零基础爬虫----python爬取豆瓣电影top250的信息(转)
今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习。话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的。
python环境:python3.5
先看看网页的样子
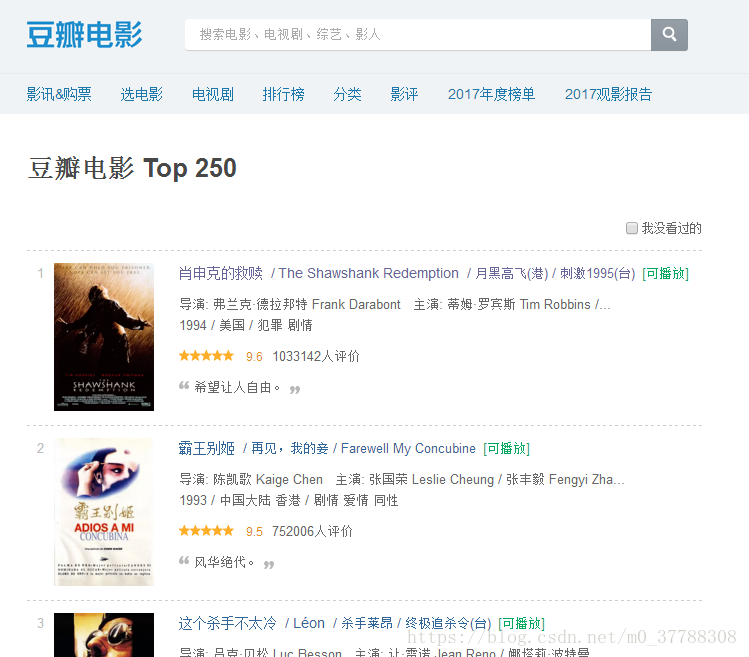
我们下面将要对电影的名字、链接、评分、评价人数和一句话描述这些信息进行提取
1、检查并复制电影名字的xPath信息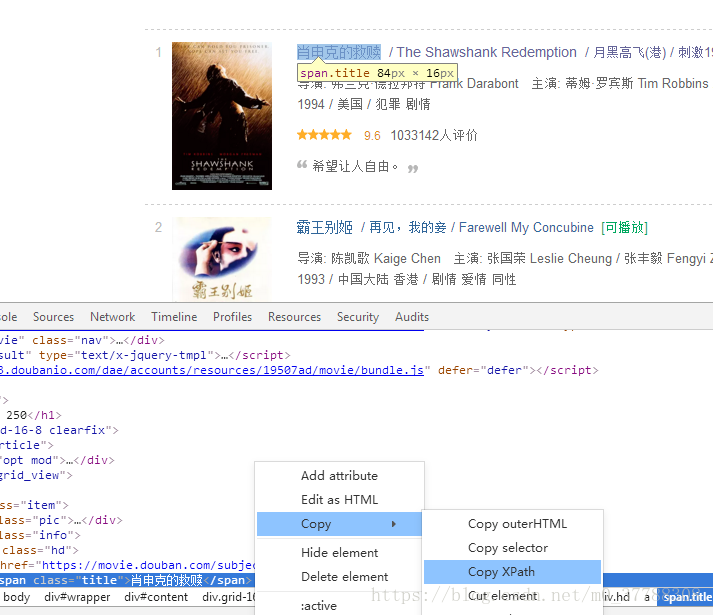
电影《肖申克的救赎》的xPath信息如下:
//*[@id=”content”]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]
按照爬虫的代码套路来一波
from lxml import etree
import requests def get_1_name():
'''
爬取豆瓣top250电影的第1个电影的名字
:return:
'''
url = 'https://movie.douban.com/top250' # #豆瓣top250网址
data = requests.get(url).text # #得到html内容
s = etree.HTML(data) # #etree.HTML用来解析html内容
xpath_test = '//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]'+'/text()' # #谷歌浏览器中选中文字,右键检查,复制xpath
title = s.xpath(xpath_test)[0] # #列表只有一个元素
print(title)
输出结果: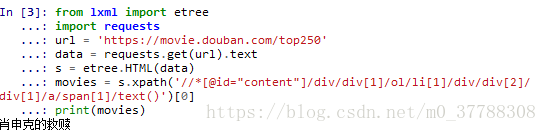
第六行代码最后加[0],是因为不加的话,返回的则会是一个列表,不好看。
2、对同一页的不同电影名字进行提取
根据《肖申克的救赎》同方法对《霸王别姬》、《这个杀手不太冷》和《阿甘正传》的xPath信息比较:
比较可以发现电影名的xPath信息仅仅li后面的序号不一样,并且和电影名的序号一样,所以去掉序号以后,就可以得到通用的xPath信息
//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]
接下来我们把这一页的电影名字个爬下来
from lxml import etree
import requests
url = 'https://movie.douban.com/top250'
data = requests.get(url).text
s = etree.HTML(data)
title = s.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
for movies in title:
print(movies)
输出结果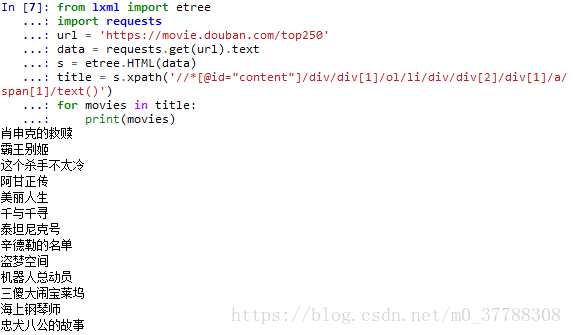
下面用类似的方法对电影评分进行提取
from lxml import etree
import requests
url = 'https://movie.douban.com/top250'
data = requests.get(url).text
s = etree.HTML(data)
score = s.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
for i in score:
print(i)
输出结果为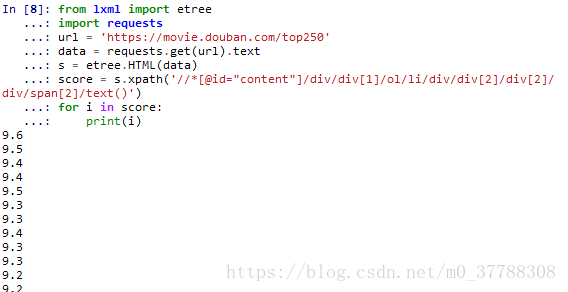
接下来要做的是输出电影及对应的评分
from lxml import etree
import requests
url = 'https://movie.douban.com/top250'
data = requests.get(url).text
s = etree.HTML(data)
file = s.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
score = s.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
for i in range(25):
print("{} {}".format(file[i],score[i]))
输出结果为:
这里我们默认电影名字以及评分都是完整的、正确的信息,这种默认一般情况下是没问题的。但其实是有缺陷的。如果我们少爬了或者多爬了信息,就会发生匹配的错误,那么该怎么避免这种错误呢?
仔细思考下,发现我们若是以电影名字为单位,分别获取对应的信息,那么匹配肯定完全正确。
电影名字的标签肯定在这部电影的框架内,于是我们从电影名字的标签往上找,发现覆盖整部电影的标签,把xPath信息复制下来
//*[@id="content"]/div/div[1]/ol/li[1]
然后我们将整部电影和其他信息的xPath信息进行比较
//*[@id="content"]/div/div[1]/ol/li[1]
//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]
//*[@id="content"]/div/div[1]/ol/li[2]/div/div[2]/div[2]/div/span[2]
不难发现电影名和评分的前半部分与整部电影的前半部分是一样的。那我们就可以这样写xPath的方式来定位信息:
file = s.xpath('//*[@id="content"]/div/div[1]/ol/li[1]')
movies_name = div.xpath('./div/div[2]/div[1]/a/span[1]/text()')
movies_score = div.xpath('./div/div[2]/div[2]/div/span[2]/text()')
在实际的代码中体验一下
from lxml import etree
import requests
url = 'https://movie.douban.com/top250'
data = requests.get(url).text
s = etree.HTML(data)
file = s.xpath('//*[@id="content"]/div/div[1]/ol/li[1]')
for div in file:
movies_name = div.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
movies_score = div.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
print("{} {}".format(movies_name,movies_score))
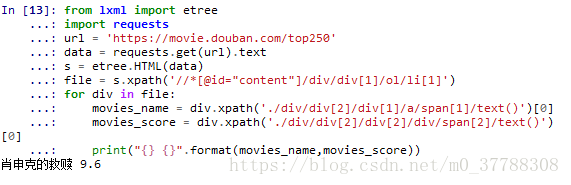
输出结果为
上面我们爬取了一部电影的信息,那么怎么爬取这一页的呢?很简单把li后面的[1]去掉就可以了。来看看新的代码
from lxml import etree
import requests
url = 'https://movie.douban.com/top250'
data = requests.get(url).text
s = etree.HTML(data)
file = s.xpath('//*[@id="content"]/div/div[1]/ol/li')
for div in file:
movies_name = div.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
movies_score = div.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
print("{} {}".format(movies_name,movies_score))
结果为: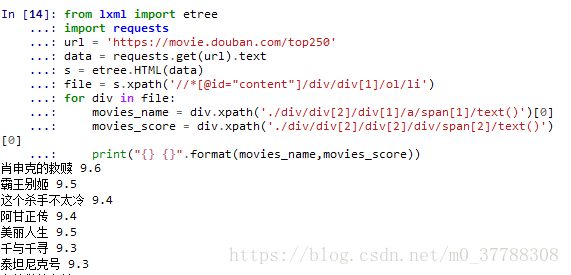
其他信息的提取与之类似,就不在细讲了,代码跑一遍
from lxml import etree
import requests
url = 'https://movie.douban.com/top250'
data = requests.get(url).text
s = etree.HTML(data)
file = s.xpath('//*[@id="content"]/div/div[1]/ol/li')
for div in file:
movies_name = div.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
movies_score = div.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
movies_href = div.xpath('./div/div[2]/div[1]/a/@href')[0]
movies_number = div.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0].strip("(").strip( ).strip(")")
movie_scrible = div.xpath('./div/div[2]/div[2]/p[2]/span/text()')
print("{} {} {} {} {}".format(movies_name,movies_href,movies_score,movies_number,movie_scrible[0]))
结果为: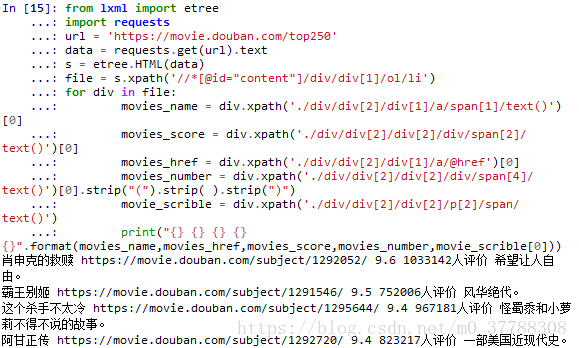
这样我们就对第一页的信息进行了提取,那么我么怎么把所有的页都提取呢?比较一下不同页的URL
第一页:https://movie.douban.com/top250?start=0
第二页:https://movie.douban.com/top250?start=25
第三页:https://movie.douban.com/top250?start=50
第四页:https://movie.douban.com/top250?start=75
......
URL的变化规律很简单,只是start=()的数字不一样,以25为单位递增,所以写个循环就可以了,下面把整个代码跑一下,所有25页的信息全部提取下来。
from lxml import etree
import requests
import time
for a in range(10):
url = 'https://movie.douban.com/top250?start={}'.format(a*25)
data = requests.get(url).text
# print(data)
s = etree.HTML(data)
file = s.xpath('//*[@id="content"]/div/div[1]/ol/li')
for div in file:
movies_name = div.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0]
movies_score = div.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
movies_href = div.xpath('./div/div[2]/div[1]/a/@href')[0]
movies_number = div.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0].strip("(").strip( ).strip(")")
movie_scrible = div.xpath('./div/div[2]/div[2]/p[2]/span/text()')
# time.sleep(1)
if len(movie_scrible)>0:
print("{} {} {} {} {}".format(movies_name,movies_href,movies_score,movies_number,movie_scrible[0]))
else:
print("{} {} {} {}".format(movies_name,movies_href,movies_score,movies_number))
结果为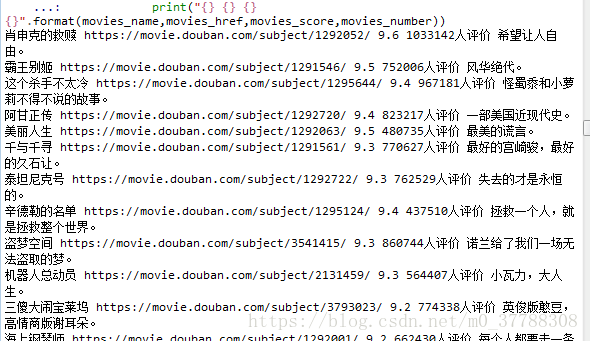
这只是一部分截图,整体的包含了250部电影。
注:这里加了个if语句,是因为发现有的电影没有一句话描述。Ok了,这个爬虫很简单,也是我刚开始学习xPath,适合新手学习
---------------------
作者:云南省高校数据化运营管理工程研究中心
来源:CSDN
原文:https://blog.csdn.net/m0_37788308/article/details/80378042
版权声明:本文为博主原创文章,转载请附上博文链接!
零基础爬虫----python爬取豆瓣电影top250的信息(转)的更多相关文章
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- python爬取豆瓣电影Top250(附完整源代码)
初学爬虫,学习一下三方库的使用以及简单静态网页的分析.就跟着视频写了一个爬取豆瓣Top250排行榜的爬虫. 网页分析 我个人感觉写爬虫最重要的就是分析网页,找到网页的规律,找到自己需要内容所在的地方, ...
- Python 爬取豆瓣电影Top250排行榜,爬虫初试
from bs4 import BeautifulSoup import openpyxl import re import urllib.request import urllib.error # ...
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- 第一个nodejs爬虫:爬取豆瓣电影图片
第一个nodejs爬虫:爬取豆瓣电影图片存入本地: 首先在命令行下 npm install request cheerio express -save; 代码: var http = require( ...
随机推荐
- C#词频统计 效能分析
在邹老师的效能分析的建议下对上次写过的词频统计的程序进行分析改进. 效能分析:个人很浅显的认为就是程序的运行效率,代码的执行效率 1.VS 提供了自带的分析工具:performance tool (性 ...
- Linux 系统下使用dd命令备份还原MBR主引导记录
https://en.wikipedia.org/wiki/Master_boot_recordhttps://www.cyberciti.biz/faq/howto-copy-mbr/https:/ ...
- python------面向对象进阶 异常处理
一. 异常处理 try: pass except KeyError as e : #注3.x用as ,except KeyError, e ,2.x 用逗号. print("No this ...
- 运行gunicorn失败:[ERROR] Connection in use: ('0.0.0.0', 8000)
参考:https://pdf-lib.org/Home/Details/5262 执行命令:gunicorn -w 4 -b 0.0.0.0:8000 wsgi:app,遇到如下错误: [2019-0 ...
- Python小练习(二)
按照下面的要求实现对列表的操作: 1)产生一个列表,其中有40个元素,每个元素是0到100的一个随机整数 2)如果这个列表中的数据代表着某个班级40人的分数,请计算成绩低于平均 ...
- [C#]时间格式和字符串的相互转换
一.字符串转化为时间格式 string date = "2018/9/27 10:53:56"; DateTime dt1 = DateTime.Parse(date);//方式1 ...
- 【rocketMQ】之centos6.9安装RocketMQ4.2
基于最新的RocketMQ4.2版本,搭建2Master模式. 硬件环境:centos6.9_x64(两台虚拟机) IP1:192.168.150.128 IP2:192.168.150.129 1. ...
- problem: vue之数组元素中的数组类型值数据改变却无法在子组件视图更新问题
问题:给父组件上的一个数组中的某个元素中的数组类型值,添加值后,数据没有在子组件上更新. 对元素添加值之后,vue的数据其实已经更新了并传给了子组件,子组件中没有立即更新. 那么这里有个问题,在子组件 ...
- python网页爬虫开发之五-反爬
1.头信息检查是否频繁相同 随机产生一个headers, #user_agent 集合 user_agent_list = [ 'Mozilla/5.0 (Windows NT 6.1; WOW64 ...
- css3兼容性检测工具
1. Modernizr 会在Modernizr 会在页面加载后立即检测特性:然后创建一个包含检测结果的 JavaScript 对象,同时在 html 元素加入方便你调整 CSS 的 class ...