net.parameters(), lr = 0.01) # 训练过程中,先梯度清零
optimizer.zero_grad() # 计算损失
output = net(input)
loss = criterion(output, target) # 反向传播
loss.backward()
optimizer.step()
torchvision实现了常用的图像数据加载功能。
四、CIFAR-10 分类
import torch.nn as nn
import torch as t
from torch.autograd import Variable
import torch.nn.functional as F
import torch.optim as optim
import torchvision as tv
import torchvision.transforms as transforms
from torchvision.transforms import ToPILImage show = ToPILImage() # 把Tensor转换成Image,方便可视化 # 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转为Tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5,0.5, 0.5)),]) # 训练集
trainset = tv.datasets.CIFAR10(root = 'F:/PycharmProjects/', train = True, download =
True, transform = transform)
trainloader = t.utils.data.DataLoader(trainset, batch_size = 4, shuffle = True, num_workers = 2) # 测试集
testset = tv.datasets.CIFAR10(root = 'F:/PycharmProjects/', train = False, download =
True, transform = transform)
testloader = t.utils.data.DataLoader(testset, batch_size = 4, shuffle = False, num_workers = 2) classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck') (data, label) = trainset[100]
print(classes[label]) show((data + 1) / 2).resize(100, 100) # 将dataset返回的每一条数据样本拼接成一个batch
dataiter = iter(trainloader)
images, labels = dataiter.next()
print(' '.join('%11s' % classes[labels[j]] for j in range(4)))
show(tv.utils.make_grid((images + 1) / 2)).resize((400, 100)) class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10) def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x net = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr = 0.001, momentum = 0.9) for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
inputs, labels = Variable(inputs), Variable(labels) optimizer.zero_grad() outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
# 参数更新
optimizer.step() running_loss += loss.data[0]
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training') dataiter = iter(testloader)
images, labels = dataiter.next()
outputs = net(Variable(images))
_, predicted = t.max(outputs.data, 1)
print('predicted result', ' '.join('%5s' % classes[predicted[j]] for j in range(4))) correct = 0
total = 0
for data in testloader:
images, labels = data
outputs = net(Variable(images))
_, predicted = t.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted ==labels).sum print('The accuracy is: %d %%' % (100 * correct / total)) #GPU加速操作:
if t.cuda.is_available():
net.cuda()
images = images.cuda()
labels = labels.cuda()
output = net(Variable(images))
loss = criterion(output, Variable(labels))
Pytorch学习笔记(一)——简介的更多相关文章
- Linux内核学习笔记-1.简介和入门
原创文章,转载请注明:Linux内核学习笔记-1.简介和入门 By Lucio.Yang 部分内容来自:Linux Kernel Development(Third Edition),Robert L ...
- React学习笔记 - JSX简介
React Learn Note 2 React学习笔记(二) 标签(空格分隔): React JavaScript 一.JSX简介 像const element = <h1>Hello ...
- CUBRID学习笔记 1 简介 cubrid教程
CUBRID 是一个全面开源,且完全免费的关系数据库管理系统.CUBRID为高效执行Web应用进行了高度优化,特别是需要处理大数据量和高并发请求的复杂商务服务.通过提供独特的最优化特性,CUBRID可 ...
- [PyTorch 学习笔记] 1.1 PyTorch 简介与安装
PyTorch 的诞生 2017 年 1 月,FAIR(Facebook AI Research)发布了 PyTorch.PyTorch 是在 Torch 基础上用 python 语言重新打造的一款深 ...
- shiro学习笔记_0100_shiro简介
前言:第一次知道shiro是2016年夏天,做项目时候我要写springmvc的拦截器,申哥看到后,说这个不安全,就给我捣鼓了shiro,我就看了下,从此认识了shiro.此笔记是根据网上的视频教程记 ...
- Mybatis-Plus 实战完整学习笔记(一)------简介
第一章 简介 1. 什么是MybatisPlus MyBatis-Plus(简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上只 ...
- ElasticSearch学习笔记-01 简介、安装、配置与核心概念
一.简介 ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎.设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便.支持通过HTTP使用JSON进 ...
- python学习笔记1--python简介和第一行代码编写
一.什么是python? python是一种面向对象,解释型语言,它语法简介,容易学习.本节博客就来说说本人学习python的心得体会. 二.python环境安装 目前python版本有python2 ...
- Pytorch学习笔记(二)---- 神经网络搭建
记录如何用Pytorch搭建LeNet-5,大体步骤包括:网络的搭建->前向传播->定义Loss和Optimizer->训练 # -*- coding: utf-8 -*- # Al ...
随机推荐
- TF Boys (TensorFlow Boys ) 养成记(四):TensorFlow 简易 CIFAR10 分类网络
前面基本上把 TensorFlow 的在图像处理上的基础知识介绍完了,下面我们就用 TensorFlow 来搭建一个分类 cifar10 的神经网络. 首先准备数据: cifar10 的数据集共有 6 ...
- MySQL 存储过程 -光标的使用
#四.光标的使用 #声明光标 语法:DECLARE 光标名字 CURSOR FOR sql语句 #打开光标 OPEN 光标名称 #使用光标 FETCH 光标名称 into ... #关闭光标 CLOS ...
- sql返回前N行
场景:返回每个客户最近的3个订单. 假设我们已经有一个POC索引(详情见http://www.cnblogs.com/xiaopotian/p/6821502.html),有两种策略来完成该任务:一种 ...
- ZookeeperGettingStarted
reference url: http://zookeeper.apache.org/doc/trunk/zookeeperStarted.html#sc_FileManagement ZooKee ...
- Android 热修复技术中的CLASS_ISPREVERIFIED问题
一.前言 上一篇博客中,我们通过介绍dex分包原理引出了Android的热补丁技术,而现在我们将解决两个问题. 1. 怎么将修复后的Bug类打包成dex 2. 怎么将外部的dex插入到ClassLoa ...
- Opengl中的GLUT下的回调函数
void glutDisplayFunc(void (*func)(void)); 注册当前窗口的显示回调函数 参数: func:形为void func()的函数,完成具体的绘制操作 这个函数告诉GL ...
- freePCRF免费版体验
[摘要]遍寻网络数昼夜,未得开源PCRF,亦未得有参考价值的PCRF相关文档.所幸觅得免费体验版freePCRF软件.可窥见PCRF设计思路.方法:PCC规则定义.管理策略:遂记录安装.体验心得. f ...
- Jquery ajax的参数格式化
jQuery的ajax会自动将js对象转换为可传递的参数,$.param(jsobj, boolean),但是默认会把对象中数组类型加上[]符号,后台就不怎么好取了 参数boolean为true时不加 ...
- java学习(七)java中抽象类及 接口
抽象类的特点: A:抽象类和抽象方法必须用abstract关键字修饰. B:抽象类中不一定有抽象方法,但是抽象方法的类必须定义为抽象类 c: 抽象类不能被实例化,因为它不是具体的. 抽象类有构造方法, ...
- 20145233《网络对抗》Exp5 MSF基础应用
20145233<网络对抗>Exp5 MSF基础应用 实验问题思考 什么是exploit,payload,encode exploit是发现了的可以利用的安全漏洞或者配置弱点,这类模块存储 ...