Hadoop学习之路(二十七)MapReduce的API使用(四)
第一题
下面是三种商品的销售数据
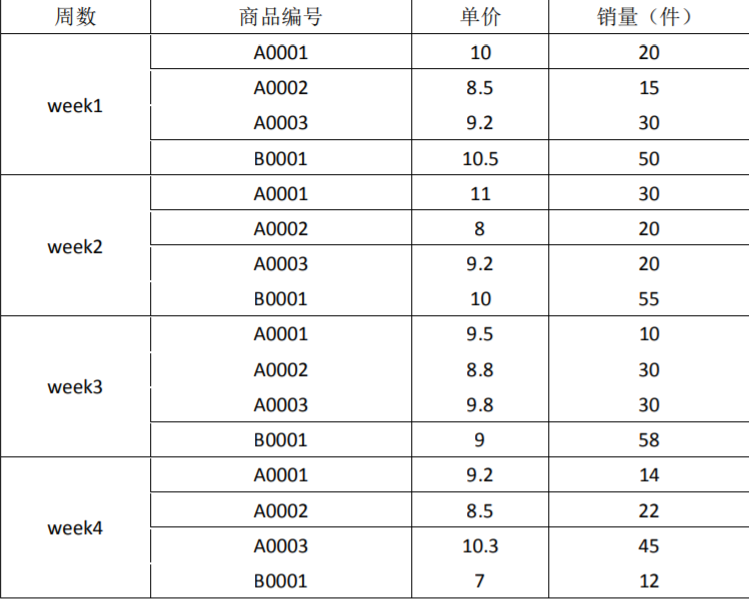
要求:根据以上数据,用 MapReduce 统计出如下数据:
1、每种商品的销售总金额,并降序排序
2、每种商品销售额最多的三周
第二题:MapReduce 题
现有如下数据文件需要处理:
格式:CSV
数据样例:
user_a,location_a,2018-01-01 08:00:00,60
user_a,location_a,2018-01-01 09:00:00,60
user_a,location_b,2018-01-01 10:00:00,60
user_a,location_a,2018-01-01 11:00:00,60
字段:用户 ID,位置 ID,开始时间,停留时长(分钟)
数据意义:某个用户在某个位置从某个时刻开始停留了多长时间
处理逻辑: 对同一个用户,在同一个位置,连续的多条记录进行合并
合并原则:开始时间取最早的,停留时长加和
要求:请编写 MapReduce 程序实现
其他:只有数据样例,没有数据。
UserLocationMR.java
/**
测试数据:
user_a location_a 2018-01-01 08:00:00 60
user_a location_a 2018-01-01 09:00:00 60
user_a location_a 2018-01-01 11:00:00 60
user_a location_a 2018-01-01 12:00:00 60
user_a location_b 2018-01-01 10:00:00 60
user_a location_c 2018-01-01 08:00:00 60
user_a location_c 2018-01-01 09:00:00 60
user_a location_c 2018-01-01 10:00:00 60
user_b location_a 2018-01-01 15:00:00 60
user_b location_a 2018-01-01 16:00:00 60
user_b location_a 2018-01-01 18:00:00 60 结果数据:
user_a location_a 2018-01-01 08:00:00 120
user_a location_a 2018-01-01 11:00:00 120
user_a location_b 2018-01-01 10:00:00 60
user_a location_c 2018-01-01 08:00:00 180
user_b location_a 2018-01-01 15:00:00 120
user_b location_a 2018-01-01 18:00:00 60 */
public class UserLocationMR { public static void main(String[] args) throws Exception {
// 指定hdfs相关的参数
Configuration conf = new Configuration();
// conf.set("fs.defaultFS", "hdfs://hadoop02:9000");
// System.setProperty("HADOOP_USER_NAME", "hadoop"); Job job = Job.getInstance(conf);
// 设置jar包所在路径
job.setJarByClass(UserLocationMR.class); // 指定mapper类和reducer类
job.setMapperClass(UserLocationMRMapper.class);
job.setReducerClass(UserLocationMRReducer.class); // 指定maptask的输出类型
job.setMapOutputKeyClass(UserLocation.class);
job.setMapOutputValueClass(NullWritable.class);
// 指定reducetask的输出类型
job.setOutputKeyClass(UserLocation.class);
job.setOutputValueClass(NullWritable.class); job.setGroupingComparatorClass(UserLocationGC.class); // 指定该mapreduce程序数据的输入和输出路径
Path inputPath = new Path("D:\\武文\\second\\input");
Path outputPath = new Path("D:\\武文\\second\\output2");
FileSystem fs = FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath); // 最后提交任务
boolean waitForCompletion = job.waitForCompletion(true);
System.exit(waitForCompletion ? 0 : 1);
} private static class UserLocationMRMapper extends Mapper<LongWritable, Text, UserLocation, NullWritable> { UserLocation outKey = new UserLocation(); /**
* value = user_a,location_a,2018-01-01 12:00:00,60
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] split = value.toString().split(","); outKey.set(split); context.write(outKey, NullWritable.get());
}
} private static class UserLocationMRReducer extends Reducer<UserLocation, NullWritable, UserLocation, NullWritable> { SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); UserLocation outKey = new UserLocation(); /**
* user_a location_a 2018-01-01 08:00:00 60
* user_a location_a 2018-01-01 09:00:00 60
* user_a location_a 2018-01-01 11:00:00 60
* user_a location_a 2018-01-01 12:00:00 60
*/
@Override
protected void reduce(UserLocation key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { int count = 0;
for (NullWritable nvl : values) {
count++;
// 如果是这一组key-value中的第一个元素时,直接赋值给outKey对象。基础对象
if (count == 1) {
// 复制值
outKey.set(key);
} else { // 有可能连续,有可能不连续, 连续则继续变量, 否则输出
long current_timestamp = 0;
long last_timestamp = 0;
try {
// 这是新遍历出来的记录的时间戳
current_timestamp = sdf.parse(key.getTime()).getTime();
// 这是上一条记录的时间戳 和 停留时间之和
last_timestamp = sdf.parse(outKey.getTime()).getTime() + outKey.getDuration() * 60 * 1000;
} catch (ParseException e) {
e.printStackTrace();
} // 如果相等,证明是连续记录,所以合并
if (current_timestamp == last_timestamp) { outKey.setDuration(outKey.getDuration() + key.getDuration()); } else { // 先输出上一条记录
context.write(outKey, nvl); // 然后再次记录当前遍历到的这一条记录
outKey.set(key);
}
}
}
// 最后无论如何,还得输出最后一次
context.write(outKey, NullWritable.get());
}
}
}
UserLocation.java
public class UserLocation implements WritableComparable<UserLocation> {
private String userid;
private String locationid;
private String time;
private long duration;
@Override
public String toString() {
return userid + "\t" + locationid + "\t" + time + "\t" + duration;
}
public UserLocation() {
super();
}
public void set(String[] split){
this.setUserid(split[0]);
this.setLocationid(split[1]);
this.setTime(split[2]);
this.setDuration(Long.parseLong(split[3]));
}
public void set(UserLocation ul){
this.setUserid(ul.getUserid());
this.setLocationid(ul.getLocationid());
this.setTime(ul.getTime());
this.setDuration(ul.getDuration());
}
public UserLocation(String userid, String locationid, String time, long duration) {
super();
this.userid = userid;
this.locationid = locationid;
this.time = time;
this.duration = duration;
}
public String getUserid() {
return userid;
}
public void setUserid(String userid) {
this.userid = userid;
}
public String getLocationid() {
return locationid;
}
public void setLocationid(String locationid) {
this.locationid = locationid;
}
public String getTime() {
return time;
}
public void setTime(String time) {
this.time = time;
}
public long getDuration() {
return duration;
}
public void setDuration(long duration) {
this.duration = duration;
}
@Override
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeUTF(userid);
out.writeUTF(locationid);
out.writeUTF(time);
out.writeLong(duration);
}
@Override
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
this.userid = in.readUTF();
this.locationid = in.readUTF();
this.time = in.readUTF();
this.duration = in.readLong();
}
/**
* 排序规则
*
* 按照 userid locationid 和 time 排序 都是 升序
*/
@Override
public int compareTo(UserLocation o) {
int diff_userid = o.getUserid().compareTo(this.getUserid());
if(diff_userid == 0){
int diff_location = o.getLocationid().compareTo(this.getLocationid());
if(diff_location == 0){
int diff_time = o.getTime().compareTo(this.getTime());
if(diff_time == 0){
return 0;
}else{
return diff_time > 0 ? -1 : 1;
}
}else{
return diff_location > 0 ? -1 : 1;
}
}else{
return diff_userid > 0 ? -1 : 1;
}
}
}
UserLocationGC.java
public class UserLocationGC extends WritableComparator{
public UserLocationGC(){
super(UserLocation.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
UserLocation ul_a = (UserLocation)a;
UserLocation ul_b = (UserLocation)b;
int diff_userid = ul_a.getUserid().compareTo(ul_b.getUserid());
if(diff_userid == 0){
int diff_location = ul_a.getLocationid().compareTo(ul_b.getLocationid());
if(diff_location == 0){
return 0;
}else{
return diff_location > 0 ? -1 : 1;
}
}else{
return diff_userid > 0 ? -1 : 1;
}
}
}
第三题:MapReduce 题--倒排索引
概念: 倒排索引(Inverted Index),也常被称为反向索引、置入档案或反向档案,是一种索引方法, 被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档 检索系统中最常用的数据结构。了解详情可自行百度
有两份数据:
mapreduce-4-1.txt
huangbo love xuzheng
huangxiaoming love baby huangxiaoming love yangmi
liangchaowei love liujialing
huangxiaoming xuzheng huangbo wangbaoqiang
mapreduce-4-2.txt
hello huangbo
hello xuzheng
hello huangxiaoming
题目一:编写 MapReduce 求出以下格式的结果数据:统计每个关键词在每个文档中当中的 第几行出现了多少次 例如,huangxiaoming 关键词的格式:
huangixaoming mapreduce-4-1.txt:2,2; mapreduce-4-1.txt:4,1;mapreduce-4-2.txt:3,1
以上答案的意义:
关键词 huangxiaoming 在第一份文档 mapreduce-4-1.txt 中的第 2 行出现了 2 次
关键词 huangxiaoming 在第一份文档 mapreduce-4-1.txt 中的第 4 行出现了 1 次
关键词 huangxiaoming 在第二份文档 mapreduce-4-2.txt 中的第 3 行出现了 1 次
题目二:编写 MapReduce 程序求出每个关键词在每个文档出现了多少次,并且按照出现次 数降序排序
例如:
huangixaoming mapreduce-4-1.txt,3;mapreduce-4-2.txt,1
以上答案的含义: 表示关键词 huangxiaoming 在第一份文档 mapreduce-4-1.txt 中出现了 3 次,在第二份文档mapreduce-4-2.txt 中出现了 1 次
Hadoop学习之路(二十七)MapReduce的API使用(四)的更多相关文章
- Hadoop学习之路(十七)MapReduce框架Partitoner分区
Partitioner分区类的作用是什么? 在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,比如按照省份划分的话,需要把同一省份的数据放到一个文件中:按照性别划分的话,需要 ...
- 【Hadoop学习之十二】MapReduce案例分析四-TF-IDF
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 概念TF-IDF(term fre ...
- 嵌入式Linux驱动学习之路(二十七)字符设备驱动的另一种写法
之前讲的字符设备驱动程序,只要有一个主设备号,那么次设备号无论是什么都会和同一个 struct file_operations 结构体对应. 而本节课讲的是如何在设备号相同的情况下,让不同的次设备号对 ...
- Hadoop学习记录(4)|MapReduce原理|API操作使用
MapReduce概念 MapReduce是一种分布式计算模型,由谷歌提出,主要用于搜索领域,解决海量数据计算问题. MR由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce( ...
- hadoop学习记录(二)HDFS java api
FSDateinputStream 对象 FileSystem对象中的open()方法返回的是FSDateInputStream对象,改类继承了java.io.DateInoutStream接口.支持 ...
- Hadoop学习之路(十)HDFS API的使用
HDFS API的高级编程 HDFS的API就两个:FileSystem 和Configuration 1.文件的上传和下载 package com.ghgj.hdfs.api; import org ...
- Hadoop学习之旅三:MapReduce
MapReduce编程模型 在Google的一篇重要的论文MapReduce: Simplified Data Processing on Large Clusters中提到,Google公司有大量的 ...
- 阿里封神谈hadoop学习之路
阿里封神谈hadoop学习之路 封神 2016-04-14 16:03:51 浏览3283 评论3 发表于: 阿里云E-MapReduce >> 开源大数据周刊 hadoop 学生 s ...
- 《Hadoop学习之路》学习实践
(实践机器:blog-bench) 本文用作博文<Hadoop学习之路>实践过程中遇到的问题记录. 本文所学习的博文为博主“扎心了,老铁” 博文记录.参考链接https://www.cnb ...
- Java web与web gis学习笔记(二)——百度地图API调用
系列链接: Java web与web gis学习笔记(一)--Tomcat环境搭建 Java web与web gis学习笔记(二)--百度地图API调用 JavaWeb和WebGIS学习笔记(三)-- ...
随机推荐
- 高并发系列之——MQ消息中间件Kafka
1.前言 1.1 包路径和源码 下载链接 基于发布订阅的分布式消息系统,使用scala语言编写. 特点:采用分区机制,每个分区可以放到不同的服务器上,提高了吞吐率,同时基于磁盘存储,以及副本机制可以确 ...
- 【SSH网上商城项目实战01】整合Struts2、Hibernate4.3和Spring4.2
转自:https://blog.csdn.net/eson_15/article/details/51277324 今天开始做一个网上商城的项目,首先从搭建环境开始,一步步整合S2SH.这篇博文主要总 ...
- LeetCode SQL: Second Highest Salary
, NULL, salary) as `salary` from ( ,) tmp Write a SQL query to get the second highest salary from th ...
- Java 基础:数组
一.数组声明: int[] x; int x[]; 在Java中一般使用前者,机把int[]看做一个类型,C++中只能后者 二.数组初始化: 直接提供值: int[] x = {1, 3, 4}; i ...
- PyCharm导入包的问题
在此之前,我们说一下虚拟环境这个概念: 在django项目中,直接就安装各种package,可能会造成系统混乱,因为package之间会有依赖的.比方说,你现在直接装django,他会依赖其他的包(开 ...
- 探索canvas画布绘制技术
图片来自KrzysztofBanaś 下面我们开始尝试研究不同的绘图风格和技术 - 边缘平滑,贝塞尔曲线,墨水和粉笔,笔和印章和图案 -等等.事实证明,网上没有太多关于此的内容.在下面的示例中,您请大 ...
- drupal 开发笔记
“以前我在开发Java项目的时候,都需要自己设计数据库表结构,数据库表结构的设计关系到一个人开发技能的高低,而在Drupal里面,我们通常是不需要设计数据库表结构,我们要做的是创建新的内容类型,然后为 ...
- 线性表的Java实现--链式存储(单向链表)
单向链表(单链表)是链表的一种,其特点是链表的链接方向是单向的,对链表的访问要通过顺序读取从头部开始. 链式存储结构的线性表将采用一组任意的存储单元存放线性表中的数据元素.由于不需要按顺序存储,链表在 ...
- web测试流程的总结及关注点
项目的测试流程大只包含的几个阶段:立项.需求评审.用例评审.测试执行.测试报告文档 一.立项后测试需要拿到的文档 1.需求说明书 2.原型图(及UI图) 3.接口文档 4.数据库字典(表的数量.缓存机 ...
- VUE知识day2
VUE用途 VUE:是用来做单页面的 掘金网单击时会创建对象与销毁,减少与服务器的交互 1模块使用------------------- 1导出------------ export default ...