EM算法笔记
EM算法在很多地方都用使用到,比如简单的K-means算法,还有在隐马尔可夫里面,也涉及到了EM算法,可见EM算法在机器学习领域的重要地位。在这里就写一下我对于EM算法的一些理解笔记。后续有新的理解也会追加的。
EM算法的全称叫做:期望最大。EM算法的想法很简单,就像一个人有两条腿向前走,你总是需要固定一条腿动另一条腿这样交替往前走。这里面的两条腿,一个是隐变量,一个是参数θ。
在了解EM算法之前,首先需要了解一些基本的概念。
凹凸函数
这个是《最优化》里面的概念,如果它的二阶导大于0,那么就是凸函数;如果是二阶导小于0,那么就是凹函数。(我记得《最优化》数学老师说,高数的定义和最优化的定义是反着的,因为用的概念不一样,高数好像用的是前苏联的定义,最优化是用的欧洲定义。我也不知道是不是真的……)。这样可能不是很容易记住,所以就取两个很有代表性的函数,方便记忆:凸函数:x2,凹函数:−x2。这样,就是你忘记了定义,也很容易通过这两个函数想越来。更重要的是为了方便你理解下面的概念。
Jensen不等式
这个是EM里面,我认为最重要的一个概念,因为它其实是贯穿整个EM的算法里面的。Jensen不等式的概念也很简单,就是如果是凸函数:f(E(x)) < E(f(x));凹函数:f(E(x)) > E(f(x))。这个定义可能一开始没看明白是什么意思,主要问题可能是那个E(x)的期望。换一个简单的说法, 就是如果是凸函数f(x+y2)<f(x)+f(y)2。这里其实是就是把期望这个公式简化成每个变量出现的概率是1/2,然后你把这个画到f(x)=x2里面就一目了然了。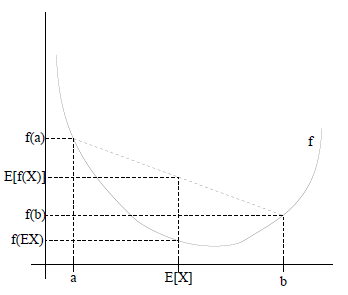
EM算法
给定的训练样本是x(1),...,x(m),我们希望求出最大的概率p(x;θ)。
我们可以求出这个模型的最大似然估计:
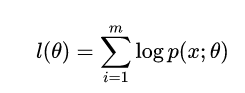
然后取对数:
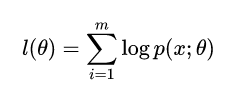
但是,在这个模型里面我们认为p(x;θ)是存在隐变量z的,于是上式改写成
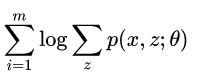
之前求最大似然是很容易,取完对数求导就可以了,但是现在不行,因为有一个隐变量了。那么应该怎么做呢,我们可以固定一个参数,先求另一个参数的最大化,然后再求之前固定的参数。
但是先固定哪个呢,还是随便固定?(这个问题在K-means里面也有,后面再解释。)
这里,我们先观察上面那个式子,直接想出θ是不可能了,因为有z。所以如果想求θ,就一定要固定z。那怎么固定z呢?EM算法就用到了Jensen不等式来估计这个这个z。log是一个凹函数,所以上面那个式子根据不等式是存在一个下界的,那么我们就可以通过下界等式成立的情况来求出最大的z对不对?所以我们可以写出
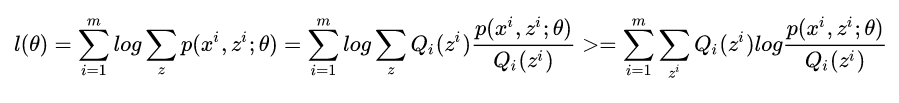
我们可以把jensen的f(x)换log就是上面那个式子了。
EM算法可以写成: 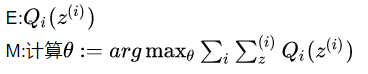
EM推导
EM要解决两个问题,一个是什么时候等式相等;二是为什么一定收敛。
什么时候等式成立呢?
x=E(x)的时候,你带入就会发现两边等式是相等的。因为都是取那一个点,而且概率也一样,所以自然相等。所以就是p(xi,zi;θ)Qi(z(i))=c
然后把Q乘过去,并对所有的z求和,得到:
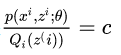
又因为∑zQi(zi)等于1所以∑zp(xi,zi;θ)=c
因此我们可以知道
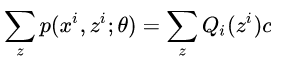
从而EM算法两步可以理解为: 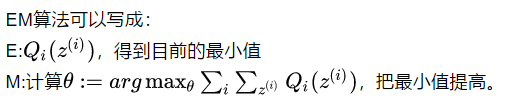
为什么一定收敛?
其实为什么收敛需要解决的一个问题是,是否是单调,如果是单调的话,就可以通过变化幅度来决定。

之所以l(t)<=l(t+1)是因为在M步的时候,θ让公式变大了。所以既然单调,就可以通过变化来证明收敛。
其实这两个问题,也是E与M分别需要解决的问题,E就是让等式成立,而M就是让新状态大于旧状态。
参考资料:
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
http://www.csuldw.com/2015/12/02/2015-12-02-EM-algorithms/
EM算法笔记的更多相关文章
- 读吴恩达算-EM算法笔记
最近感觉对EM算法有一点遗忘,在表述的时候,还是有一点说不清,于是重新去看了这篇<CS229 Lecture notes>笔记. 于是有了这篇小札. 关于Jensen's inequali ...
- 机器学习-EM算法笔记
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域算法的基础,比如隐式马尔科夫算法(HMM), LDA主题模型的变分推断,混合高斯模型 ...
- 学习笔记——EM算法
EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计.EM算法的每次迭代由两步组成:E步,求期望(expectation):M步,求 ...
- 猪猪的机器学习笔记(十四)EM算法
EM算法 作者:樱花猪 摘要: 本文为七月算法(julyedu.com)12月机器学习第十次次课在线笔记.EM算法全称为Expectation Maximization Algorithm,既最大 ...
- GMM高斯混合模型学习笔记(EM算法求解)
提出混合模型主要是为了能更好地近似一些较复杂的样本分布,通过不断添加component个数,能够随意地逼近不论什么连续的概率分布.所以我们觉得不论什么样本分布都能够用混合模型来建模.由于高斯函数具有一 ...
- 《统计学习方法》笔记九 EM算法及其推广
本系列笔记内容参考来源为李航<统计学习方法> EM算法是一种迭代算法,用于含有隐变量的概率模型参数的极大似然估计或极大后验概率估计.迭代由 (1)E步:求期望 (2)M步:求极大 组成,称 ...
- python机器学习笔记:EM算法
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域的基础,比如隐式马尔科夫算法(HMM),LDA主题模型的变分推断算法等等.本文对于E ...
- 统计学习方法笔记--EM算法--三硬币例子补充
本文,意在说明<统计学习方法>第九章EM算法的三硬币例子,公式(9.5-9.6如何而来) 下面是(公式9.5-9.8)的说明, 本人水平有限,怀着分享学习的态度发表此文,欢迎大家批评,交流 ...
- 《统计学习方法》笔记(9):EM算法和隐马尔科夫模型
EM也称期望极大算法(Expectation Maximization),是一种用来对含有隐含变量的概率模型进行极大似然估计的迭代算法.该算法可应用于隐马尔科夫模型的参数估计. 1.含有隐含参数的概率 ...
随机推荐
- JavaScript之读取和写入cookie
首先先让我们简单地了解一下cookie. 在我们制作网页的过程中,经常需要把信息从一个页面传递给另一个页面,这时候就需要用到JavaScript中的cookie机制了.简单说来,cookie提 ...
- Django学习(5)优雅地分页展示网页
在我们平时浏览网页时,经常会遇到网页里条目很多的情形,这时就会用到分页展示的功能.那么,在Django中,是如何实现网页分类的功能的呢?答案是Paginator类. 本次分享讲具体展示如何利用Djan ...
- drupal简单安装和插件安装
1.从官网下载drupal安装包:https://www.drupal.org/download 2.windows下使用WAMPSERVER作为php的服务器,在官网http://www.wamps ...
- try、catch、finally详解,你不知道的异常处理
介绍 不管是新手还是工作几年的老油条,对try{}catch{}来说是不陌生的.他可以来帮助我们获取异常信息,在try中的代码出现错误,火灾catch代码块中被捕获到.官方也给了详细的解释:. 抛出异 ...
- Matlab adaptive quadrature
% script to perform adaptive quadrature clear all, close all global pts % function to be integrated ...
- Sample Means(耶鲁大学教材)
Sample Means The sample mean from a group of observations is an estimate of the population mean. Giv ...
- 微信公共号:CTO技术总监
业务价值胜过技术策略: 战略目标胜过具体项目的效益: 内置的互操作胜过定制的集成: 共享服务胜过特定目标的实现: 灵活性胜过优化: 不断演进地提炼胜过在最开始追求完美!
- cordova极光推送插件使用
首先是在极光官网注册登录账号,然后创建推送应用,创建完应用之后,点击打开应用,设置应用的包名,保存: 然后回到应用主界面,看到AppKey,以及MasterSecret,这时候MasterSecret ...
- lfs(systemd版本)学习笔记-第3页
我的邮箱地址:zytrenren@163.com欢迎大家交流学习纠错! lfs(systemd)学习笔记-第2页 的地址:https://www.cnblogs.com/renren-study-no ...
- 在JSP中获取oracle中的时间戳类型的字段并显示
在oracle中有一种特殊的时间显示类型——Timestamp时间戳 通常我们将当前时间转化为时间戳的语法如下: select cast (sysdate as timestamp ) from du ...