03.搭建Spark集群(CentOS7+Spark2.1.1+Hadoop2.8.0)
接上一篇:https://www.cnblogs.com/yjm0330/p/10077076.html
一、下载安装scala
1、官网下载
2、spar01和02都建立/opt/scala目录,解压tar -zxvf scala-2.12.8.tgz
3、配置环境变量
vi /etc/profile 增加一行
export SCALA_HOME=/opt/scala/scala-2.12.8
同时把hadoop的环境变量增加进去,完整版是:
export JAVA_HOME=/opt/java/jdk1.8.0_191
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export SCALA_HOME=/opt/scala/scala-2.12.8
export CLASSPATH=$:CLASSPATH:${JAVA_HOME}/lib/
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${SCALA_HOME}/bin:$PATH
然后source /etc/profile
4、验证
scala -version
5、同步spark02配置文件
scp /etc/profile spark02:/etc
二、下载安装spark
1、下载,解压,同scala,建立/opt/spark目录
2、配置环境变量
export SPARK_HOME=/opt/spark/spark-2.4.0-bin-hadoop2.7
完整版更新:
export JAVA_HOME=/opt/java/jdk1.8.0_191
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export SCALA_HOME=/opt/scala/scala-2.12.8
export SPARK_HOME=/opt/spark/spark-2.4.0-bin-hadoop2.7
export CLASSPATH=$:CLASSPATH:${JAVA_HOME}/lib/
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${SCALA_HOME}/bin:$PATH
source /etc/profile
scp /etc/profile spark02:/etc
3、配置conf下文件
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
vi spark-env.sh
export SCALA_HOME=/opt/scala/scala-2.12.8
export JAVA_HOME=/opt/java/jdk1.8.0_191
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/opt/spark/spark-2.4.0-bin-hadoop2.7
export SPARK_MASTER_IP=spark01
export SPARK_EXECUTOR_MEMORY=2G
vi slaves
spark02
同步到spark02
scp /opt/spark/spark-2.4.0-bin-hadoop2.7/conf/spark-env.sh spark02:/opt/spark/spark-2.4.0-bin-hadoop2.7/conf/
scp /opt/spark/spark-2.4.0-bin-hadoop2.7/conf/slaves spark02:/opt/spark/spark-2.4.0-bin-hadoop2.7/conf/
三、测试spark
因为spark是依赖于hadoop提供的分布式文件系统的,所以在启动spark之前,先确保hadoop在正常运行。
在hadoop正常运行的情况下,在spark01(也就是hadoop的namenode,spark的marster节点)上执行命令:
cd /opt/spark/spark-2.4.0-bin-hadoop2.7/sbin
执行启动脚本:./start-all.sh
在浏览器里访问Mster机器,我的Spark集群里Master机器是spark01,IP地址是192.168.2.245,访问8080端口,URL是:http://192.168.2.245:8080/
用local模式运行一个计算圆周率的Demo。按照下面的步骤来操作。
第一步,进入到Spark的根目录,也就是执行下面的脚本:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master local examples/jars/spark-examples_2.11-2.4.0.jar
yarn-client模式:
注意执行之前关闭010203的防火墙:
centos7.0(默认是使用firewall作为防火墙,如若未改为iptables防火墙,使用以下命令查看和关闭防火墙)
查看防火墙状态:firewall-cmd --state
关闭防火墙:systemctl stop firewalld.service
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client examples/jars/spark-examples_2.11-2.4.0.jar
四、遇到的问题
1、jps命令无法找到
[root@namenode ~]# jps
bash: jps: command not found...
[root@namenode ~]# find / -name jps
find: ‘/run/user/1001/gvfs’: Permission denied
[root@namenode ~]# rpm -qa |grep -i jdk
java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64
java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64
java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64
java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64
[root@namenode ~]# yum list *openjdk-devel*
需要安装openjdk-devel包
[root@namenode ~]# yum install java-1.8.0-openjdk-devel.x86_64
[root@namenode ~]# which jps
/usr/bin/jps
[root@namenode ~]# jps
12995 Jps
10985 ResourceManager
11179 NodeManager
10061 NameNode
10301 DataNode
10655 SecondaryNameNode
2、XShell上传文件到Linux服务器上
在学习Linux过程中,我们常常需要将本地文件上传到Linux主机上,这里简单记录下使用Xsheel工具进行文件传输
1:首先连接上一台Linux主机
2:输入rz命令,看是否已经安装了lrzsz,如果没有安装则执行 yum -y install lrzsz命令进行安装。
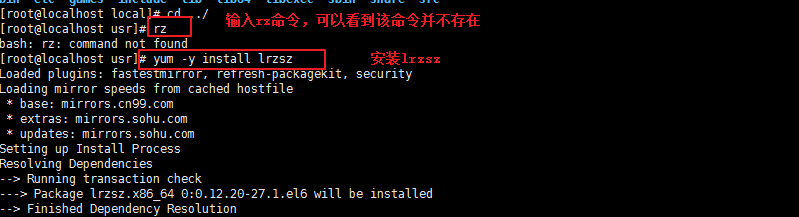
3:安装成功后,输入rpm命令确认是否正确安装

4: 使用 rz -y命令进行文件上传,此时会弹出上传的窗口:
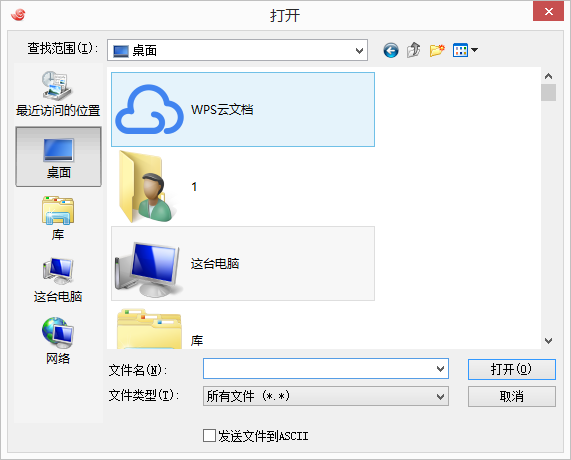
5:选择要上传的文件,点击确定即可将本地文件上传到Linux上,如图表示成功上传文件

6:使用ls命令可以看到文件已经上传到了当前目录下

03.搭建Spark集群(CentOS7+Spark2.1.1+Hadoop2.8.0)的更多相关文章
- 使用Docker搭建Spark集群(用于实现网站流量实时分析模块)
上一篇使用Docker搭建了Hadoop的完全分布式:使用Docker搭建Hadoop集群(伪分布式与完全分布式),本次记录搭建spark集群,使用两者同时来实现之前一直未完成的项目:网站日志流量分析 ...
- 实验室中搭建Spark集群和PyCUDA开发环境
1.安装CUDA 1.1安装前工作 1.1.1选取实验器材 实验中的每台计算机均装有双系统.选择其中一台计算机作为master节点,配置有GeForce GTX 650显卡,拥有384个CUDA核心. ...
- 从0到1搭建spark集群---企业集群搭建
今天分享一篇从0到1搭建Spark集群的步骤,企业中大家亦可以参照次集群搭建自己的Spark集群. 一.下载Spark安装包 可以从官网下载,本集群选择的版本是spark-1.6.0-bin-hado ...
- 搭建spark集群
搭建spark集群 spark1.6和hadoop2.61.准备hadoop环境:2.准备下载包:3.解压安装包:tar -xf spark-1.6.0-bin-hadoop2.6.tgz4.修改配置 ...
- 如何基于Jupyter notebook搭建Spark集群开发环境
摘要:本文介绍如何基于Jupyter notebook搭建Spark集群开发环境. 本文分享自华为云社区<基于Jupyter Notebook 搭建Spark集群开发环境>,作者:apr鹏 ...
- 大数据平台搭建-spark集群安装
版本要求 java 版本:1.8.*(1.8.0_60) 下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downl ...
- 利用最新的CentOS7.5,hadoop3.1,spark2.3.2搭建spark集群
1. 桥接模式,静态ip上外网:vi /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE=EthernetPROXY_METHOD=noneBROWSER_ ...
- CDH搭建Hadoop集群(Centos7)
一.说明 节点(CentOS7.5) Server || Agent CPU node11 Server || Agent 4G node12 Agent 2G node13 Agent 2G 二 ...
- docker使用Dockerfile搭建spark集群
1.创建Dockerfile文件,内容如下 # 基础镜像,包括jdk FROM openjdk:8u131-jre-alpine #作者 LABEL maintainer "tony@163 ...
随机推荐
- 一分钟在云端快速创建MySQL数据库实例
本教程将帮助您了解如何使用Azure管理门户迅速创建,连接,配置MySQL 数据库 on Azure.完成本教程后,您将在Azure上拥有一个示例MySQL数据库服务器,并了解如何使用管理门户执行基本 ...
- C/C++面试问题分类大汇总 ZZ 【C++】
http://www.mianwww.com/html/2014/05/21208.html 指针和引用的区别 指针指向一块内存,它的内容是指向内存的地址:引用是某内存的别名 引用使用是无需解引用,指 ...
- SQL读取注册表值
最近写一个自动检查SQL Serve安全配置的检查脚本,需要查询注册表,下面是使用SQL查询注册表值的方法. ) ) ) ) --For Named instance --SET @Instance ...
- H5 签到功能
Introduce(介绍) 用户签到的H5例子(css+jquery,无图片),由于网上找的的用户签到例子都不好,要不就是好多图片组成的,要不就大量冗余代码,所以特意做了个签到界面(移动端). Use ...
- WebDAV漏洞直接远程溢出拿下服务器
以上是 我做的幻灯片 介绍什么是WebDAV 有什么用 漏洞测试需要的工具 http://pan.baidu.com/s/1o6DYxAE看到这里 说明直接远程溢出 提升权限为system 这些都很久 ...
- 报错 Filtered offsite request
用scrapy框架迭代爬取时报错 scrapy日志: 在 setting.py 文件中 设置 日志 记录等级 LOG_LEVEL= 'DEBUG' LOG_FILE ='log.txt' 观察 scr ...
- AngularJS 自定义指令directive 介绍
--------------------------------------------------------------------------- 指令的作用是把我们自定义的语义化标签替换成浏览器 ...
- Spark读写HBase时出现的问题--RpcRetryingCaller: Call exception
问题描述 Exception in thread "main" org.apache.hadoop.hbase.client.RetriesExhaustedException: ...
- LWIP2.0.2 & FreeRTOS & MQTT 客户端的 使用
1.参考链接 :http://www.nongnu.org/lwip/2_0_x/group__mqtt.html 2.首先移植好lwip,然后添加lwip-2.0.2\src\apps\mqtt ...
- Delphi XE10在 Android下调用静态库a文件
Delphi Seatle can link Delphi project with Static library files(*.a): 1.at Delphi IDE, Add the " ...