基于RobotFramework——自定义kafka库并导入使用
【Kafka】
首先介绍一下我了解的kafka的皮毛信息——
- kafka——一个分布流处理系统:流处理:可以像消息队列一样publish或者subscribe信息;分布式:提供了容错性,并发处理消息的机制
- 集群——kafka运行在集群上,集群包含一个或多个服务器。所谓服务器集群,就是将很多服务器集中在一起进行同一种服务,在客户端看起来像是只有一个服务器。集群可以利用多个计算机进行并行计算从而有很高的计算速度,也可以使用多个计算机做备份,从而使得一个机器坏了,整个系统还能正常运行
- Broker——一个集群有多个broker(一台服务器就是一个broker),一个broker可以容纳多个Topic
- Topic——主题,由用户定义并配置在kafka服务器,用于建立生产者和消费者之间的订阅关系。生产者发送消息到指定的topic下,消费者从这个topic下消费消息。每一条消息包含键值(key),值(value)和时间戳(timestamp)
- Producer——消息生产者,就是像kafka broker发消息的客户端
- Consumer——消息消费者,是消息的使用方,负责消费kafka服务器上的信息
- Partition——消息分区,一个Topic可以分为多个Partition,每个Partition是一个有序的队列,Partition中的每条消息都会被分配一个有序的id(offset)
- offset——消息在Partition中的偏移量,每一条消息在Partition都有唯一的偏移量。
- Consumer Group——消费者分组,用于归组同类消费者。每个consumer属于一个特定的consumer group,多个消费者可以共同消费一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个分组名称,通常也被称为消费者集群。
【kafka-python】
kafka-python是一个python的Kafka客户端,可以用来向kafka的topic发送消息、消费消息。
接下来介绍如何封装自定义的kafka库,然后再RobotFramework上使用——
- 创建文件夹
- 在D:\Python27\Lib\site-packages的文件夹里面创建你的自定义库文件夹,例如lmkafka
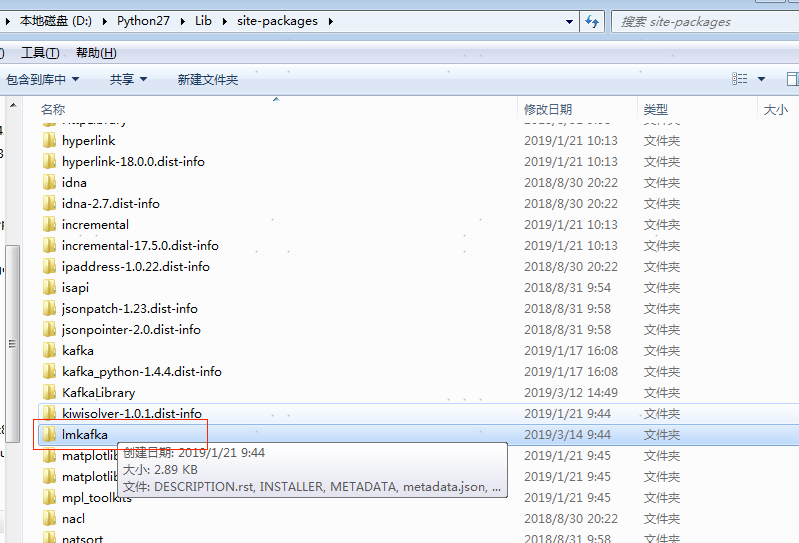
- 在文件夹里面创建两个文件,分别是__init__.py和producer.py(该文件名自定义),代码如下
#producer.py
#!/usr/bin/python
# -*- coding: UTF-8 -*-
#命令行输入pip install kafka-python,进行下载 from kafka import KafkaProducer class Produce(object):
def produce(self,ip,topic,filepath):
producer = KafkaProducer(bootstrap_servers=[ip])
with open(filepath) as f:
msg = f.read()
print msg
# 发送
producer.send(topic, msg)
#print filepath
producer.close()
#__init__.py
#!/usr/bin/python
# -*- coding: UTF-8 -*- from producer import Produce class lmkafka(Produce):
ROBOT_LIBRARY_SCOPE = 'GLOBAL'
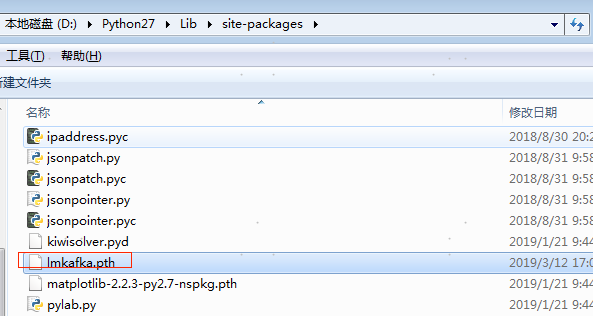
- 创建成功后,尝试重启ride,导入lmkafka库,如果导入不成功(库名为红色),则需要添加路径——在D:\Python27\Lib\site-packages的文件夹里面添加.pth文件,例如lmkafka.pth
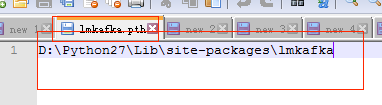
- 文件内容:D:\Python27\Lib\site-packages\lmkafka
再次查看,库导入成功
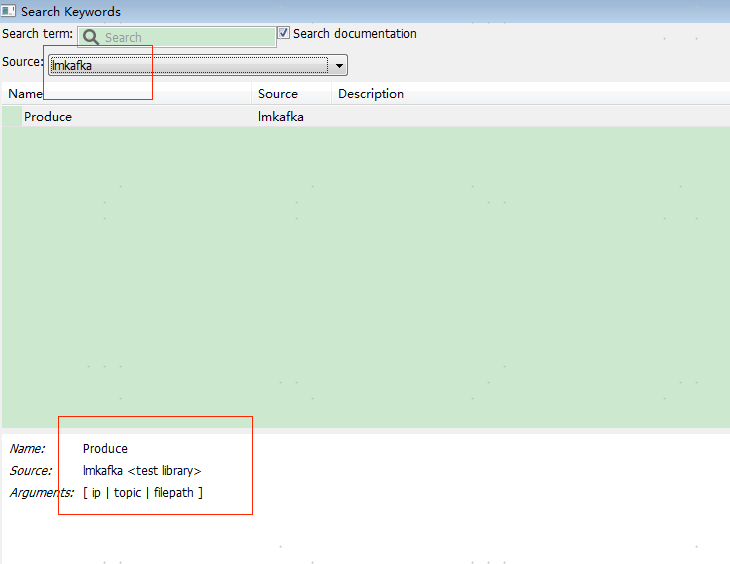
库的使用——

可以向kafka里面发送数据啦~
基于RobotFramework——自定义kafka库并导入使用的更多相关文章
- 【Eclipse】Elipse自定义library库并导入项目
1.定义像JRE System Library之类的库 (1)点击UserLibrary (2)如果没有就点击new新建一个user library,否则进行4 (3)向user library添加 ...
- 基于科大讯飞AIUI平台自定义语义库的开发
说明:我写这篇文章的主要目的是因为我在做这块的时候遇到过一些坑,也是希望后来者能少走一些弯路. 科大讯飞AIUI开放平台地址 科大讯飞AIUI开放平台后处理地址 AIUI后处理开放平台协议 1. 科大 ...
- 基于Web的Kafka管理器工具之Kafka-manager的编译部署详细安装 (支持kafka0.8、0.9和0.10以后版本)(图文详解)(默认端口或任意自定义端口)
不多说,直接上干货! 至于为什么,要写这篇博客以及安装Kafka-manager? 问题详情 无奈于,在kafka里没有一个较好自带的web ui.启动后无法观看,并且不友好.所以,需安装一个第三方的 ...
- Go语言学习之11 日志收集系统kafka库实战
本节主要内容: 1. 日志收集系统设计2. 日志客户端开发 1. 项目背景 a. 每个系统都有日志,当系统出现问题时,需要通过日志解决问题 b. 当系统机器比较少时,登陆到服务器上查看即可 ...
- ElasticSearch7.3学习(十五)----中文分词器(IK Analyzer)及自定义词库
1. 中文分词器 1.1 默认分词器 先来看看ElasticSearch中默认的standard 分词器,对英文比较友好,但是对于中文来说就是按照字符拆分,不是那么友好. GET /_analyze ...
- jsp自定义函数库
步骤如下: 1.创建一个函数库类,里面的方法就是标签函数库要调用的方法(必须是静态方法) package com.mdd.tag; public class JiSuan { //两个数相 ...
- HyperLedger Fabric基于zookeeper和kafka集群配置解析
简述 在搭建HyperLedger Fabric环境的过程中,我们会用到一个configtx.yaml文件(可参考Hyperledger Fabric 1.0 从零开始(八)--Fabric多节点集群 ...
- robot framework自定义python库
自定义python库的好处: robot framework填表式,将python的灵活性弄没了,但是不要担心,RF早就想到了解决办法,就是扩充自己的库. 1.在python应用程序包目录下创建一个新 ...
- 给ambari集群里的kafka安装基于web的kafka管理工具Kafka-manager(图文详解)
不多说,直接上干货! 参考博客 基于Web的Kafka管理器工具之Kafka-manager的编译部署详细安装 (支持kafka0.8.0.9和0.10以后版本)(图文详解)(默认端口或任意自定义端口 ...
随机推荐
- 在Windows Server 2008 R2 Server中,连接其他服务器的数据库遇到“未启用当前数据库的 SQL Server Service Broker,因此查询通知不受支持。如果希望使用通知,请为此数据库启用 Service Broker ”
项目代码和数据库部署在不同的Windows Server 2008 R2 Server中,错误日志显示如下: "未启用当前数据库的 SQL Server Service Broker,因此查 ...
- varnish缓存系统基础知识
缓存系统类型 1.页面缓存/pageCache 缓存静态资源(html js css image) 例如:varnish squid 2.数据缓存/dataCache 缓存应 ...
- python进阶之 进程&线程区别
1.进程创建方式 import time import os from multiprocessing import Process def func (): time.sleep(1) print( ...
- Tomcat不加项目名称访问设置
一.Tomcat不加项目名称访问设置 一.方法一:修改配置文件server.xml 1.修改配置文件server.xml <Host appBase="webapps" au ...
- iOS代理模式(delegate)的使用
前言: 代理模式是iOS中非常重要的一个模式,iOS SDK中的系统控件几乎都用到了代理模式.代理模式用来处理事件监听.参数传递功能. 协议创建(Protocol): 可手打如下代码,或者在代码块里面 ...
- 使用new和newInstance()创建类的区别
在初始化一个类,生成一个实例的时候,newInstance()方法和new关键字除了一个是方法,一个是关键字外,最主要有什么区别?它们的区别在于创建对象的方式不一样,前者是使用类加载机制,后者是创建一 ...
- typescript 01 认识ts和ts的类型
看ITYING ts专辑(前三集总结) TypeScript 是 Javascript 的超级,遵循最新的 ES6.Es5 规范.TypeScript 扩展了 JavaScript 的语法.TypeS ...
- Python基础(十一) 类继承
类继承: 继承的想法在于,充份利用已有类的功能,在其基础上来扩展来定义新的类. Parent Class(父类) 与 Child Class(子类): 被继承的类称为父类,继承的类称为子类,一个父类, ...
- 51.webpack vue-cli创建项目
在上两篇博文中已经安装了node.js.webpack.vue-cli,安装的版本为: 今天通过这篇博文创建项目. 1.选择路径 首先通过命令行进入想要创建项目的路径,例如: 通过e:命令进入盘幅,再 ...
- reactjs中使用高德地图计算两个经纬度之间的距离
第一步下载依赖 npm install --save react-amap 第二步,在组件中使用 import React, { Component } from 'react' import { L ...