20181012关于mysql内部执行流程
转自:https://www.cnblogs.com/annsshadow/p/5037667.html
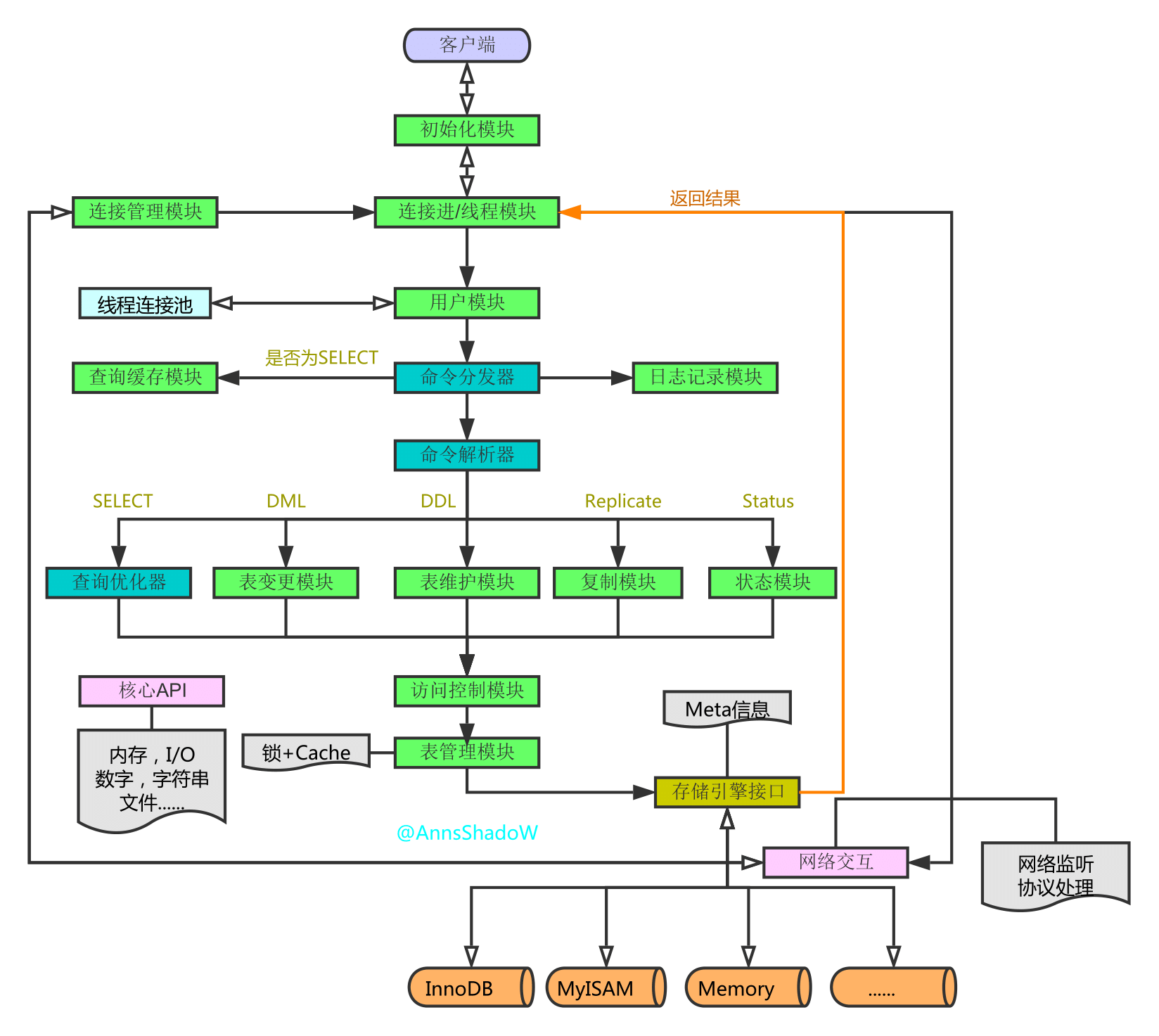
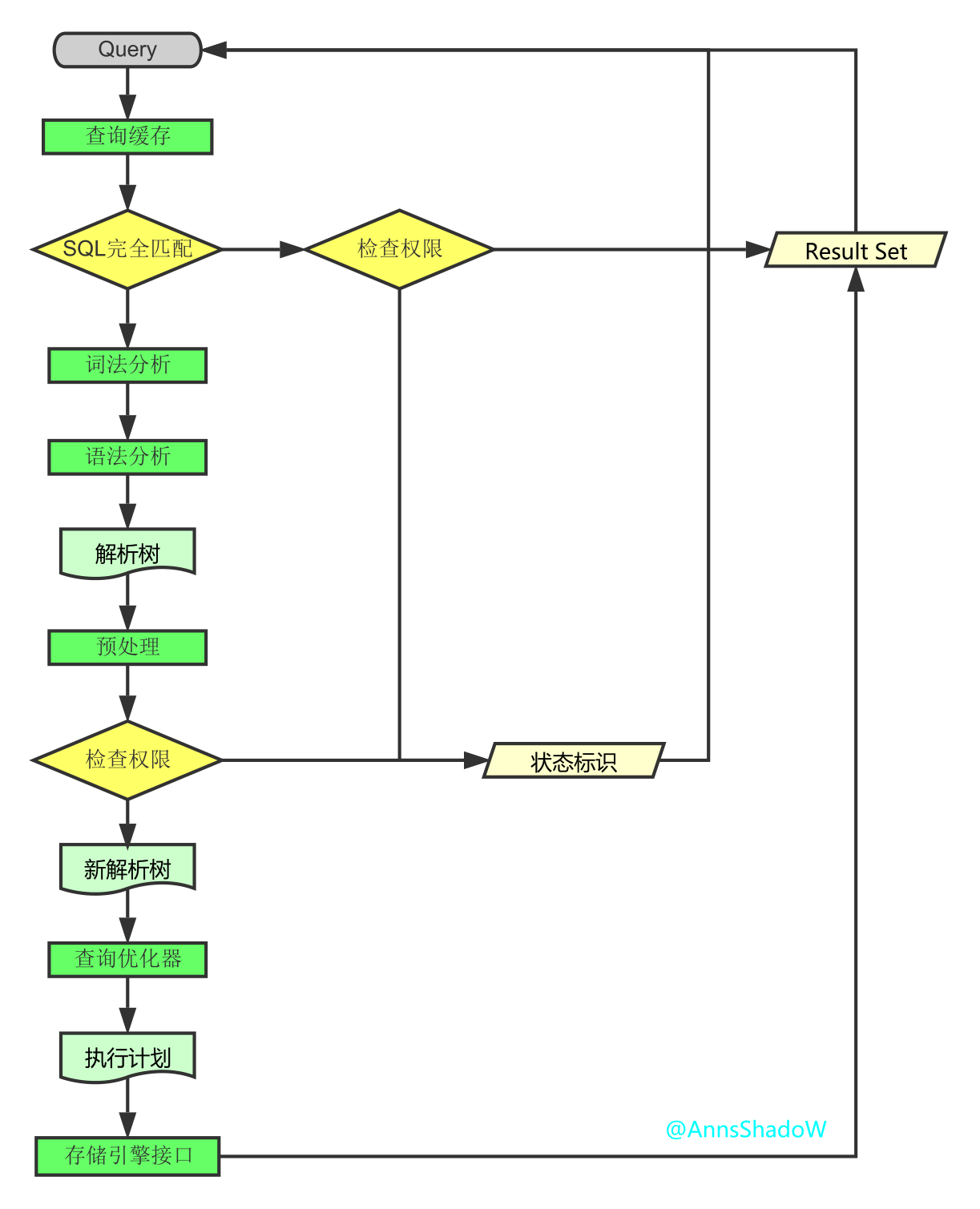
步步深入:MySQL架构总览->查询执行流程->SQL解析顺序

SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT < limit_number >
1 FROM <left_table>
2 ON <join_condition>
3 <join_type> JOIN <right_table>
4 WHERE <where_condition>
5 GROUP BY <group_by_list>
6 HAVING <having_condition>
7 SELECT
8 DISTINCT <select_list>
9 ORDER BY <order_by_condition>
10 LIMIT <limit_number>
create database testQuery
CREATE TABLE table1
(
uid VARCHAR(10) NOT NULL,
name VARCHAR(10) NOT NULL,
PRIMARY KEY(uid)
)ENGINE=INNODB DEFAULT CHARSET=UTF8; CREATE TABLE table2
(
oid INT NOT NULL auto_increment,
uid VARCHAR(10),
PRIMARY KEY(oid)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;
INSERT INTO table1(uid,name) VALUES('aaa','mike'),('bbb','jack'),('ccc','mike'),('ddd','mike');
INSERT INTO table2(uid) VALUES('aaa'),('aaa'),('bbb'),('bbb'),('bbb'),('ccc'),(NULL);
SELECT
a.uid,
count(b.oid) AS total
FROM
table1 AS a
LEFT JOIN table2 AS b ON a.uid = b.uid
WHERE
a. NAME = 'mike'
GROUP BY
a.uid
HAVING
count(b.oid) < 2
ORDER BY
total DESC
LIMIT 1;
mysql> select * from table1,table2;
+-----+------+-----+------+
| uid | name | oid | uid |
+-----+------+-----+------+
| aaa | mike | 1 | aaa |
| bbb | jack | 1 | aaa |
| ccc | mike | 1 | aaa |
| ddd | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 2 | aaa |
| ccc | mike | 2 | aaa |
| ddd | mike | 2 | aaa |
| aaa | mike | 3 | bbb |
| bbb | jack | 3 | bbb |
| ccc | mike | 3 | bbb |
| ddd | mike | 3 | bbb |
| aaa | mike | 4 | bbb |
| bbb | jack | 4 | bbb |
| ccc | mike | 4 | bbb |
| ddd | mike | 4 | bbb |
| aaa | mike | 5 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 5 | bbb |
| ddd | mike | 5 | bbb |
| aaa | mike | 6 | ccc |
| bbb | jack | 6 | ccc |
| ccc | mike | 6 | ccc |
| ddd | mike | 6 | ccc |
| aaa | mike | 7 | NULL |
| bbb | jack | 7 | NULL |
| ccc | mike | 7 | NULL |
| ddd | mike | 7 | NULL |
+-----+------+-----+------+
28 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1,
-> table2
-> WHERE
-> table1.uid = table2.uid
-> ;
+-----+------+-----+------+
| uid | name | oid | uid |
+-----+------+-----+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 3 | bbb |
| bbb | jack | 4 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 6 | ccc |
+-----+------+-----+------+
6 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 3 | bbb |
| bbb | jack | 4 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
7 rows in set (0.00 sec)

mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike';
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
4 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
3 rows in set (0.00 sec)
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
| ddd | 0 |
+-----+-------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2
-> ORDER BY
-> total DESC;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
| ddd | 0 |
+-----+-------+
2 rows in set (0.00 sec)
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2
-> ORDER BY
-> total DESC
-> LIMIT 1;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
+-----+-------+
1 row in set (0.00 sec)

20181012关于mysql内部执行流程的更多相关文章
- MySQL内部执行流程
本文参照自:https://www.cnblogs.com/xiaotengyi/articles/3641983.html mysql处理java传过来的SQL具体步骤: 1.java通过JDBC获 ...
- Mysql漂流系列(一):MySQL的执行流程
MySQL的执行流程 MySQL的执行流程: MySQL的执行流程分析: 1.当我们请求mysql服务器的时候,MySQL前端会有一个监听,请求到了之后,服务器得到相关的SQL语句,执行之前(虚线部分 ...
- [源码分析] 带你梳理 Flink SQL / Table API内部执行流程
[源码分析] 带你梳理 Flink SQL / Table API内部执行流程 目录 [源码分析] 带你梳理 Flink SQL / Table API内部执行流程 0x00 摘要 0x01 Apac ...
- MySQL Update执行流程解读
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 一.update跟踪执行配置 使用内部程序堆栈跟踪工具path_viewer,跟踪mysql update 一行数据的执行 ...
- MySQL之执行流程
最近开始在学习mysql相关知识,自己根据学到的知识点,根据自己的理解整理分享出来,本篇文章会分析下一个sql语句在mysql中的执行流程,包括sql的查询在mysql内部会怎么流转,sql语句的更新 ...
- python学习之内部执行流程,内部执行流程,编码(一)
python的执行流程: 加载内存--->词法分析--->语法分析--->编译--->转换字节码---->转换成机器码---->供给CPU调度 python的编码: ...
- mysql系列二、mysql内部执行过程
向MySQL发送一个请求的时候,MySQL到底做了什么 客户端发送一条查询给服务器. 服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果.否则进入下一阶段. 服务器端进行SQL解析.预 ...
- MySql基础架构以及SQL语句执行流程
01. mysql基础架构 SQL语句是如何执行的 学习一下mysql的基础架构,从一条sql语句是如何执行的来学习. 一般我们写一条查询语句类似下面这样: select user,password ...
- mysql join语句的执行流程是怎么样的
mysql join语句的执行流程是怎么样的 join语句是使用十分频繁的sql语句,同样结果的join语句,写法不同会有非常大的性能差距. select * from t1 straight_joi ...
随机推荐
- org.apache.poi.hssf.util.Region
从POI 3.18开始被Deprecated,在3.20版本中被移除了,所以3.20以前的都有 为了避免这个问题,用CellRangeAddress代替Region,其用法相同
- 微信小程序资源
1.http://blog.csdn.net/wyx100/article/details/52667518 2.http://mp.weixin.qq.com/s?__biz=MzIyMDM2Mjg ...
- Windows环境下使用Netsh命令快速切换IP配置
不同的内网环境需要使用不同的IP配置,频繁切换令人发狂,因此搜索了快速切换IP配置的方法. Netsh interface IP Set address "以太网" Static ...
- Spring Boot (28) actuator与spring-boot-admin
在上一篇中,通过restful api的方式查看信息过于繁琐,也不直观,效率低下.当服务过多的时候看起来就过于麻烦,每个服务都需要调用不同的接口来查看监控信息. SBA SBA全称spring boo ...
- 浏览器的两种模式quirks mode 和strict mode
关键字: javascript.quirks mode.strict mode 在看js代码时,有时会看到关于quirks mode(怪异模式)和strict mode(严格格式)的东西,一直也没深究 ...
- eclipse中添加maven
收藏一下,一篇很好的例子 maven相关插件:链接:http://pan.baidu.com/s/1i3Ks95j 密码:7pgh eclipse:链接:http://pan.baidu.com/s/ ...
- vim之vimrc配置文件
""""""""""""""""&quo ...
- MySql学习笔记(二) —— 正则表达式的使用
前面介绍利用一些关键字搭配相应的SQL语句进行数据库查找过滤,但随着过滤条件的复杂性的增加,where 子句本身的复杂性也会增加.这时我们就可以利用正则表达式来进行匹配查找. 1.基本字符匹配 ' o ...
- 14XML解析
XML解析 XML解析 DOM4J DOM4J是dom4j.org出品的一个开源XML解析包Dom4j是一个易用的.开源的库,用于XML,XPath和XSLT的解析及相关应用.它应用于Java平台,采 ...
- Python基础之简介
参考原文 廖雪峰Python教程 什么是Python? Python是一种计算机程序设计语言,又被称为胶水语言,它是高级的编程语言. Python能干什么? 网站后端程序员.自动化运维.数据分析师.游 ...