深入理解Adaboost算法
理解算法确实是欲速则不达,唯有一步一步慢慢看懂,然后突然觉得写的真的太好了,那才是真的有所理解了。
Adaboost的两点关键点:
1. 如何根据弱模型的表现更新训练集的权重;
2. 如何根据弱模型的表现决定弱模型的话语权
算法步骤:
从训练数据中训练出一系列的弱分类器,然后把这些弱分类器集成为一个强分类器,这里并没有继续对强分类器继续合成。
给定一个训练数据集T={(x1,y1), (x2,y2)…(xN,yN)},其中实例 ,而实例空间
,而实例空间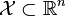 ,yi属于标记集合{-1,+1},Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。
,yi属于标记集合{-1,+1},Adaboost的目的就是从训练数据中学习一系列弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。
Adaboost的算法流程如下:
- 步骤1. 首先,初始化训练数据的权值分布。每一个训练样本最开始时都被赋予相同的权值:1/N。

- 步骤2. 进行多轮迭代,用m = 1,2, ..., M表示迭代的第多少轮
a. 使用具有权值分布Dm的训练数据集学习,得到基本分类器(选取让误差率最低的阈值来设计基本分类器):

b. 计算Gm(x)在训练数据集上的分类误差率

由上述式子可知,Gm(x)在训练数据集上的误差率em就是被Gm(x)误分类样本的权值之和。

由上述式子可知,em <= 1/2时,am >= 0,且am随着em的减小而增大,意味着分类误差率越小的基本分类器在最终分类器中的作用越大。
d. 更新训练数据集的权值分布(目的:得到样本的新的权值分布),用于下一轮迭代

使得被基本分类器Gm(x)误分类样本的权值增大,而被正确分类样本的权值减小。就这样,通过这样的方式,AdaBoost方法能“重点关注”或“聚焦于”那些较难分的样本上。
其中,Zm是规范化因子,使得Dm+1成为一个概率分布:

- 步骤3. 组合各个弱分类器

从而得到最终分类器,如下:

深入理解Adaboost算法的更多相关文章
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- Adaboost 算法
一 Boosting 算法的起源 boost 算法系列的起源来自于PAC Learnability(PAC 可学习性).这套理论主要研究的是什么时候一个问题是可被学习的,当然也会探讨针对可学习的问题的 ...
- Adaboost 算法的原理与推导
0 引言 一直想写Adaboost来着,但迟迟未能动笔.其算法思想虽然简单“听取多人意见,最后综合决策”,但一般书上对其算法的流程描述实在是过于晦涩.昨日11月1日下午,邹博在我组织的机器学习班第8次 ...
- Adaboost算法结合Haar-like特征
Adaboost算法结合Haar-like特征 一.Haar-like特征 目前通常使用的Haar-like特征主要包括Paul Viola和Michal Jones在人脸检测中使用的由Papageo ...
- adaboost算法
三 Adaboost 算法 AdaBoost 是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器,即弱分类器,然后把这些弱分类器集合起来,构造一个更强的最终分类器.(很多博客里说的三个臭皮匠 ...
- 数据挖掘学习笔记--AdaBoost算法(一)
声明: 这篇笔记是自己对AdaBoost原理的一些理解,如果有错,还望指正,俯谢- 背景: AdaBoost算法,这个算法思路简单,但是论文真是各种晦涩啊-,以下是自己看了A Short Introd ...
- 前向分步算法 && AdaBoost算法 && 提升树(GBDT)算法 && XGBoost算法
1. 提升方法 提升(boosting)方法是一种常用的统计学方法,在分类问题中,它通过逐轮不断改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能 0x1: 提升方法的基本 ...
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- Adaboost 算法实例解析
Adaboost 算法实例解析 1 Adaboost的原理 1.1 Adaboost基本介绍 AdaBoost,是英文"Adaptive Boosting"(自适应增强)的缩写,由 ...
随机推荐
- KVM虚拟机管理——资源调整
1. 概述2. 计算资源调整2.1 调整处理器配置2.2 调整内存配置3. 存储资源调整3.1 根分区扩展3.2 添加磁盘4. 网络资源调整 1. 概述 KVM在使用过程中,会涉及到计算(CPU,内存 ...
- java使用何种类型表示精确的小数?
问题 java使用何种类型表示精确的小数? 结论 float和double类型的主要设计目标是为了科学计算和工程计算,速度快,存在精度丢失 BigDecimal用来表示任意精确浮点数运算的类,在商业应 ...
- 记一次拿webshell踩过的坑(如何用PHP编写一个不包含数字和字母的后门)
0x01 前言 最近在做代码审计的工作中遇到了一个难题,题目描述如下: <?php include 'flag.php'; if(isset($_GET['code'])){ $code = $ ...
- Nginx支持WebSocket反向代理-学习小结
WebSocket是目前比较成熟的技术了,WebSocket协议为创建客户端和服务器端需要实时双向通讯的webapp提供了一个选择.其为HTML5的一部分,WebSocket相较于原来开发这类app的 ...
- Centos下内网DNS主从环境部署记录
一.DNS是什么?DNS(Domain Name System),即域名系统.它使用层次结构的命名系统,将域名和IP地址相互映射,形成一个分布式数据库系统. DNS采用C-S架构,服务器端工作在UDP ...
- C_数据结构_递归实现求阶乘
# include <stdio.h> int main(void) { int val; printf("请输入一个数字:"); printf("val = ...
- 实践——ELF文件格式分析
一.分析文件头 1. 段入口类型定义(/usr/include/elf.h)下面产生的hello是32位的 使用命令#Hexdump –x ELF_1.o 第一行: 前4字节,蓝色部分,是一个魔数,表 ...
- kNN算法学习(一)
1.首先需要一些训练样本集,例如一道问题(数据)及答案(标签),可以看做一条样本,那么多条,就是样本集 当然这里应该是一条数据及该数据所属的分类,该类别称为标签 2.现在我们已经知道数据与所属类别的对 ...
- 如何实现基于ssh框架的投票系统的的质量属性
如何实现基于ssh框架的投票系统的的质量属性: 项目 :网上考试系统 我做的是网上考试系统,因为标准化的考试越来越重要,而通过计算机进行标准化判卷,系统会自动判卷出成绩,组织考试的人不用组织人员打印试 ...
- ubuntu 下搭建redis和php的redis的拓展
系统环境: 腾讯云服务器, ubuntu16.0.4.4 ,php7.0 一.安装redis服务 sudo apt-get install redis-server 安装好的redis目录在 /e ...