scrapy实例matplotlib脚本下载
利用scrapy框架实现matplotlib实例脚本批量下载至本地并进行文件夹分类;话不多说上代码:
首先是爬虫代码:
- import scrapy
- from scrapy.linkextractors import LinkExtractor
- from urllib.parse import urljoin
- from ..items import MatplotlibExamplesItem
- class MatExamplesSpider(scrapy.Spider):
- name = 'mat_examples'
- # allowed_domains = ['matplotlib.org']
- start_urls = ['https://matplotlib.org/gallery/index.html']
- def parse(self, response):
- le = LinkExtractor(restrict_xpaths='//span[contains(@class, "caption-text")]/a[contains(@class, "reference internal")]')
- links = le.extract_links(response)
- for link in links:
- yield scrapy.Request(link.url, callback=self.parse_mat)
- def parse_mat(self, response):
- href = response.xpath('//div[contains(@class, "docutils container")]/a/@href').extract_first()
- # print('href:', href)
- url = response.urljoin(href)
- # print('url:', url)
- example = MatplotlibExamplesItem()
- example['file_urls'] = [url]
- return example
分析代码:
parse函数主要为了获取初始url中的所有实例所在页面的url,通过yield输出scrapy.Request中的callback来调用parse_mat函数,下面继续介绍parse_mat函数的作用;
le = LinkExtractor(restrict_xpaths='//span[contains(@class, "caption-text")]/a[contains(@class, "reference internal")]')
此处代码主要是为了获取单个实例代码所在页面链接,如下图示:
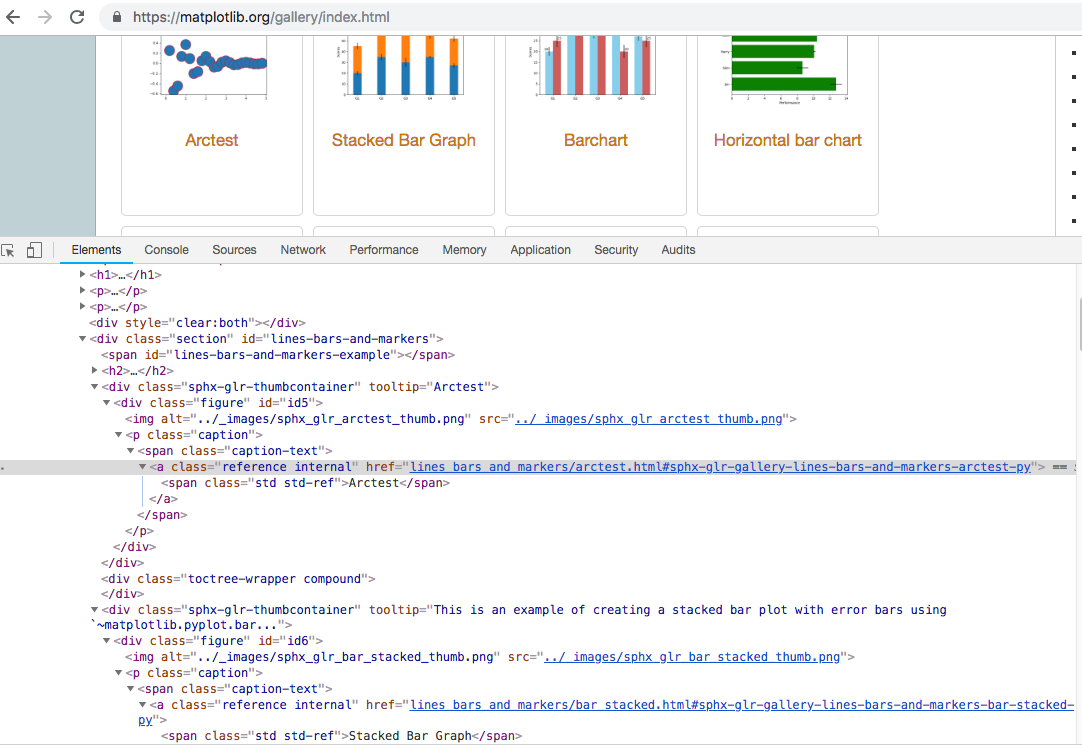
parse_mat函数主要是为了获取每个实例所在的下载链接,并存入item中返回至pipelines中进行下载;
href = response.xpath('//div[contains(@class, "docutils container")]/a/@href').extract_first() ---通过xpath规则获取对应的下载链接;
url = response.urljoin(href) ---通过urljoin方法将链接补全;
example = MatplotlibExamplesItem()
example['file_urls'] = [url] ----存入item中返回
下图为显示下载链接所在页面位置,便于使用xpath规则获取链接;
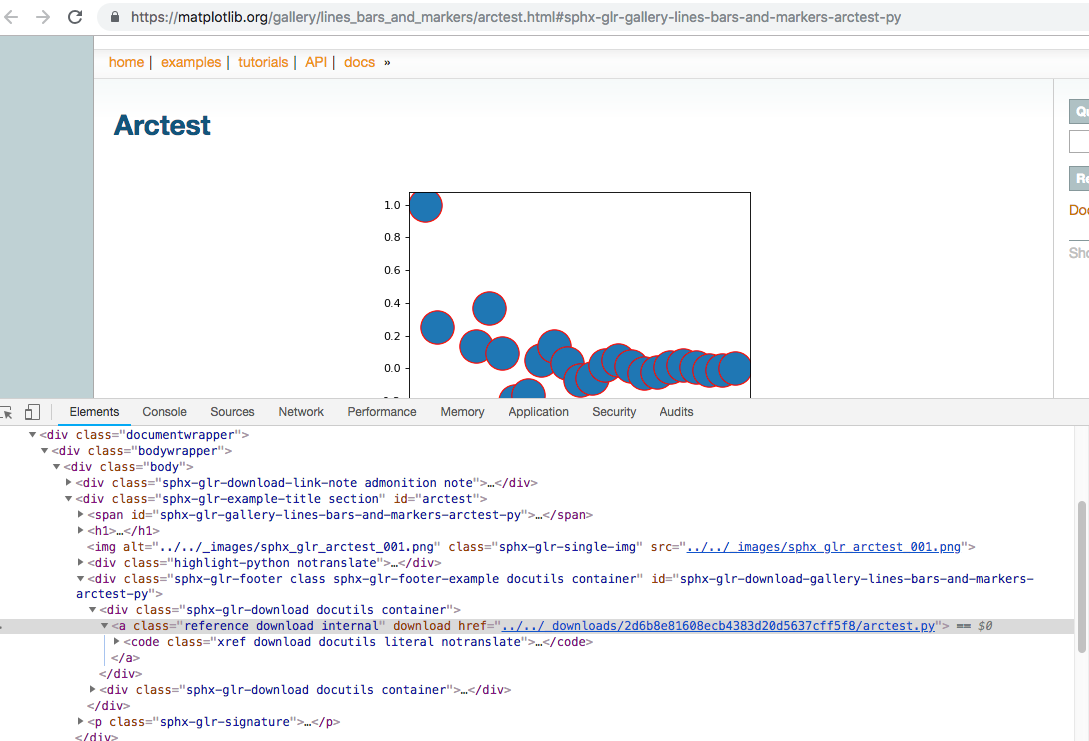
接下来写pipelines代码,具体代码如下:
- from scrapy.pipelines.files import FilesPipeline
- from urllib.parse import urlparse
- from os.path import basename, dirname, join
- class MatplotlibExamplesFilesPipeline(FilesPipeline):
- """docstring for Matploitem, spiderbExamplesFilesPipeline"""
- def file_path(self, request, response=None, info=None):
- # print('rl:', request.url)
- path = urlparse(request.url).path
- print('path', path)
- # return join(basename(dirname(path)), basename(path))
- return join(basename(path).split('.')[0], basename(path))
通过重写file_path方法保存下载文件,至于文件下载的文件或者路径可在setting中配置;
分析代码:
path = urlparse(request.url).path ---通过urlparse方法将url进行分解,以下用实例进行介绍该方法的输出:

实例1:介绍urlparse方法的输出
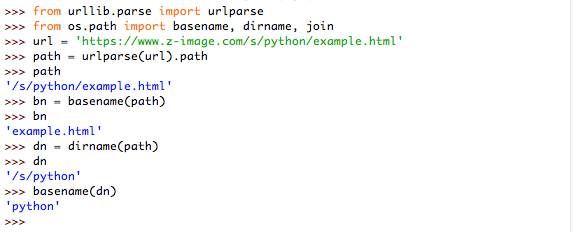
实例2:介绍basename与dirname方法的输出
return join(basename(path).split('.')[0], basename(path))
由于获取的下载链接:https://matplotlib.org/_downloads/2d6b8e81608ecb4383d20d5637cff5f8/arctest.py
所以basename(dirname(path))得到的是一串’2d6b8e81608ecb4383d20d5637cff5f8‘哈希值,于是就直接用basename(path).split('.')[0]为文件夹的名字
接下来写上简单的item的代码(这个代码最简单了,就是写url和file):
- import scrapy
- class MatplotlibExamplesItem(scrapy.Item):
- # define the fields for your item here like:
- # name = scrapy.Field()
- file_urls = scrapy.Field()
- files = scrapy.Field()
最后贴上setting的代码:
- BOT_NAME = 'matplotlib_examples'
- SPIDER_MODULES = ['matplotlib_examples.spiders']
- NEWSPIDER_MODULE = 'matplotlib_examples.spiders'
- ITEM_PIPELINES = {
- # 'scrapy.pipelines.files.FilesPipeline':1,
- 'matplotlib_examples.pipelines.MatplotlibExamplesFilesPipeline':1,
- }
- FILES_STORE = 'result'
- # Obey robots.txt rules
- ROBOTSTXT_OBEY = False
- # Disable cookies (enabled by default)
- COOKIES_ENABLED = False
- # Override the default request headers:
- DEFAULT_REQUEST_HEADERS = {
- 'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
- }
'BOT_NAME' ----爬虫项目名称;一般进行新建scrapy爬虫后都自动写入了;
'ITEM_PIPELINES ' ---此处记得改为自己写的pipelines类名;
'FILES_STORE' ---此处为下载文件所在的文件夹;
其他的配置就基本了;例如是否遵循robots.txt协议,是否用cookies,user-agent改为与浏览器相同,这些都是为了避免被‘ban’;
最后的最后附上项目:
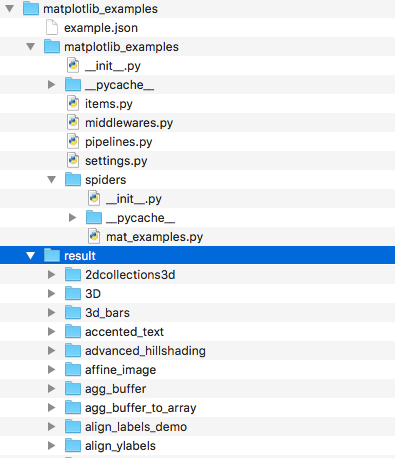
scrapy实例matplotlib脚本下载的更多相关文章
- 爬虫入门六 总结 资料 与Scrapy实例-bibibili番剧信息
title: 爬虫入门六 总结 资料 与Scrapy实例-bibibili番剧信息 date: 2020-03-16 20:00:00 categories: python tags: crawler ...
- 10个提供免费PHP脚本下载的网站
本文将重点介绍10个PHP脚本的免费资源下载站.之前推荐 <16个下载超酷脚本的热门网站>,这些网站除了PHP脚本,还有JavaScript.Java.Perl.ASP等脚本.如果你已是脚 ...
- Python爬虫框架Scrapy实例(三)数据存储到MongoDB
Python爬虫框架Scrapy实例(三)数据存储到MongoDB任务目标:爬取豆瓣电影top250,将数据存储到MongoDB中. items.py文件复制代码# -*- coding: utf-8 ...
- 第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器 编写spiders爬虫文件循环 ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
- python爬虫脚本下载YouTube视频
python爬虫脚本下载YouTube视频 爬虫 python YouTube视频 工作环境: python 2.7.13 pip lxml, 安装 pip install lxml,主要用xpath ...
- 二十 Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
编写spiders爬虫文件循环抓取内容 Request()方法,将指定的url地址添加到下载器下载页面,两个必须参数, 参数: url='url' callback=页面处理函数 使用时需要yield ...
- python脚本下载 Google Driver 文件
使用python脚本下载 Google Driver 文件 import yaml import sys import requests import os import re import tarf ...
- Python爬虫框架Scrapy实例(四)下载中间件设置
还是豆瓣top250爬虫的例子,添加下载中间件,主要是设置动态Uesr-Agent和代理IP Scrapy代理IP.Uesr-Agent的切换都是通过DOWNLOADER_MIDDLEWARES进行控 ...
随机推荐
- BestCoder Round #61 (div.2) C.Subtrees dfs
Subtrees 问题描述 一棵有N个节点的完全二叉树,问有多少种子树所包含的节点数量不同. 输入描述 输入有多组数据,不超过1000组. 每组数据输入一行包含一个整数N.(1\leq N\leq ...
- 并发与并行(concurrency vs parallesim)
最近对计算机中并发(concurrency)和并行(parallesim)这两个词的区别很迷惑,将搜索到的相关内容整理如下. http://www.vaikan.com/docs/Concurrenc ...
- Python3基础复习
目录 基本语法 运算符 输出格式 数据类型 数据结构 函数 面向对象 补充 异常 模块和包 文件 时间 线程和进程 基本语法 基本语法只列举与Java不一样的. 运算符 and, or而非 & ...
- 使用免费SSL证书让网站支持HTTPS访问
参考掘金的文章,掘金的文章最详细. https://juejin.im/post/5a31cbf76fb9a0450b6664ee 先检查是否存在 EPEL 源: # 进入目录检查是否存在 EPEL ...
- 【废弃】【WIP】JavaScript 函数
创建: 2017/10/09 更新: 2017/11/03 加上[wip] 废弃: 2019/02/19 重构此篇.原文归入废弃 增加[废弃中]标签与总体任务 结束: 2019/03/12 完成废弃 ...
- codevs3327选择数字(单调队列优化)
3327 选择数字 时间限制: 1 s 空间限制: 256000 KB 题目等级 : 钻石 Diamond 题目描述 Description 给定一行n个非负整数a[1]..a[n].现 ...
- selenium3 + python - autoit上传文件
一.环境准备: 1.可以autoit官网上下载,安装 http://www.autoitscript.com/site/ 2.AutoIt里面几个菜单功能介绍: SciTE Script Editor ...
- CyclibcBarrier与CountDownLatch区别
1.CyclibcBarrier的线程运行到某个位置后即停止运行,直到所有的线程都到达这个点,所有线程才开始运行:CountDownLatch是线程运行到某个点后,计数器-1,程序继续运行即Cycli ...
- 自己的myeclipse添加javaee7步骤
1 new一个javaee名字,然后add jars 就可以
- 【洛谷4933】大师(DP)
题目: 洛谷4933 分析: (自己瞎yy的DP方程竟然1A了,写篇博客庆祝一下) (以及特斯拉电塔是向Red Alert致敬吗233) 这里只讨论公差不小于\(0\)的情况,小于\(0\)的情况进行 ...