hadoop学习day1环境配置笔记(非完整流程)
hdfs的工作机制:
1、客户把一个文件存入hdfs,其实hdfs会把这个文件切块后,分散存储在N台linux机器系统中(负责存储文件块的角色:data node)<准确来说:切块的行为是由客户端决定的>
2、一旦文件被切块存储,那么,hdfs中就必须有一个机制,来记录用户的每一个文件的切块信息,及每一块的具体存储机器(负责记录块信息的角色是:name node)
3、为了保证数据的安全性,hdfs可以将每一个文件块在集群中存放多个副本(到底存几个副本,是由当时存入该文件的客户端指定的)
在客户端查看hdfs根目录文件命令
hadoop fs -ls /
如果你只有3个datanode,但是你却指定副本数为4,是不会生效的,因为每个datanode上只能存放一个副本。
修改各台机器的主机名和ip地址
1.创建一个虚拟机。完整克隆3个
2.对三个虚拟机,修改网卡配置:删除eth0的配置,把eth1改为eth0
vi /etc/udev/rules.d/-persistent-net.rules
3.看vmware 网络设置-nat下的网关
4.根据网关设置ip
vi /etc/sysconfig/network-scripts/ifcfg-eth0
删除物理地址:
HWADDR UUID
修改:
ONBOOT=yes
BOOTPROTO=static
IPADDR=192.168.33.**
GATEWAY=192.168.33.1
NETMASK=255.255.255.0
DNS1=192.168.33.1
在虚拟机检测连通性
IFCONFIG
PING网关
修改电脑的vmnet8网关=192.168.33.1 ip=192.168.33.** 掩码
windows ping网关测试
5.在windows中将各台linux机器的主机名配置到的windows的本地域名映射文件中:不用每次访问输ip,改输别名
c:/windows/system32/drivers/etc/hosts
192.168.33.61 hdp-
192.168.33.62 hdp-
192.168.33.63 hdp-
192.168.33.64 hdp-
配置linux服务器的基础软件环境
防火墙
关闭防火墙:service iptables stop
关闭防火墙自启: chkconfig iptables off
配置java
解压jdk
查看path
echo $PATH
在解压后文件夹:
./bin/java 执行java
bin/java 执行java
/bin/java 失败,因为在总的根目录找不到bin/java
在bin目录输入java,command not found 会去path找而不是当前目录
可以在bin目录改输./java 成功执行
1) 配置环境变量:JAVA_HOME PATH
vi /etc/profile 在文件的最后,加入:
export JAVA_HOME=/root/apps/jdk1..0_60 export PATH=$PATH:$JAVA_HOME/bin
2) 修改完成后,记得 source /etc/profile使配置生效
3) 将安装好的jdk目录用scp命令拷贝到其他机器 scp需安装
scp -r apps/ 192.168.33.12:/root/
scp安装 13:00
4) 将/etc/profile配置文件也用scp命令拷贝到其他机器并分别执行source命令
linux命令:jps
可以看到正在执行的所有java进程,jdk自带命令,可以看hadoop node是否执行
ps -ef |grep
查看进程号为2520的详细启动信息
netstat -nltp|grep
查看进程号为2520的占用端口
配置hdp-01到集群中所有机器(包含自己)的免密登陆
>>ssh-keygen >>ssh-copy-id hdp-
>>输密码
>>ssh-copy-id hdp-02
>>输密码
对于 NameNode 和 DataNode 可通过如下Web页面查看其信息:
I. NameNode: http://{NameNodeServer}:50070/
/dfshealth.jsp HDFS信息页面,其中有链接可以查看文件系统
/dfsnodelist.jsp?whatNodes=(DEAD|LIVE) 显示DEAD或LIVE状态的datanode
/fsck 运行fsck命令,不推荐在集群繁忙时使用!
II. DataNode: http://{DataNodeServer}:50075/
/blockScannerReport 每个datanode都会指定间隔验证块信息
3.X版本需要配置web页面
1.启动hadoop.然后netstat -nltp|grep 50070,如果,没有找到进程,说明没有配置web界面的端口修改hdfs-site,xml中加上如下配置
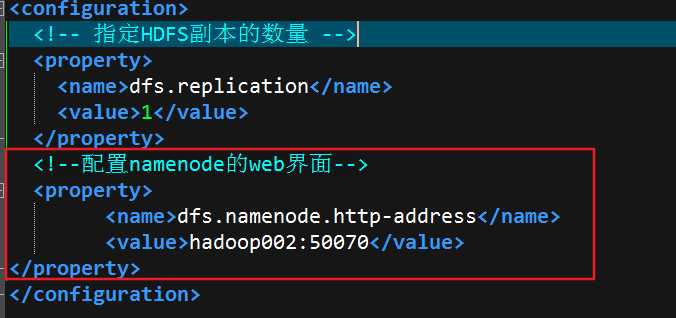
如果你用的主机名:端口号,先去检查下/etc/hosts下的主机名的ip,是否配置的和你当前的ip相同,然后重新启动hadoop
2.现在虚拟机内尝试访问hadoop002:50070,如果访问不了,估计是sellinux的问题执行以下命令setenforce 0(设置为permissive模式)接着重新在虚拟机内访问,此时应该可以正常访问了
3.但是在外部的宿主机内此时无法访问,说明linux的防火墙没有开放50070端口,简单粗暴的方式是把防火墙关掉sudo service iptables stop还有一种方式就是修改防火墙的配置文件开放50070端口执行以下命令
sudo vi /etc/sysconfig/iptables,加上这么一行-I INPUT -m state --state NEW -m tcp -p tcp --dport 50070 -j ACCEPT
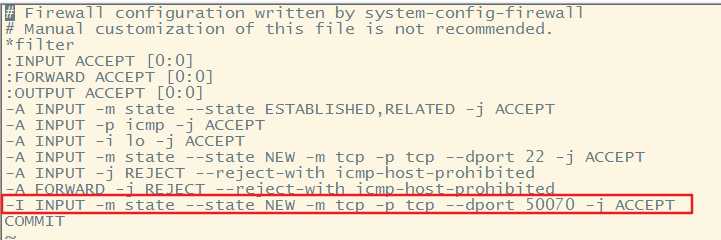
修改完成后sudo service iptables restart重启防火墙服务
4.这个时候在宿主浏览器中输入主机名:端口即可访问,如果还访问不了,去修改下宿主机的hosts文件C:\Windows\System32\drivers\etc\hosts中的ip,保持和虚拟机中的主机ip一致然后重新访问即可
ll -h
查看当前目录文件 同时显示大小kb,mb,gb
hdfs的客户端会读以下两个参数,来决定切块大小、副本数量:
切块大小的参数: dfs.blocksize
副本数量的参数: dfs.replication
cat blk_23232 >> jdk.tgz
cat blk_23233 >> jdk.tgz
hadoop hdfs的块文件合并就是原始文件
cat file1 >> file2的意思是把 file1 的文档内容输入file2 这个文档里。
hdfs客户端的常用操作命令
1、上传文件到hdfs中
hadoop fs -put /本地文件 /aaa
2、下载文件到客户端本地磁盘
hadoop fs -get /hdfs中的路径 /本地磁盘目录
3、在hdfs中创建文件夹
hadoop fs -mkdir -p /aaa/xxx
4、移动hdfs中的文件(更名)
hadoop fs -mv /hdfs的路径1 /hdfs的另一个路径2
复制hdfs中的文件到hdfs的另一个目录
hadoop fs -cp /hdfs路径_1 /hdfs路径_2
5、删除hdfs中的文件或文件夹
hadoop fs -rm -r /aaa
6、查看hdfs中的文本文件内容
hadoop fs -cat /demo.txt
hadoop fs -tail -f /demo.txt 查看尾部20行
Junit Test中注解
JUnit4使用Java5中的注解(annotation),以下是JUnit4常用的几个annotation:
@Before:初始化方法 对于每一个测试方法都要执行一次(注意与BeforeClass区别,后者是对于所有方法执行一次)
@After:释放资源 对于每一个测试方法都要执行一次(注意与AfterClass区别,后者是对于所有方法执行一次)
@Test:测试方法,在这里可以测试期望异常和超时时间
@Test(expected=ArithmeticException.class)检查被测方法是否抛出ArithmeticException异常
@Ignore:忽略的测试方法
@BeforeClass:针对所有测试,只执行一次,且必须为static void
@AfterClass:针对所有测试,只执行一次,且必须为static void
一个JUnit4的单元测试用例执行顺序为:
@BeforeClass -> @Before -> @Test -> @After -> @AfterClass;
每一个测试方法的调用顺序为:
@Before -> @Test -> @After;
java写hadoop程序,从hdfs下载文件需要在windows下配置环境变量HADOOP_HOME,因为下载要用到hadoop里面的包,hadoop windows需要自己编译,得有winutils才行,某些版本在github可以下载
https://github.com/steveloughran/winutils
hadoop学习day1环境配置笔记(非完整流程)的更多相关文章
- CentOS6.5环境配置笔记
CentOS6.5环境配置笔记 一.概述 服务器系统重装,配置应用运行环境 CentOS6.5 x64 二.修改密码 重新设置登录密码 $passwd 或 $passwd root 三.配置端口号及防 ...
- 深度学习主机环境配置: Ubuntu16.04+GeForce GTX 1080+TensorFlow
接上文<深度学习主机环境配置: Ubuntu16.04+Nvidia GTX 1080+CUDA8.0>,我们继续来安装 TensorFlow,使其支持GeForce GTX 1080显卡 ...
- 基于Eclipse的Hadoop应用开发环境配置
基于Eclipse的Hadoop应用开发环境配置 我的开发环境: 操作系统ubuntu11.10 单机模式 Hadoop版本:hadoop-0.20.1 Eclipse版本:eclipse-java- ...
- 深度学习主机环境配置: Ubuntu16.04 + GeForce GTX 1070 + CUDA8.0 + cuDNN5.1 + TensorFlow
深度学习主机环境配置: Ubuntu16.04 + GeForce GTX 1070 + CUDA8.0 + cuDNN5.1 + TensorFlow 最近在公司做深度学习相关的学习和实验,原来一直 ...
- 1 python学习——python环境配置
1 python学习--python环境配置 要学习python语言,光看书看教程还是不好,得动手去写.当然,不管学习什么编程语言,最佳的方式还在于实践. 要实践,先得有一个Python解释器来解释执 ...
- (转)深度学习主机环境配置: Ubuntu16.04+Nvidia GTX 1080+CUDA8.0
深度学习主机环境配置: Ubuntu16.04+Nvidia GTX 1080+CUDA8.0 发表于2016年07月15号由52nlp 接上文<深度学习主机攒机小记>,这台GTX10 ...
- Hadoop:Hadoop简介及环境配置
http://blog.csdn.net/pipisorry/article/details/51243805 Hadoop简介 下次写上... 皮皮blog 配置hadoop环境可能出现的问题 每次 ...
- Ubuntu虚拟机+ROS+Android开发环境配置笔记
Ubuntu虚拟机+ROS+Android开发环境配置笔记 虚拟机设置: 1.本地环境:Windows 7:VMWare:联网 2.虚拟环境 :Ubuntu 14.04. 比較稳定,且支持非常多ROS ...
- 深度学习主机环境配置: Ubuntu16.04+Nvidia GTX 1080+CUDA8.0
不多说,直接上干货! 深度学习主机环境配置: Ubuntu16.04+Nvidia GTX 1080+CUDA8.0
随机推荐
- Java网络编程学习A轮_03_抓包分析TCP四次挥手
参考资料: http://www.jellythink.com/archives/705 示例代码: https://github.com/gordonklg/study,socket module ...
- 在x86为arm 编译 httpd 2.2.31
这个版本的httpd 已经自带 apr apr-util pcre , 不用额外下载源代码 1) 编写环境变量脚本,并执行 cross-env.sh : export ARMROOTFS=/h1roo ...
- ElasticSearch安装和head插件安装
本文主要介绍elasticsearch5.0安装及head插件安装.确保系统已经安装好jdk1.8以上,操作系统CentOS6以上. 一.elasticsearch安装配置 1.官网下载源码包 下载不 ...
- Java实现时钟小程序【代码】
哎,好久没上博客园发东西了,上一次还是两个月前的五一写的一篇计算器博客,不过意外的是那个程序成了这学期的Java大作业,所以后来稍微改了一下那个程序就交了上去,这还是美滋滋.然后五月中旬的时候写了一个 ...
- UVA-10570 Meeting with Aliens (枚举+贪心)
题目大意:将一个1~n的环形排列变成升序的,最少需要几次操作?每次操作可以交换任意两个数字. 题目分析:枚举出1的位置.贪心策略:每次操作都保证至少一个数字交换到正确位置上. # include< ...
- 201621123010《Java程序设计》第8周学习总结
1. 本周学习总结 以你喜欢的方式(思维导图或其他)归纳总结集合相关内容. 2. 书面作业 1. ArrayList代码分析 1.1 解释ArrayList的contains源代码 答:如图,可见co ...
- Java例子
1. 本章学习总结 今天主要学习了三个知识点 封装 继承 多态 2. 书面作业 Q1. java HelloWorld命令中,HelloWorld这个参数是什么含义? 今天学了一个重要的命令javac ...
- 20181009-5 选题 Scrum立会报告+燃尽图 04
Scrum立会报告+燃尽图(04)选题 此作业要求参见:[https://edu.cnblogs.com/campus/nenu/2018fall/homework/2194] 一.小组介绍 组长:刘 ...
- vue.js 源代码学习笔记 ----- fillter-parse.js
/* @flow */ export function parseFilters (exp: string): string { let inSingle = false let inDouble = ...
- C# ,asp.net 获取当前,相对,绝对路径
一.C#获取当前路径的方法: 1. System.Diagnostics.Process.GetCurrentProcess().MainModule.FileName -获取模块的完整路径. 2. ...