指导手册01:安装Hadoop
指导手册01:安装Hadoop
Part 1:安装及配置虚拟机
1.安装Linux.
(1)打开VMvirtualBox
(2) 控制->新建虚拟机,输入虚拟机名称“marst+学号” 类型:Linux,版本:other Linux(64-bit)
CentOS-6.8-x86_64-bin-DVD1
(3)内存建议1024M, 创建虚拟盘VHD虚拟硬盘,动态分配,硬盘20G。
(4) 右击己创建的虚拟机master, 设置:网络,网卡1:桥接网卡。存储:光盘,选择CentOS-6.8-x86_64-bin-DVD1安装包。(先解压:D:\大数据软件\CentOS-6.8-x86_64-bin-DVD1.rar)
(5) 选择Install or upgrade an existing system (安装或升级现有的系统)
(6)选择安装语言,简体中文,键盘U.S.English,存储设备->Basic Strage Devices,(基本步骤安装),选择“yes discard anyd data”(是的,删除所有检测到的硬盘的所有数据”。
(7)设置主机名为:“mater01.centos.com”,单击下一步,选择时区,设置管理员密码:hadoop.
(8)选择“Use All Space”(使用所有空间)。
(9)选择安装CentOS组件,这里选择“Desktop”(桌面)
(10)安装成功,重击重启,登录,输入用户名“root”以及密码”hadoop”。
2.设置IP
IP的分配与宿主机同一网段,系统默己自动获取IP,可以通过ipconfig命令查看IP地址。并通过宿主机ping 该虚拟机地址,是否能ping通。
也可以手动修改IP地址方式如下:
(1)修改配置文件“/etc/sysconfig/network-scripts/ifcfg-eth0”。
(2)执行命令“vi /etc/sysconfig/network-scripts/ifcfg-eth0
(3)修改ONBOOT=yes(启动时是否激活网卡);BOOTPROTO=static (静态设置IP);添加ip地址,子网掩码,网关。
(4)重启服务(执行命令 service network restart”)
3.远程连接虚拟机(window 安装ssh工具)
(1)在宿主机上ping 虚拟机,查看是事能正常ping通。(注意:Linux机和windows宿机主需关闭防火墙,linux关闭防火墙命令为:service iptabes stop)
(2)在宿主机上安装SSH Secure。 安装完后桌面两个图标,一个是远程连接命令操作工具,另一个是文件传输工具。
(3)单击Quick Connect, 输入Linux的ip地址,用户名:root,端口号:22,密码:hadoop 就可远程登录。
4.虚拟机在线安装软件
|
小贴士:yum命令是在Fedora和RedHat以及SUSE中基于rpm的软件包管理器。 1、RPM是Linux的一种软件包名称,以.rpm结尾 2、yum是杜克大学为了提高RPM软件包安装性而开发的一种软件包管理器。 3、yum安装方法可以彻底解决RPM安装的关联性问题 4、yum提供了查找、安装、删除某一个、一组甚至全部软件包的命令,而且命令简洁而又好记。 Yum命令使用参考文章http://man.linuxde.net/yum yum和apt-get的区别:https://www.cnblogs.com/wxishang1991/p/5322489.html
|
配置本地yum源主要步骤:
(1)执行命令“cd /etc/yum.repos.d”.
(2)查看yum.repos.d目录下的文件:
CentOS-Base.repo,是网络源, CentOS-Medi.pro是本地源。
配置本地源,需要将除yum本地源以外的其它yum源禁用。
执行命令“mv CentOS-Base.repo CentOS-Base.rep.bak”
(3)执行命命令“vi CentOS-Media.repo”. 将baseurl的值改为file:///media/(光盘挂载点位位置),将gpgcheck的值改为0(表示对从这个源下载的rpm包不进行校验),enable值改为1(表示启用这个源)。,
(4)挂载
执行mount /dev/dvd /media
如果测挂载成功,检查虚拟机光盘是否己启用。
(5)更新云源
Yum cleal all
(6)使用yum从光盘安装包安装软件。在此以安装vim、zip、openssh-server、openssh-clent为例。
yum install –y vim zip openssh-server openssh-client
5.测试实现
使用vim编辑器在虚拟机master的/opt目录下编写文件a.txt。
(1)使用ssh工具打开master会话。
(2)进入/opt目录,命令为cd /opt
(3)使用vim创建一个空文件,命令为: vim a.txt
(4)按“A”“I”,或”O”键,进入编辑状态,在a.txt文件里编写一段文字:”welcome hadoop!”
(5)按”Esc”键,退出编辑状态,输入“:wq”,按回车保存退出。
另一件方式
用ssh文件传输工具连接master,在window机器上编写好a.txt上传到mater的/opt文件夹下。
LINUX基本命令文章:http://www.cnblogs.com/yjd_hycf_space/p/7730690.html
Vim使用文章:https://blog.csdn.net/leon1741/article/details/54314053
1.linux添加一个网卡(桥接模式)并两台机ping通。
2.挂载centos 光驱
mount /dev/dvd /media
3.安装gcc、kernel、kernel-devel内核源,以便能对virtualbox的驱动进行编译。
yum install gcc kernel kernel-devel -y
4.安装虚拟机增强功能。
5.输入df查看己安装的文件系统,发现己有sr0
6设置-共享文件夹-设置共享文件夹soft(windows中共享的文件夹)
7.mount -t vboxsf soft /mnt
如提示错误
/sbin/mount.vboxsf: mounting failed with the error: Invalid argument
1.取消自动挂载可以解决,
2.r若1没有效果,即在/etc/fstab中添加一项
soft /mnt/shared vboxsf rw,gid=100,uid=1000,auto 0 0
8. cd/mnt/share就可查看到共享文件夹。
Part 2: 安装java
1.在windows 下安装java
(1)双击jdk文件安装
(2)更改jdk安装目录;
(3)更改jre安装目录;
(4)配置环境变量
系统变量→新建:JAVA_HOME 变量值:C:\Program Files\Java\jdk1.8.0_121
系统变量→Path→编辑:在变量值最后输入 :%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;
系统变量→新建:CLASSPATH 变量值:.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar
2.在Linux下安装Java
(1)上传JDK安装包到/opt目录下
(2)进入/opt目录,执行命令“rpm –ivh jdk-7u80-linux-x64.rpm”安装JDK
3.配置SSH无密码登录
(1)使用ssh-keygen产生公钥与私钥对。
输入命令“ssh-keygen -t rsa”,接着按三次Enter键
3.测试实现
在Windows下查看jdk 版本的步骤如下。
(1)打开windwos运行窗口。
(2)执行命令“java –version”.
在Linux系统下查看JDK版本的步骤如下。
(1)打开终端会话。
(2)执行命令“java –version”。
Part 3 Hadoop安装与配置
|
基于思路: 1.新建虚拟机master,配置固定IP(可设两个网卡,一个网卡桥接,另一个网卡NAT方式),关闭防火墙,安装必要软件; 2.克隆master到salve1、slave2、slave3; 3.修改slave1~slave3的IP,改为固定IP; |
1. 上传hadoop安装包。
通过SSH Secure File Transfer Client上传hadoop-2.6.4.tar.gz文件到/opt目录
2. 解压缩hadoop-2.6.0.tar.gz 文件
tar -zxf hadoop-2.6.0.tar.gz -C /usr/local
解压后即可,看到/usr/local/hadoop-2.6.0文件夹
3. 配置Hadoop
进入目录:
cd /usr/local/hadoop-2.6.4/etc/hadoop/
依次修改下面的文件:
4.1 core-site.xml
<configuration>
<!-- 配置hdfs的namenode的地址-- >
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<!-- 配置Hadoop运行时产生数据的存储目录,不是临时的数据 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/var/log/hadoop/tmp</value>
</property>
</configuration>
4.2 hadoop-env.sh
<!--修改JAVA_HOM如下:-->
export JAVA_HOME=/usr/java/jdk1.7.0_80
4.3 hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/hdfs/data</value>
</property>
<!-- 指定HDFS的Web访问端口 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<!-- 指定HDFS存储数据的副本数据量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
4.4 mapred-site.xml
<configuration>
<!-- 指定mapreduce编程模型运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- jobhistory properties -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
4.5 yarn-site.xml
<configuration>
<!-- 指定yarn的老大(ResourceManager的地址) -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!—对客户端的暴露地址,客户端通过该地址向RM提交应用程序-->
<!—对ApplicationMaster的暴露地址,ApplicationMaster端通过该地址向RM申请资源释放资源-->
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<!—对nodeManager的暴露地址--- >
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/hadoop/yarn/local</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/data/tmp/logs</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs/</value>
<description>URL for job history server</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<--nodeManager总可用的虚拟CPU个数-->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
4.6 yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_80
|
如果己有Linux客户机slave节点,则 拷贝hadoop安装文件到集群slave节点,否则直接运行第6步克隆 scp -r /usr/local/hadoop-2.6.4 slave01:/usr/local scp -r /usr/local/hadoop-2.6.4 slave02:/usr/local scp -r /usr/local/hadoop-2.6.4 slave03:/usr/local |
4.7 修改 slaves文件
Slave1
Slave2
Slave3
4.8 设置IP映射
编辑/etc/hosts
10.0.2.4 master master.centos.com
10.0.2.5 slave1 slave1.centos.com
10.0.2.6 slave2 slave2.centos.com
10.0.2.7 slave3 slave3.centos.com
5.搭建集群网络环境
(1)在全局设置里设置NAT网络,集群网段设为10.0.2.0
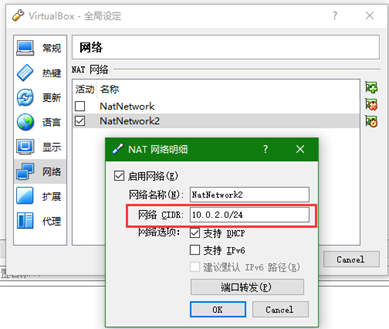
(2)将master主机添加网卡2,并设置为NAT方式。
网卡2 IP地址设为:10.0.2.4
6.克隆虚拟机
克隆master到slave1、slave2、slave3;修改slave1~slave3的IP,改为固定IP;
开启虚拟机slave1。
打开设置->网络,刷新网卡地址。

拓朴图:

(1)执行命令“rm –rf /etc/udev/rules.d/70-persistent-net.rules”删除该文件。
(2)执行命令ifconfig –a,查看HWADDR.
(3)修改/etc/sysconfig/network-scripts/ifcfg-eth0文件,修改ip地址及网卡地址
Slave1、slave2、slave3网卡IP地址分别设为:10.0.2.4;10.0.2.5, 10.0.2.6
(4)修改机器名,执行命令:“vim /etc/sysconfig/network.
修改机器名分别为:slave1.cents.com, slave2.cents.com, slave3.cents.com,
7.配置SSH无密码登录
(1)使用ssh-keygen产生公钥与私钥对。
输入命令“ssh-keygen -t rsa”,接着按三次Enter键
[root@master ~]# ssh-keygen -t rsa
Generating pub/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
a6:13:5a:7b:54:eb:77:58:bd:56:ef:d0:64:90:66:d4 root@master.centos.com
The key's randomart image is:
+--[ RSA 2048]----+
| .. |
| . .E|
| . = |
| . . o o |
| o S . . =|
| o * . o ++|
| . + . . o ooo|
| o . ..o |
| .|
+-----------------+
生成私有密钥id_rsa和公有密钥id_rsa.pub两个文件。ssh-keygen用来生成RSA类型的密钥以及管理该密钥,参数“-t”用于指定要创建的SSH密钥的类型为RSA。
(2)用ssh-copy-id将公钥复制到远程机器中
ssh-copy-id -i /root/.ssh/id_rsa.pub master//依次输入yes,123456(root用户的密码)
ssh-copy-id -i /root/.ssh/id_rsa.pub slave1
ssh-copy-id -i /root/.ssh/id_rsa.pub slave2
ssh-copy-id -i /root/.ssh/id_rsa.pub slave3
(3)验证时间是否同步
依次输入
ssh slave1
ssh slave2
ssh slave3
8.配置时间同步服务
(1)安装NTP服务。在各节点:
yum -y install ntp
(2)设置假设master节点为NTP服务主节点,那么其配置如下。
使用命令“vim /etc/ntp.conf”打开/etc/ntp.conf文件,注释掉以server开头的行,并添加:
restrict 10.0.2.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)分别在slave1、slave2、slave3中配置NTP,同样修改/etc/ntp.conf文件,注释掉server开头的行,并添加:
server master
(4)执行命令“service iptables stop & chkconfig iptables off”永久性关闭防火墙,主节点和从节点都要关闭。
(5)启动NTP服务。
① 在master节点执行命令“service ntpd start & chkconfig ntpd on”
② 在slave1、slave2、slave3上执行命令“ntpdate master”即可同步时间
③ 在slave1、slave2、slave3上分别执行“service ntpd start & chkconfig ntpd on”即可启动并永久启动NTP服务。
9.在/etc/profile添加JAVA_HOME和Hadoop路径
export HADOOP_HOME=/usr/local/hadoop-2.6.4
export PATH=$HADOOP_HOME/bin:$PATH:/usr/java/jdk1.7.0_80/bin
source /etc/profile使修改生效
10. 格式化NameNode
进入目录(usr/local)
cd /opt/hadoop-2.6.4/bin
执行格式化
./hdfs namenode -format
11.启动集群
进入目录
cd /usr/local/hadoop-2.6.4/sbin
执行启动:./
./start-dfs.sh
./start-yarn.sh
./mr-jobhistory-daemon.sh start historyserver
使用jps,查看进程
[root@centos67 sbin]# jps
3672 NodeManager
3301 DataNode
3038 NameNode
4000 JobHistoryServer
4058 Jps
3589 ResourceManager
3408 SecondaryNameNode
12. 关闭防火墙(在所有节点执行):
service iptables stop
chkconfig iptables off
13. 浏览器查看:
http://master:50070
http://master:8088
指导手册01:安装Hadoop的更多相关文章
- 指导手册 07 安装配置HIVE
指导手册 07 安装配置HIVE 安装环境及所需安装包: 1.操作系统:centos6.8 2.四台虚拟机:master :10.0.2.4, slave1:10.0.2.5,slave2:10. ...
- 指导手册03:Hadoop基础操作
指导手册03:Hadoop基础操作 Part 1:查看Hadoop集群的基本信息1.查询存储系统信息(1)在WEB浏览器的地址栏输入http://master:50070/ 请查看自己的Hadoop集 ...
- 指导手册02:伪分布式安装Hadoop(ubuntuLinux)
指导手册02:伪分布式安装Hadoop(ubuntuLinux) Part 1:安装及配置虚拟机 1.安装Linux. 1.安装Ubuntu1604 64位系统 2.设置语言,能输入中文 3.创建 ...
- 指导手册06:HBase安装部署
指导手册06:HBase安装部署 配置环境 1.参考文件: https://www.cnblogs.com/lzxlfly/p/7221890.html https://www.cnblogs.com ...
- 实训任务01:安装Hadoop
实训任务1:安装Hadoop 实训1 :为Hadoop集群增加一个节点 需示说明: 运行环境:操作系统:centos6.8 ,hadoop2.6.4 在实训指导中搭建了3个节点的hadoop集群,要求 ...
- 指导手册05:MapReduce编程入门
指导手册05:MapReduce编程入门 Part 1:使用Eclipse创建MapReduce工程 操作系统: Centos 6.8, hadoop 2.6.4 情景描述: 因为Hadoop本身 ...
- 指导手册04:运行MapReduce
指导手册04:运行MapReduce Part 1:运行单个MapReduce任务 情景描述: 本次任务要求对HDFS目录中的数据文件/user/root/email_log.txt进行计算处理, ...
- (第2篇)一篇文章教你轻松安装hadoop
摘要: 这篇文章将会手把手教你安装hadoop,只要你细心按照文章中的步骤操作,hadoop肯定能正确安装,绝对不会让你崩溃 博主福利 给大家赠送一套hadoop视频课程 授课老师是百度 hadoop ...
- hadoop学习通过虚拟机安装hadoop完全分布式集群
要想深入的学习hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个had ...
随机推荐
- 构建高性能的MYSQL数据库系统-主从复制
实验环境: DB1:172.16.1.100 DB2:172.16.1.101 VRRIP:172.16.1.99 步骤: yum -y install mysql 1.修改DB1的mysql配置文件 ...
- SQL获取第一天最后一天
DECLARE @dtdatetime SET @dt=GETDATE() DECLARE @number int --1.指定日期该年的第一天或最后一天 --A. 年的第一天 SELECTCONVE ...
- bs4.FeatureNotFound: Couldn’t find a tree builder with the features you requested: lxml.
python3 bs4解析网页时报错: bs4.FeatureNotFound: Couldn’t find a tree builder with the features you requeste ...
- 分布式系统Paxos算法
转载 原地址:https://www.jdon.com/artichect/paxos.html 主要加一个对应场景,如:Spring Cloud 的 Consul 集权之间的通信,其实是Raft算法 ...
- c#高级编程第七版 学习笔记 第三章 对象和类型
第三章 对象和类型 本章的内容: 类和结构的区别 类成员 按值和按引用传送参数 方法重载 构造函数和静态构造函数 只读字段 部分类 静态类 Object类,其他类型都从该类派生而来 3.1 类和结构 ...
- 模块 import 与from
什么是模块:就是一系列功能的集合体 模块的来源 :1内置模块 2 第三方模块 3 自定义模块 模块的格式: 1 使用python编写的.py文件 2 已被编译为共享库或DLL的C或C++扩展 ...
- JS设计模式(13)状态模式
什么是状态模式? 定义:将事物内部的每个状态分别封装成类,内部状态改变会产生不同行为. 主要解决:对象的行为依赖于它的状态(属性),并且可以根据它的状态改变而改变它的相关行为. 何时使用:代码中包含大 ...
- 关于Could not read pom.xml和No plugin found for prefix 'tomcate7' in the current project
当时出现的错误: 有大神知道我这个错误怎么解决吗[ERROR] No plugin found for prefix 'tomcate7' in the current project and in ...
- P4512 【模板】多项式除法
思路 多项式除法板子 多项式除法 给出\(A(x)\)和\(B(x)\),求一个\(n-m\)次的多项式\(D(x)\),一个\(m-1\)次多项式\(R(x)\),满足 \[ A(x)=B(x)D( ...
- (转载)Unity UGUI鼠标点击UI不受影响方法IsPointerOverGameObject
这几天在做捕鱼达人游戏时发现,当鼠标点击UI时,炮台的子弹也会发射子弹,这样会影响用户体验. 然后网上百度了一波,发现在UGUI系统上,EventSystem提供了一些方法.那就是EventSyste ...