【CSAPP笔记】9. 汇编语言——缓冲区溢出
x86-64 Linux 内存结构
先来看看一个程序在内存中是如何组织的。Linux 为每个进程维持了一段单独的虚拟地址空间。(进程是计算机科学中很深刻、很成功的一个概念。当我们在运行一个程序时,会得到一个假象,好像我们的程序是系统当中运行的唯一程序,独占存储器和处理器资源。)

- 最上面是栈(stack),一般用来保存局部变量,有 8 MB 的大小限制,因此不建议在函数内开大数组,递归的效率低是因为容易栈溢出。栈的增长方向是向下的。
- 堆(heap),动态分配的内存会在这里处理,例如
malloc、new。堆是向上增长的。 - data 区,静态存储区,存放全局变量,静态变量,常量等。
- text 区和共享库,是可执行机器指令,是只读的。
缓冲区溢出
通过对过程调用、以及数组怎么翻译成机器代码的学习,我们知道C语言对于数组的引用不进行任何边界检查,而且局部变量和状态信息(保护寄存器的值、返回地址)都存在栈中。当对数组进行越界的写操作时可能会破坏掉栈中原有的信息,导致严重的程序错误。一种特别常见的破坏状态称作缓冲区溢出(buffer overflow),段错误(segmentation fault)也是C语言初学者经常会犯的毛病。通常,在栈中分配一个数组,用这个数组保存一个字符串,只要字符串的长度超过了为数组分配的空间,就会出现缓冲区溢出。下面这个简单的实例就说明了这个问题:
char *gets(char *s)//一个没有保护措施的 gets 函数
{
int c;
char *dest = s;
int gotchar = 0;
while((c=getchar())!= '\n' && c != EOF){
*dest++ = c;
gtochar = 1;
}
*dest++ = '\0';
if(c == EOF && !gotchar)
return NULL;
return s;
}
void input()
{
char buf[8];//设置一个较小的缓冲区
gets(buf);
puts(buf);
}
在函数 input 中,故意将缓冲区设计的特别小,只有 8 个字节。任何超过 7 个字节的字符串都会导致写越界。检查 GCC 为 input 产生的汇编代码,看看栈是如何组织的:
input:
pushl %ebp # 保存帧指针
mov %esp, %ebp # 更新栈指针位置
pushl %ebx # 压入保护寄存器
subl $20, %esp # 通过减法运算在栈上分配 20 个字节的空间
leal -12(%ebp), %ebx # 计算缓冲区开始的位置,是 %ebp - 12,存放到 %ebx 中
movl %ebx, (%esp) # 将缓冲区开始的位置存到栈中(这是调用 gets 的参数)
call gets # 调用 gets
movl %ebx, (%esp) # 这是调用 puts 的参数
call puts; # 调用 puts
addl $20, %esp # 释放 20 个字节的空间
popl %ebx; # 恢复保护寄存器
popl %ebp; # 弹出帧指针
ret; # 返回
可以知道,在运行上面这个程序的时候,栈空间是长这样的:
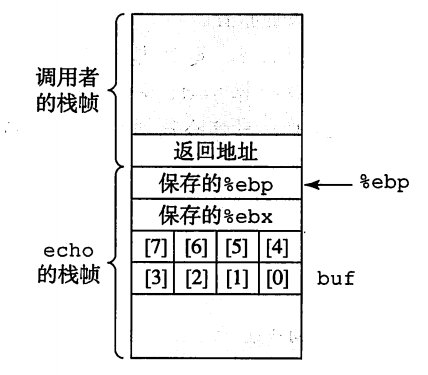
gets 从标准输入中读入一行,在末尾加上 null 字符。但是输入只在遇到一个回车符号或文件末尾才停止,并没有加入缓冲区是否会溢出的判断。看栈空间,我们知道 buf 的空间只有 8 个字节,如果我们输入的字符串大于 7 个字节,就会写到我们不该写的地方。如果单看 C 语言,是看不出数组越界写的影响的,只有研究机器代码的程序才能有所体会。
| 输入的字符数量 | 栈哪一部分被破坏 | 后果 |
|---|---|---|
| 0 ~ 7 | 没有被破坏 | 没有被破坏 |
| 8 ~ 11 | 保存的 %ebx 的值 | 被保护寄存器不能正确的恢复,调用者不能依靠这个寄存器的正确性 |
| 12 ~ 15 | 保存的 %ebp 的值 | 帧指针被破坏,不能正确地通过帧指针的偏移来引用局部变量 |
| 16 ~ 19 | 返回地址 | 返回地址被破坏,运行到 ret 指令时程序会跳转到完全意想不到的地方 |
| 20 以上 | 破坏了调用者的栈帧 | 害己害人? |
可以看到,破坏是累积的,随着字符数量的增加,破坏的状态就越来越多。
缓冲区溢出有一个更加致命的用途,就是可以让程序执行它本不愿意执行的函数,这是一种常见的通过计算机网络攻击系统安全的做法。上面说到,如果缓冲区溢出覆盖到了返回地址,那么程序在返回的时候会跳到一个完全意想不到的地方。通常,输入给程序一段字符串,这个字符串里面包括可执行代码的字节编码,称为攻击代码(exploit code),还有一些字节用一个指向攻击代码的指针覆盖返回地址,那么 ret 的执行就会让程序跳转到攻击代码。这也叫做代码注入攻击(code injection attack)

对抗栈溢出攻击
使用安全的函数
C 语言有很多的库函数,例如strcpy、strcat、sprintf 都不需要告诉它们缓冲区的大小,就能够产生一个字节序列,这样的情况就会导致容易遭受缓冲区溢出的攻击。避免使用这样的没有缓冲区溢出防御机制的函数,更好的做法是是使用例如像fgets、strncpy这样的函数来替代,它包括一个参数,限制读入的最大字节数。
栈随机化
为了在系统中插入攻击代码,攻击者不但需要插入攻击代码本身,还要插入指向攻击代码开头的指针,以便当函数返回时,通过这个指针跳到攻击代码的位置。放置这个指针需要知道栈的位置。在过去,程序栈的位置非常容易预测,栈的位置是相当固定的,这就让攻击者有机可乘。栈随机化的思想就是让栈的位置在程序每次运行的时候都有所变化。程序开始时,在栈上分配一段 0 ~ n 字节的,随机大小空间。程序不使用这段空间,而是接在后面执行,会导致程序每次执行的时候后续栈位置有所变化,让黑客难以预测攻击代码的插入位置。分配的 n 需要足够大,这样随机的变化才足够多样;也不能分配的过大,导致浪费内存。
下面是一段典型的确定栈位置的代码:
int main()
{
int local;
printf("local at %p\n", &local);
return 0;
}
书本上做了一个实验:在 32 位 Linux 系统上运行上述代码一万次,得到的地址空间变化范围是 0xff7fa7e0 ~ 0xffffd7e0,这段范围的大小约为 2^23 。
在 Linux 上,栈随机化已经是标准行为。栈随机化是一大类技术中的一种,称为地址空间布局随机化(Address-Space Layout Randomization)。采用此技术,每次运行程序时的不同部分,包括程序代码、共享库、堆、栈、全局变量,都会被加载到存储器的不同区域。这意味着一台机器上运行一个程序,与在其他机器上运行同样的程序,它的地址映射会大相径庭。
然而,一个执著的攻击者可以通过暴力来克服随机化。一种常见的把戏就是在代码开头插入很长的一段 no operation 代码,这段代码除了让程序计数器加一,指向下一条指令外,没有任何效果。攻击者要做的就是猜中栈地址变化序列中的某个地址,程序经过这个序列时,会“滑过”这段代码,达到攻击代码。就会例如上面这段大小为 2^23 的范围,某黑客有一段 128 字节的缓冲区溢出攻击代码,此黑客想要穷尽所有的起始地址,他需要尝试的次数是 2^32 / 128 ,也就是说他需要大约十三万次攻击就可以穷尽所有的地址。
栈破坏检测:金丝雀
第二道防线是应该要有检测能力,检测到栈被破坏了。C语言中,没有可靠的方法来防止对数组的越界写。但我们能够在发生了越界写之前,还没来得及发生有害后果之前,尝试检测到它。做法就是在任何的缓冲区和其他栈部分之间插入一个特殊的金丝雀(canary)值,也叫哨兵(guard),是程序每次运行时随机产生的,攻击者很难知道它是什么。在程序恢复寄存器、从函数返回之前,检查金丝雀的值是否被改变,如果是,那么程序将异常终止。
金丝雀源于历史上用这种鸟在煤矿中察觉有毒的气体。(有点意思)
限制可执行代码区域
限制可以存放可执行代码的存储器区域。一般来说,只有编译器产生的代码的那部分存储器才需要是可执行的。其他部分可以限制为只允许读和写。然而这些机制往往会带来严重的性能损失。
我们讲到的这些技术,是用于最小化程序缓冲区溢出攻击漏洞的三种常见机制。不幸的是,仍有方法能够攻击计算机,蠕虫和病毒还在继续危害许多的机器。
扯点别的
返回导向编程。可以利用修改已有的代码,来绕过系统和编译器的保护机制,攻击者控制堆栈调用以劫持程序控制流并执行针对性的机器语言指令序列(称为Gadgets)。每一段 gadget 通常结束于 return 指令,并位于共享库代码中的子程序。系列调用这些代码,攻击者可以在拥有更简单攻击防范的程序内执行任意操作。

Return-to-libc攻击。限制可执行代码区域有一种手段——研究者提出了数据执行保护策略(DEP)来帮助抵抗缓冲区溢出攻击。安全策略可以控制程序对内存的访问方式,即被保护的程序内存可以被约束为只能被写或被执行(W XOR X),而不能先写后执行。Return-into-libc 攻击方式就不具有同时写和执行的行为模式,因为其不需要注入新的恶意代码,取而代之的是重用漏洞程序中已有的函数完成攻击,让漏洞程序跳转到已有的代码序列(比如库函数的代码序列)。攻击者在实施攻击时仍然可以用恶意代码的地址(比如 libc 库中的 system()函数等)来覆盖程序函数调用的返回地址,并传递重新设定好的参数使其能够按攻击者的期望运行。与普通缓冲区溢出攻击相比,return-into-libc 攻击的防御难度更大。它可以避开数据执行保护策略,成为一种更有效、危险性更高的缓冲区溢出攻击。
蠕虫,worm:蠕虫可以自己运行,并能够将自己的等效副本传播到其他机器。
病毒,virus:病毒能将自己添加到包括操作系统的其他程序中,但不能独立运行。管蠕虫叫病毒是不对的。
参考链接
几个问题的思考:
- 为什么要限制栈的大小?
真正的原因其实是栈的地址空间必须连续,如果任其任意成长,会给内存管理带来困难。首先,对于多线程程序来说,每个线程都必须分配一个栈,因此没办法让默认值太大。 其次,就算你电脑上只跑一个单进程单线程,一头是程序代码,静态数据,malloc 自由分配的堆内存,另一头是堆栈。只要不停地让堆栈生长(调用的函数层次足够深,在堆栈上分配大量局部变量,比如大数组什么的),由于存储容量一定是一个有限值,堆栈迟早要把另一头的东西吃掉,那样你就麻烦了。(题外话:栈缓冲区溢出的后果比堆缓冲区溢出要严重许多
- 为什么要有栈和堆的分别?
“堆”和“栈”是程序运行中的不同内存空间。也就是说他们本质上都是内存。栈是程序启动的时候,系统分好了给你的。堆是用的时候才向系统申请的,用完了还回去,这个申请和交还的过程开销相对就比较大了。栈是编译时分配空间,而堆是动态分配(运行时分配空间)
。cpu有专门的寄存器(esp,ebp)来操作栈,堆都是使用间接寻址的。栈快点
【CSAPP笔记】9. 汇编语言——缓冲区溢出的更多相关文章
- Kali学习笔记22:缓冲区溢出漏洞利用实验
实验机器: Kali虚拟机一台(192.168.163.133) Windows XP虚拟机一台(192.168.163.130) 如何用Kali虚拟机一步一步“黑掉”这个windowsXP虚拟机呢? ...
- Kali学习笔记21:缓冲区溢出实验(漏洞发现)
上一篇文章,我已经做好了缓冲区溢出实验的准备工作: https://www.cnblogs.com/xuyiqing/p/9835561.html 下面就是Kali虚拟机对缓冲区溢出的测试: 已经知道 ...
- Kali学习笔记20:缓冲区溢出实验环境准备
在前几篇的博客中:我介绍了OpenVAS和Nessus这两个强大的自动化漏洞扫描器 但是,在计算机领域中有种叫做0day漏洞:没有公开只掌握在某些人手中 那么,这些0day漏洞是如何被发现的呢? 接下 ...
- CSAPP:逆向工程【缓冲区溢出攻击】
逆向工程[缓冲区溢出攻击] 任务描述 掌握函数调用时的栈帧结构,利用输入缓冲区的溢出漏洞,将攻击代码嵌入当前程序的栈帧中,使程序执行我们所期望的过程. 主要方法 溢出的字符将覆盖栈帧上的数据,会覆盖程 ...
- CSAPP阅读笔记-变长栈帧,缓冲区溢出攻击-来自第三章3.10的笔记-P192-P204
一.几个关于指针的小知识点: 1. malloc是在堆上动态分配内存,返回的是void *,使用时会配合显式/隐式类型转换,用完后需要用free手动释放. alloca是标准库函数,可以在栈上分配任 ...
- CSAPP缓冲区溢出攻击实验(上)
CSAPP缓冲区溢出攻击实验(上) 下载实验工具.最新的讲义在这. 网上能找到的实验材料有些旧了,有的地方跟最新的handout对不上.只是没有关系,大体上仅仅是程序名(sendstring)或者參数 ...
- CSAPP缓冲区溢出攻击实验(下)
CSAPP缓冲区溢出攻击实验(下) 3.3 Level 2: 爆竹 实验要求 这一个Level的难度陡然提升,我们要让getbuf()返回到bang()而非test(),并且在执行bang()之前将g ...
- 【CSAPP笔记】4. 汇编语言——基础知识
程序的机器级表示 计算机能读懂是机器代码(machine code)-- 用字节序列编码的低级操作 -- 也就是0和1.编译器基于编程语言的规则.目标机器的指令集和操作系统的规则,经过一系列阶段产生机 ...
- CSAPP 缓冲区溢出试验
缓冲区溢出试验是CSAPP课后试验之一,目的是: 更好的理解什么是缓冲区溢出 如何攻击带有缓冲区溢出漏洞的程序 如何编写出更加安全的代码 了解并理解编译器和操作系统为了让程序更加安全而提供的几种特性 ...
随机推荐
- Hadoop系列-zookeeper基础
目前是刚刚初学完zookeeper,这篇文章主要是简单的对一些基本的概念进行梳理强化. zookeeper基础概念的理解 有时候计算机领域很多名词都是从一长串英文提取首字母缩写而来,但很不幸zooke ...
- 2017-2018-1 20155305 《信息安全系统设计基础》第四周学习总结(课堂提交作业未来得及提交码云链接myod补充博客)
2017-2018-1 20155305 <信息安全系统设计基础>第四周学习总结(课堂提交作业未来得及提交码云链接myod补充博客) 课堂提交题目要求 编写MyOD.java 用java ...
- 2015539平措卓玛课堂测试(ch06)
课堂测试(ch06) 1.下面代码中,对数组x填充后,采用直接映射高速缓存,所有对x和y引用的命中率为(D) A .1 B .1/4 C .1/2 D .3/4 解析:缓存命中:当程序需要第(k+1) ...
- JavaScript函数作用域与对象以及实用技巧
1. JS作用域 1.1 全局作用域和局部作用域 函数外面声明的就是 全局作用域 函数内是局部作用域 全局变量可以直接在函数内修改和使用 变量,使用var是声明,没有var是使用变量. 如果在函数内使 ...
- SSIS 数据流的错误输出
数据流任务对错误的处理,和控制流不同,在数据流中,主要是对于错误行的处理,一般通过Error Output配置. 1,操作失败的类型:Error(Conversion) 和 Truncation. 2 ...
- javascript中的toString()方法
javascript中的toString()方法,主要用于Array.Boolean.Date.Error.Function.Number等对象.下面是这些方法的一些解析和简单应用,做个纪律,以作备忘 ...
- vue使用import来引入组件的注意事项
Vue使用import ... from ...来导入组件,库,变量等.而from后的来源可以是js,vue,json.这个是在webpack.base.conf.js中设置的: module.exp ...
- Idea for Mac 快捷键(快捷键选择:Mac OS X 10.5+)
删除一行 command + delete 查找 command + f 查找替换 command + r 复制一行 comma ...
- spring cloud网关通过Zuul RateLimit 限流配置
目录 引入依赖 配置信息 RateLimit源码简单分析 RateLimit详细的配置信息解读 在平常项目中为了防止一些没有token访问的API被大量无限的调用,需要对一些服务进行API限流.就好比 ...
- Fiddler 抓包https配置 提示:creation of the root certificate was not successful 证书安装不成功
window7 提示:creation of the root certificate was not successful 证书安装不成功 1.cmd 命令行 找到fiddler的安装目录 如 ...