【转】利用python的KMeans和PCA包实现聚类算法
转自:https://www.cnblogs.com/yjd_hycf_space/p/7094005.html
题目: 通过给出的驾驶员行为数据(trip.csv),对驾驶员不同时段的驾驶类型进行聚类,聚成普通驾驶类型,激进类型和超冷静型3类 。 利用Python的scikit-learn包中的Kmeans算法进行聚类算法的应用练习。并利用scikit-learn包中的PCA算法来对聚类后的数据进行降维,然后画图展示出聚类效果。通过调节聚类算法的参数,来观察聚类效果的变化,练习调参。
数据介绍: 选取某一个驾驶员的经过处理的数据集trip.csv,将该驾驶人的各个时间段的特征进行聚类。(注:其中的driver 和trip_no 不参与聚类)
字段介绍: driver :驾驶员编号;trip_no:trip编号;v_avg:平均速度;v_var:速度的方差;a_avg:平均加速度;a_var:加速度的方差;r_avg:平均转速;r_var:转速的方差; v_a:速度level为a时的时间占比(同理v_b , v_c , v_d ); a_a:加速度level为a时的时间占比(同理a_b, a_c); r_a:转速level为a时的时间占比( r_b, r_c)
聚类算法要求:
(1)统计各个类别的数目
(2)找出聚类中心
(3)将每条数据聚成的类别(该列命名为jllable )和原始数据集进行合并,形成新的dataframe,命名为new_df ,并输出到本地,命名为new_df.csv。
降维算法要求:
(1)将用于聚类的数据的特征的维度降至2维,并输出降维后的数据,形成一个dataframe名字new_pca
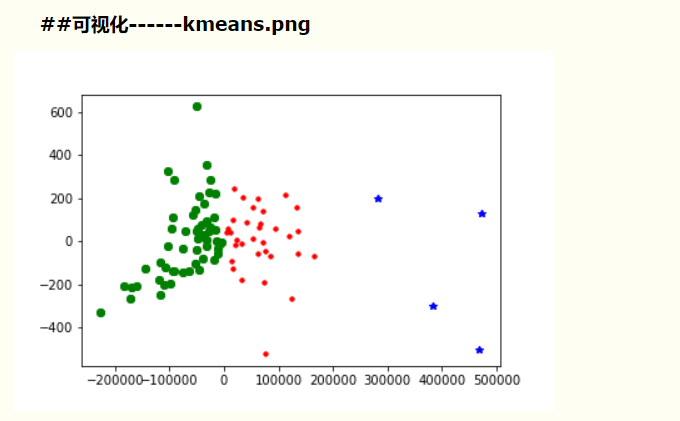
(2)画图来展示聚类效果(可用如下代码):
import matplotlib.pyplot asplt
d = new_pca[new_df['jllable'] == 0]
plt.plot(d[0], d[1], 'r.')
d = new_pca[new_df['jllable'] == 1]
plt.plot(d[0], d[1], 'go')
d = new_pca[new_df['jllable'] == 2]
plt.plot(d[0], d[1], 'b*')
plt.gcf().savefig('D:/workspace/python/Practice/ddsx/kmeans.png')
plt.show()
python实现代码如下:
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt df=pd.read_csv('trip.csv', header=0, encoding='utf-8')
df1=df.ix[:,2:]
kmeans = KMeans(n_clusters=3, random_state=10).fit(df1)
df1['jllable']=kmeans.labels_
df_count_type=df1.groupby('jllable').apply(np.size) ##各个类别的数目
df_count_type
##聚类中心
kmeans.cluster_centers_
##新的dataframe,命名为new_df ,并输出到本地,命名为new_df.csv。
new_df=df1[:]
new_df
new_df.to_csv('new_df.csv') ##将用于聚类的数据的特征的维度降至2维,并输出降维后的数据,形成一个dataframe名字new_pca
pca = PCA(n_components=2)
new_pca = pd.DataFrame(pca.fit_transform(new_df)) ##可视化
d = new_pca[new_df['jllable'] == 0]
plt.plot(d[0], d[1], 'r.')
d = new_pca[new_df['jllable'] == 1]
plt.plot(d[0], d[1], 'go')
d = new_pca[new_df['jllable'] == 2]
plt.plot(d[0], d[1], 'b*')
plt.gcf().savefig('kmeans.png')
plt.show()


【转】利用python的KMeans和PCA包实现聚类算法的更多相关文章
- 利用python的KMeans和PCA包实现聚类算法
题目: 通过给出的驾驶员行为数据(trip.csv),对驾驶员不同时段的驾驶类型进行聚类,聚成普通驾驶类型,激进类型和超冷静型3类 . 利用Python的scikit-learn包中的Kmeans算法 ...
- 机器学习实战之 第10章 K-Means(K-均值)聚类算法
第 10 章 K-Means(K-均值)聚类算法 K-Means 算法 聚类是一种无监督的学习, 它将相似的对象归到一个簇中, 将不相似对象归到不同簇中.相似这一概念取决于所选择的相似度计算方法.K- ...
- 【机器学习实战】第 10 章 K-Means(K-均值)聚类算法
第 10 章 K-Means(K-均值)聚类算法 K-Means 算法 聚类是一种无监督的学习, 它将相似的对象归到一个簇中, 将不相似对象归到不同簇中.相似这一概念取决于所选择的相似度计算方法.K- ...
- 【机器学习实战】第10章 K-Means(K-均值)聚类算法
第 十 章 K-Means(K-均值)聚类算法 K-Means 算法 聚类是一种无监督的学习, 它将相似的对象归到一个簇中, 将不相似对象归到不同簇中.相似这一概念取决于所选择的相似度计算方法.K-M ...
- K-Means聚类算法原理
K-Means算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means算法有大量的变体,本文就从最传统的K-Means算法讲起,在其基础上讲述K-Means的优化变体 ...
- 一步步教你轻松学K-means聚类算法
一步步教你轻松学K-means聚类算法(白宁超 2018年9月13日09:10:33) 导读:k-均值算法(英文:k-means clustering),属于比较常用的算法之一,文本首先介绍聚类的理 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- 利用Python进行数据分析(4) NumPy基础: ndarray简单介绍
一.NumPy 是什么 NumPy 是 Python 科学计算的基础包,它专为进行严格的数字处理而产生.在之前的随笔里已有更加详细的介绍,这里不再赘述. 利用 Python 进行数据分析(一)简单介绍 ...
- 利用Python进行数据分析(1) 简单介绍
一.处理数据的基本内容 数据分析 是指对数据进行控制.处理.整理.分析的过程. 在这里,“数据”是指结构化的数据,例如:记录.多维数组.Excel 里的数据.关系型数据库中的数据.数据表等. 二.说说 ...
随机推荐
- 三层+EasyUI+Ajax 提交Form表单
源代码下载:http://download.csdn.net/download/qq_25237531/10267746
- HibernateTemplate的用法以及作用
HibernateTemplate作用:从字面上意思我们就知道他是一个模板,然后我们又知道hibernate是一个对象关系映射的框架,所以我们很容易联想到他的功能就是将Hibernate 的持久层访问 ...
- PHP7.27: MySqlhelper class
https://github.com/ThingEngineer/PHP-MySQLi-Database-Class https://github.com/wildantea/php-pdo-mysq ...
- JS之this应用详解
目录 1. this作为全局变量2. 作为对象方法的调用3. 作为构造函数调用4. apply调用 this是Javascript语言的一个关键字.它代表函数运行时,自动生成的一个内部对象,只能在函数 ...
- 【读书笔记】iOS-设计简单的Frenzic式益智游戏
如果你决定用UIView动画或Core Animation,一定要编写一些测试用例,模拟游戏可能遇到的要求最高的动画,另外不要忘记播放声音.不要等到最后才增加声音,因为在iPhone上播放音乐和音效确 ...
- Jmeter进阶篇之逻辑控制器
最近,遇到了一个困扰很多人的问题.情景如下: 业务流程:登录一个网站,反复进行充值. 通常的做法是使用jmeter对登录和充值的接口进行反复的执行: 但是实现的方法却不能完美的贴合业务流程.并且,在进 ...
- ArcGIS Server Rest 认证过程分析
1. http://192.168.1.220:6080/arcgis/admin/login?redirect= Request URL: http://192.168.1.220:6080/arc ...
- Expo大作战(四十一)【完】--expo sdk 之 Assets,BarCodeScanner,AppLoading
Expo大作战系列完结! 简要:本系列文章讲会对expo进行全面的介绍,本人从2017年6月份接触expo以来,对expo的研究断断续续,一路走来将近10个月,废话不多说,接下来你看到内容,讲全部来与 ...
- 【Java入门提高篇】Day22 Java容器类详解(五)HashMap源码分析(上)
准备了很长时间,终于理清了思路,鼓起勇气,开始介绍本篇的主角——HashMap.说实话,这家伙能说的内容太多了,要是像前面ArrayList那样翻译一下源码,稍微说说重点,肯定会让很多人摸不着头脑,不 ...
- 简述 Spring Cloud 是什么1
很多同学都了解了Spring ,了解了 Spring Boot, 但对于 Spring Cloud 是什么还是比较懵逼的. 本文带你简单的了解下,什么是Spring Cloud. Spring Clo ...