Hadoop讲解
1.简介
Hadoop是一款开源的大数据通用处理平台,其提供了分布式存储和分布式离线计算,适合大规模数据、流式数据(写一次,读多次),不适合低延时的访问、大量的小文件以及频繁修改的文件。
*Hadoop由HDFS、YARN、MapReduce组成。
Hadoop的特点:
1.高扩展(动态扩容):能够存储和处理千兆字节数据(PB),能够动态的增加和卸载节点,提升存储能力(能够达到上千个节点)
2.低成本:只需要普通的PC机就能实现,不依赖高端存储设备和服务器。
3.高效率:通过在Hadoop集群中分化数据并行处理,使得处理速度非常快。
4.可靠性:数据有多份副本,并且在任务失败后能自动重新部署。
Hadoop的使用场景:
1.日志分析,将数据分片并行计算处理。
2.基于海量数据的在线应用。
3.推荐系统,精准营销。
4.搜索引擎。
Hadoop生态圈:
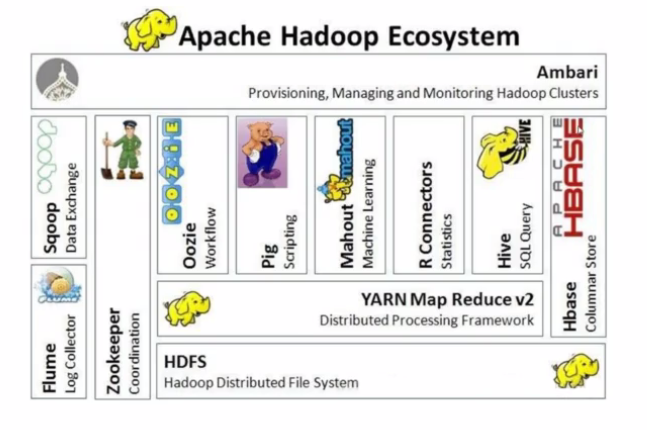
Hive:利用Hive可以不需要编写复杂的Hadoop程序,只需要写一个SQL语句,Hive就会把SQL语句转换成Hadoop的任务去执行,降低使用Hadoop离线计算的门槛。
HBase:海量数据存储的非关系型数据库,单个表中的数据能够容纳百亿行x百万列。
ZooKeeper:监控Hadoop集群中每个节点的状态,管理整个集群的配置,维护节点间数据的一致性。
Flume:海量日志采集系统。
2.内部结构
2.1 HDFS
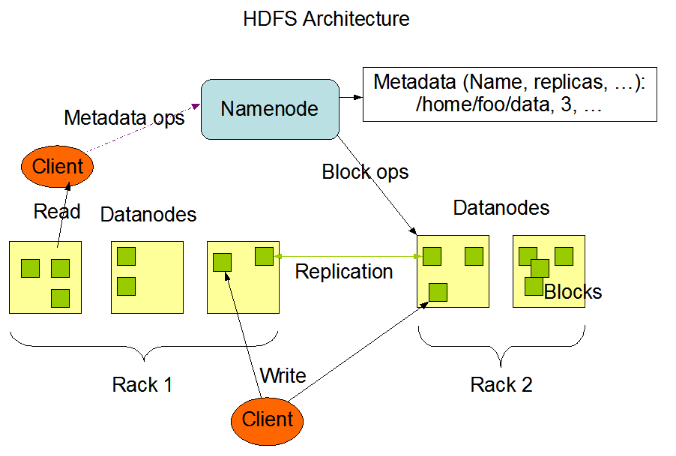
HDFS是分布式文件系统,存储海量的文件,其中HDFS中包含NameNode、DataNode、SecondaryNameNode组件等。
Block数据块
1.HDFS中基本的存储单元,1.X版本中每个Block默认是64M,2.X版本中每个Block默认是128M。
2.一个大文件会被拆分成多个Block进行存储,如果一个文件少于Block的大小,那么其实际占用的空间为文件自身大小。
3.每个Block都会在不同的DataNode节点中存在备份(默认备份数是3)
DataNode
1.保存具体的Blocks数据。
2.负责数据的读写操作和复制操作。
3.DataNode启动时会向NameNode汇报当前存储的数据块信息。
NameNode
1.存储文件的元信息和文件与Block、DataNode的关系,NameNode运行时所有数据都保存在内存中,因此整个HDFS可存储的文件数受限于NameNode的内存大小。
2.每个Block在NameNode中都对应一条记录,如果是大量的小文件将会消耗大量内存,因此HDFS适合存储大文件。
3.NameNode中的数据会定时保存到本地磁盘中(只有元数据),但不保存文件与Block、DataNode的位置信息,这部分数据由DataNode启动时上报和运行时维护。
*NameNode不允许DataNode具有同一个Block的多个副本,所以创建的最大副本数量是当时DataNode的总数。
*DataNode会定期向NameNode发送心跳信息,一旦在一定时间内NameNode没有接收到DataNode发送的心跳则认为其已经宕机,因此不会再给它任何IO请求。
*如果DataNode失效造成副本数量下降并且低于预先设置的阈值或者动态增加副本数量,则NameNode会在合适的时机重新调度DataNode进行复制。
SecondaryNameNode
1.定时与NameNode进行同步,合并HDFS中系统镜像,定时替换NameNode中的镜像。
HDFS写入文件的流程
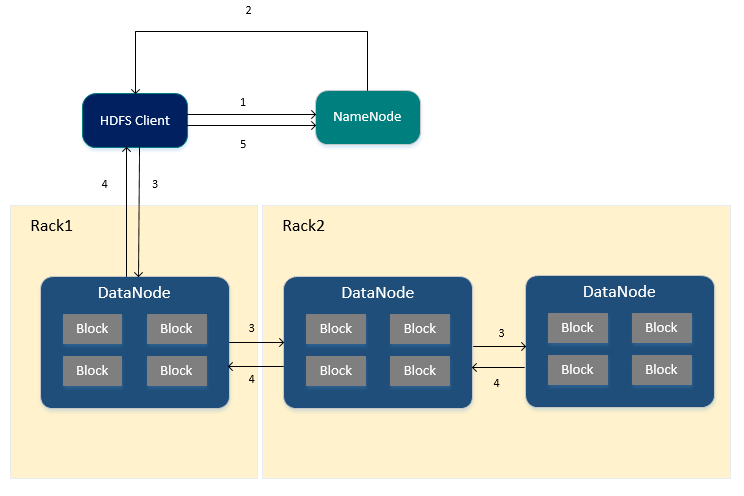
1.HDFS Client向NameNode申请写入文件。
2.NameNode根据文件大小,返回文件要写入的DataNode列表以及Block id (此时NameNode已存储文件的元信息、文件与DataNode、Block之间的关系)
3.HDFS Client收到响应后,将文件写入第一个DataNode中,第一个DataNode接收到数据后将其写入本地磁盘,同时把数据传递给第二个DataNode,直到写入备份数个DataNode。
4.每个DataNode接收完数据后都会向前一个DataNode返回写入成功的响应,最终第一个DataNode将返回HDFS Client客户端写入成功的响应。
5.当HDFS Client接收到整个DataNodes的确认请求后会向NameNode发送最终确认请求,此时NameNode才会提交文件。
*当写入某个DataNode失败时,数据会继续写入其他的DataNode,NameNode会重新寻找DataNode继续复制,以保证数据的可靠性。
*每个Block都会有一个校验码并存放在独立的文件中,以便读的时候来验证数据的完整性。
*文件写入完毕后,向NameNode发送确认请求,此时文件才可见,如果发送确认请求之前NameNode宕机,那么文件将会丢失,HDFS客户端无法进行读取。
HDFS读取文件的流程
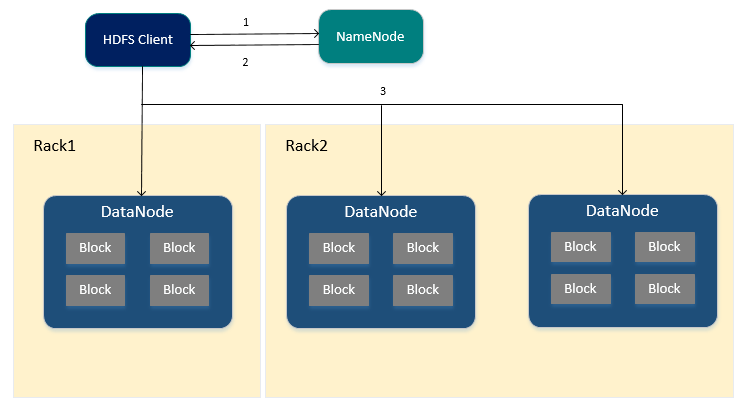
1.HDFS Client向NameNode申请读取指定文件。
2.NameNode返回文件所有的Block以及这些Block所在的DataNodes中(包括复制节点)
3.HDFS Client根据NameNode的返回,优先从与HDFS Client同节点的DataNode中直接读取(若HDFS Client不在集群范围内则随机选择),如果从DataNode中读取失败则通过网络从复制节点中进行读取。
机架感知
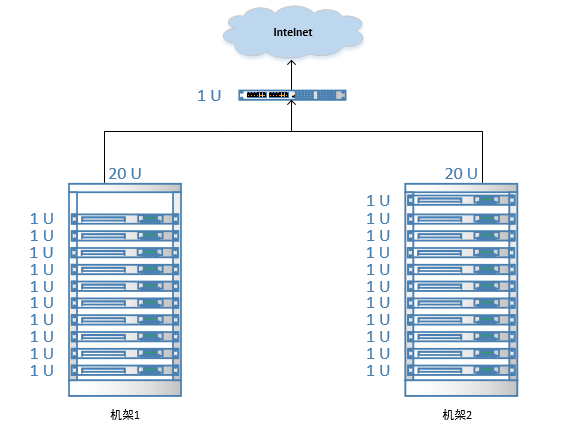
分布式集群中通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群。
机架内的机器之间的网络速度通常都会高于跨机架机器之间的网络速度,并且机架之间机器的网络通信通常受到上层交换机间网络带宽的限制。
Hadoop默认没有开启机架感知功能,默认情况下每个Block都是随机分配DataNode,需要进行相关的配置,那么在NameNode启动时,会将机器与机架的对应信息保存在内存中,用于在HDFS Client申请写文件时,能够根据预先定义的机架关系合理的分配DataNode。
Hadoop机架感知默认对3个副本的存放策略为:
第1个Block副本存放在和HDFS Client所在的节点中(若HDFS Client不在集群范围内则随机选取)
第2个Block副本存放在与第一个节点不同机架下的节点中(随机选择)
第3个Block副本存放在与第2个副本所在节点的机架下的另一个节点中,如果还有更多的副本则随机存放在集群的节点中。
*使用此策略可以保证对文件的访问能够优先在本机架下找到,并且如果整个机架上发生了异常也可以在另外的机架上找到该Block的副本。
2.2 YARN
YARN是分布式资源调度框架(任务计算框架的资源调度框架),主要负责集群中的资源管理以及任务调度并且监控各个节点。
ResourceManager
1.是整个集群的资源管理者,管理并监控各个NodeManager。
2.处理客户端的任务请求。
3.启动和监控ApplicationMaster。
4.负责资源的分配以及调度。
NodeManager
1.是每个节点的管理者,负责任务的执行。
2.处理来自ResourceManager的命令。
3.处理来自ApplicationMaster的命令。
ApplicationMaster
1.数据切分,用于并行计算处理。
2.计算任务所需要的资源。
3.负责任务的监控与容错。
任务运行在YARN的流程
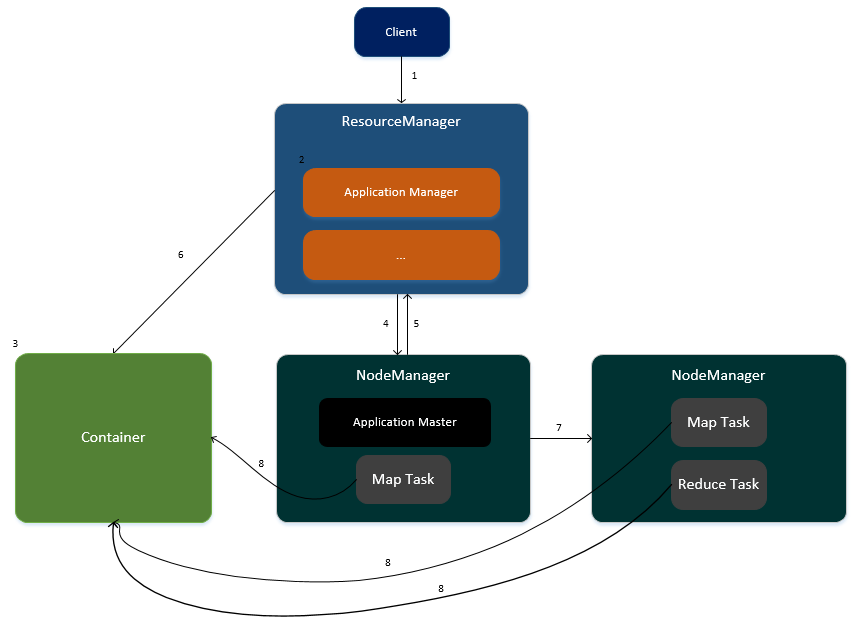
1.客户端提交任务请求到ResourceManager。
2.ResourceManager生成一个ApplicationManager进程,用于任务的管理。
3.ApplicationManager创建一个Container容器用于存放任务所需要的资源。
4.ApplicationManager寻找其中一个NodeManager,在此NodeManager中启动一个ApplicationMaster,用于任务的管理以及监控。
5.ApplicationMaster向ResourceManager进行注册,并计算任务所需的资源汇报给ResourceManager(CPU与内存)
6.ResourceManager为此任务分配资源,资源封装在Container容器中。
7.ApplicationMaster通知集群中相关的NodeManager进行任务的执行。
8.各个NodeManager从Container容器中获取资源并执行Map、Reduce任务。
2.3 MapReduce
MapReduce是分布式离线并行计算框架,高吞吐量,高延时,原理是将分析的数据拆分成多份,通过多台节点并行处理,相对于Storm、Spark任务计算框架而言,MapReduce是最早出现的计算框架。
MapReduce、Storm、Spark任务计算框架对比:

MapReduce执行流程
MapReduce将程序划分为Map任务以及Reduce任务两部分。
Map任务处理流程
1.读取文件中的内容,解析成Key-Value的形式 (Key为偏移量,Value为每行的数据)
2.重写map方法,编写业务逻辑,生成新的Key和Value。
3.对输出的Key、Value进行分区(Partitioner类)
4.对数据按照Key进行排序、分组,相同key的value放到一个集合中(数据汇总)
*处理的文件必须要在HDFS中。
Reduce任务处理流程
1.对多个Map任务的输出,按照不同的分区,通过网络复制到不同的reduce节点。
2.对多个Map任务的输出进行合并、排序。
3.将reduce的输出保存到文件,存放在HDFS中。
3.Hadoop的使用
3.1 安装
由于Hadoop使用Java语言进行编写,因此需要安装JDK。

从Apache Hadoop官网下载并进行解压。

etc目录:Hadoop配置文件存放目录。
logs目录:Hadoop日志存放目录。
bin目录、sbin目录:Hadoop可执行命令存放目录。
etc目录

bin目录
sbin目录
3.2 Hadoop配置
1.配置环境
编辑etc/hadoop/hadoop-env.sh文件,修改JAVA_HOME配置项为本地JAVA的HOME目录,此文件是Hadoop启动时加载的环境变量。

编辑/etc/hosts文件,添加主机名与IP的映射关系。

2.配置Hadoop公共属性(core-site.xml)
<configuration>
<!-- Hadoop工作目录,用于存放Hadoop运行时产生的临时数据 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-2.9.0/data</value>
</property>
<!-- NameNode的通信地址,1.x默认9000,2.x可以使用8020 -->
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.1.80:8020</value>
</property>
</configuration>
3.配置HDFS(hdfs-site.xml)
<configuration>
<!--指定block的副本数量(将block复制到集群中备份数-1个节点的DataNode中)-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 关闭HDFS的访问权限 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
4.配置YARN(yarn-site.xml)
<configuration>
<!-- 配置Reduce取数据的方式是shuffle(随机) -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
5.配置MapReduce(mapred-site.xml)
<configuration>
<!-- 让MapReduce任务使用YARN进行调度 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6.配置SSH
//生成秘钥
ssh-keygen -t rsa //复制秘钥到本机
ssh-copy-id 192.168.1.80
3.3 启动HDFS
1.格式化NameNode

2.启动HDFS,将会启动NameNode、DataNode、SecondaryNameNode三个进程,可以通过jps命令进行查看。


*若启动时出现错误,则可以进入logs目录查看相应的日志文件。
当HDFS启动完毕后,可以访问http://localhost:50070进入HDFS的可视化管理界面,可以在此页面中监控整个HDFS集群的状况并且进行文件的上传以及下载。
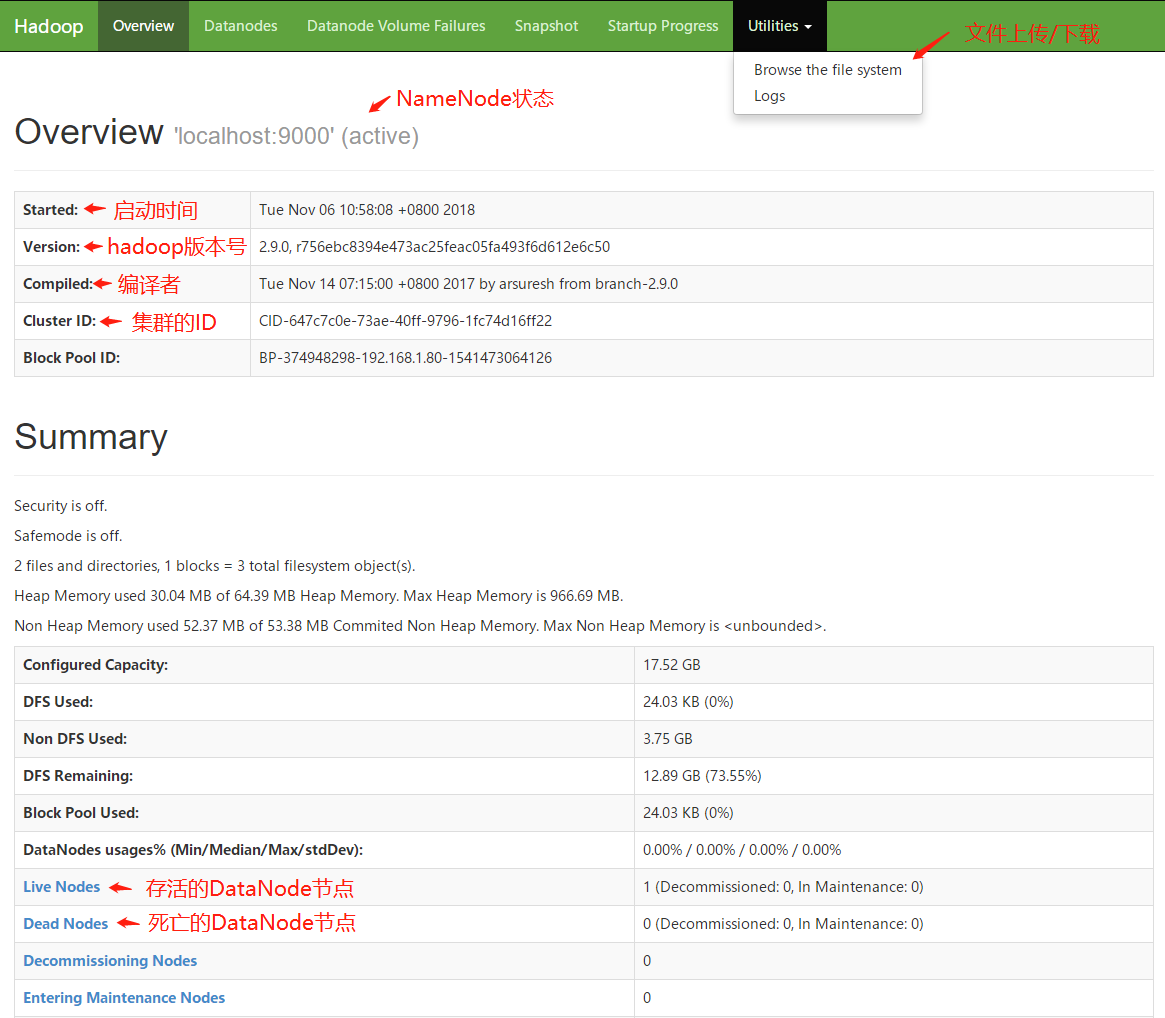
*进入HDFS监控页面下载文件时,会将请求重定向,重定向后的地址的主机名为NameNode的主机名,因此客户端本地的host文件中需要配置NameNode主机名与IP的映射关系。
3.4 启动YARN

启动YARN后,将会启动ResourceManager以及NodeManager进程,可以通过jps命令进行查看。

当YARN启动完毕后,可以访问http://localhost:8088进入YARN的可视化管理界面,可以在此页面中查看任务的执行情况以及资源的分配。

3.5 使用Shell命令操作HDFS
HDFS中的文件系统与Linux类似,由/代表根目录,cd切换目录。
hadoop fs -cat <src>:显示文件中的内容。 hadoop fs -copyFromLocal <localsrc> <dst>:将本地中的文件上传到HDFS。 hadoop fs -copyToLocal <src> <localdst>:将HDFS中的文件下载到本地。 hadoop fs -count <path>:查询指定路径下文件的个数。 hadoop fs -cp <src> <dst>:在HDFS内对文件进行复制。 hadoop fs -get <src> <localdst>:将HDFS中的文件下载到本地。 hadoop fs -ls <path>:显示指定目录下的内容。 hadoop fs -mkdir <path>:创建目录。 hadoop fs -moveFromLocal <localsrc> <dst>:将本地中的文件剪切到HDFS中。 hadoop fs -moveToLocal <src> <localdst> :将HDFS中的文件剪切到本地中。 hadoop fs -mv <src> <dst> :在HDFS内对文件进行移动。 hadoop fs -put <localsrc> <dst>:将本地中的文件上传到HDFS。 hadoop fs -rm <src>:删除HDFS中的文件。
3.6 JAVA中操作HDFS示例
/**
* @Auther: ZHUANGHAOTANG
* @Date: 2018/11/6 11:49
* @Description:
*/
public class HDFSUtils { /**
* HDFS NamenNode URL
*/
private static final String NAMENODE_URL = "hdfs://hadoop1:8020"; /**
* 配置项
*/
private static Configuration conf = null; static {
conf = new Configuration();
} /**
* 创建目录
*/
public static void mkdir(String dir) throws Exception {
if (StringUtils.isBlank(dir)) {
throw new Exception("Parameter Is NULL");
}
dir = NAMENODE_URL + dir;
FileSystem fs = FileSystem.get(URI.create(NAMENODE_URL), conf);
if (!fs.exists(new Path(dir))) {
fs.mkdirs(new Path(dir));
}
fs.close();
} /**
* 删除目录或文件
*/
public static void delete(String dir) throws Exception {
if (StringUtils.isBlank(dir)) {
throw new Exception("Parameter Is NULL");
}
dir = NAMENODE_URL + dir;
FileSystem fs = FileSystem.get(URI.create(NAMENODE_URL), conf);
fs.delete(new Path(dir), true);
fs.close();
} /**
* 遍历指定路径下的目录和文件
*/
public static List<String> listAll(String dir) throws Exception {
List<String> names = new ArrayList<>();
if (StringUtils.isBlank(dir)) {
throw new Exception("Parameter Is NULL");
}
dir = NAMENODE_URL + dir;
FileSystem fs = FileSystem.get(URI.create(dir), conf);
FileStatus[] files = fs.listStatus(new Path(dir));
for (int i = 0, len = files.length; i < len; i++) {
if (files[i].isFile()) { //文件
names.add(files[i].getPath().toString());
} else if (files[i].isDirectory()) { //目录
names.add(files[i].getPath().toString());
} else if (files[i].isSymlink()) { //软或硬链接
names.add(files[i].getPath().toString());
}
}
fs.close();
return names;
} /**
* 上传当前服务器的文件到HDFS中
*/
public static void uploadLocalFileToHDFS(String localFile, String hdfsFile) throws Exception {
if (StringUtils.isBlank(localFile) || StringUtils.isBlank(hdfsFile)) {
throw new Exception("Parameter Is NULL");
}
hdfsFile = NAMENODE_URL + hdfsFile;
FileSystem fs = FileSystem.get(URI.create(NAMENODE_URL), conf);
Path src = new Path(localFile);
Path dst = new Path(hdfsFile);
fs.copyFromLocalFile(src, dst);
fs.close();
} /**
* 通过流上传文件
*/
public static void uploadFile(String hdfsPath, InputStream inputStream) throws Exception {
if (StringUtils.isBlank(hdfsPath)) {
throw new Exception("Parameter Is NULL");
}
hdfsPath = NAMENODE_URL + hdfsPath;
FileSystem fs = FileSystem.get(URI.create(NAMENODE_URL), conf);
FSDataOutputStream os = fs.create(new Path(hdfsPath));
BufferedInputStream bufferedInputStream = new BufferedInputStream(inputStream);
byte[] data = new byte[1024];
while (bufferedInputStream.read(data) != -1) {
os.write(data);
}
os.close();
fs.close();
} /**
* 从HDFS中下载文件
*/
public static byte[] readFile(String hdfsFile) throws Exception {
if (StringUtils.isBlank(hdfsFile)) {
throw new Exception("Parameter Is NULL");
}
hdfsFile = NAMENODE_URL + hdfsFile;
FileSystem fs = FileSystem.get(URI.create(NAMENODE_URL), conf);
Path path = new Path(hdfsFile);
if (fs.exists(path)) {
FSDataInputStream is = fs.open(path);
FileStatus stat = fs.getFileStatus(path);
byte[] data = new byte[(int) stat.getLen()];
is.readFully(0, data);
is.close();
fs.close();
return data;
} else {
throw new Exception("File Not Found In HDFS");
}
} }
3.7 执行一个MapReduce任务
Hadoop中提供了hadoop-mapreduce-examples-2.9.0.jar,其封装了一些任务计算方法,可以直接进行调用。

*使用hadoop jar命令执行JAR包。
1.创建一个文件,将此文件上传到HDFS中。
2.使用Hadoop提供的hadoop-mapreduce-examples-2.9.0.jar执行wordcount词频统计功能,然后在YARN管理页面中进行查看。

YARN管理页面中可以查看任务的执行进度:
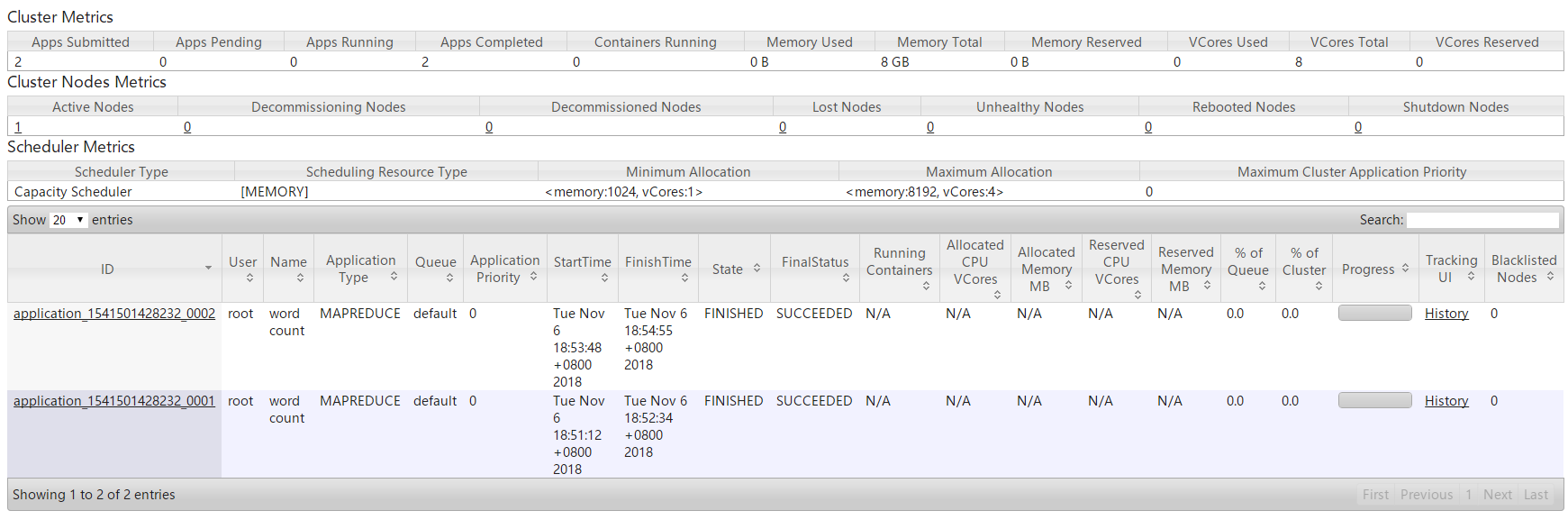
3.当任务执行完毕后,可以查看任务的执行结果。

*任务的执行结果将会放到HDFS的文件中。
Hadoop讲解的更多相关文章
- 马士兵老师hadoop讲解总结博客地址记录(啊啊啊啊啊,自己没有保存写好的博客...)
http://www.cnblogs.com/yucongblog/p/6650822.html
- hadoop中HBase子项目入门讲解
HBase 是Hadoop的一个子项目,HBase采用了Google BigTable的稀疏的,面向列的数据库实现方式的理论,建立在hadoop的hdfs上,一方面里用了hdfs的高可靠性和可伸缩行, ...
- 详细讲解Hadoop源码阅读工程(以hadoop-2.6.0-src.tar.gz和hadoop-2.6.0-cdh5.4.5-src.tar.gz为代表)
首先,说的是,本人到现在为止,已经玩过. 对于,这样的软件,博友,可以去看我博客的相关博文.在此,不一一赘述! Eclipse *版本 Eclipse *下载 Jd ...
- 马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解
Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解 在Hadoop分布式环境下实现K-Means聚类算法的伪代码如下: 输入:参数0--存储样本数据的文本文件inpu ...
- 马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解(转)
马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动 马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作 马士兵hadoop第三课:java开发hdfs 马士兵hadoop第 ...
- [转] hadoop MapReduce实例解析-非常不错,讲解清晰
来源:http://blog.csdn.net/liuxiaochen123/article/details/8786715?utm_source=tuicool 2013-04-11 10:15 4 ...
- 图文讲解基于centos虚拟机的Hadoop集群安装,并且使用Mahout实现贝叶斯分类实例 (7)
接下来,我们开启hadoop集群. 如果之前打开过Hadoop,可能会发生lock的问题,解决方案:http://blog.csdn.net/caoshichaocaoshichao/article/ ...
- 最新Hadoop Shell完全讲解
本文为原创博客,转载请注明出处:http://www.cnblogs.com/MrFee/p/4683953.html 1.appendToFile 功能:将一个或多个源文件系统的内容追加至 ...
随机推荐
- Spring的p标签
看Spring in action的时候看过p标签,可惜这东西不用就忘. p标签是为了简化setter的注入而引入的. 用法: p:属性 = "{值}" p:属性-ref = &q ...
- (转)如何基于FFMPEG和SDL写一个少于1000行代码的视频播放器
原文地址:http://www.dranger.com/ffmpeg/ FFMPEG是一个很好的库,可以用来创建视频应用或者生成特定的工具.FFMPEG几乎为你把所有的繁重工作都做了,比如解码.编码. ...
- 同一页面中引入多个JS库产生的冲突解决方案(转)
发生JS库冲突的主要原因:与jQuery库一样,许多JS库都使用‘$’符号作为其代号.因此在一个页面中引入多个JS库,并且使用‘$’作为代号时,程序不能识别其代表哪个库(这个是我自己的解释,但更深的原 ...
- Spring-Condition设置
为了满足不同条件下生成更为合适的bean,可以使用condition配置其条件.假如有一个bean,id为magicBean,只有当其具有magic属性时才生成,方法如下: javaConfig模式: ...
- asp.net基于windows服务实现定时发送邮件的方法
本文实例讲述了asp.net基于windows服务实现定时发送邮件的方法.分享给大家供大家参考,具体如下: //定义组件 private System.Timers.Timer time; publi ...
- linux,shell脚本中获取脚本的名字,使用脚本的名字。
需求描述: 写shell脚本的过程中,有时会需要获取脚本的名字,比如,有的时候,脚本 中会有usage()这种函数,可能就会用到脚本的名字. 实现方法: shell脚本中,通过使用$0就可以获取到脚本 ...
- Java中的各种加密算法
Java中为我们提供了丰富的加密技术,可以基本的分为单向加密和非对称加密 1.单向加密算法 单向加密算法主要用来验证数据传输的过程中,是否被篡改过. BASE64 严格地说,属于编码格式,而非加密算法 ...
- 第四章 Spring.Net 如何管理您的类___IObjectPostProcessor接口
官方取名叫 对象后处理器 (object post-processor) , 听起来很高级的样子啊!实际上就是所有实现了这个接口的类,增加了两个方法. Spring.Objects.Factory.C ...
- [转]ASP.NET MVC 5– 使用Wijmo MVC 5模板1分钟创建应用
开始使用 使用ComponentOne Studio for ASP.NET Wijmo制作MVC5应用程序,首先要做的是安装Studio for ASP.NET Wijmo . 测试环境 VS201 ...
- docker学习-docker容器