使用RequireJS并实现一个自己的模块加载器 (二)
2017 新年好 !
新年第一天对我来说真是悲伤 ,早上兴冲冲地爬起来背着书包跑去实验室,结果今天大家都休息 。回宿舍的时候发现书包湿了,原来盒子装的牛奶盖子松了,泼了一书包,电脑风扇口和USB口都进牛奶了,赶紧拔掉电池,用风扇吹啊吹。强行开机,无线网卡坏掉,屏幕里面进牛奶,难看死啦 ~
鼠标也坏掉了,谁能赠送我一个鼠标啊 ..O...
中午吃完饭,就开始完善模块加载器了。到傍晚,差不多了,出去浪了一会儿 ~
my-Require.js
回顾
在 使用RequireJS 并实现一个自己的RequireJS(一) 中,回顾了 RequireJS 的用法,在这一篇,按照 require.js 的思路实现了一个自己的模块加载器 。
全局变量
首先,需要定义几个全局变量,用来保存已经加载的模块,尚未加载的模块,所有模块等全局信息。
var context = {
topModule: "", //顶层模块
waitings: [], // 尚未加载的模块
loadeds: [], // 已经加载的模块
baseUrl: "",
/**
* 每一个模块都有下面的几个属性
*
* moduleNmae 模块名称
* deps 模块依赖
* factory 模块工厂函数 .
* args 该模块的依赖模块的返回值
* returnValue 该魔铠工厂函数的返回值
*/
modules: [] // 所有模块集合
};
在 waitings 里面记录尚未加载的模块,但是已经插入到head中。
loadeds 记录 已经加载完成的模块。
在每一个script 脚本插入的onload的事件中,在waitings 里面删除模块名,在loadeds 里面添加,如果发现 waitings 为空,那么就开始递归执行工厂函数 。
加载 require 顶层模块
在 my-require.js 里面都是用 data-main 属性来启动 require 模块,所以先寻找 data-main 属性,并插入到 head中 。
这里将 data-main 作为的路径作为 baseUrl ,也可以使用 requirejs.config 来配置
var data_main_src = document.querySelector("[data-main]").getAttribute('data-main');
// data-main 的形式为 app/main,这里 app 作为baseUrl
var lastIndex = data_main_src.lastIndexOf("/");
if (lastIndex === -1) {
context.baseUrl = "./";
} else {
context.baseUrl = data_main_src.subString(0, lastIndex);
}
// 创建顶层节点
var data_main_node = document.createElement('script');
data_main_node.async = true;
document.querySelector('head').appendChild(data_main_node);
data_main_node.src = data_main_src + ".js";
data_main_node.onload = function() {
// 将 顶层模块 从waitings 里面杀出,并添加到 loadeds 数组中。
removeByEle(context.waitings, context.topModule)
context.loadeds.push(context.topModule);
}
这里引出第一个 辅助函数 removeByEle,这个函数用来在数组中删除元素
/**
* [数组根据元素删除元素]
* @param {[array]} arr [原数组]
* @param {[any]} ele [要去除的元素]
*/
function removeByEle(arr, ele) {
var index = arr.indexOf(ele);
if (index === -1) return;
arr.splice(index, 1);
}
定义 require 方法
之后,定义require 方法。
require 方法用来使用模块,也就是定义一个顶层模块,这个模块不需要被其他模块加载 。define 用来定义模块。
require 可以认为是特殊的 define
关于 require 和define 的不同,可以参见这个回答requirejs中define和require的定位以及使用区别?
/**
* [require 方法,使用一个模块]
* @param {[array]} deps [依赖数组]
* @param {[function]} factory [工厂函数]
*/
requirejs.require = function(deps, factory) {
/**
* 如果是 let module = require("module") 这种形式,那么就调用 use 方法。
*/
if (arguments.length === 1 && typeof deps === "string") {
return use(deps);
}
// 生成随机模块名,方法:
// callback+setTimeout("1");
let moduleNmae = "callback" + setTimeout("1");
context.topModule = moduleNmae;
context.waitings.push(moduleNmae);
// 生成一个模块配置
context.modules[moduleNmae] = {
moduleNmae: moduleNmae,
deps: deps,
factory: factory,
args: [],
returnValue: ""
}
// 递归遍历所有依赖,添加到 `head` 中,并设置 这个节点的一个属性`data-module-name`标识模块名。
deps.forEach(function(dep) {
let depPath = context.baseUrl + dep + ".js";
let scriptNode = document.createElement('script');
scriptNode.setAttribute("data-module-name", dep);
scriptNode.async = true;
scriptNode.src = depPath;
context.waitings.push(dep);
document.querySelector('head').appendChild(scriptNode);
scriptNode.onload = scriptOnload;
})
};
// 最后,把这个方法暴露给`window`
window.require = requirejs.require;
这里又引出一个函数, scriptOnload,在script 节点加载完成后触发
`` javascript
/**
* [每一个脚本插入head中,都会执行这个事件 。这是事件完成两件事,
* 1. 如果是一个匿名模块加载,那么取得这个匿名模块,并完成模块命名,
* 2. 当节点加载完毕,判断 waitingss 是否为空,
* 如果不为空,返回,
* 如果为空,说明已经全部加载完毕,现在就可以执行所有的工厂函数]
* @param {[object]} e [事件对象]
*/
function scriptOnload(e) {
e = e || window.event;
let node = e.target;
let modeuleName = node.getAttribute('data-module-name');
tempModule.modeuleName = modeuleName;
context.modules[modeuleName] = tempModule;
removeByEle(context.waitings, modeuleName);
context.loadeds.push(modeuleName);
if (!context.waitings.length) {
exec(context.topModule);
}
}
> 由于在define中,我使用匿名模块 。那么在define 定义一个模块的时候,无法知道模块名 。所以先放在一个`临时模块`寄存。
> 在define 执行结束,会立即触发 `onload` 事件,那么 事件对象 `e` 就必然是这个define 正在定义的模块,就可以使用 ·`data-module-name` 取得真正
> 的模块名,此时进行替换就可以了 。
在看 define 如何定义一个模块
## 定义 define 方法
``` javascript
/**
* [define 和 require 做的工作几乎相同,
* 由于RequireJS 是更推崇匿名模块的,所以这里就没有做命名模块
*
* 实现匿名模块
* 需要在这里用一个临时变量作为 doulename 保存,define 函数执行完毕,就会触发onload 事件,这个事件拿到
* 的script节点对象必然就是这个节点,即将模块名该为正真的名字。]
* @param {[array]} deps [依赖数组]
* @param {[function]} factory [工厂函数]
*/
requirejs.define = function(deps, factory) {
// 注意这里使用一个全局临时模块来标识正在加载的模块,之后来 onload 中替换为正真的模块 。
tempModule = {
deps: deps,
args: [],
returnValue: "",
factory: factory
}
// 这里的逻辑和 require 一样,偷个懒,没有封装
deps.forEach(function(dep) {
var script = document.createElement("script");
script.setAttribute("data-module-name", dep);
script.async = true;
script.src = baseUrl + dep + ".js";
document.querySelector("head").appendChild(script);
script.onload = scriptNode;
context.waitings.push(dep);
});
};
window.define = requirejs.define;
执行回调
我们再回到 scriptOnload 函数,每个模块加载完成,就会在 waitings 里面去掉,然后检查 waitings 数组,如果为空,说明全部加载完,
就可以执行 exec 函数,在这里函数中,递归执行所有的回调 。
/**
* [所有模块加载完毕,递归执行工程函数 , 核心方法]
* @param {[string]} moduleNmae [模块名]
*/
function exec(moduleNmae) {
let module = context.modules[moduleNmae];
let deps = module.deps;
let args = [];
deps.forEach(function(dep) {
exec(dep);
args.push(context.modules[dep].returnValue);
});
module.args = args;
module.returnValue = context.modules[moduleNmae].factory.apply(context.modules[moduleNmae], args);
}
最后走到这里,就可以发现 my-require 的核心流程了。
先调用 require 函数和define 函数,将所有的依赖转化为script 节点插入到 dom 中,然后在 每一个 节点的 onload 事件中,将模块作为实体保存起来,并检查所有模块是否加载完成,如果加载完成,递归执行所有回调。
补充
最后,补充两个方法
/**
* [ 当 形如 var module = require("module"); 这样时,就是用这个函数,最后再使用 require 重载起来,
* 由于这个函数开始执行,那么所有的模块一定都加载完毕了,此时可以不判断waitingss,直接执行 exec ]
* @param {[string]} 'moduleNmae' [模块名]
* @return {[object]} [模块工厂函数的返回值]
*/
function use(moduleNmae) {
let modeule = context.modules[modeuleName];
exec(modeuleName);
return modeule.returnValue;
}
/**
* 配置模块,这里只简单配置 baseUrl
*/
requirejs.config = function(config) {
this.context.baseUrl = config.baseUrl || baseUrl;
}
测试
昨天太懒啦,没有编写复杂的测试,就简单的写了写,

rect.js
'use strict';
// 这里也是一个需要改进的地方,需要判断,没有没有依赖模块
define([], function () {
return {
getArea: function (length) {
return length * length;
},
getPerimeter: function (length) {
return length * 4;
}
}
})
circle.js
'use strict';
define([], function () {
return {
getArea: function (lenth) {
return Math.PI * length * length;
},
getPerimeter: function (length) {
return length * 2 * Math.PI;
}
}
})
02.js
'use strict';
require(["circle","rect"], function(circle,rect) {
console.log("the area of a Circle having radius 5 is :" + rect.getArea(5));
console.log("the perimeter of a Rect having length 5 is :" + circle.getPerimeter(5));
})
index.html
<body>
<script src="../myrequire.js" data-main="02"></script>
</body>
结果
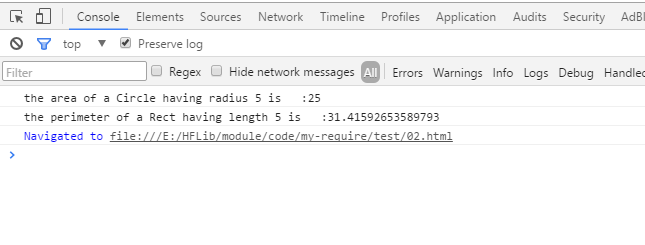
脚本都已经插入到 head 中了

OK
总结
这个图简单地表示了测试程序的流程。(鼠标还在路上,用触摸板画的,太丑了,囧 ...等以后画一个漂亮的换上 。)

这个模块加载器相比于 requirejs还有很多功能没有完成
- 没有实现预加载, 这里
let module = require("module")只能寻找到已经加载的模块。 - 没有实现定义模块时命名
- 缺少很多配置项
但是,基本的功能已经实现了。
使用RequireJS并实现一个自己的模块加载器 (二)的更多相关文章
- 使用RequireJS并实现一个自己的模块加载器 (一)
RequireJS & SeaJS 在 模块化开发 开发以前,都是直接在页面上引入 script 标签来引用脚本的,当项目变得比较复杂,就会带来很多问题. JS项目中的依赖只有通过引入JS的顺 ...
- 实现一个类 RequireJS 的模块加载器 (二)
2017 新年好 ! 新年第一天对我来说真是悲伤 ,早上兴冲冲地爬起来背着书包跑去实验室,结果今天大家都休息 .回宿舍的时候发现书包湿了,原来盒子装的牛奶盖子松了,泼了一书包,电脑风扇口和USB口都进 ...
- 【模块化编程】理解requireJS-实现一个简单的模块加载器
在前文中我们不止一次强调过模块化编程的重要性,以及其可以解决的问题: ① 解决单文件变量命名冲突问题 ② 解决前端多人协作问题 ③ 解决文件依赖问题 ④ 按需加载(这个说法其实很假了) ⑤ ..... ...
- 一个简单的AMD模块加载器
一个简单的AMD模块加载器 参考 https://github.com/JsAaron/NodeJs-Demo/tree/master/require PS Aaron大大的比我的完整 PS 这不是一 ...
- js 简易模块加载器 示例分析
前端模块化 关注前端技术发展的各位亲们,肯定对模块化开发这个名词不陌生.随着前端工程越来越复杂,代码越来越多,模块化成了必不可免的趋势. 各种标准 由于javascript本身并没有制定相关标准(当然 ...
- RequireJS 是一个JavaScript模块加载器
RequireJS 是一个JavaScript模块加载器.它非常适合在浏览器中使用, 它非常适合在浏览器中使用,但它也可以用在其他脚本环境, 就像 Rhino and Node. 使用RequireJ ...
- SeaJS:一个适用于 Web 浏览器端的模块加载器
什么是SeaJS?SeaJS是一款适用于Web浏览器端的模块加载器,它同时又与Node兼容.在SeaJS的世界里,一个文件就是一个模块,所有模块都遵循CMD(Common Module Definit ...
- 构建服务端的AMD/CMD模块加载器
本文原文地址:http://trock.lofter.com/post/117023_1208040 . 引言: 在前端开发领域,相信大家对AMD/CMD规范一定不会陌生,尤其对requireJS. ...
- JavaScript AMD 模块加载器原理与实现
关于前端模块化,玉伯在其博文 前端模块化开发的价值 中有论述,有兴趣的同学可以去阅读一下. 1. 模块加载器 模块加载器目前比较流行的有 Requirejs 和 Seajs.前者遵循 AMD规范,后者 ...
随机推荐
- POJ 3260 The Fewest Coins(多重背包问题, 找零问题, 二次DP)
Q: 既是多重背包, 还是找零问题, 怎么处理? A: 题意理解有误, 店主支付的硬币没有限制, 不占额度, 所以此题不比 1252 难多少 Description Farmer John has g ...
- POJ 1691 Painting a Board(状态压缩DP)
Description The CE digital company has built an Automatic Painting Machine (APM) to paint a flat boa ...
- ios开发之--UICollectionView的使用
最近项目中需要实现一种布局,需要用到UICollectionView,特在此整理记录下! 贴上最终实现的效果图: 1,声明 @interface FirstViewController ()<U ...
- hive的初步认识与hive的本质
Hive是什么?就从这儿开始学习.... Hive是建立在Hadoop hdfs上的数据仓库基础架构. Hive可以用来数据抽取转换加载(ETL). Hive定义了简单的类SQL查询语句,称为HQL. ...
- Keil MDK从未有过的详细使用讲解(转)
这博主关于MDK 的使用的文章,写的得TM的好 TM的实用! 真心收藏! 熟悉Keil C 51的朋友对于Keil MDK上手应该比较容易,毕竟界面是很像的.但ARM内核毕竟不同于51内核,因此无论 ...
- js中hover事件时候的BUG以及解决方法
hover事件是我们在开发前段时候遇到的稀松平常的问题,但是有没有发现会出现有一个BUg,比如,你移动到一个元素上,让它执行一个方法,然后你快速的移入移出的时候,他会进行亮瞎你眼睛的频闪效果,而且跟得 ...
- ios 图片处理( 1.按比例缩放 2.指定宽度按比例缩放
本文转载至 http://blog.sina.com.cn/s/blog_6f29e81f0101tat6.html //按比例缩放,size 是你要把图显示到 多大区域 CGSizeMake(300 ...
- c++中new/operator new/placement new
1. new/delete c++中的new(和对应的delete)是对堆内存进行申请和释放,且两个都不能被重载. 2. operator new/operator delete c++中如果想要实现 ...
- linux常用的一些访问目录
救命三键(Ctrl+Alt+Delete) /var/log 如果是网络服务的问题时,请到 这个目录里头去查阅一下 log file (登录档): /etc/rc.local 修改挂载 ...
- ios开发 点击文本(TextField)输入的时候向上推以及输入之后恢复的动画
1.添加委托UITextFieldDelegate 2. -(BOOL)textFieldShouldReturn:(UITextField *)textField { [textField resi ...