Join 和 apply 用法
在关系型数据库系统中,为了满足第三范式(3NF),需要将满足“传递依赖”的表分离成单独的表,通过Join 子句将相关表进行连接,Join子句共有三种类型:外连接,内连接,交叉连接;外连接分为:left join、right join、full join;内链接是:inner join,交叉连接是:cross join。
一,Join子句的组成
Join子句由连接表,连接类型和On子句组成,伪代码如下:
from Left_Table
[inner|left|right|full] join Right_Table
[on condition]
1,根据位置,将参与Join的两个表分为左表和右表
- 在Join子句中,左表和右表进行笛卡尔集合运算,左表中的任意一行都和右表中的所有行进行“组合”,生成虚拟表(Virtual Table),虚拟表的数据行总数Rows(VT)=Rows(left_table)*Rows(right_table);
- 左表和右表进行Join操作,没有先后顺序,这点和Apply子句不同,Apply子句的左表先于右表执行运算;
2,连接类型
在外连接中,left,right和full关键字标识Join子句的"保留表":在进行外连接查询时,保留表中的数据全部返回,不会被on子句过滤。
3,On子句,用于都虚拟表进行过滤
在on子句表达式中,常用的运算符是相等(=),也可以使用不等(>,<>),like等运算符,返回的结果是布尔值;
on子句表达式的操作数,可以是表列(Column),常量,表达式,例如;
- on left_table.column=right_table.column
- on left_table.column=value
- on left_table.column+xx=value
- 不过滤:比如设置on 1=1
4,On子句决定Join的顺序
如果一个查询包含多个Join子句,那么On子句决定Join子句执行的顺序;执行Join的顺序是:tb和tc先执行连接操作,ta和tb后执行连接操作。
from ta
left join tb
left join tc
on tb.column=tc.column
on ta.column=tb.column
5,On子句过滤和Where子句过滤
On子句的执行顺序先于where子句,在进行过滤时,On子句无法过滤保留表,但是where子句能够过滤保留表;
对于inner join,由于没有保留表,所以,在On子句和where子句中进行过滤,结果是一样的,但是,建议明确区分where子句和on子句的职能,on子句用于过滤连接的虚拟表,where用于对最终的结果集进行过滤。
例如:在On子句中,ta.column2=value1 不会过滤左表ta,如果不满足该条件,那么右表相应的数据列设置为NULL,left关键字保证左表中的所有数据行都返回;where子句(ta.column3=value2)过滤左表ta;
from ta
left join tb
on ta.column1=ta.column1
and ta.column2=value1
where ta.column3=value2
二,创建测试代码
create table dbo.ta
(
a int not null,
b int not null
)
go
create table dbo.tb
(
ca int not null,
cb int not null
)
go insert into dbo.ta(a,b)
values(1,1),(2,1)
go insert into dbo.tb(ca,cb)
values(1,1),(3,1)
go
三,left join(左外连接)
1,left join算法
把左表作为保留表,返回左表的全部数据,对于右表中不匹配on子句条件数据行,返回NULL;
select *
from dbo.ta a
left join dbo.tb b
on a.a=b.ca

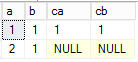
2,使用常量过滤左表
在左外连接中,左表会返回所有数据,对于“and left_table.column=value”,是在第一个条件成立时,对返回的结果进行过滤,而左表数据会全部返回,当不满足条件时,设置右表数据为NULL;
select *
from dbo.ta a
left join dbo.tb b
on a.a=b.ca and a.a=1
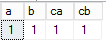
3,使用where子句过滤左表
where子句是对结果集进行过滤的最后一个Filter
select *
from dbo.ta a
left join dbo.tb b
on a.a=b.ca
where a.a=1
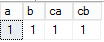
4,使用where子句过滤右表
如果使用where子句对右表进行过滤,一般可以转换成inner join
select *
from dbo.ta a
left join dbo.tb b
on a.a=b.ca
where b.ca=1
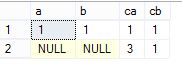
四,right join(右外连接)
right join 算法是把右表作为保留表,将右表中的数据全部显示出来,对于左表中匹配不到的数据行,将其字段值设置为NULL;
select *
from dbo.ta a
right join dbo.tb b
on a.a=b.ca
五,inner join(内连接)
算法是:inner join没有保留表,只返回满足 on 子句条件的数据行,对于不满足on子句条件的数据行,不返回
select *
from dbo.ta a
inner join dbo.tb b
on a.a=b.ca

六,full join(全连接)
算法是:full join 把左表和右表都作为保留表,如果左表和右表中的数据行满足On子句条件,那么显示数据行数据,如果不匹配,则相应的字段设置为null。
select *
from dbo.ta a
full join dbo.tb b
on a.a=b.ca
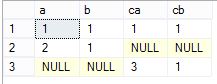
七,cross join(交叉连接)
算法是:cross join 是对左表和游标进行笛卡尔乘积,cross join没有on子句,笛卡尔乘积是将左表中的任意一行数据和右表中的所有数据行进行组合,cross join 将笛卡尔乘积后的结果直接显示出来
select *
from dbo.ta a
cross join dbo.tb b
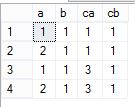
八,自连接用于累积求和
自连接是指一个table 和自己进行join,例如以下语句,表 dbo.ta和自身进行inner join,计算b字段的累积和。
select t1.a,sum(t2.b) as b
from dbo.ta t1
inner join dbo.ta as t2
on t1.a>=t2.a
group by t1.a
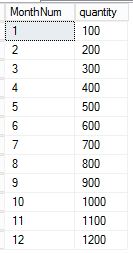
在实际的产品环境中,经常利用自联结进行累加求和的计算,例如有如下一个Table:dbo.FinanceMonth,每个月的产量是Quantity,计算一年内到该月份为止的所有月份的Quantity的累积值。
create table dbo.FinanceMonth
(
MonthNum int not null,
quantity int not null
)
go
;with cte as
(
select 1 as MonthNum,
100 as quantity
union all
select MonthNum+1,quantity+100
from cte
where MonthNum<12
)
insert into dbo.FinanceMonth
select MonthNum, quantity
from cte
使用自链接计算累积值
select a.MonthNum,sum(b.quantity) as TotalQuantity
from dbo.FinanceMonth a
inner join dbo.FinanceMonth b
on a.MonthNum>=b.MonthNum
group by a.MonthNum
order by a.MonthNum

九,apply 用法
1,join和apply的区别
join 子句左表和右表的计算是不分先后的,从性能上考虑,最好把小表作为左表,当右表数据量大的时候,会减少查询的时间消耗。apply子句的左表和右表是区分先后顺序的,apply是先计算左表,后计算右表,因此apply子句不是集合操作语句。如果右表是一个表值函数,apply会先取得左表中的一行记录的值,作为参数值传递给表值函数进行计算,左表中的一行记录和“右表”进行笛卡尔乘积做为最终结果。如果右表查询出来的结果是空的,那么右表字段设置为null。
select *
from dbo.ta a
outer apply (
select *
from dbo.tb b
where a.a=b.ca) p
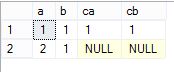
从查询结果上看,跟left join是相同的,但是在性能上,outer apply 比left join要差,因为TSQL 擅长集合操作,使用集合的思想编写的代码性能一般都很高,left join是集合操作语句,性能优于outer apply
虽然apply性能低,但是也有其用武之地,当需要按照顺序进行连接时,apply是最好的选择。
2,apply的两种用法
outer apply 和cross apply的相同点是:
- 先计算左表,后计算右表;
- 对左表中的每一行记录,右表都要“逐行”计算,类似于相关子查询,实际上,TSQL对apply进行优化之后,并不是逐行,而是逐N行;
outer apply 和cross apply的不同点是:
- outer apply:将左表作为保留表,如果右表没有匹配行,那么右表中的字段会设置为null,类似于left join。
- cross apply:没有保留表,对于左表中的一行记录,如果右表中没有匹配行,那么该行记录不显示在最终结果集中,类似于inner join。
select *
from dbo.ta a
cross apply (
select *
from dbo.tb b
where a.a=b.ca) p

十,join语句的应用
1,使用cross join能够快速产生大量顺序数字
cross join的结果集中数据行的数量是:左表数据行数和右表数据行数的乘积,由于每个table都有10个数字(从0到9),4个table进行cross join能够快速产生10的4次方,即10000个顺序数字。
;with num as
(
select n
from(values(0),(1),(2),(3),(4),(5),(6),(7),(8),(9)) as p(n)
)
select a.n+b.n*10+c.n*100+d.n*1000 as n
--into dbo.num
from num a
cross join num b
cross join num c
cross join num d
order by n
2,使用left join 查询不存在于右表的数据行
如果左表中的数据不存于右表,那么右表的字段是null,通过在 where 子句中设置filter,能够查询出存在于左表,但是不存在于右表的数据行
select *
from dbo.ta t1
left join dbo.tb t2
on t1.a=t2.ca
where t2.ca is null;
Join 和 apply 用法的更多相关文章
- Join 和 Apply 用法全解
在关系型数据库系统中,为了满足第三范式(3NF),需要将满足“传递依赖”的表分离成单独的表,通过Join 子句将相关表进行连接,Join子句共有三种类型:外连接,内连接,交叉连接:外连接分为:left ...
- SQL中order by;group up;like;关联查询join on的用法
排序order by的用法: 1.order by 字段名1 asc/desc, 字段名2 asc/desc,... 先按照字段名1的升序/降续给表进行排列 然后 按照字段名2的升序/降续给表进行排列 ...
- python join()阻塞的用法
join()阻塞的用法,用来检测线程有没有完全执行完毕 #!/usr/bin/env python#-*- coding:utf-8 -*-import threadingimport time de ...
- python中的filter、map、reduce、apply用法
1. filter 功能: filter的功能是过滤掉序列中不符合函数条件的元素,当序列中要删减的元素可以用某些函数描述时,就应该想起filter函数. 调用: filter(function,seq ...
- mysql union 和 left join 结合查询用法
union 和 left join 结合查询用法 SELECT u.nickname,z.group_comming_type,z.id,z.user_id,z.title,z.create_time ...
- SQL JOIN 和 UNION 用法
1 SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo FROM Persons, Orders WHERE Persons.Id_P ...
- 连接、关联、JOIN、APPLY(SQL Server)
连接方式 连接类型 个人总结 阐述(生成两个集合的约束笛卡儿积) INNER JOIN 内连接 关联相同的(用于查找关联的信息) FROM C AS c INNER JOIN D AS d ON ...
- T-SQL中的APPLY用法(半翻译)
本文接上文:T-SQL 中的CROSS JOIN用法(半翻译) 同样可用于微软认证70-461: Querying Microsoft SQL Server 2012考试的学习中. --------- ...
- T-SQL中的APPLY用法
原文出处:http://www.sqlservercentral.com/articles/Stairway+Series/121318/ 从SQL Server 2005开始,微软添加了一个新的运算 ...
随机推荐
- C#开发笔记
Dictionary 检查后获取值:Dictionary.TryGetValue() KeyValuePair<T, K> 的非泛型形式:DictionaryEntry List 由ILi ...
- 基于ThinkPHP3的微信平台开发_1
微信公众平台是个好东西,具体的就不说了,我直接说技术>_< 下图为目录结构一览: 微信开发 - 文件目录结构 平台功能: 此次开发的平台是面向多微信公众号.微信多公众号主(下面简称号主)的 ...
- unity 改变场景
public class GameManager : MonoBehaviour { public void OnStartGame(int sceneName) { SceneManager.Loa ...
- Leetcode Palindrome Linked List
Given a singly linked list, determine if it is a palindrome. Follow up:Could you do it in O(n) time ...
- 双向链表、双向循环链表的JS实现
关于链表简介.单链表.单向循环链表.JS中的使用以及扩充方法: 单链表.循环链表的JS实现 关于四种链表的完整封装: https://github.com/zhuwq585/Data-Structu ...
- Django--全文检索功能
经过两个月的时间,毕设终于算是把所有主要功能都完成了,最近这一周为了实现全文检索的功能,也算是查阅了不少资料,今天就在这里记录一下,以免以后再用到时抓瞎了~ 首先介绍一下我使用的Django全文检索逻 ...
- javax.mail 发送邮件异常
一.运行过程抛出异常 1.Exception in thread "main" java.lang.NoClassDefFoundError: com/sun/mail/util/ ...
- MyXls导出Excel的各种设置
MyXls是一个操作Excel的开源类库,支持设置字体.列宽.行高(由BOSSMA实现).合并单元格.边框.背景颜色.数据类型.自动换行.对齐方式等,通过众多项目的使用表现,证明MyXls对于创建简单 ...
- android webView开发之js调用java代码示例
1.webView设置 webView.getSettings().setJavaScriptEnabled(true);//设置支持js webView.addJavascriptInterface ...
- 关于 Poco::TCPServer框架 (windows 下使用的是 select模型) 学习笔记.
说明 为何要写这篇文章 ,之前看过阿二的梦想船的<Poco::TCPServer框架解析> http://www.cppblog.com/richbirdandy/archive/2010 ...