Maths | 离散K-L变换/ 主成分分析法
目录
1. 概述
全称:Discrete Karhunen–Loève Transform (KLT)
离散K-L变换来源于祖宗PCA(Principal component analysis)。参见维基百科
- PCA方法在1901年由Karl Pearson提出。在上世纪30年代,Harold Hotelling开拓了PCA的应用方向。
- PCA在信号处理领域称为Discrete Karhunen–Loève Transform (KLT),也就是我们今天的主角;在多变量质量控制领域称为the Hotelling transform,等等。
目的:将原始特征转换为数量较少的新特征。
特点:
- 适用于任意概率密度函数
- 最小均方误差意义下的最优正交变换
- 在消除模式特征之间的相关性、突出差异性方面具有最优效果
2. K-L变换方法和原理推导
2.1. 向量分解
对列向量\(\boldsymbol x\),我们用确定的完备正交归一向量系\(\{\boldsymbol u_j\}\)展开:
\[
\boldsymbol x=\sum_{j=1}^\infty {y_j\boldsymbol u_j}
\]
其中在某个基向量\(\boldsymbol u_j\)上的投影为:
\[
y_j=\boldsymbol u_j^T \boldsymbol x=\boldsymbol u_j^T \sum_{j=1}^\infty {y_j\boldsymbol u_j}
\]
这是惯用方法了。
2.2. 向量估计及其误差
出于压缩数据等目的,我们往往用有限项估计\(\boldsymbol x\),即:
\[
\boldsymbol {\hat x} = \sum_{i=1}^d {y_j\boldsymbol u_j}
\]
估计引入的均方误差为:
\[
\epsilon = E[(x-\hat x)^T(x-\hat x)]=E[\sum_{j=d+1}^\infty {|y_j\boldsymbol u_j|^2}]
\]
\[
=E[\sum_{j=d+1}^\infty {y_j^2}]=E[\sum_{j=d+1}^\infty {\boldsymbol u_j^T \boldsymbol x \boldsymbol x^T \boldsymbol u_j}]
\]
注意,上式之所以这么写,是为了满足矩阵乘法,最终得到一个实数\(y_j^2\)。
对于一组确定的基向量,\(\boldsymbol u_j\)是常量而不是变量,因此上式可以简化为:
\[
\epsilon = \sum_{j=d+1}^\infty {\boldsymbol u_j^T E[\boldsymbol x \boldsymbol x^T] \boldsymbol u_j}
\]
其中,\(R=E[\boldsymbol x \boldsymbol x^T]\)是自相关矩阵(因为\(\boldsymbol x\)是列向量),当输入向量\(\boldsymbol x\)给定时,该矩阵就是确定的。
因此,要使估计误差\(\epsilon\)最小,就要求合理选择归一正交向量系\(\{\boldsymbol u_j\}\)。
2.3. 寻找最小误差对应的正交向量系
由拉格朗日乘子法,构造:
\[
g(\boldsymbol u_j) = \sum_{j=d+1}^\infty {\boldsymbol {u_j^T R u_j}}-\sum_{j=d+1}^\infty {\lambda_j (\boldsymbol {u_j^Tu_j}-1)}
\]
对每一个\(\boldsymbol u_j\)求偏导,并令其为0,得:
\[
(2\boldsymbol {Ru_j}-2\lambda_j\boldsymbol {Iu_j})=0,j=d+1,d+2,...
\]
其中用到二次型求偏导的结论,参见博文:二次型求偏导
简化得:
\[
\boldsymbol {Ru_j} = \lambda_j \boldsymbol {Iu_j},j=d+1,d+2,...
\]
这意味着:当我们选取\(\boldsymbol R\)的特征向量作为正交向量系\(\{\boldsymbol u_j\}\)时,可以取得误差极值!\(\lambda_j\)即对应特征值。
这里虽然下标从\(d+1\)开始,但正是因为估计采用的是特征向量系,因此误差也继续沿用特征向量系。
进一步,估计误差的极值为:
\[
\epsilon = \sum_{j=d+1}^\infty {\boldsymbol {u_j^T R u_j}} = \sum_{j=d+1}^\infty {\boldsymbol u_j^T \lambda_j \boldsymbol {Iu_j}} = \sum_{j=d+1}^\infty {\lambda_j}
\]
这意味着:如果我们选取最大特征值对应的特征向量系,作为正交向量系,那么估计误差将会是最小的!
同理,我们是把大特征值的用作估计,因此剩下小特征值的给误差。
因此我们得到了K-L变换本质方法:
取\(\boldsymbol R\)的\(d\)个最大特征值对应的特征向量,作为正交基向量展开\(\boldsymbol x\)。此时截断均方误差最小。

这\(d\)个特征向量组成的正交坐标系,称为\(\boldsymbol x\)所在的\(D\)维空间的\(d\)维K-L变换坐标系,而展开系数向量\(\boldsymbol y\)称为\(\boldsymbol x\)的K-L变换。
最后注意一个技术细节:数据去均值。
前面我们学习的,实际上只针对单个数据:(列)向量\(\boldsymbol x\)。
但实际应用中,我们往往会对多个列向量组成的矩阵\(\boldsymbol X\)执行PCA任务。
推广过程类似,在第四节介绍。根据结论,我们往往会直接取矩阵\(\boldsymbol {XX^T}\)的自协方差矩阵,来获得特征值。
由于自协方差是二阶中心距,因此我们要对数据进行中心化。即把\(\boldsymbol x\)看作是随机变量\(\mathrm x\)的取值,要求\(\mathbb E(\mathrm x) = \boldsymbol 0\)。
比如,我们有两个点:(4,1)和(-2,-3)。那么我们求每个维度上的均值:1和-1,处理后的数据点为:(3,2)和(-3,-2)。
3. K-L变换高效率的本质
我们不妨看一看变换后的\(\boldsymbol y\)的自相关矩阵:
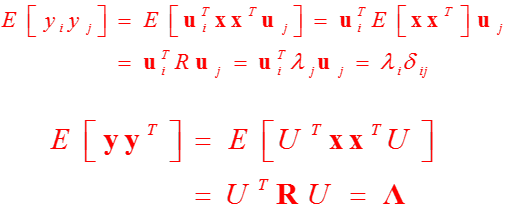
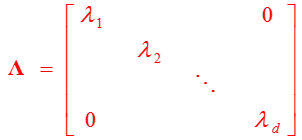
变换后的结果是对角阵!即元素是彼此不相关的。这是K-L变换用于高效数据压缩的杀手锏。
实际上,PCA是寻找输入空间中的一个旋转,使得方差的主坐标,和新表示空间的基坐标对齐。如P92简单例的示意图。
可惜的是,该变换不具有分离性,二维不可分,缺少快速算法。
4. PCA在编、解码应用上的进一步推导
梳理自《DEEP LEARNING》。
4.1. 编、解码函数的定义
待编码的点为\(\boldsymbol x \in \mathbb R^n\)
编码函数为\(\boldsymbol c= f(\boldsymbol x) \in \mathbb R^l\),\(l<n\),以节约存储空间。
解码函数为\(g(\boldsymbol c)\),希望的效果为\(g(\boldsymbol c) \approx \boldsymbol x\)
为了简化,我们用矩阵乘法的形式实现解码器。即\(g(\boldsymbol c)=\boldsymbol {Dc},\boldsymbol D \in \mathbb R^{n*l}\)
其实大家也看出来了,这里解码的思想,仍然是用数目较少的向量,来估计高维的向量\(\boldsymbol x\)。所以才写成矩阵乘法的形式。
4.2. 寻找最优编码\(\boldsymbol c^*\)
4.2.1. 构造、简化优化函数
我们可以采用\(L^2\)范数,来衡量原始输入\(\boldsymbol x\)和重构向量\(g(\boldsymbol c)\)的距离。
这里需要强调一点:我们是在寻找最优编码\(\boldsymbol c^*\)!即当解码函数\(\boldsymbol D\)给定时,如何编码得到\(\boldsymbol c^*\),使得衡量原始输入\(\boldsymbol x\)和重构向量\(g(\boldsymbol c^*)\)之间的距离最小。**
即解码流程已定,只需要考虑编码,但最终效果是解码后误差最小。
为了进一步推导,我们利用平方\(L^2\)范数。
由于\(L^2\)范数是非负的,并且平方运算在非负值上是单调的,因此二者会在相同的最优编码\(\boldsymbol c^*\)上取得最小值:
\[
\boldsymbol c^* = arg \min_c \Vert \boldsymbol x - g(\boldsymbol c) \Vert _2^2 = (\boldsymbol x - g(\boldsymbol c))^T(\boldsymbol x - g(\boldsymbol c))
\]
由分配律(矩阵乘法服从分配律和结合律,不服从交换律),展开得:
\[
(\boldsymbol x - g(\boldsymbol c))^T(\boldsymbol x - g(\boldsymbol c)) = \boldsymbol {x^Tx} - \boldsymbol x^T g(\boldsymbol c) - g(\boldsymbol c)^T \boldsymbol x + g(\boldsymbol c)^Tg(\boldsymbol c) = \boldsymbol {x^Tx} - 2\boldsymbol x^T g(\boldsymbol c) + g(\boldsymbol c)^Tg(\boldsymbol c)
\]
其中\(g(\boldsymbol c)^T \boldsymbol x\)是标量,所以转置等于自己。
在上式中,第一项不依赖于\(\boldsymbol c\),因此我们的优化目标简化为后两项:
\[
\boldsymbol c^* = arg \min_c - 2\boldsymbol x^T g(\boldsymbol c) + g(\boldsymbol c)^Tg(\boldsymbol c)
\]
代入\(g(\boldsymbol c)\)定义:
\[
\boldsymbol c^* = arg \min_c - 2\boldsymbol {x^TDc} + \boldsymbol {c^TD^TDc}
\]
为了简化问题,我们规定\(\boldsymbol D\)中的列向量是相互正交的。要注意不是正交矩阵,因为一般不是方阵。
此外,为了保证\(\boldsymbol D\)有唯一解,我们规定\(\boldsymbol D\)中所有列向量都只有单位范数。
基于这两点假设,我们就可以得到非常简洁的表达式:
\[
\boldsymbol c^* = arg \min_c - 2\boldsymbol {x^TDc} + \boldsymbol {c^TI_lc} = arg \min_c - 2\boldsymbol {x^TDc} + \boldsymbol {c^Tc}
\]
4.2.2. 最优编码函数
我们对上式求\(\boldsymbol c\)的偏导,令其为0,得:
\[
- 2\boldsymbol {D^Tx} + 2\boldsymbol c^* = 0
\]
\[
\boldsymbol c^* = \boldsymbol {D^Tx}
\]
这意味着:最优编码同样利用矩阵乘法,非常高效。
复原的向量为:
\[
\boldsymbol{\hat x} = \boldsymbol {DD^Tx}
\]
4.3. 寻找最优编码矩阵\(\boldsymbol D^*\)
实际上,待处理的\(n\)维点有多个:\(\{\boldsymbol x^{(i)},i=1,2,...\}\),因此\(\boldsymbol D\)必须是整体最优设计。
上一节只针对单个点\(\boldsymbol x\)进行讨论,是因为最终结果只与\(\boldsymbol D\)有关。因此我们现在再全面讨论\(\boldsymbol D\)即可。
因此优化函数为:
\[
\boldsymbol D^* = arg\,\min_{\boldsymbol D} {\sqrt{\sum_{i,j} {(\boldsymbol x_j^{(i)} - \boldsymbol {DD^Tx})^2} }}
\]
这是矩阵之间的Frobenius范数。
之后的推导运用了迹运算的性质等,结论相同:最优矩阵\(\boldsymbol D\)由\(\boldsymbol {XX^T}\)前\(l\)个最大特征值对应的特征向量组成。
Maths | 离散K-L变换/ 主成分分析法的更多相关文章
- 降维之主成分分析法(PCA)
一.主成分分析法的思想 我们在研究某些问题时,需要处理带有很多变量的数据,比如研究房价的影响因素,需要考虑的变量有物价水平.土地价格.利率.就业率.城市化率等.变量和数据很多,但是可能存在噪音和冗余, ...
- (数据科学学习手札22)主成分分析法在Python与R中的基本功能实现
上一篇中我们详细介绍推导了主成分分析法的原理,并基于Python通过自编函数实现了挑选主成分的过程,而在Python与R中都有比较成熟的主成分分析函数,本篇我们就对这些方法进行介绍: R 在R的基础函 ...
- 【转载】主成分分析法(PCA)
https://www.jisilu.cn/question/252942 进行维数约减(Dimensionality Reduction),目前最常用的算法是主成分分析法 (Principal Co ...
- 吴恩达机器学习笔记(八) —— 降维与主成分分析法(PCA)
主要内容: 一.降维与PCA 二.PCA算法过程 三.PCA之恢复 四.如何选取维数K 五.PCA的作用与适用场合 一.降维与PCA 1.所谓降维,就是将数据由原来的n个特征(feature)缩减为k ...
- 机器学习回顾篇(14):主成分分析法(PCA)
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 【机器学习】主成分分析法 PCA (II)
主成分分析法(PAC)的优化——选择主成分的数量 根据上一讲,我们知道协方差为① 而训练集的方差为②. 我们希望在方差尽可能小的情况下选择尽可能小的K值. 也就是说我们需要找到k值使得①/②的值尽可能 ...
- 主成分分析法(PCA)原理和步骤
主成分分析法(PCA)原理和步骤 主成分分析(Principal Component Analysis,PCA)是一种多变量统计方法,它是最常用的降维方法之一,通过正交变换将一组可能存在相关性的变量数 ...
- 用PCA(主成分分析法)进行信号滤波
用PCA(主成分分析法)进行信号滤波 此文章从我之前的C博客上导入,代码什么的可以参考matlab官方帮助文档 现在网上大多是通过PCA对数据进行降维,其实PCA还有一个用处就是可以进行信号滤波.网上 ...
- 【笔记】主成分分析法PCA的原理及计算
主成分分析法PCA的原理及计算 主成分分析法 主成分分析法(Principal Component Analysis),简称PCA,其是一种统计方法,是数据降维,简化数据集的一种常用的方法 它本身是一 ...
随机推荐
- 六、框架<iframe>、背景、实体
HTML5框架 框架标签(frame) 框架对于页面的设计有着很大的作用 框架集的标签(<frameset>) 框架集标签定义如何将窗口分割为框架 每一个frameset定义一系列行或列 ...
- SpringBoot 出现Whitelabel Error Page 解决办法
这是咋了,咋的就404了 我路径也挺对的啊 注解也都写上了啊 咋就找不到了呢? debug吧它不进方法 看日志吧,他还不报错 这家伙给我急的 百度一下午也没解决,最后还是看官网才知道错在了那里,程序只 ...
- Halcon除法
今天,用到了Halcon 的除法.求出两个region的面积,area1,area2.我想求出它们的比值area1/area2.但是发现比值是整数,没有保留小数.应该改为这样area1/real(ar ...
- JEECG-Swagger UI的使用说明
一.代码生成 (此步骤为代码生成器的使用,如不清楚请查阅相关文档视频) 1.进入菜单[在线开发]-->[Online表单开发],选中一张单表/主表,点击代码生成按钮. 2.弹出页面中填写代码生成 ...
- 【Noip模拟 20160929】划区灌溉
题目描述 约翰的奶牛们发现山脊上的草特别美味.为了维持草的生长,约翰打算安装若干喷灌器. 为简化问题,山脊可以看成一维的数轴,长为L(1≤L≤1,000,000)L(1≤L≤1,000,000),而且 ...
- Python3 timeit的用法
Python3中的timeit模块可以用来测试小段代码的运行时间 其中主要通过两个函数来实现:timeit和repeat,代码如下: def timeit(stmt="pass", ...
- CORSFilter 跨域资源访问
CORS 定义 Cross-Origin Resource Sharing(CORS)跨来源资源共享是一份浏览器技术的规范,提供了 Web 服务从不同域传来沙盒脚本的方法,以避开浏览器的同源策略,是 ...
- c++ 中的智能指针实现
摘要:C++11 中新增加了智能指针来预防内存泄漏的问题,在 share_ptr 中主要是通过“引用计数机制”来实现的.我们今天也来自己实现一个简单的智能指针: // smartPointer.cpp ...
- HBase Snapshot原理和实现
HBase 从0.95开始引入了Snapshot,可以对table进行Snapshot,也可以Restore到Snapshot.Snapshot可以在线做,也可以离线做.Snapshot的实现不涉及到 ...
- 机器学习性能指标(ROC、AUC、召回率)
混淆矩阵 构造一个高正确率或高召回率的分类器比较容易,但很难保证二者同时成立 ROC 横轴:FPR(假正样本率)=FP/(FP+TN) 即,所有负样本中被分错的比例 纵轴:TPR(真正样本率)=TP/ ...