Selenium2+python自动化
一、打开网站
1.第一步:从selenium里面导入webdriver模块
2.打开Firefox浏览器(Ie和Chrome对应下面的)
3.打开百度网址
二、设置休眠
1.由于打开百度网址后,页面加载需要几秒钟,所以最好等到页面加载完成后再继续下一步操作
2.导入time模块,time模块是Python自带的,所以无需下载
3.设置等待时间,单位是秒(s),时间值可以是小数也可以是整数
三、页面刷新
1.有时候页面操作后,数据可能没及时同步,需要重新刷新
2.这里可以模拟刷新页面操作,相当于浏览器输入框后面的刷新按钮
四、前进和后退
1.当在一个浏览器打开两个页面后,想返回上一页面,相当于浏览器左上角的左箭头按钮
2.返回到上一页面后,也可以切换到下一页,相当于浏览器左上角的右箭头按钮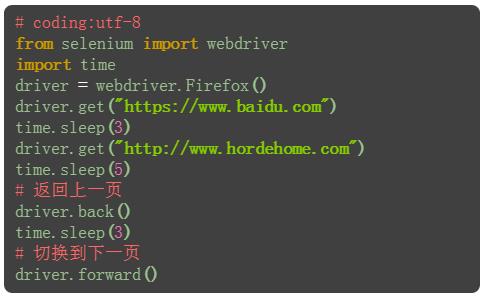
五、设置窗口大小
1.可以设置浏览器窗口大小,如设置窗口大小为手机分辨率540*960
2.也可以最大化窗口
六、截屏
1.打开网站之后,也可以对屏幕截屏
2.截屏后设置制定的保存路径+文件名称+后缀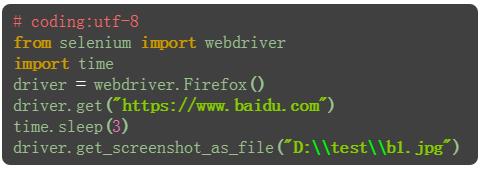
七、退出
1.退出有两种方式,一种是close;另外一种是quit
2.close用于关闭当前窗口,当打开的窗口较多时,就可以用close关闭部分窗口
3.quit用于结束进程,关闭所有的窗口
4.最后结束测试,要用quit。quit可以回收c盘的临时文件
八、基本的元素定位
selenium的webdriver提供了八种基本的元素定位方法,前面六种是通过元素的属性来直接定位的,后面的xpath和css定位更加灵活,需要重点掌握其中一个。
1.通过id定位:find_element_by_id()
2.通过name定位:find_element_by_name()
3.通过class定位:find_element_by_class_name()
4.通过tag定位:find_element_by_tag_name()
5.通过link定位:find_element_by_link_text()
6.通过partial_link定位:find_element_by_partial_link_text()
7.通过xpath定位:find_element_by_xpath()
8.通过css定位:find_element_by_css_selector()
Selenium2+python自动化的更多相关文章
- Selenium2+python自动化23-富文本(自动发帖)
前言 富文本编辑框是做web自动化最常见的场景,有很多小伙伴遇到了不知道无从下手,本篇以博客园的编辑器为例,解决如何定位富文本,输入文本内容 一.加载配置 1.打开博客园写随笔,首先需要登录,这里为了 ...
- Selenium2+python自动化24-js处理富文本(带iframe)
前言 上一篇Selenium2+python自动化23-富文本(自动发帖)解决了富文本上iframe问题,其实没什么特别之处,主要是iframe的切换,本篇讲解通过js的方法处理富文本上iframe的 ...
- Selenium2+python自动化7-xpath定位
前言 在上一篇简单的介绍了用工具查看目标元素的xpath地址,工具查看比较死板,不够灵活,有时候直接复制粘贴会定位不到.这个时候就需要自己手动的去写xpath了,这一篇详细讲解xpath的一些语法. ...
- Selenium2+python自动化13-Alert
不是所有的弹出框都叫alert,在使用alert方法前,先要识别出它到底是不是alert.先认清楚alert长什么样子,下次碰到了,就可以用对应方法解决.alert\confirm\prompt弹出框 ...
- Selenium2+python自动化28-table定位
前言 在web页面中经常会遇到table表格,特别是后台操作页面比较常见.本篇详细讲解table表格如何定位. 一.认识table 1.首先看下table长什么样,如下图,这种网状表格的都是table ...
- Selenium2+python自动化43-判断title(title_is)
From: https://www.cnblogs.com/yoyoketang/p/6539117.html 前言 获取页面title的方法可以直接用driver.title获取到,然后也可以把获取 ...
- Selenium2+python自动化54-unittest生成测试报告(HTMLTestRunner)
前言 批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLT ...
- Selenium2+python自动化61-Chrome您使用的是不受支持的命令行标记:--ignore-certificate-errors
前言 您使用的是不受支持的命令行标记:--ignore-certificate-errors.稳定性和安全性会有所下降 selenium2启动Chrome浏览器是需要安装驱动包的,但是不同的Chrom ...
- Selenium2+python自动化59-数据驱动(ddt)
前言 在设计用例的时候,有些用例只是参数数据的输入不一样,比如登录这个功能,操作过程但是一样的.如果用例重复去写操作过程会增加代码量,对应这种多组数据的测试用例,可以用数据驱动设计模式,一组数据对应一 ...
- Selenium2+python自动化55-unittest之装饰器(@classmethod)
前言 前面讲到unittest里面setUp可以在每次执行用例前执行,这样有效的减少了代码量,但是有个弊端,比如打开浏览器操作,每次执行用例时候都会重新打开,这样就会浪费很多时间. 于是就想是不是可以 ...
随机推荐
- Java Reflect
Method method=demo.getMethod("sayChina"); method.invoke(demo.newInstance()); ...
- 有关查询和执行计划的DMV
转自:http://www.cnblogs.com/CareySon/archive/2012/05/17/2506035.html 查看被缓存的查询计划 SET TRANSACTION ISOLAT ...
- 解决angular-deckgrid高度不均衡和重加载的问题
在项目中使用angular-deckgrid+ng-infinite-scroll实现瀑布流的无限加载.但是实际测试中发现deckgrid有2个比较严重影响体验的BUG: 每次添加新的card,整个d ...
- Apache mod_rewrite
mod_rewrite是Apache的一个非常强大的功能,它可以实现伪静态页面.下面我详细说说它的使用方法!对初学者很有用的哦! 1.检测Apache是否支持mod_rewrite phpinfo() ...
- javascript的ajax功能的概念和示例
AJAX即“Asynchronous Javascript And XML”(异步JavaScript和XML). 个人理解:ajax就是无刷新提交,然后得到返回内容. 对应的不使用ajax时的传统网 ...
- TextBox 控件
TextBox控件上有一个箭头,MultiLine属性,是多行显示 TextBox控件有System.Windows.TextBox类提供,提供了基本的文本输入和编辑功能 属性 A ...
- jQuery事件篇---基础事件
写在前面: 有一段时间未更新博客了,利用这段时间,重新看了<jQuery基础教程 第四版>和<锋利的jQuery 第二版>,这两本书绝对是jQuery入门非常好的书,值得多读几 ...
- 面向对象(基础oop)之结构与数组高级
大家好,我叫李京阳,,很高兴认识大家,之所以我想开一个自己的博客,就是来把自己所了解的知识点通过自己的话写一下,希望被博客园的朋友们点评和一起讨论一下,也希望从博客园中多认识一些软件开发人员!现在我开 ...
- 解决:IDEA 中 new Java Class 怎么没了?
前言:写代码时遇到的问题,所以记录下来.我的包名为“interface”,只有这个包及包下的文件不能建java文件. 问题 解决方式(对于普通包名) 点击应用,ok就可以了. 解决方式(对于包名为“i ...
- 一个简单IOC与DI示例
1.通过bean工厂实现读取xml文件,并实例化对象,实现自动注入. package com.pri.test; import com.pri.factory.BeanFactory; import ...