python爬搜狗微信获取指定微信公众号的文章
前言:
之前收藏了一个叫微信公众号的文章爬取,里面用到的模块不错。然而
偏偏报错= =。果断自己写了一个
正文:
第一步爬取搜狗微信搜到的公众号:
http://weixin.sogou.com/weixin?type=1&query=FreeBuf&ie=utf8&s_from=input&_sug_=n&_sug_type_=1&w=01015002&oq=&ri=11&sourceid=sugg&sut=0&sst0=1529673558816&lkt=0%2C0%2C0&p=40040108
将FreeBuf改为自己要搜的公众号
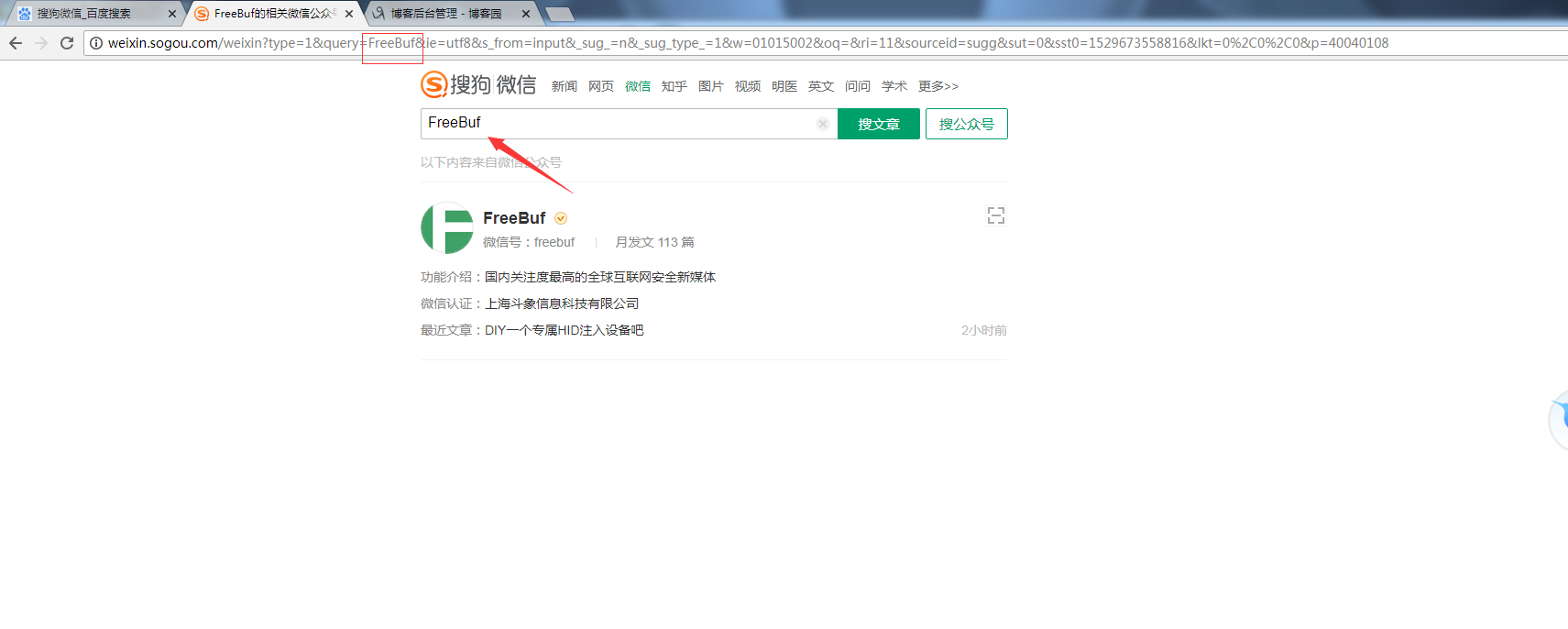
查看网页源代码:

正则匹配:
第一个正则:匹配指定的URL 正则: src=.*&timestamp=.*&ver=.*&signature=.*

蓝色标出来的是我们要的,注意多请求URL可以注意到URL,signature也就是签名是随机变化的。所以可得到正则:.*== ,取第一个,然后打开此链接爬取文章链接即可(更多细节会在代码看到)

代码:
import requests
import re
import threading
user=input('请输入要搜索的微信公众号或微信号:')
headers={'user-agent':'Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)'}
url='http://weixin.sogou.com/weixin?type=1&s_from=input&query={}&ie=utf8&_sug_=y&_sug_type_=&w=01015002&oq=jike&ri=0&sourceid=sugg&stj=0%3B0%3B0%3B0&stj2=0&stj0=0&stj1=0&hp=36&hp1=&sut=4432&sst0=1529305369937&lkt=5%2C1529305367635%2C1529305369835'.format(user.rstrip()) def zhuaqu():
r = requests.get(url=url, headers=headers)
rsw = re.findall('src=.*&timestamp=.*&ver=.*&signature=.*', str(r.text))
if '验证码' in str(r.text):
print('[-]发现验证码请访问URL:{}后在重新运行此脚本'.format(r.url))
exit()
else:
cis = re.findall('.*?==', str(rsw[0]))
qd = "".join(cis)
qd2 = "{}".format(qd)
qd3 = qd2.replace(';', '&')
urls = 'https://mp.weixin.qq.com/profile?'.strip() + qd3
uewq=requests.get(url=urls,headers=headers)
if '验证码' in str(uewq.text):
print('[-]发现验证码请访问URL:{}后在重新运行此脚本'.format(uewq.url))
exit()
else:
ldw = re.findall('src = ".*?" ; ', uewq.text)
ldw2=re.findall('timestamp = ".*?" ; ',uewq.text)
ldw3=re.findall('ver = ".*?" ; ',uewq.text)
ldw4=re.findall('signature = ".*?"',uewq.text)
ldws="".join(ldw)
ldw2s="".join(ldw2)
ldw3s="".join(ldw3)
ldw4s="".join(ldw4)
ldwsjihe=ldws+ldw2s+ldw3s+ldw4s
fk=ldwsjihe.split()
fkchuli="".join(fk)
gs=fkchuli.replace('"','')
hew=gs.replace(';','&')
wanc="http://mp.weixin.qq.com/profile?"+hew
xiau=requests.get(url=wanc,headers=headers)
houxu=re.findall('{.*?}',xiau.content.decode('utf-8'))
title=re.findall('"title":".*?"',str(houxu))
purl=re.findall('"content_url":".*?"',str(houxu))
for i in range(0,len(title)):
jc='{}:{}'.format(title[i],'https://mp.weixin.qq.com'+purl[i]).replace('"','')
jc2=jc.replace('content_url','')
jc3=jc2.replace(';','&')
print(jc3) t=threading.Thread(target=zhuaqu,args=())
t.start()
测试结果:
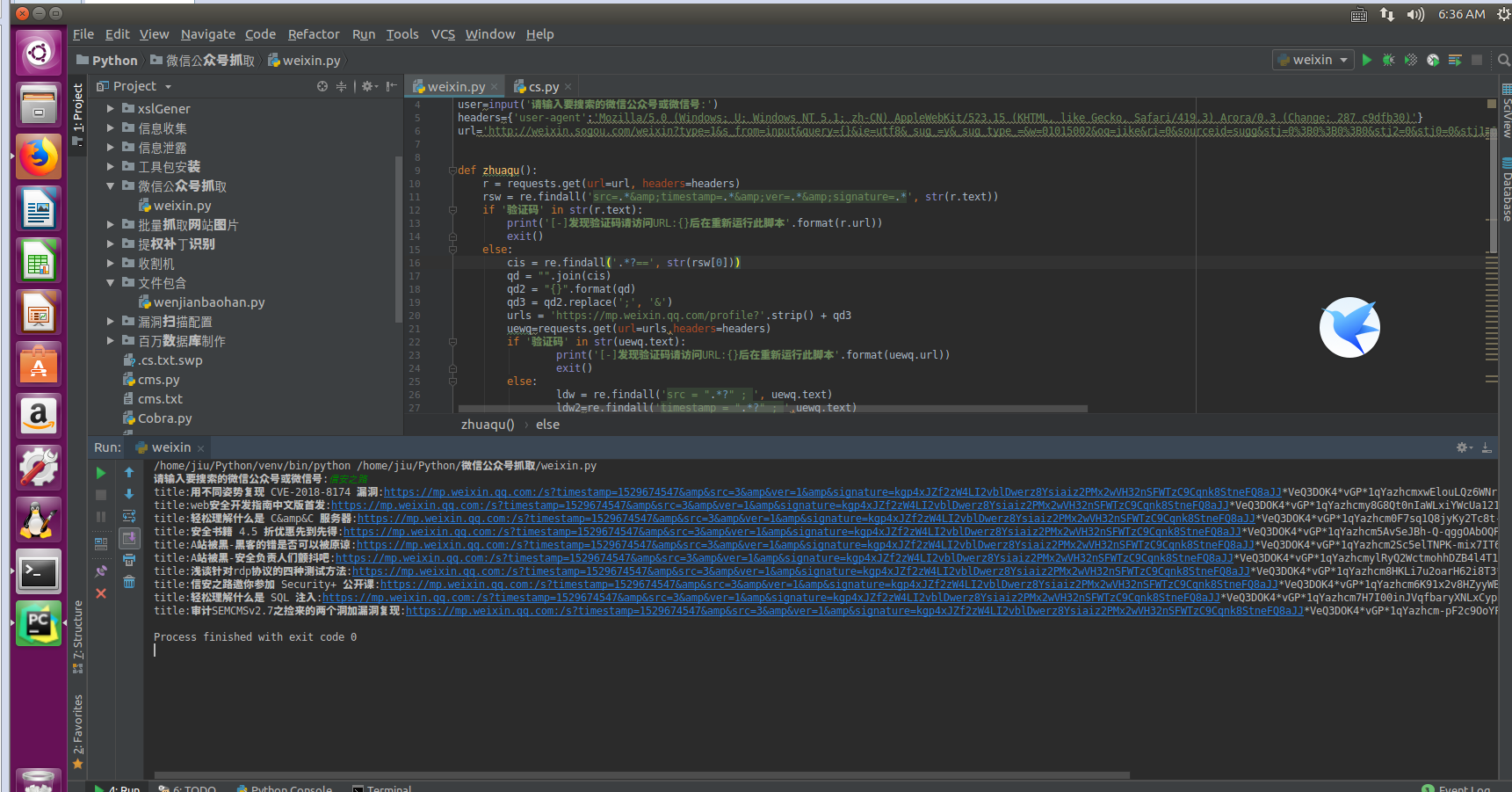

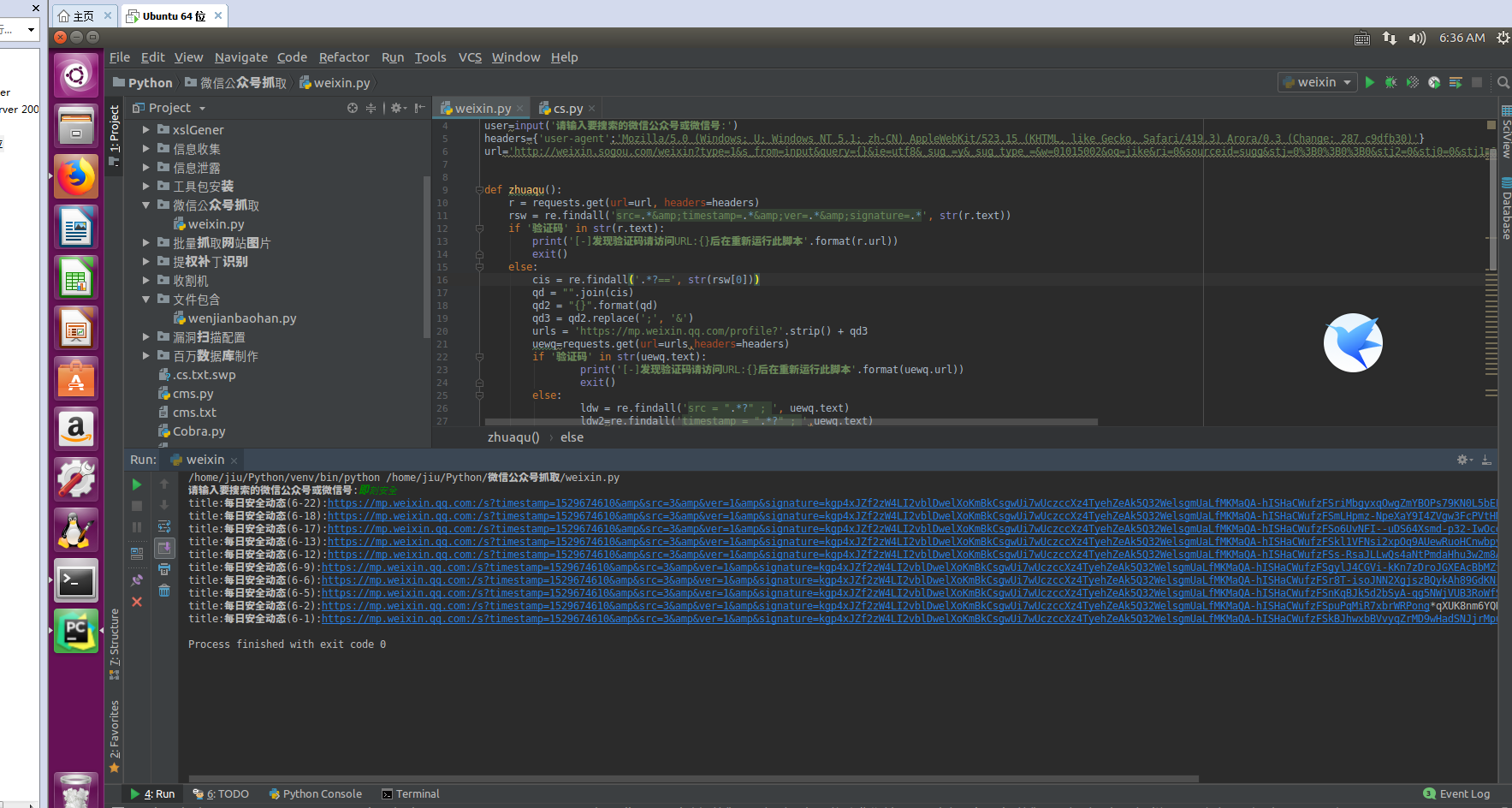

BGM:
python爬搜狗微信获取指定微信公众号的文章的更多相关文章
- Python3 itchat微信获取好友、公众号、群聊的基础信息
Python3 itchat微信获取好友.公众号.群聊的基础信息 一.简介 安装 itchat pip install itchat 使用个人微信的过程当中主要有三种账号需要获取,分别为: 好友 公众 ...
- 50行Python代码,教你获取公众号全部文章
> 本文首发自公众号:python3xxx 爬取公众号的方式常见的有两种 - 通过搜狗搜索去获取,缺点是只能获取最新的十条推送文章 - 通过微信公众号的素材管理,获取公众号文章.缺点是需要申请自 ...
- 微信小程序和公众号和H5之间相互跳转
参考链接:https://www.imooc.com/article/22900 一.小程序和公众号 答案是:可以相互关联. 在微信公众号里可以添加小程序. 可关联已有的小程序或快速创建小程序.已关联 ...
- 微信小程序自运营器 微信小程序自动运营器(让你的微信小程序,公众号零运营成本,24小时全自动运营)
自动发单,自动评价,自动评论,自动推广 微信小程序自运营器 微信小程序自动运营器(让你的微信小程序,公众号零运营成本,24小时全自动运营) 我们会根据你的微信公众号或微信小程序定制开发带有一定AI智 ...
- 微信开发笔记:公众号获取access_token
微信开发中,access_token的获取是一种非常常见的功能,通过公众号的appid和appsecret来向微信公众平台请求一个临时通行凭证:access_token.公众平台上的绝大部分操作都会需 ...
- Chrome获取微信授权,调试公众号页面
1.目的 你可能遇到过这种情况,在微信中打开公众号是这样的. 复制链接,在chrome中打开是这样的. 博主今天要解决的就是,如果在chrome中加载需要微信授权的页面,至于加载成功后要干嘛,测试?抓 ...
- 微信第三方平台开头篇--MVC代码(第三方获取ticket和公众号授权)
微信公众号授权给开放平台 公众号授权给第三方平台的技术实现流程比较简单 这个步骤遗漏了开头获取第三方平台自己的accessToken 先说下流程 如何注册开放平台的第三方信息看截图 其他不说了,此文只 ...
- 微信跳转,网页跳转微信app跳转公众号关注页面[转载]
[微信跳转链接]之跳转公众号关注页面如何做到在微信内部在这里插入代码片浏览器打开的webview页面中,跳转到微信公众号的关注页面呢!我们可以通过访问微信提供的URL协议(weixin://)来实现这 ...
- 用iframe嵌入了一个微信公众号平台文章的URL
JS: $.ajaxPrefilter( function (options) { if (options.crossDomain && jQuery.support.cors) { ...
随机推荐
- Builder(建造者)
意图: 将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示. 适用性: 当创建复杂对象的算法应该独立于该对象的组成部分以及它们的装配方式时. 当构造过程必须允许被构造的对象有不同 ...
- [原][译][osgearth]API加载地球(OE官方文档翻译)
原文参考:http://docs.osgearth.org/en/latest/developer/maps.html#programmatic-map-creation 本人翻译水平有限... 加载 ...
- android 蓝牙通信编程讲解
以下是开发中的几个关键步骤: 1,首先开启蓝牙 2,搜索可用设备 3,创建蓝牙socket,获取输入输出流 4,读取和写入数据 5,断开连接关闭蓝牙 下面是一个demo 效果图: SearchDevi ...
- 【Python】使用codecs模块进行文件操作及消除文件中的BOM
前言 此前遇到过UTF8格式的文件有无BOM的导致的问题,最近在做自动化测试,读写配置文件时又遇到类似的问题,和此前一样,又是折腾了挺久之后,通过工具比较才知道原因. 两次在一个问题上面栽更头,就在想 ...
- GitLab 使用指南(IntelliJ IDEA)
一.环境 GitLab Community Edition 10.6.4 IntelliJ IDEA 2017.03 二.Git 使用 (Linux/MAC,cmd 模式) 本地新建项目(从Git服务 ...
- Android-----购物车(包含侧滑删除,商品筛选,商品增加和减少,价格计算,店铺分类等)
电商项目中常常有购物车这个功能,做个很多项目了,都有不同的界面,选了一个来讲一下. 主要包含了 店铺分类,侧滑删除,商品筛选,增加和减少,价格计算等功能. 看看效果图: 重要代码: private v ...
- MHA-ATLAS-MySQL高可用2
六,配置VIP漂移 主机名 IP地址(NAT) 漂移VIP 描述 mysql-db01 eth0:192.168.0.51 VIP:192.168.0.60 系统:CentOS6.5(6.x都可以) ...
- Alpha发布
作业链接[https://edu.cnblogs.com/campus/nenu/2018fall/homework/2283] 视频展示 链接[https://v.youku.com/v_show/ ...
- 第十一次作业 - Alpha 事后诸葛亮
拖鞋旅游队团队事后诸葛亮会议 前言 队名:拖鞋旅游队 组长博客:https://www.cnblogs.com/Sulumer/p/10054510.html 时间:2018-12-1 20:00 地 ...
- New Concept English Two 28 76
$课文74 舞台之外 784. An ancient bus stopped by a dry river bed and a party of famous actors and actresse ...