Sizzle源码分析:一 设计思路
一.前言
DOM选择器(Sizzle)是jQuery框架中非常重要的一部分,在H5还没有流行起来的时候,jQuery为我们提供了一个简洁,方便,高效的DOM操作模式,成为那个时代的经典。虽然现在Vue,React等MVVM框架的热度如日中天,但是了解下jQuery的DOM选择器设计思路,可以学习到Sizzle设计的精妙之处,为自己模块设计和框架设计提供很好的参考意义,也为了解MVVM框架虚拟DOM打下更好的基础。
二.Sizzle的特别之处
首先介绍下jQuery选择器模块,就是Sizzle选择器,他的网址是http://sizzlejs.com/,如果你只需要进行文档节点的查询,可以直接引入Sizzle的文件就可以了,而不需要整个jQuery文件。
Sizzle选择器有哪些特点呢?
1. 高效,Sizzle通过很多方法来实现了极致的访问速度,为我们搜索DOM节点提供了一个很好的指导,号称是当时最快的DOM选择器引擎。
2. 支持多种查询方式,包括基本选择器(ID,Class,TAG),层级选择器,伪类选择器等等,符合多种复杂场景。
3. 体积小,压缩后只有3K
Sizzle快具体在哪些原因呢,主要从几个角度来分析
1. 优先浏览器本地API:比如基本选择器最终调用的是getElementById等等,对于复杂选择器如果支持querySelector接口,优先使用querySelector来查询。最后对比较老旧的选择器才使用自己的查询逻辑。那使用浏览器本地API比JS本地执行性能高出很多,不在一个数量级。
2. 优化选择符:通过两个角度来优化,一是尽量缩小DOM根节点,缩小搜索的范围,另外是寻找备选种子集合,通过本地接口过滤出备选种子集合,而不是去搜索所有的DOM节点
3. 通过从右向左的方式来解析,在大多数情况下效率高出从左向右的模式很多
4. 通过创建编译函数,通过空间换时间的方式,来提高相同选择符的查询性能,每个选择符查询之后都会被词法分析,然后创建为过滤函数,只要对种子集合执行过滤函数即可。
在介绍Sizzle源码之前,先解释一下从右向左分析的思路,比如有个选择符#div[name=wrapper] div[name=ad2] 如果是我们来分析这个字符串应该怎么分析?我们有两个选择
从左到右分析 和 从右到左分析,那么哪个方案更优呢?答案是从右向左,即使是浏览器渲染CSS也通常是这个规则,为啥呢?
我们考虑下HTML的基本结构,HTML被浏览器首先解析为DOM树类似于下面的结构:

假如我们要查询ad2这个div,$("#div[name=wrapper] div[name=ad2]")
1. 按从左往右的思路,我们首先要找到所有的Div,然后对每个Div是不是warpper,找到以后再对比他的子节点,看看他是不是ad2,对于一个嵌套很深的DOM树来说,每个Div可能存在很多子节点,那么每次遍历子节点的过程将会非常耗时,这是因为父与子的关系是一对多的关系。
2. 按从右向左的思路,我们首先找到所有的DIV,然后看看这个DIV是不是ad2,如果是的话再往上一层父节点查看,是不是wrapper,因为每个节点只有一个父节点,那么这个查询过程瞬间讯速了很多,是不是,因为子于父的关系是多对一,我们知道了子,那就等于是1对1,所以这个过程查询的概率效率肯定要比从左向右迅速许多。
三.如何分析框架源码
Sizzle.js的源码总共有2000多行,里面包含了很多的正则表达式,函数和兼容性处理,咋一看头都是懵的,这里我觉得读框架的源码需要有两个思路:
1. 简化模块,把主线留下:
首先把源码分层,比如jQuery的事件和委托机制,之前文章中介绍过,总共分了4,5层,这样一层一层的分析,可以由底向上,集中注意力,一点点解开源码的大门,否则各种模块耦合在一起会让你看的怀疑人生。
2. 理清思路,找出设计图纸
了解作者的思路,我们每个人在编码的时候是有一个设计流程或者设计图,还有数据结构,我们首先就要通过注释或者相关资料了解作者的这些思路,可以很快的读通源码流程,而不是一上来就淹没在源码中,效率很低。
四.Sizzle框架设计思路分析
首先那我们在分析Sizzle的时候就首先做一个分层处理:
第一层 把兼容性相关逻辑去掉,只保留最常见的选择符的流程,我们假设我们的浏览器都是没有bug的,只需要走正常流程。
第二层 我们把比较复杂的位置伪类相关的逻辑去掉,只考虑普通选择符和层级选择符,比如 $("#div_test > span input[checked=true]"),先不考虑类似:first等位置伪类,这样,源码一下子就精简了很多,等分析完了再加上去掉的逻辑。
第二,我们需要把Sizzle查询的整体思路给画出来,把作者的设计思路画出来,再分析源码就清晰很多。
然后我们来了解一下Sizzle的整个流程图:

首先浏览器先做兼容性和初始化的一些处理,这些略过,然后通过正则表达式判断当前的选择符是不是 ID或者Class或者Tag的简单表达式,如果是的话直接调用JS原生接口getElementById/getElementsByClassName/getElementsByTagName来查询结果,这种效率是最高的,因为JS原生API是性能最好的。
如果是复杂选择器,比如带层级关系或者带伪类等,再判断浏览器是不是支持querySelectorAll高级查询,如果支持,调用querySelectorAll即可,这也是性能比较高的方案,但是如果我们的浏览器版本比较低不支持的话,就只能走下面Sizzle自己的方式来了。
由此可见,随着ES标准的发展,jQuery也引入了最新的API,从而实现了性能的最大优化。
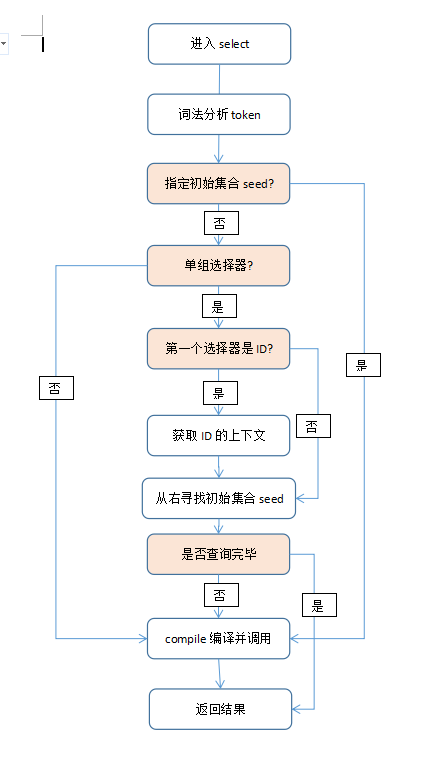
现在进入到Sizzle自己的逻辑来了,首先进入select函数,看看整个流程,比如对于#div_test > span input[checked=true]
1. 首先进入词法分析过程tokenize把选择符字符串转换为token数组,以便后面分析使用,具体过程我们后面再说
2. 尝试缩小上下文范围,默认上下文是document,在这里我们发现#div_test是个ID选择符,可以直接把上下文定位到div_test这个节点,从而提高了查询性能
3. 尝试寻找一个初始集合seed,也就是说缩小备选dom列表,这里是input,所以我们把div_test节点下的所有子节点中的input节点作为seed数组保存起来
4. 将剩下的选择符进行编译保存,然后执行编译函数得到结果。
这里有几个细节说明一下,tokenize函数实现的过程是很多编译器实现的一种方式,比如js代码在执行之前也是从字符串需要进行词法分析,编译优化再执行的过程,通过tokenize可以让机器能理解我们的数据。Sizzle也通过两个尝试,一是缩小上下文,一是建立初始集合seed集合,从而尽可能的去缩小查询的范围,尽可能的提高查询的性能。
Sizzle源码分析:一 设计思路的更多相关文章
- Spring5源码分析(1)设计思想与结构
1 源码地址(带有中文注解)git@github.com:yakax/spring-framework-5.0.2.RELEASE--.git Spring 的设计初衷其实就是为了简化我们的开发 基于 ...
- [转]Libev源码分析 -- 整体设计
Libev源码分析 -- 整体设计 libev是Marc Lehmann用C写的高性能事件循环库.通过libev,可以灵活地把各种事件组织管理起来,如:时钟.io.信号等.libev在业界内也是广受好 ...
- Sizzle源码分析 (一)
Sizzle 源码分析 (一) 2.1 稳定 版本 Sizzle 选择器引擎博大精深,下面开始阅读它的源代码,并从中做出标记 .先从入口开始,之后慢慢切入 . 入口函数 Sizzle () 源码 19 ...
- sizzle源码分析 (4)sizzle 技术总结及值得我们学习的地方
分析sizzle源码并不是为了去钻牛角尖,而是去了解它的思想,学习下期中一些技术的运用. 1,sizzle中的正则表达式jquery源码中充斥着各种正则表达式,能否看懂其源码的关键之一就是对正则表达式 ...
- SOFA 源码分析 —— 过滤器设计
前言 通常 Web 服务器在处理请求时,都会使用过滤器模式,无论是 Tomcat ,还是 Netty,过滤器的好处是能够将处理的流程进行分离和解耦,比如一个 Http 请求进入服务器,可能需要解析 h ...
- Sizzle源码分析:三 筛选和编译
好了有了之前的词法分析过程,现在我们来到select函数来,这个函数的整体流程,前面也大概说过: 1. 先做词法分析获得token列表 2. 如果有种子集合直接到编译过程 3. 如果没有种子集合并且是 ...
- Spark ML源码分析之一 设计框架解读
本博客为作者原创,如需转载请注明参考 在深入理解Spark ML中的各类算法之前,先理一下整个库的设计框架,是非常有必要的,优秀的框架是对复杂问题的抽象和解剖,对这种抽象的学习本身 ...
- Sizzle源码分析:二 词法分析
上一篇我们了解了Sizzle的整体流程,下面我开始一点点分析各个流程,我们进行查询的第一步就是词法分析tokenize,同样先了解下思路,如果是#div_test > span input[ch ...
- Sizzle 源码分析 (二)
在Sizzle函数中,如果能快速处理或者通过querySelector处理,那么就使用它处理.否则使用select函数处理 . select函数 select = Sizzle.select = fu ...
随机推荐
- 【Python】Python 打印和输出更多用法。
Python 打印和输出 简述 在编程实践中,print 的使用频率非常高,特别是程序运行到某个时刻,要检测产生的结果时,必须用 print 来打印输出. 关于 print 函数,前面很多地方已经提及 ...
- Python-装饰器-案例-获取文件列表
import os def get_all_path(fun): '''装饰器.功能:获取全路径文件名.如:D:/tmp/12.txt :param fun: :return:file_path_li ...
- OPENSSL编程 (secure shell, ssh)
很好的 OPENSSL编程 教程,名字就叫“OPENSSL编程” 它里面还有很多关于密码学的东西. http://www.pengshuo.me http://www.pengshuo.me/2014 ...
- WebDriver API 实例详解(二)
十一.双击某个元素 被测试网页的html源码: <html> <head> <meta charset="UTF-8"> </head&g ...
- [golang note] 网络编程 - RPC编程
net包 • 官方文档 http://godoc.golangtc.com/pkg/net/ Package net provides a portable interface for network ...
- zookeeper集群-solrcloud集群
本文只写具体的搭建过程,具体原理请看官网文档.国内博客都是基本上都是通过tomcat搭建的solr,本文是通过内部集成的jetty容器搭建. 一.zookeeper集群搭建 1.安装JAVA环境,版本 ...
- 泰德激光打标软件 包含 #include "Main.h" 时 原本正确的单元却报错
问题:泰德激光打标软件 ,当新增单元需要包含 #include "Main.h" 时, 原本正确的单元却报错. 办法:包含 #include "Main.h" ...
- 使用Sed和Awk实现批量文件的文本替换
摘要: 使用 Sed 完成文本替换操作任务是非常合适的.结合 find 命令,即可实现指定批量文件的文本替换.同时给出了Awk的解决方案作为对比. 问题 现在, 我要将一个原有Java项目中的一些包及 ...
- 网关服务Spring Cloud Gateway(三)
上篇文章介绍了 Gataway 和注册中心的使用,以及 Gataway 中 Filter 的基本使用,这篇文章我们将继续介绍 Filter 的一些常用功能. 修改请求路径的过滤器 StripPrefi ...
- 常用php操作redis命令整理(三)LIST类型
LIST 头元素和尾元素:头元素指的是列表左端/前端第一个元素,尾元素指的是列表右端/后端第一个元素.举个例子,列表list包含三个元素:x, y, z,其中x是头元素,而z则是尾元素.空列表:指不包 ...