Java多线程(六) —— 线程并发库之并发容器
参考文献:
http://www.blogjava.net/xylz/archive/2010/07/19/326527.html
一、ConcurrentMap API
从这一节开始正式进入并发容器的部分,来看看JDK 6带来了哪些并发容器。
在JDK 1.4以下只有Vector和Hashtable是线程安全的集合(也称并发容器,Collections.synchronized*系列也可以看作是线程安全的实现)。从JDK 5开始增加了线程安全的Map接口ConcurrentMap和线程安全的队列BlockingQueue(尽管Queue也是同时期引入的新的集合,但是规范并没有规定一定是线程安全的,事实上一些实现也不是线程安全的,比如PriorityQueue、ArrayDeque、LinkedList等,在Queue章节中会具体讨论这些队列的结构图和实现)。
在介绍ConcurrencyMap之前先来回顾下Map的体系结构。下图描述了Map的体系结构,其中蓝色字体的是JDK 5以后新增的并发容器。
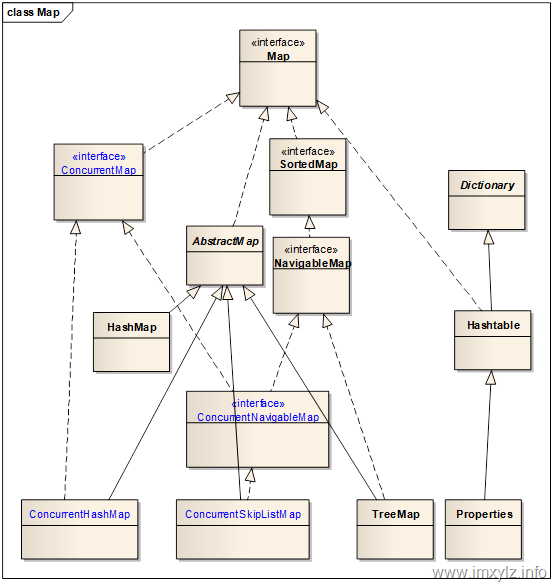
针对上图有以下几点说明:
- Hashtable是JDK 5之前Map唯一线程安全的内置实现(Collections.synchronizedMap不算)。特别说明的是Hashtable的t是小写的(不知道为啥),Hashtable继承的是Dictionary(Hashtable是其唯一公开的子类),并不继承AbstractMap或者HashMap。尽管Hashtable和HashMap的结构非常类似,但是他们之间并没有多大联系。
- ConcurrentHashMap是HashMap的线程安全版本,ConcurrentSkipListMap是TreeMap的线程安全版本。
- 最终可用的线程安全版本Map实现是ConcurrentHashMap / ConcurrentSkipListMap / Hashtable / Properties四个,但是Hashtable是过时的类库,因此如果可以的应该尽可能的使用ConcurrentHashMap和ConcurrentSkipListMap。
回到正题来,这个小节主要介绍ConcurrentHashMap的API以及应用,下一节才开始将原理和分析。

除了实现Map接口里面对象的方法外,ConcurrentHashMap还实现了ConcurrentMap里面的四个方法。
V putIfAbsent(K key,V value)
如果不存在key对应的值,则将value以key加入Map,否则返回key对应的旧值。这个等价于清单1 的操作:
清单1 putIfAbsent的等价操作
if (!map.containsKey(key))
return map.put(key, value);
else
return map.get(key);
在前面的章节中提到过,连续两个或多个原子操作的序列并不一定是原子操作。比如上面的操作即使在Hashtable中也不是原子操作。而putIfAbsent就是一个线程安全版本的操作的。
有些人喜欢用这种功能来实现单例模式,例如清单2。
清单2 一种单例模式的实现
package xylz.study.concurrency;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;public class ConcurrentDemo1 {
private static final ConcurrentMap<String, ConcurrentDemo1> map = new ConcurrentHashMap<String, ConcurrentDemo1>();
private static ConcurrentDemo1 instance;
public static ConcurrentDemo1 getInstance() {
if (instance == null) {map.putIfAbsent("INSTANCE", new ConcurrentDemo1());
instance = map.get("INSTANCE");
}
return instance;
}private ConcurrentDemo1() {
}}
当然这里只是一个操作的例子,实际上在单例模式文章中有很多的实现和比较。清单2 在存在大量单例的情况下可能有用,实际情况下很少用于单例模式。但是这个方法避免了向Map中的同一个Key提交多个结果的可能,有时候在去掉重复记录上很有用(如果记录的格式比较固定的话)。
boolean remove(Object key,Object value)
只有目前将键的条目映射到给定值时,才移除该键的条目。这等价于清单3 的操作。
清单3 remove(Object,Object)的等价操作
if (map.containsKey(key) && map.get(key).equals(value)) {
map.remove(key);
return true;
}
return false;
由于集合类通常比较的hashCode和equals方法,而这两个方法是在Object对象里面,因此两个对象如果hashCode一致,并且覆盖了equals方法后也一致,那么这两个对象在集合类里面就是“相同”的,不管是否是同一个对象或者同一类型的对象。也就是说只要key1.hashCode()==key2.hashCode() && key1.equals(key2),那么key1和key2在集合类里面就认为是一致,哪怕他们的Class类型不一致也没关系,所以在很多集合类里面允许通过Object来类型来比较(或者定位)。比如说Map尽管添加的时候只能通过制定的类型<K,V>,但是删除的时候却允许通过一个Object来操作,而不必是K类型。
既然Map里面有一个remove(Object)方法,为什么ConcurrentMap还需要remove(Object,Object)方法呢?这是因为尽管Map里面的key没有变化,但是value可能已经被其他线程修改了,如果修改后的值是我们期望的,那么我们就不能拿一个key来删除此值,尽管我们的期望值是删除此key对于的旧值。
这种特性在原子操作章节的AtomicMarkableReference和AtomicStampedReference里面介绍过。
boolean replace(K key,V oldValue,V newValue)
只有目前将键的条目映射到给定值时,才替换该键的条目。这等价于清单4 的操作。
清单4 replace(K,V,V)的等价操作
if (map.containsKey(key) && map.get(key).equals(oldValue)) {
map.put(key, newValue);
return true;
}
return false;
V replace(K key,V value)
只有当前键存在的时候更新此键对于的值。这等价于清单5 的操作。
清单5 replace(K,V)的等价操作
if (map.containsKey(key)) {
return map.put(key, value);
}
return null;
replace(K,V,V)相比replace(K,V)而言,就是增加了匹配oldValue的操作。
其实这4个扩展方法,是ConcurrentMap附送的四个操作,其实我们更关心的是Map本身的操作。当然如果没有这4个方法,要完成类似的功能我们可能需要额外的锁,所以有总比没有要好。比如清单6,如果没有putIfAbsent内置的方法,我们如果要完成此操作就需要完全锁住整个Map,这样就大大降低了ConcurrentMap的并发性。这在下一节中有详细的分析和讨论。
清单6 putIfAbsent的外部实现
public V putIfAbsent(K key, V value) {
synchronized (map) {
if (!map.containsKey(key)) return map.put(key, value);
return map.get(key);
}
}
二、ConcurrentMap实现
本来想比较全面和深入的谈谈ConcurrentHashMap的,发现网上有很多对HashMap和ConcurrentHashMap分析的文章,因此本小节尽可能的分析其中的细节,少一点理论的东西,多谈谈内部设计的原理和思想。
要谈ConcurrentHashMap的构造,就不得不谈HashMap的构造,因此先从HashMap开始简单介绍。
1. HashMap原理
我们从头开始设想。要将对象存放在一起,如何设计这个容器。目前只有两条路可以走,一种是采用分格技术,每一个对象存放于一个格子中,这样通过对格子的编号就能取到或者遍历对象;另一种技术就是采用串联的方式,将各个对象串联起来,这需要各个对象至少带有下一个对象的索引(或者指针)。显然第一种就是数组的概念,第二种就是链表的概念。所有的容器的实现其实都是基于这两种方式的,不管是数组还是链表,或者二者俱有。HashMap采用的就是数组的方式。
有了存取对象的容器后还需要以下两个条件才能完成Map所需要的条件。
- 能够快速定位元素:Map的需求就是能够根据一个查询条件快速得到需要的结果,所以这个过程需要的就是尽可能的快。
- 能够自动扩充容量:显然对于容器而然,不需要人工的去控制容器的容量是最好的,这样对于外部使用者来说越少知道底部细节越好,不仅使用方便,也越安全。
首先条件1,快速定位元素。快速定位元素属于算法和数据结构的范畴,通常情况下哈希(Hash)算法是一种简单可行的算法。所谓哈希算法,是将任意长度的二进制值映射为固定长度的较小二进制值。常见的MD2,MD4,MD5,SHA-1等都属于Hash算法的范畴。具体的算法原理和介绍可以参考相应的算法和数据结构的书籍,但是这里特别提醒一句,由于将一个较大的集合映射到一个较小的集合上,所以必然就存在多个元素映射到同一个元素上的结果,这个叫“哈希碰撞”,后面会用到此知识,暂且不表。
条件2,如果满足了条件1,一个元素映射到了某个位置,现在一旦扩充了容量,也就意味着元素映射的位置需要变化。因为对于Hash算法来说,调整了映射的小集合,那么原来映射的路径肯定就不复存在,那么就需要对现有重新计算映射路径,也就是所谓的rehash过程。
好了有了上面的理论知识后来看HashMap是如何实现的。
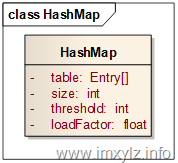
在HashMap中首先由一个对象数组table是不可避免的,修饰符transient只是表示序列号的时候不被存储而已。size描述的是Map中元素的大小,threshold描述的是达到指定元素个数后需要扩容,loadFactor是扩容因子(loadFactor>0),也就是计算threshold的。那么元素的容量就是table.length,也就是数组的大小。换句话说,如果存取的元素大小达到了整个容量(table.length)的loadFactor倍(也就是table.length*loadFactor个),那么就需要扩充容量了。在HashMap中每次扩容就是将扩大数组的一倍,使数组大小为原来的两倍。
然后接下来看如何将一个元素映射到数组table中。显然要映射的key是一个无尽的超大集合,而table是一个较小的有限集合,那么一种方式就是将key编码后的hashCode值取模映射到table上,这样看起来不错。但是在Java中采用了一种更高效的办法。由于与(&)是比取模(%)更高效的操作,因此Java中采用hash值与数组大小-1后取与来确定数组索引的。为什么这样做是更有效的?参考资料7对这一块进行非常详细的分析,这篇文章的作者非常认真,也非常仔细的分析了里面包含的思想。
清单1 indexFor片段
static int indexFor(int h, int length) {
return h & (length-1);
}
前面说明,既然是大集合映射到小集合上,那么就必然存在“碰撞”,也就是不同的key映射到了相同的元素上。那么HashMap是怎么解决这个问题的?
注:解决哈希冲突的两种方法:开放地址法、链地址法。
- 开放地址法包括:线性探测(依次往下)、二次探测(依次往下的二次方)、再哈希法
- 链地址法包括
在HashMap中采用了下面方式(链地址法),解决了此问题。
- 同一个索引的数组元素组成一个链表,查找允许时循环链表找到需要的元素。
- 尽可能的将元素均匀的分布在数组上。
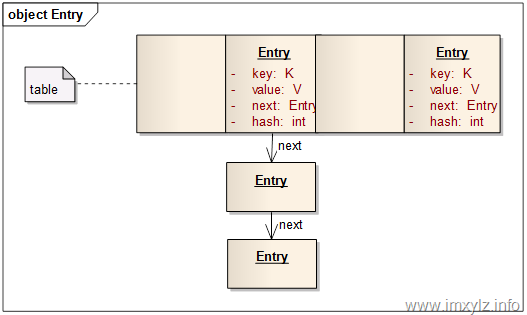
对于问题1,HashMap采用了上图的一种数据结构。table中每一个元素是一个Map.Entry,其中Entry包含了四个数据,key,value,hash,next。key和value是存储的数据;hash是元素key的Hash后的表现形式(最终要映射到数组上),这里链表上所有元素的hash经过清单1 的indexFor后将得到相同的数组索引;next是指向下一个元素的索引,同一个链表上的元素就是通过next串联起来的。
再来看问题2 尽可能的将元素均匀的分布在数组上这个问题是怎么解决的。首先清单2 是将key的hashCode经过一系列的变换,使之更符合小数据集合的散列模型。
清单2 hashCode的二次散列
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
至于清单2 为什么这样散列我没有找到依据,也没有什么好的参考资料。参考资料1 分析了此过程,认为是一种比较有效的方式,有兴趣的可以研究下。
第二点就是在清单1 的描述中,尽可能的与数组的长度减1的数与操作,使之分布均匀。这在参考资料7 中有介绍。
第三点就是构造数组时数组的长度是2的倍数。清单3 反映了这个过程。为什么要是2的倍数?在参考资料7 中分析说是使元素尽可能的分布均匀。
清单3 HashMap 构造数组
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
另外loadFactor的默认值0.75和capacity的默认值16是经过大量的统计分析得出的,很久以前我见过相关的数据分析,现在找不到了,有兴趣的可以查询相关资料。这里不再叙述了。
有了上述原理后再来分析HashMap的各种方法就不是什么问题的。
清单4 HashMap的get操作
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
清单4 描述的是HashMap的get操作,在这个操作中首先判断key是否为空,因为为空的话总是映射到table的第0个元素上(可以看上面的清单2和清单1)。然后就需要查找table的索引。一旦找到对应的Map.Entry元素后就开始遍历此链表。由于不同的hash可能映射到同一个table[index]上,而相同的key却同时映射到相同的hash上,所以一个key和Entry对应的条件就是hash(key)==e.hash 并且key.equals(e.key)。从这里我们看到,Object.hashCode()只是为了将相同的元素映射到相同的链表上(Map.Entry),而Object.equals()才是比较两个元素是否相同的关键!这就是为什么总是成对覆盖hashCode()和equals()的原因。
清单5 HashMap的put操作
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
清单5 描述的是HashMap的put操作。对比get操作,可以发现,put实际上是先查找,一旦找到key对应的Entry就直接修改Entry的value值,否则就增加一个元素。增加的元素是在链表的头部,也就是占据table中的元素,如果table中对应索引原来有元素的话就将整个链表添加到新增加的元素的后面。也就是说新增加的元素再次查找的话是优于在它之前添加的同一个链表上的元素。这里涉及到就是扩容,也就是一旦元素的个数达到了扩容因子规定的数量(threhold=table.length*loadFactor),就将数组扩大一倍。
清单6 HashMap扩容过程
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;//重哈希
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
清单6 描述的是HashMap扩容的过程。可以看到扩充过程会导致元素数据的所有元素进行重新hash计算,这个过程也叫rehash。显然这是一个非常耗时的过程,否则扩容都会导致所有元素重新计算hash。因此尽可能的选择合适的初始化大小是有效提高HashMap效率的关键。太大了会导致过多的浪费空间,太小了就可能会导致繁重的rehash过程。在这个过程中loadFactor也可以考虑。
举个例子来说,如果要存储1000个元素,采用默认扩容因子0.75,那么1024显然是不够的,因为1000>0.75*1024了,所以选择2048是必须的,显然浪费了1048个空间。如果确定最多只有1000个元素,那么扩容因子为1,那么1024是不错的选择。另外需要强调的一点是扩容因此越大,从统计学角度讲意味着链表的长度就也大,也就是在查找元素的时候就需要更多次的循环。所以凡事必然是一个平衡的过程。
这里可能有人要问题,一旦我将Map的容量扩大后(也就是数组的大小),这个容量还能减小么?比如说刚开始Map中可能有10000个元素,运行一旦时间以后Map的大小永远不会超过10个,那么Map的容量能减小到10个或者16个么?答案就是不能,这个capacity一旦扩大后就不能减小了,只能通过构造一个新的Map来控制capacity了。
HashMap的几个内部迭代器也是非常重要的,这里限于篇幅就不再展开了,有兴趣的可以自己研究下。
Hashtable的原理和HashMap的原理几乎一样,所以就不讨论了。另外LinkedHashMap是在Map.Entry的基础上增加了before/after两个双向索引,用来将所有Map.Entry串联起来,这样就可以遍历或者做LRU Cache等。这里也不再展开讨论了。
memcached 内部数据结构就是采用了HashMap类似的思想来实现的,有兴趣的可以参考资料8,9,10。
为了不使这篇文章过长,因此将ConcurrentHashMap的原理放到下篇讲。需要说明的是,尽管ConcurrentHashMap与HashMap的名称有些渊源,而且实现原理有些相似,但是为了更好的支持并发,ConcurrentHashMap在内部也有一些比较大的调整,这个在下篇会具体介绍。
2. ConcurrentHashMap原理
在读写锁章节部分介绍过一种是用读写锁实现Map的方法。此种方法看起来可以实现Map响应的功能,而且吞吐量也应该不错。但是通过前面对读写锁原理的分析后知道,读写锁的适合场景是读操作>>写操作,也就是读操作应该占据大部分操作,另外读写锁存在一个很严重的问题是读写操作不能同时发生。要想解决读写同时进行问题(至少不同元素的读写分离),那么就只能将锁拆分,不同的元素拥有不同的锁,这种技术就是“锁分离”技术。
默认情况下ConcurrentHashMap是用了16个类似HashMap 的结构,其中每一个HashMap拥有一个独占锁。也就是说最终的效果就是通过某种Hash算法,将任何一个元素均匀的映射到某个HashMap的Map.Entry上面,而对某个一个元素的操作就集中在其分布的HashMap上,与其它HashMap无关。这样就支持最多16个并发的写操作。
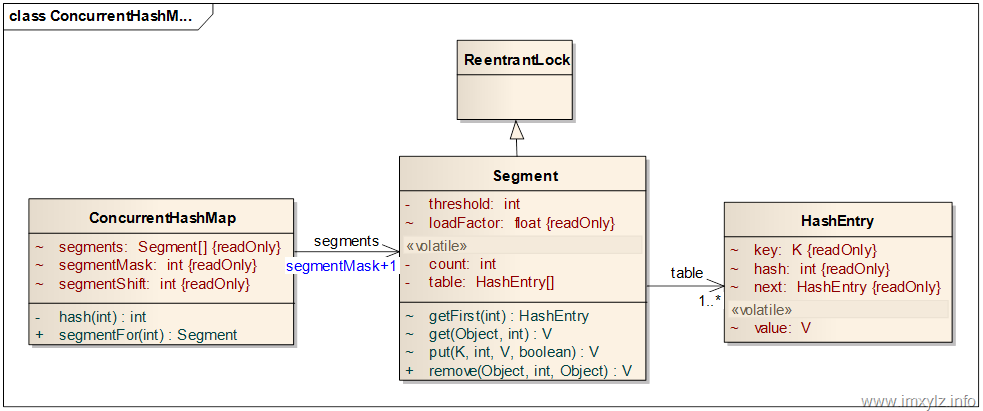
上图就是ConcurrentHashMap的类图。参考上面的说明和HashMap的原理分析,可以看到ConcurrentHashMap将整个对象列表分为segmentMask+1个片段(Segment)。其中每一个片段是一个类似于HashMap的结构,它有一个HashEntry的数组,数组的每一项又是一个链表,通过HashEntry的next引用串联起来。
这个类图上面的数据结构的定义非常有学问,接下来会一个个有针对性的分析。
首先如何从ConcurrentHashMap定位到HashEntry。在HashMap的原理分析部分说过,对于一个Hash的数据结构来说,为了减少浪费的空间和快速定位数据,那么就需要数据在Hash上的分布比较均匀。对于一次Map的查找来说,首先就需要定位到Segment,然后从过Segment定位到HashEntry链表,最后才是通过遍历链表得到需要的元素。
在不讨论并发的前提下先来讨论如何定位到HashEntry的。在ConcurrentHashMap中是通过hash(key.hashCode())和segmentFor(hash)来得到Segment的。清单1 描述了如何定位Segment的过程。其中hash(int)是将key的hashCode进行二次编码,使之能够在segmentMask+1个Segment上均匀分布(默认是16个)。可以看到的是这里和HashMap还是有点不同的,这里采用的算法叫Wang/Jenkins hash,有兴趣的可以参考资料1和参考资料2。总之它的目的就是使元素能够均匀的分布在不同的Segment上,这样才能够支持最多segmentMask+1个并发,这里segmentMask+1是segments的大小。
清单1 定位Segment
private static int hash(int h) {
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
显然在不能够对Segment扩容的情况下,segments的大小就应该是固定的。所以在ConcurrentHashMap中segments/segmentMask/segmentShift都是常量,一旦初始化后就不能被再次修改,其中segmentShift是查找Segment的一个常量偏移量。
有了Segment以后再定位HashEntry就和HashMap中定位HashEntry一样了,先将hash值与Segment中HashEntry的大小减1进行与操作定位到HashEntry链表,然后遍历链表就可以完成相应的操作了。
能够定位元素以后ConcurrentHashMap就已经具有了HashMap的功能了,现在要解决的就是如何并发的问题。要解决并发问题,加锁是必不可免的。再回头看Segment的类图,可以看到Segment除了有一个volatile类型的元素大小count外,Segment还是集成自ReentrantLock的。另外在前面的原子操作和锁机制中介绍过,要想最大限度的支持并发,那么能够利用的思路就是尽量读操作不加锁,写操作不加锁。如果是读操作不加锁,写操作加锁,对于竞争资源来说就需要定义为volatile类型的。volatile类型能够保证happens-before法则,所以volatile能够近似保证正确性的情况下最大程度的降低加锁带来的影响,同时还与写操作的锁不产生冲突。
同时为了防止在遍历HashEntry的时候被破坏,那么对于HashEntry的数据结构来说,除了value之外其他属性就应该是常量,否则不可避免的会得到ConcurrentModificationException。这就是为什么HashEntry数据结构中key,hash,next是常量的原因(final类型)。
有了上面的分析和条件后再来看Segment的get/put/remove就容易多了。
get操作
清单2 Segment定位元素
V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
HashEntry<K,V> getFirst(int hash) {
HashEntry<K,V>[] tab = table;
return tab[hash & (tab.length - 1)];
}V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}
清单2 描述的是Segment如何定位元素。首先判断Segment的大小count>0,Segment的大小描述的是HashEntry不为空(key不为空)的个数。如果Segment中存在元素那么就通过getFirst定位到指定的HashEntry链表的头节点上,然后遍历此节点,一旦找到key对应的元素后就返回其对应的值。但是在清单2 中可以看到拿到HashEntry的value后还进行了一次判断操作,如果为空还需要加锁再读取一次(readValueUnderLock)。为什么会有这样的操作?尽管ConcurrentHashMap不允许将value为null的值加入,但现在仍然能够读到一个为空的value就意味着此值对当前线程还不可见(这是因为HashEntry还没有完全构造完成就赋值导致的,后面还会谈到此机制)。
put操作
清单3 描述的是Segment的put操作。首先就需要加锁了,修改一个竞争资源肯定是要加锁的,这个毫无疑问。需要说明的是Segment集成的是ReentrantLock,所以这里加的锁也就是独占锁,也就是说同一个Segment在同一时刻只有能一个put操作。
接下来来就是检查是否需要扩容,这和HashMap一样,如果需要的话就扩大一倍,同时进行rehash操作。
查找元素就和get操作是一样的,得到元素就直接修改其值就好了。这里onlyIfAbsent只是为了实现ConcurrentMap的putIfAbsent操作而已。需要说明以下几点:
- 如果找到key对于的HashEntry后直接修改就好了,如果找不到那么就需要构造一个新的HashEntry出来加到hash对于的HashEntry的头部,同时就的头部就加到新的头部后面。这是因为HashEntry的next是final类型的,所以只能修改头节点才能加元素加入链表中。
- 如果增加了新的操作后,就需要将count+1写回去。前面说过count是volatile类型,而读取操作没有加锁,所以只能把元素真正写回Segment中的时候才能修改count值,这个要放到整个操作的最后。
- 在将新的HashEntry写入table中时是通过构造函数来设置value值的,这意味对table的赋值可能在设置value之前,也就是说得到了一个半构造完的HashEntry。这就是重排序可能引起的问题。所以在读取操作中,一旦读到了一个value为空的value是就需要加锁重新读取一次。为什么要加锁?加锁意味着前一个写操作的锁释放,也就是前一个锁的数据已经完成写完了了,根据happens-before法则,前一个写操作的结果对当前读线程就可见了。当然在JDK 6.0以后不一定存在此问题。
- 在Segment中table变量是volatile类型,多次读取volatile类型的开销要不非volatile开销要大,而且编译器也无法优化,所以在put操作中首先建立一个临时变量tab指向table,多次读写tab的效率要比volatile类型的table要高,JVM也能够对此进行优化。
清单3 Segment的put操作
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
remove 操作
清单4 描述了Segment删除一个元素的过程。同put一样,remove也需要加锁,这是因为对table可能会有变更。由于HashEntry的next节点是final类型的,所以一旦删除链表中间一个元素,就需要将删除之前或者之后的元素重新加入新的链表。而Segment采用的是将删除元素之前的元素一个个重新加入删除之后的元素之前(也就是链表头结点)来完成新链表的构造。
清单4 Segment的remove操作
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
for (HashEntry<K,V> p = first; p != e; p = p.next)
newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}
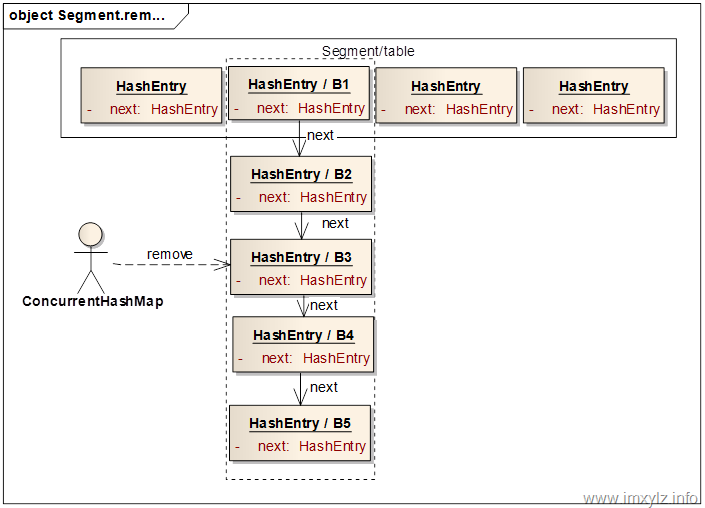
下面的示意图描述了如何删除一个已经存在的元素的。假设我们要删除B3元素。首先定位到B3所在的Segment,然后再定位到Segment的table中的B1元素,也就是Bx所在的链表。然后遍历链表找到B3,找到之后就从头结点B1开始构建新的节点B1(蓝色)加到B4的前面,继续B1后面的节点B2构造B2(蓝色),加到由蓝色的B1和B4构成的新的链表。继续下去,直到遇到B3后终止,这样就构造出来一个新的链表B2(蓝色)->B1(蓝色)->B4->B5,然后将此链表的头结点B2(蓝色)设置到Segment的table中。这样就完成了元素B3的删除操作。需要说明的是,尽管就的链表仍然存在(B1->B2->B3->B4->B5),但是由于没有引用指向此链表,所以此链表中无引用的(B1->B2->B3)最终会被GC回收掉。这样做的一个好处是,如果某个读操作在删除时已经定位到了旧的链表上,那么此操作仍然将能读到数据,只不过读取到的是旧数据而已,这在多线程里面是没有问题的。

除了对单个元素操作外,还有对全部的Segment的操作,比如size()操作等。
size操作
size操作涉及到统计所有Segment的大小,这样就会遍历所有的Segment,如果每次加锁就会导致整个Map都被锁住了,任何需要锁的操作都将无法进行。这里用到了一个比较巧妙的方案解决此问题。
在Segment中有一个变量modCount,用来记录Segment结构变更的次数,结构变更包括增加元素和删除元素,每增加一个元素操作就+1,每进行一次删除操作+1,每进行一次清空操作(clear)就+1。也就是说每次涉及到元素个数变更的操作modCount都会+1,而且一直是增大的,不会减小。
遍历两次ConcurrentHashMap中的segments,每次遍历是记录每一个Segment的modCount,比较两次遍历的modCount值的和是否相同,如果相同就返回在遍历过程中获取的Segment的count的和,也就是所有元素的个数。如果不相同就重复再做一次。重复一次还不相同就将所有Segment锁住,一个一个的获取其大小(count),最后将这些count加起来得到总的大小。当然了最后需要将锁一一释放。清单5 描述了这个过程。
这里有一个比较高级的话题是为什么在读取modCount的时候总是先要读取count一下。为什么不是先读取modCount然后再读取count的呢?也就是说下面的两条语句能否交换下顺序?
sum += segments[i].count;
mcsum += mc[i] = segments[i].modCount;
答案是不能!为什么?这是因为modCount总是在加锁的情况下才发生变化,所以不会发生多线程同时修改的情况,也就是没必要时volatile类型。另外总是在count修改的情况下修改modCount,而count是一个volatile变量。于是这里就充分利用了volatile的特性。
根据happens-before法则,第(3)条:对volatile字段的写入操作happens-before于每一个后续的同一个字段的读操作。也就是说一个操作C在volatile字段的写操作之后,那么volatile写操作之前的所有操作都对此操作C可见。所以修改modCount总是在修改count之前,也就是说如果读取到了一个count的值,那么在count变化之前的modCount也就能够读取到,换句话说就是如果看到了count值的变化,那么就一定看到了modCount值的变化。而如果上面两条语句交换下顺序就无法保证这个结果一定存在了。
在ConcurrentHashMap.containsValue中,可以看到每次遍历segments时都会执行int c = segments[i].count;,但是接下来的语句中又不用此变量c,尽管如此JVM仍然不能将此语句优化掉,因为这是一个volatile字段的读取操作,它保证了一些列操作的happens-before顺序,所以是至关重要的。在这里可以看到:
ConcurrentHashMap将volatile发挥到了极致!
另外isEmpty操作于size操作类似,不再累述。
清单5 ConcurrentHashMap的size操作
public int size() {
final Segment<K,V>[] segments = this.segments;
long sum = 0;
long check = 0;
int[] mc = new int[segments.length];
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
for (int k = 0; k < RETRIES_BEFORE_LOCK; ++k) {
check = 0;
sum = 0;
int mcsum = 0;
for (int i = 0; i < segments.length; ++i) {
sum += segments[i].count;
mcsum += mc[i] = segments[i].modCount;
}
if (mcsum != 0) {
for (int i = 0; i < segments.length; ++i) {
check += segments[i].count;
if (mc[i] != segments[i].modCount) {
check = -1; // force retry
break;
}
}
}
if (check == sum)
break;
}
if (check != sum) { // Resort to locking all segments
sum = 0;
for (int i = 0; i < segments.length; ++i)
segments[i].lock();
for (int i = 0; i < segments.length; ++i)
sum += segments[i].count;
for (int i = 0; i < segments.length; ++i)
segments[i].unlock();
}
if (sum > Integer.MAX_VALUE)
return Integer.MAX_VALUE;
else
return (int)sum;
}
ConcurrentSkipListMap/Set
本来打算介绍下ConcurrentSkipListMap的,结果打开源码一看,彻底放弃了。那里面的数据结构和算法我估计研究一周也未必能够完全弄懂。很久以前我看TreeMap的时候就头大,想想那些复杂的“红黑二叉树”我头都大了。这些都归咎于从前没有好好学习《数据结构和算法》,现在再回头看这些复杂的算法感觉非常头疼,为了减少脑细胞的死亡,暂且还是不要惹这些“玩意儿”。有兴趣的可以看看参考资料4 中对TreeMap的介绍。
参考资料:
四、并发队列和Queue简介
Queue是JDK 5以后引入的新的集合类,它属于Java Collections Framework的成员,在Collection集合中和List/Set是同一级别的接口。通常来讲Queue描述的是一种FIFO的队列,当然不全都是,比如PriorityQueue是按照优先级的顺序(或者说是自然顺序,借助于Comparator接口)。
下图描述了Java Collections Framework中Queue的整个家族体系。
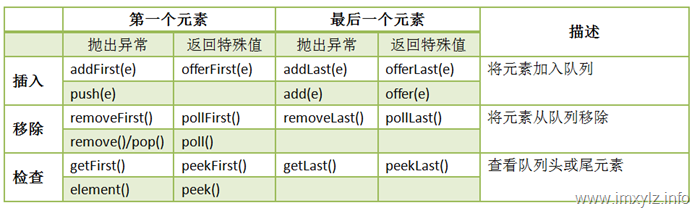
对于Queue而言是在Collection的基础上增加了offer/remove/poll/element/peek方法,另外重新定义了add方法。对于这六个方法,有不同的定义。
|
抛出异常 |
返回特殊值 |
操作描述 |
|
|
插入 |
add(e) |
offer(e) |
将元素加入到队列尾部 |
|
移除 |
remove() |
poll() |
移除队列头部的元素 |
|
检查 |
element() |
peek() |
返回队列头部的元素而不移除此元素 |
特别说明的是对于Queue而言,规范并没有规定是线程安全的,为了解决这个问题,引入了可阻塞的队列BlockingQueue。对于BlockingQueue而言所有操作的是线程安全的,并且队列的操作可以被阻塞,直到满足某种条件。Queue的另一个子接口Deque描述的是一个双向的队列。与Queue不同的是,Deque允许在队列的头部增加元素和在队列的尾部删除元素。也就是说Deque是一个双向队列。二者功能都有的队列就是BlockingDeque,这种阻塞队列允许在队列的头和尾部分别操作元素,应该说是Queue中功能最强大的实现。
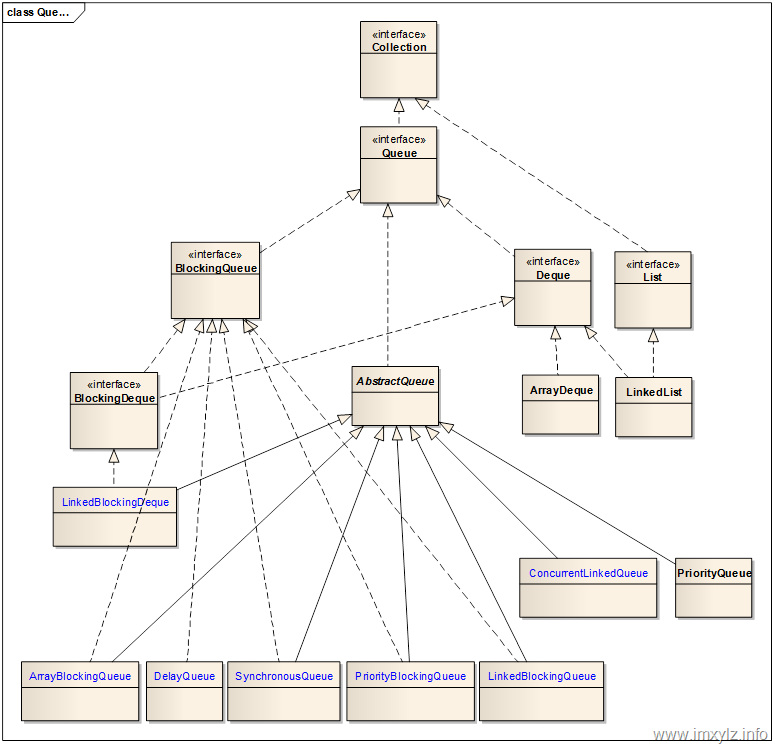
在JDK 5之前LinkedList就已经存在,而且本身实现都是一种双向队列。所以到了JDK 5以后就将LinkedList同时实现Deque接口,这样LinkedList就又属于Queue的一部分了。
通常情况下Queue都是靠链表结构实现的,但是链表意味着有一些而外的引用开销,如果是双向链表开销就更大了。所以为了节省内存,一种方式就是使用固定大小的数组来实现队列。在这种情况下队列的大小是固定,元素的遍历通过数组的索引进行,很显然这是一种双向链表的模型。ArrayDeque就是这样一种实现。
另外ArrayBlockingQueue也是一种数组实现的队列,但是却没有改造成双向,仅仅实现了BlockingQueue的模型。理论上和ArrayDeque一样也应该容易改造成双向的实现。
PriorityQueue和PriorityBlockingQueue实现了一种排序的队列模型。这很类似与SortedSet,通过队列的Comparator接口或者Comparable元素来排序元素。这种情况下元素在队列中的出入就不是按照FIFO的形式,而是根据比较后的自然顺序来进行。
CocurrentLinkedQueue是一种线程安全却非阻塞的FIFO队列,这种队列通常实现起来比较简单,但是却很有效。在接下来的章节会详细的描述它。
SynchronousQueue是一种特别的BlockingQueue,它只是把一个add/offer操作的元素直接移交给remove/take操作。也就是说它本身不会缓存任何元素,所以严格意义上说来讲并不是一种真正的队列。此队列维护一个线程列表,这些线程等待从队列中加入元素或者移除元素。简单的说,至少有一个remove/take操作时add/offer操作才能成功,同样至少有一个add/offer操作时remove/take操作才能成功。这是一种双向等待的队列模型,出队列等待加入等列,而入队列又等待出队列。这种队列的好处在于能够最大线程的保持吞吐量却又是线程安全的。所以对于一个需要快速处理的任务队列,SynchronousQueue是一个不错的选择。
BlockingQueue还有一种实现DelayQueue,这种实现允许每一个元素(Delayed)带有一个延时时间,当调用take/poll的时候会检测队列头元素这个时间是否<=0,如果满足就是说已经超时了,那么此元素就可以被移除了,否则就会等待。特别说明的是这个头元素应该是最先被超时的元素(这个时间是绝对时间)。这个类设计很巧妙,被用于ScheduledFutureTask来进行定时操作。希望后面会开辟一个章节讲讲这里面的想法。实在不行在讲线程池部分肯定会提到这个。
五、ConcurrentLinkedQueue
ConcurrentLinkedQueue是Queue的一个线程安全实现。先来看一段文档说明。
一个基于链接节点的无界线程安全队列。此队列按照 FIFO(先进先出)原则对元素进行排序。队列的头部 是队列中时间最长的元素。队列的尾部 是队列中时间最短的元素。新的元素插入到队列的尾部,队列获取操作从队列头部获得元素。当多个线程共享访问一个公共 collection 时,ConcurrentLinkedQueue 是一个恰当的选择。此队列不允许使用 null 元素。
由于ConcurrentLinkedQueue只是简单的实现了一个队列Queue,因此从API的角度讲,没有多少值的介绍,使用起来也很简单,和前面遇到的所有FIFO队列都类似。出队列只能操作头节点,入队列只能操作尾节点,任意节点操作就需要遍历完整的队列。
重点放在解释ConcurrentLinkedQueue的原理和实现上。
在继续探讨之前,结合前面线程安全的相关知识,我来分析设计一个线程安全的队列哪几种方法。
第一种:使用synchronized同步队列,就像Vector或者Collections.synchronizedList/Collection那样。显然这不是一个好的并发队列,这会导致吞吐量急剧下降。
第二种:使用Lock。一种好的实现方式是使用ReentrantReadWriteLock来代替ReentrantLock提高读取的吞吐量。但是显然ReentrantReadWriteLock的实现更为复杂,而且更容易导致出现问题,另外也不是一种通用的实现方式,因为ReentrantReadWriteLock适合哪种读取量远远大于写入量的场合。当然了ReentrantLock是一种很好的实现,结合Condition能够很方便的实现阻塞功能,这在后面介绍BlockingQueue的时候会具体分析。
第三种:使用CAS操作。尽管Lock的实现也用到了CAS操作,但是毕竟是间接操作,而且会导致线程挂起。一个好的并发队列就是采用某种非阻塞算法来取得最大的吞吐量。
ConcurrentLinkedQueue采用的就是第三种策略。它采用了参考资料1 中的算法。
在锁机制中谈到过,要使用非阻塞算法来完成队列操作,那么就需要一种“循环尝试”的动作,就是循环操作队列,直到成功为止,失败就会再次尝试。这在前面的章节中多次介绍过。
针对各种功能深入分析。
在开始之前先介绍下ConcurrentLinkedQueue的数据结构。

在上面的数据结构中,ConcurrentLinkedQueue只有头结点、尾节点两个元素,而对于一个节点Node而言除了保存队列元素item外,还有一个指向下一个节点的引用next。 看起来整个数据结构还是比较简单的。但是也有几点是需要说明:
- 所有结构(head/tail/item/next)都是volatile类型。 这是因为ConcurrentLinkedQueue是非阻塞的,所以只有volatile才能使变量的写操作对后续读操作是可见的(这个是有happens-before法则保证的)。同样也不会导致指令的重排序。
- 所有结构的操作都带有原子操作,这是由AtomicReferenceFieldUpdater保证的,这在原子操作中介绍过。它能保证需要的时候对变量的修改操作是原子的。
- 由于队列中任何一个节点(Node)只有下一个节点的引用,所以这个队列是单向的,根据FIFO特性,也就是说出队列在头部(head),入队列在尾部(tail)。头部保存有进入队列最长时间的元素,尾部是最近进入的元素。
- 没有对队列长度进行计数,所以队列的长度是无限的,同时获取队列的长度的时间不是固定的,这需要遍历整个队列,并且这个计数也可能是不精确的。
- 初始情况下队列头和队列尾都指向一个空节点,但是非null,这是为了方便操作,不需要每次去判断head/tail是否为空。但是head却不作为存取元素的节点,tail在不等于head情况下保存一个节点元素。也就是说head.item这个应该一直是空,但是tail.item却不一定是空(如果head!=tail,那么tail.item!=null)。
对于第5点,可以从ConcurrentLinkedQueue的初始化中看到。这种头结点也叫“伪节点”,也就是说它不是真正的节点,只是一标识,就像c中的字符数组后面的\0以后,只是用来标识结束,并不是真正字符数组的一部分。
private transient volatile Node<E> head = new Node<E>(null, null);
private transient volatile Node<E> tail = head;
有了上述5点再来解释相关API操作就容易多了。
在上一节中列出了add/offer/remove/poll/element/peek等价方法的区别,所以这里就不再重复了。
清单1 入队列操作
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
Node<E> n = new Node<E>(e, null);
for (;;) {
Node<E> t = tail;
Node<E> s = t.getNext();
if (t == tail) {
if (s == null) {
if (t.casNext(s, n)) {
casTail(t, n);
return true;
}
} else {
casTail(t, s);
}
}
}
}
清单1 描述的是入队列的过程。整个过程是这样的。
- 获取尾节点t,以及尾节点的下一个节点s。如果尾节点没有被别人修改,也就是t==tail,进行2,否则进行1。
- 如果s不为空,也就是说此时尾节点后面还有元素,那么就需要把尾节点往后移,进行1。否则进行3。
- 修改尾节点的下一个节点为新节点,如果成功就修改尾节点,返回true。否则进行1。
从操作3中可以看到是先修改尾节点的下一个节点,然后才修改尾节点位置的,所以这才有操作2中为什么获取到的尾节点的下一个节点不为空的原因。
特别需要说明的是,对尾节点的tail的操作需要换成临时变量t和s,一方面是为了去掉volatile变量的可变性,另一方面是为了减少volatile的性能影响。
清单2 描述的出队列的过程,这个过程和入队列相似,有点意思。
头结点是为了标识队列起始,也为了减少空指针的比较,所以头结点总是一个item为null的非null节点。也就是说head!=null并且head.item==null总是成立。所以实际上获取的是head.next,一旦将头结点head设置为head.next成功就将新head的item设置为null。至于以前就的头结点h,h.item=null并且h.next为新的head,但是由于没有对h的引用,所以最终会被GC回收。这就是整个出队列的过程。
清单2 出队列操作
public E poll() {
for (;;) {
Node<E> h = head;
Node<E> t = tail;
Node<E> first = h.getNext();
if (h == head) {
if (h == t) {
if (first == null)
return null;
else
casTail(t, first);
} else if (casHead(h, first)) {
E item = first.getItem();
if (item != null) {
first.setItem(null);
return item;
}
// else skip over deleted item, continue loop,
}
}
}
}
另外对于清单3 描述的获取队列大小的过程,由于没有一个计数器来对队列大小计数,所以获取队列的大小只能通过从头到尾完整的遍历队列,显然这个代价是很大的。所以通常情况下ConcurrentLinkedQueue需要和一个AtomicInteger搭配才能获取队列大小。后面介绍的BlockingQueue正是使用了这种思想。
清单3 遍历队列大小
public int size() {
int count = 0;
for (Node<E> p = first(); p != null; p = p.getNext()) {
if (p.getItem() != null) {
// Collections.size() spec says to max out
if (++count == Integer.MAX_VALUE)
break;
}
}
return count;
}
参考资料:
- Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms
- 多线程基础总结十一—ConcurrentLinkedQueue
- 对ConcurrentLinkedQueue进行的并发测试
六、可阻塞的BlockingQueue(1)
在《并发容器 part 4 并发队列与Queue简介》节中的类图中可以看到,对于Queue来说,BlockingQueue是主要的线程安全版本。这是一个可阻塞的版本,也就是允许添加/删除元素被阻塞,直到成功为止。
BlockingQueue相对于Queue而言增加了两个操作:put/take。下面是一张整理的表格。
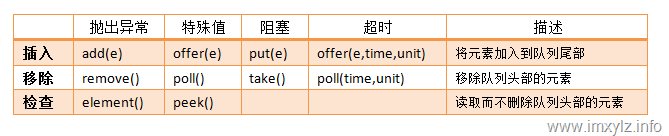
看似简单的API,非常有用。这在控制队列的并发上非常有好处。既然加入队列和移除队列能够被阻塞,这在实现生产者-消费者模型上就简单多了。
清单1 是生产者-消费者模型的一个例子。这个例子是一个真实的场景。服务端(ICE服务)接受客户端的请求(accept),请求计算此人的好友生日,然后将计算的结果存取缓存中(Memcache)中。在这个例子中采用了ExecutorService实现多线程的功能,尽可能的提高吞吐量,这个在后面线程池的部分会详细说明。目前就可以理解为new Thread(r).start()就可以了。另外这里阻塞队列使用的是LinkedBlockingQueue。
清单1 一个生产者-消费者例子
package xylz.study.concurrency;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingDeque;public class BirthdayService {
final int workerNumber;
final Worker[] workers;
final ExecutorService threadPool;
static volatile boolean running = true;
public BirthdayService(int workerNumber, int capacity) {
if (workerNumber <= 0) throw new IllegalArgumentException();
this.workerNumber = workerNumber;
workers = new Worker[workerNumber];
for (int i = 0; i < workerNumber; i++) {
workers[i] = new Worker(capacity);
}
//
boolean b = running;// kill the resorting
threadPool = Executors.newFixedThreadPool(workerNumber);
for (Worker w : workers) {
threadPool.submit(w);
}
}Worker getWorker(int id) {
return workers[id % workerNumber];}
class Worker implements Runnable {
final BlockingQueue<Integer> queue;
public Worker(int capacity) {
queue = new LinkedBlockingQueue<Integer>(capacity);
}public void run() {
while (true) {
try {
consume(queue.take());
} catch (InterruptedException e) {
return;
}
}
}void put(int id) {
try {
queue.put(id);
} catch (InterruptedException e) {
return;
}
}
}public void accept(int id) {
//accept client request
getWorker(id).put(id);
}protected void consume(int id) {
//do the work
//get the list of friends and save the birthday to cache
}
}
在清单1 中可以看到不管是put()还是get(),都抛出了一个InterruptedException。我们就从这里开始,为什么会抛出这个异常。
上一节中提到实现一个并发队列有三种方式。显然只有第二种 Lock 才能实现阻塞队列。在锁机制中提到过,Lock结合Condition就可以实现线程的阻塞,这在锁机制部分的很多工具中都详细介绍过,而接下来要介绍的LinkedBlockingQueue就是采用这种方式。
LinkedBlockingQueue 原理
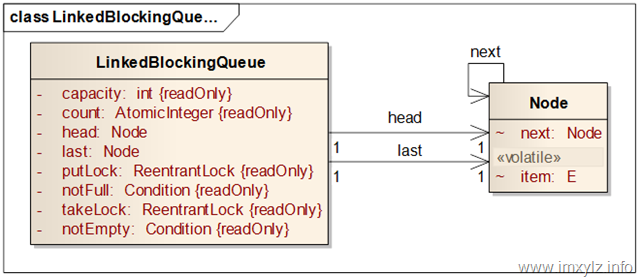 对比ConcurrentLinkedQueue的结构图,LinkedBlockingQueue多了两个ReentrantLock和两个Condition以及用于计数的AtomicInteger,显然这会导致LinkedBlockingQueue的实现有点复杂。对照此结构,有以下几点说明:
对比ConcurrentLinkedQueue的结构图,LinkedBlockingQueue多了两个ReentrantLock和两个Condition以及用于计数的AtomicInteger,显然这会导致LinkedBlockingQueue的实现有点复杂。对照此结构,有以下几点说明:
- 但是整体上讲,LinkedBlockingQueue和ConcurrentLinkedQueue的结构类似,都是采用头尾节点,每个节点指向下一个节点的结构,这表示它们在操作上应该类似。
- LinkedBlockingQueue引入了原子计数器count,这意味着获取队列大小size()已经是常量时间了,不再需要遍历队列。每次队列长度有变更时只需要修改count即可。
- 有了修改Node指向有了锁,所以不需要volatile特性了。既然有了锁Node的item为什么需要volatile在后面会详细分析,暂且不表。
- 引入了两个锁,一个入队列锁,一个出队列锁。当然同时有一个队列不满的Condition和一个队列不空的Condition。其实参照锁机制前面介绍过的生产者-消费者模型就知道,入队列就代表生产者,出队列就代表消费者。为什么需要两个锁?一个锁行不行?其实一个锁完全可以,但是一个锁意味着入队列和出队列同时只能有一个在进行,另一个必须等待其释放锁。而从ConcurrentLinkedQueue的实现原理来看,事实上head和last (ConcurrentLinkedQueue中是tail)是分离的,互相独立的,这意味着入队列实际上是不会修改出队列的数据的,同时出队列也不会修改入队列,也就是说这两个操作是互不干扰的。更通俗的将,这个锁相当于两个写入锁,入队列是一种写操作,操作head,出队列是一种写操作,操作tail。可见它们是无关的。但是并非完全无关,后面详细分析。
在没有揭示入队列和出队列过程前,暂且猜测下实现原理。
根据前面学到的锁机制原理结合ConcurrentLinkedQueue的原理,入队列的阻塞过程大概是这样的:
- 获取入队列的锁putLock,检测队列大小,如果队列已满,那么就挂起线程,等待队列不满信号notFull的唤醒。
- 将元素加入到队列尾部,同时修改队列尾部引用last。
- 队列大小加1。
- 释放锁putLock。
- 唤醒notEmpty线程(如果有挂起的出队列线程),告诉消费者,已经有了新的产品。
对比入队列,出队列的阻塞过程大概是这样的:
- 获取出队列的锁takeLock,检测队列大小,如果队列为空,那么就挂起线程,等待队列不为空notEmpty的唤醒。
- 将元素从头部移除,同时修改队列头部引用head。
- 队列大小减1。
- 释放锁takeLock。
- 唤醒notFull线程(如果有挂起的入队列线程),告诉生产者,现在还有空闲的空间。
下面来验证上面的过程。
入队列过程(put/offer)
清单2 阻塞的入队列过程
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
try {
while (count.get() == capacity)
notFull.await();
} catch (InterruptedException ie) {
notFull.signal(); // propagate to a non-interrupted thread
throw ie;
}
insert(e);
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
}
清单2 描述的是入队列的阻塞过程。可以看到和上面描述的入队列的过程基本相同。但是也有以下几个问题:
- 如果在入队列的时候线程被中断,那么就需要发出一个notFull的信号,表示下一个入队列的线程能够被唤醒(如果阻塞的话)。
- 入队列成功后如果队列不满需要补一个notFull的信号。为什么?队列不满的时候其它入队列的阻塞线程难道不知道么?有可能。这是因为为了减少上下文切换的次数,每次唤醒一个线程(不管是入队列还是出队列)都是只随机唤醒一个(notify),而不是唤醒所有的(notifyall())。这会导致其它阻塞的入队列线程不能够即使处理队列不满的情况。
- 如果队列不为空并且可能有一个元素的话就唤醒一个出队列线程。这么做说明之前队列一定为空,因为在加入队列之后队列最多只能为1,那么说明未加入之前是0,那么就可能有被阻塞的出队列线程,所以就唤醒一个出队列线程。特别说明的是为什么使用一个临时变量c,而不用count。这是因为读取一个count的开销比读取一个临时一个变量大,而此处c又能够完成确认队列最多只有一个元素的判断。首先c默认为-1,如果加入队列后获取原子计数器的结果为0,说明之前队列为空,不可能消费(出队列),也不可能入队列,因为此时锁还在当前线程上,那么加入一个后队列就不为空了,所以就可以安全的唤醒一个消费(出对立)线程。
- 入队列的过程允许被中断,所以总是抛出InterruptedException 异常。
针对第2点,特别补充说明下。本来这属于锁机制中条件队列的范围,由于没有应用场景,所以当时没有提。
前面提高notifyall总是比notify更可靠,因为notify可能丢失通知,为什么不适用notifyall呢?
先解释下notify丢失通知的问题。
notify丢失通知问题
假设线程A因为某种条件在条件队列中等待,同时线程B因为另外一种条件在同一个条件队列中等待,也就是说线程A/B都被同一个Conditon.await()挂起,但是等待的条件不同。现在假设线程B的线程被满足,线程C执行一个notify操作,此时JVM从Conditon.await()的多个线程(A/B)中随机挑选一个唤醒,不幸的是唤醒了A。此时A的条件不满足,于是A继续挂起。而此时B仍然在傻傻的等待被唤醒的信号。也就是说本来给B的通知却被一个无关的线程持有了,真正需要通知的线程B却没有得到通知,而B仍然在等待一个已经发生过的通知。
如果使用notifyall,则能够避免此问题。notifyall会唤醒所有正在等待的线程,线程C发出的通知线程A同样能够收到,但是由于对于A没用,所以A继续挂起,而线程B也收到了此通知,于是线程B正常被唤醒。
既然notifyall能够解决单一notify丢失通知的问题,那么为什么不总是使用notifyall替换notify呢?
假设有N个线程在条件队列中等待,调用notifyall会唤醒所有线程,然后这N个线程竞争同一个锁,最多只有一个线程能够得到锁,于是其它线程又回到挂起状态。这意味每一次唤醒操作可能带来大量的上下文切换(如果N比较大的话),同时有大量的竞争锁的请求。这对于频繁的唤醒操作而言性能上可能是一种灾难。
如果说总是只有一个线程被唤醒后能够拿到锁,那么为什么不使用notify呢?所以某些情况下使用notify的性能是要高于notifyall的。
如果满足下面的条件,可以使用单一的notify取代notifyall操作:
相同的等待者,也就是说等待条件变量的线程操作相同,每一个从wait放回后执行相同的逻辑,同时一个条件变量的通知至多只能唤醒一个线程。
也就是说理论上讲在put/take中如果使用sinallAll唤醒的话,那么在清单2 中的notFull.singal就是多余的。
出队列过程(poll/take)
再来看出队列过程。清单3 描述了出队列的过程。可以看到这和入队列是对称的。从这里可以看到,出队列使用的是和入队列不同的锁,所以入队列、出队列这两个操作才能并行进行。
清单3 阻塞的出队列过程
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
try {
while (count.get() == 0)
notEmpty.await();
} catch (InterruptedException ie) {
notEmpty.signal(); // propagate to a non-interrupted thread
throw ie;
}x = extract();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
为什么有异常?
有了入队列、出队列的过程后再来回答前面的几个问题。
为什么总是抛出InterruptedException 异常? 这是很大一块内容,其实是Java对线程中断的处理问题,希望能够在系列文章的最后能够对此开辟单独的篇章来谈谈。
在锁机制里面也是总遇到,这是因为,Java里面没有一种直接的方法中断一个挂起的线程,所以通常情况下等于一个处于WAITING状态的线程,允许设置一个中断位,一旦线程检测到这个中断位就会从WAITING状态退出,以一个InterruptedException 的异常返回。所以只要是对一个线程挂起操作都会导致InterruptedException 的可能,比如Thread.sleep()、Thread.join()、Object.wait()。尽管LockSupport.park()不会抛出一个InterruptedException 异常,但是它会将当前线程的的interrupted状态位置上,而对于Lock/Condition而言,当捕捉到interrupted状态后就认为线程应该终止任务,所以就抛出了一个InterruptedException 异常。
又见volatile
还有一个不容易理解的问题。为什么Node.item是volatile类型的?
起初我不大明白,因为对于一个进入队列的Node,它的item是不变,当且仅当出队列的时候会将头结点元素的item 设置为null。尽管在remove(o)的时候也是设置为null,但是那时候是加了putLock/takeLock两个锁的,所以肯定是没有问题的。那么问题出在哪?
我们知道,item的值是在put/offer的时候加入的。这时候都是有putLock锁保证的,也就是说它保证使用putLock锁的读取肯定是没有问题的。那么问题就只可能出在一个不适用putLock却需要读取Node.item的地方。
peek操作时获取头结点的元素而不移除它。显然他不会操作尾节点,所以它不需要putLock锁,也就是说它只有takeLock锁。清单4 描述了这个过程。
清单4 查询队列头元素过程
public E peek() {
if (count.get() == 0)
return null;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
Node<E> first = head.next;
if (first == null)
return null;
else
return first.item;
} finally {
takeLock.unlock();
}
}
清单4 描述了peek的过程,最后返回一个非null节点的结果是Node.item。这里读取了Node的item值,但是整个过程却是使用了takeLock而非putLock。换句话说putLock对Node.item的操作,peek()线程可能不可见!
清单5 队列尾部加入元素
private void insert(E x) {
last = last.next = new Node<E>(x);
}
清单5 是入队列offer/put的一部分,这里关键在于last=new Node<E>(x)可能发生重排序。Node构造函数是这样的:Node(E x) { item = x; }。在这一步里面我们可能得到以下一种情况:
- 构建一个Node对象n;
- 将Node的n赋给last
- 初始化n,设置item=x
在执行步骤2 的时候一个peek线程可能拿到了新的Node n,这时候它读取item,得到了一个null。显然这是不可靠的。
对item采用volatile之后,JMM保证对item=x的赋值一定在last=n之前,也就是说last得到的一个是一个已经赋值了的新节点n。这就不会导致读取空元素的问题的。
出对了poll/take和peek都是使用的takeLock锁,所以不会导致此问题。
删除操作和遍历操作由于同时获取了takeLock和putLock,所以也不会导致此问题。
总结:当前仅当元素加入队列时读取此元素才可能导致不一致的问题。采用volatile正式避免此问题。
附加功能
BlockingQueue有一个额外的功能,允许批量从队列中异常元素。这个API是:
int drainTo(Collection<? super E> c, int maxElements); 最多从此队列中移除给定数量的可用元素,并将这些元素添加到给定 collection 中。
int drainTo(Collection<? super E> c); 移除此队列中所有可用的元素,并将它们添加到给定 collection 中。
清单6 描述的是最多移除指定数量元素的过程。由于批量操作只需要一次获取锁,所以效率会比每次获取锁要高。但是需要说明的,需要同时获取takeLock/putLock两把锁,因为当移除完所有元素后这会涉及到尾节点的修改(last节点仍然指向一个已经移走的节点)。
由于迭代操作contains()/remove()/iterator()也是获取了两个锁,所以迭代操作也是线程安全的。
清单6 批量移除操作
public int drainTo(Collection<? super E> c, int maxElements) {
if (c == null)
throw new NullPointerException();
if (c == this)
throw new IllegalArgumentException();
fullyLock();
try {
int n = 0;
Node<E> p = head.next;
while (p != null && n < maxElements) {
c.add(p.item);
p.item = null;
p = p.next;
++n;
}
if (n != 0) {
head.next = p;
assert head.item == null;
if (p == null)
last = head;
if (count.getAndAdd(-n) == capacity)
notFull.signalAll();
}
return n;
} finally {
fullyUnlock();
}
}
七、可阻塞的BlockingQueue (2)
在上一节中详细分析了LinkedBlockingQueue 的实现原理。实现一个可扩展的队列通常有两种方式:一种方式就像LinkedBlockingQueue一样使用链表,也就是每一个元素带有下一个元素的引用,这样的队列原生就是可扩展的;另外一种就是通过数组实现,一旦队列的大小达到数组的容量的时候就将数组扩充一倍(或者一定的系数倍),从而达到扩容的目的。常见的ArrayList就属于第二种。前面章节介绍过的HashMap确是综合使用了这两种方式。
对于一个Queue而言,同样可以使用数组实现。使用数组的好处在于各个元素之间原生就是通过数组的索引关联起来的,一次元素之间就是有序的,在通过索引操作数组就方便多了。当然也有它不利的一面,扩容起来比较麻烦,同时删除一个元素也比较低效。
ArrayBlockingQueue 就是Queue的一种数组实现。
ArrayBlockingQueue 原理
在没有介绍ArrayBlockingQueue原理之前可以想象下,一个数组如何实现Queue的FIFO特性。首先,数组是固定大小的,这个是毫无疑问的,那么初始化就是所有元素都为null。假设数组一段为头,另一端为尾。那么头和尾之间的元素就是FIFO队列。
- 入队列就将尾索引往右移动一个,新元素加入尾索引的位置;
- 出队列就将头索引往尾索引方向移动一个,同时将旧头索引元素设为null,返回旧头索引的元素。
- 一旦数组已满,那么就不允许添加新元素(除非扩充容量)
- 如果尾索引移到了数组的最后(最大索引处),那么就从索引0开始,形成一个“闭合”的数组。
- 由于头索引和尾索引之间的元素都不能为空(因为为空不知道take出来的元素为空还是队列为空),所以删除一个头索引和尾索引之间的元素的话,需要移动删除索引前面或者后面的所有元素,以便填充删除索引的位置。
- 由于是阻塞队列,那么显然需要一个锁,另外由于只是一份数据(一个数组),所以只能有一个锁,也就是同时只能有一个线程操作队列。
有了上述几点分析,设计一个可阻塞的数组队列就比较容易了。
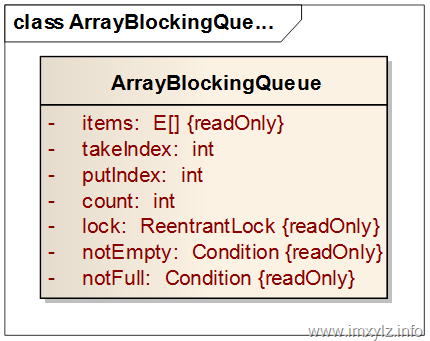
上图描述的ArrayBlockingQueue的数据结构。首先有一个数组E[],用来存储所有的元素。由于ArrayBlockingQueue最终设置为一个不可扩展大小的Queue,所以这里items就是初始化就固定大小的数组(final类型);另外有两个索引,头索引takeIndex,尾索引putIndex;一个队列的大小count;要支持阻塞就必须需要一个锁lock和两个条件(非空、非满),这三个元素都是不可变更类型的(final)。
由于只有一把锁,所以任何时刻对队列的操作都只有一个线程,这意味着对索引和大小的操作都是线程安全的,所以可以看到这个takeIndex/putIndex/count就不需要原子操作和volatile语义了。
清单1 描述的是一个可阻塞的添加元素过程。这与前面介绍的消费者、生产者模型相同。如果队列已经满了就挂起等待,否则就插入元素,同时唤醒一个队列已空的线程。对比清单2 可以看到是完全相反的两个过程。这在前面几种实现生产者-消费者模型的时候都介绍过了。
清单1 可阻塞的添加元素
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
final E[] items = this.items;
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
try {
while (count == items.length)
notFull.await();
} catch (InterruptedException ie) {
notFull.signal(); // propagate to non-interrupted thread
throw ie;
}
insert(e);
} finally {
lock.unlock();
}
}
清单2 可阻塞的移除元素
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
try {
while (count == 0)
notEmpty.await();
} catch (InterruptedException ie) {
notEmpty.signal(); // propagate to non-interrupted thread
throw ie;
}
E x = extract();
return x;
} finally {
lock.unlock();
}
}
需要注意到的是,尽管每次加入、移除一个元素使用的都是signal()通知,而不是signalAll()通知。我们参考上一节中notify替换notifyAll的原则:每一个await醒来的动作相同,每次最多唤醒一个线程来操作。显然这里符合这两种条件,因此使用signal要比使用signalAll要高效,并且是可靠的。
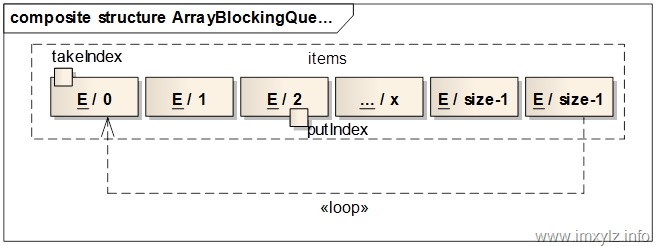 上图描述了take()/put()的索引位置示意图。
上图描述了take()/put()的索引位置示意图。
一开始takeIndex/putIndex都在E/0位置,然后每加入一个元素offer/put,putIndex都增加1,也就是往后边移动一位;每移除一个元素poll/take,takeIndex都增加1,也是往后边移动一位,显然takeIndex总是在putIndex的“后边”,因为当队列中没有元素的时候takeIndex和putIndex相等,同时当前位置也没有元素,takeIndex也就是无法再往右边移动了;一旦putIndex/takeIndex移动到了最后面,也就是size-1的位置(这里size是指数组的长度),那么就移动到0,继续循环。循环的前提是数组中元素的个数小于数组的长度。整个过程就是这样的。可见putIndex同时指向头元素的下一个位置(如果队列已经满了,那么就是尾元素位置,否则就是一个元素为null的位置)。
比较复杂的操作时删除任意一个元素。清单3 描述的是删除任意一个元素的过程。显然删除任何一个元素需要遍历整个数组,也就是它的复杂度是O(n),这与根据索引从ArrayList中查找一个元素的复杂度O(1)相比开销要大得多。参考声明的结构图,一旦删除的是takeIndex位置的元素,那么只需要将takeIndex往“右边”移动一位即可;如果删除的是takeIndex和putIndex之间的元素怎么办?这时候就从删除的位置i开始,将i后面的所有元素位置都往“左”移动一位,直到putIndex为止。最终的结果是删除位置的所有元素都“后退”了一个位置,同时putIndex也后退了一个位置。
清单3 删除任意一个元素
public boolean remove(Object o) {
if (o == null) return false;
final E[] items = this.items;
final ReentrantLock lock = this.lock;
lock.lock();
try {
int i = takeIndex;
int k = 0;
for (;;) {
if (k++ >= count)
return false;
if (o.equals(items[i])) {
removeAt(i);
return true;
}
i = inc(i);
}} finally {
lock.unlock();
}
}
void removeAt(int i) {
final E[] items = this.items;
// if removing front item, just advance
if (i == takeIndex) {
items[takeIndex] = null;
takeIndex = inc(takeIndex);
} else {
// slide over all others up through putIndex.
for (;;) {
int nexti = inc(i);
if (nexti != putIndex) {
items[i] = items[nexti];
i = nexti;
} else {
items[i] = null;
putIndex = i;
break;
}
}
}
--count;
notFull.signal();
}
对于其他的操作,由于都是带着Lock的操作,所以都比较简单就不再展开了。
下一篇中将介绍另外两个BlockingQueue, PriorityBlockingQueue和SynchronousQueue 然后对这些常见的Queue进行一个小范围的对比。
八、可阻塞的BlockingQueue (3)
在Set中有一个排序的集合SortedSet,用来保存按照自然顺序排列的对象。Queue中同样引入了一个支持排序的FIFO模型。
并发队列与Queue简介 中介绍了,PriorityQueue和PriorityBlockingQueue就是支持排序的Queue。显然一个支持阻塞的排序Queue要比一个非线程安全的Queue实现起来要复杂的多,因此下面只介绍PriorityBlockingQueue,至于PriorityQueue只需要去掉Blocking功能就基本相同了。
排序的BlockingQueue — PriorityBlockingQueue
先简单介绍下PriorityQueue,因为PriorityBlockingQueue内部就是通过PriorityQueue适配实现的,只不过通过锁进行同步和阻塞而已。
PriorityQueue是一个数组实现的,是一个二叉树的实现,这个二叉树的任意一个节点都比其子节点要小,这样顶点就是最小的节点。每一个元素或者节点要么本身是可比较的(Comparable),或者队列本身带有一个比较器(Comparator<? super E>),所有元素就是靠比较自身的大小来确定顺序的。而数组中顶点就是数组的第0个元素,因此出队列的话总是取第0个元素。对于第0个元素,其子节点是第1个元素和第2个元素,对于第1个元素,其子元素又是第3/4个元素,以此类推,第i个元素的父节点就是(i-1)/2。这样任意一个元素加入队列就从其父节点(i-1)/2开始比较,一旦新节点比父节点小就交换两个节点,然后继续比较新节点与其新的父节点。知道所有节点都是按照父节点一定比子节点小的顺序排列。这是一个有点复杂的算法,此处不再讨论更多的细节。不管是删除还是查找,我们只需要了解的顶点(索引为0的元素)总是最小的。
特别需要说明的是PriorityQueue是一个无界的队列,也就是说一旦元素的个数达到了数组的大小,那么就将数组扩大50%,这样这个数组就是无穷大的。当然了如果达到了整数的最大值就会得到一个OutOfMemoryError,这个是由逻辑保证的。
对于PriorityBlockingQueue而言,由于是无界的,因此就只有非空的信号,也就是说只有take()才能阻塞,put是永远不会阻塞(除非达到Integer.MAX_VALUE直到抛出一个OutOfMemoryError异常)。
只有take()操作的时候才可能因为队列为空而挂起。同时其它需要操作队列变化和大小的只需要使用独占锁ReentrantLock就可以了,非常方便。需要说明的是PriorityBlockingQueue采用了一个公平的锁。
总的来说PriorityBlockingQueue 不是一个FIFO的队列,而是一个有序的队列,这个队列总是取“自然顺序”最小的对象,同时又是一个只能出队列阻塞的BlockingQueue,对于入队列却不是阻塞的。所有操作都是线程安全的。
直接交换的BlockingQueue — SynchronousQueue
这是一个很有意思的阻塞队列,其中每个插入操作必须等待另一个线程的移除操作,同样任何一个移除操作都等待另一个线程的插入操作。因此此队列内部其实没有任何一个元素,或者说容量是0,严格说并不是一种容器。由于队列没有容量,因此不能调用peek操作,因为只有移除元素时才有元素。
一个没有容量的并发队列有什么用了?或者说存在的意义是什么?
SynchronousQueue 的实现非常复杂,当然了如果真要去分析还是能够得到一些经验的,但是前面分析了过多的结构后,发现越来越陷于数据结构与算法里面了。我的初衷是通过研究并发实现的原理来更好的利用并发来最大限度的利用可用资源。所以在后面的章节中尽可能的少研究数据结构和算法,但是为了弄清楚里面的原理,必不可免的会涉及到一些这方面的知识,希望后面能够适可而止。
再回到话题。SynchronousQueue 内部没有容量,但是由于一个插入操作总是对应一个移除操作,反过来同样需要满足。那么一个元素就不会再SynchronousQueue 里面长时间停留,一旦有了插入线程和移除线程,元素很快就从插入线程移交给移除线程。也就是说这更像是一种信道(管道),资源从一个方向快速传递到另一方向。
需要特别说明的是,尽管元素在SynchronousQueue 内部不会“停留”,但是并不意味之SynchronousQueue 内部没有队列。实际上SynchronousQueue 维护者线程队列,也就是插入线程或者移除线程在不同时存在的时候就会有线程队列。既然有队列,同样就有公平性和非公平性特性,公平性保证正在等待的插入线程或者移除线程以FIFO的顺序传递资源。
显然这是一种快速传递元素的方式,也就是说在这种情况下元素总是以最快的方式从插入着(生产者)传递给移除着(消费者),这在多任务队列中是最快处理任务的方式。在线程池的相关章节中还会更多的提到此特性。
事实上在《并发队列与Queue简介》中介绍了还有一种BlockingQueue的实现DelayQueue,它描述的是一种延时队列。这个队列的特性是,队列中的元素都要延迟时间(超时时间),只有一个元素达到了延时时间才能出队列,也就是说每次从队列中获取的元素总是最先到达延时的元素。这种队列的场景就是计划任务。比如以前要完成计划任务,很有可能是使用Timer/TimerTask,这是一种循环检测的方式,也就是在循环里面遍历所有元素总是检测元素是否满足条件,一旦满足条件就执行相关任务。显然这中方式浪费了很多的检测工作,因为大多数时间总是在进行无谓的检测。而DelayQueue 却能避免这种无谓的检测。在线程池的计划任务部分还有更加详细的讨论此队列实现。
下面就对常见的BlockingQueue进行小节下,这里不包括双向的队列,尽管ConcurrentLinkedQueue不是可阻塞的Queue,但是这里还是将其放在一起进行对比。
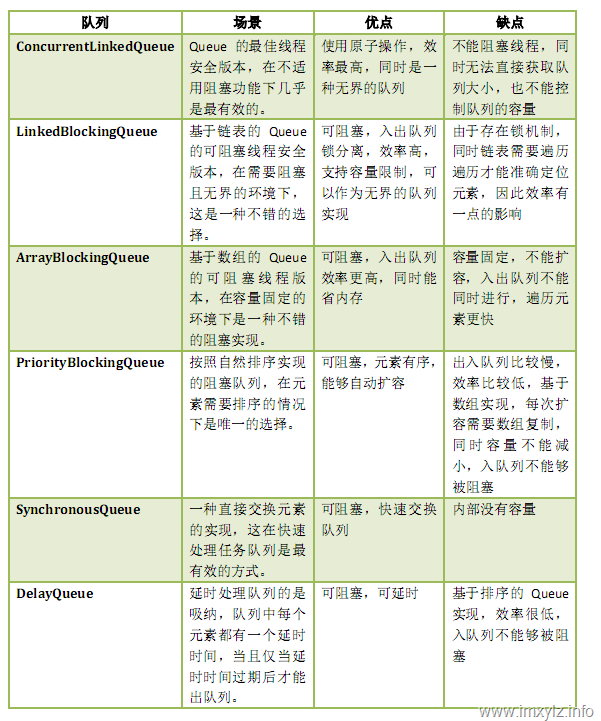
如果不需要阻塞队列,优先选择ConcurrentLinkedQueue;如果需要阻塞队列,队列大小固定优先选择ArrayBlockingQueue,队列大小不固定优先选择LinkedBlockingQueue;如果需要对队列进行排序,选择PriorityBlockingQueue;如果需要一个快速交换的队列,选择SynchronousQueue;如果需要对队列中的元素进行延时操作,则选择DelayQueue。
九、 双向队列Deque
Queue除了前面介绍的实现外,还有一种双向的Queue实现Deque。这种队列允许在队列头和尾部进行入队出队操作,因此在功能上比Queue显然要更复杂。下图描述的是Deque的完整体系图。需要说明的是LinkedList也已经加入了Deque的一部分(LinkedList是从jdk1.2 开始就存在数据结构)。
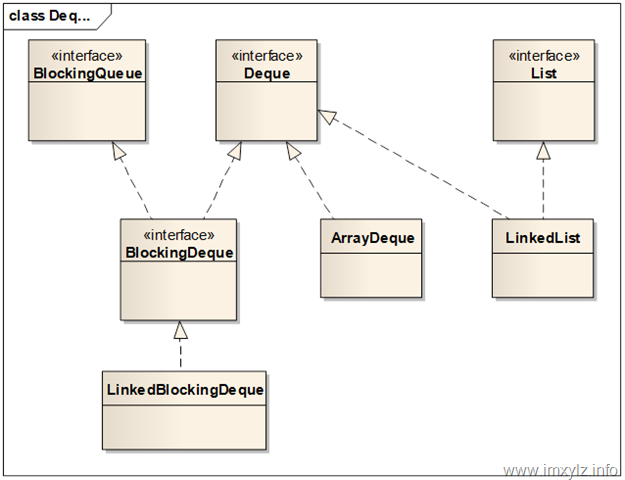
Deque在Queue的基础上增加了更多的操作方法。
从上图可以看到,Deque不仅具有FIFO的Queue实现,也有FILO的实现,也就是不仅可以实现队列,也可以实现一个堆栈。
同时在Deque的体系结构图中可以看到,实现一个Deque可以使用数组(ArrayDeque),同时也可以使用链表(LinkedList),还可以同实现一个支持阻塞的线程安全版本队列LinkedBlockingDeque。
对于数组实现的Deque来说,数据结构上比较简单,只需要一个存储数据的数组以及头尾两个索引即可。由于数组是固定长度的,所以很容易就得到数组的头和尾,那么对于数组的操作只需要移动头和尾的索引即可。
特别说明的是ArrayDeque并不是一个固定大小的队列,每次队列满了以后就将队列容量扩大一倍(doubleCapacity()),因此加入一个元素总是能成功,而且也不会抛出一个异常。也就是说ArrayDeque是一个没有容量限制的队列。
同样继续性能的考虑,使用System.arraycopy复制一个数组比循环设置要高效得多。

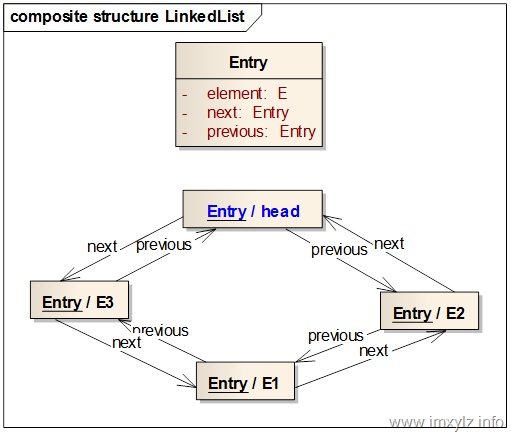
对于LinkedList本身而言,数据结构就更简单了,除了一个size用来记录大小外,只有head一个元素Entry。对比Map和Queue的其它数据结构可以看到这里的Entry有两个引用,是双向的队列。
在示意图中,LinkedList总是有一个“傀儡”节点,用来描述队列“头部”,但是并不表示头部元素,它是一个执行null的空节点。
队列一开始只有head一个空元素,然后从尾部加入E1(add/addLast),head和E1之间建立双向链接。然后继续从尾部加入E2,E2就在head和E1之间建立双向链接。最后从队列的头部加入E3(push/addFirst),于是E3就在E1和head之间链接双向链接。
双向链表的数据结构比较简单,操作起来也比较容易,从事从“傀儡”节点开始,“傀儡”节点的下一个元素就是队列的头部,前一个元素是队列的尾部,换句话说,“傀儡”节点在头部和尾部之间建立了一个通道,是整个队列形成一个循环,这样就可以从任意一个节点的任意一个方向能遍历完整的队列。
同样LinkedList也是一个没有容量限制的队列,因此入队列(不管是从头部还是尾部)总能成功。
上面描述的ArrayDeque和LinkedList是两种不同方式的实现,通常在遍历和节省内存上ArrayDeque更高效(索引更快,另外不需要Entry对象),但是在队列扩容下LinkedList更灵活,因为不需要复制原始的队列,某些情况下可能更高效。
同样需要注意的上述两个实现都不是线程安全的,因此只适合在单线程环境下使用,下面章节要介绍的LinkedBlockingDeque就是线程安全的可阻塞的Deque。事实上也应该是功能最强大的Queue实现,当然了实现起来也许会复杂一点。
十、双向并发阻塞队列BlockingDeque
这个小节介绍Queue的最后一个工具,也是最强大的一个工具。从名称上就可以看到此工具的特点:双向并发阻塞队列。所谓双向是指可以从队列的头和尾同时操作,并发只是线程安全的实现,阻塞允许在入队出队不满足条件时挂起线程,这里说的队列是指支持FIFO/FILO实现的链表。
首先看下LinkedBlockingDeque的数据结构。通常情况下从数据结构上就能看出这种实现的优缺点,这样就知道如何更好的使用工具了。
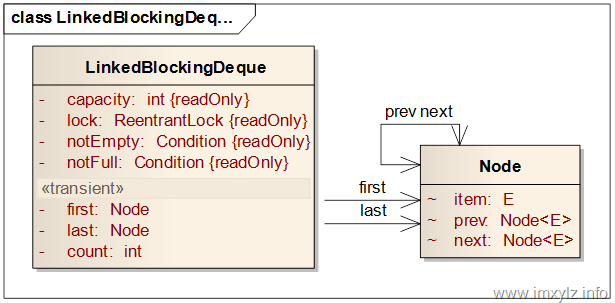
从数据结构和功能需求上可以得到以下结论:
- 要想支持阻塞功能,队列的容量一定是固定的,否则无法在入队的时候挂起线程。也就是capacity是final类型的。
- 既然是双向链表,每一个结点就需要前后两个引用,这样才能将所有元素串联起来,支持双向遍历。也即需要prev/next两个引用。
- 双向链表需要头尾同时操作,所以需要first/last两个节点,当然可以参考LinkedList那样采用一个节点的双向来完成,那样实现起来就稍微麻烦点。
- 既然要支持阻塞功能,就需要锁和条件变量来挂起线程。这里使用一个锁两个条件变量来完成此功能。
有了上面的结论再来研究LinkedBlockingDeque的优缺点。
优点当然是功能足够强大,同时由于采用一个独占锁,因此实现起来也比较简单。所有对队列的操作都加锁就可以完成。同时独占锁也能够很好的支持双向阻塞的特性。
凡事有利必有弊。缺点就是由于独占锁,所以不能同时进行两个操作,这样性能上就大打折扣。从性能的角度讲LinkedBlockingDeque要比LinkedBlockingQueue要低很多,比CocurrentLinkedQueue就低更多了,这在高并发情况下就比较明显了。
前面分析足够多的Queue实现后,LinkedBlockingDeque的原理和实现就不值得一提了,无非是在独占锁下对一个链表的普通操作。
有趣的是此类支持序列化,但是Node并不支持序列化,因此fist/last就不能序列化,那么如何完成序列化/反序列化过程呢?
清单1 LinkedBlockingDeque的序列化、反序列化
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
lock.lock();
try {
// Write out capacity and any hidden stuff
s.defaultWriteObject();
// Write out all elements in the proper order.
for (Node<E> p = first; p != null; p = p.next)
s.writeObject(p.item);
// Use trailing null as sentinel
s.writeObject(null);
} finally {
lock.unlock();
}
}private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
s.defaultReadObject();
count = 0;
first = null;
last = null;
// Read in all elements and place in queue
for (;;) {
E item = (E)s.readObject();
if (item == null)
break;
add(item);
}
}
清单1 描述的是LinkedBlockingDeque序列化/反序列化的过程。序列化时将真正的元素写入输出流,最后还写入了一个null。读取的时候将所有对象列表读出来,如果读取到一个null就表示结束。这就是为什么写入的时候写入一个null的原因,因为没有将count写入流,所以就靠null来表示结束,省一个整数空间。
十一、Exchanger
可以在对中对元素进行配对和交换的线程的同步点。每个线程将条目上的某个方法呈现给 exchange 方法,与伙伴线程进行匹配,并且在返回时接收其伙伴的对象。Exchanger 可能被视为 SynchronousQueue 的双向形式。
换句话说Exchanger提供的是一个交换服务,允许原子性的交换两个(多个)对象,但同时只有一对才会成功。先看一个简单的实例模型。
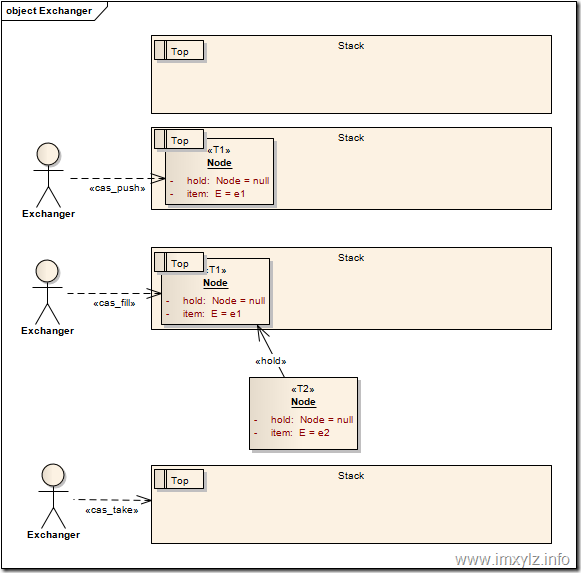
在上面的模型中,我们假定一个空的栈(Stack),栈顶(Top)当然是没有元素的。同时我们假定一个数据结构Node,包含一个要交换的元素E和一个要填充的“洞”Node。这时线程T1携带节点node1进入栈(cas_push),当然这是CAS操作,这样栈顶就不为空了。线程T2携带节点node2进入栈,发现栈里面已经有元素了node1,同时发现node1的hold(Node)为空,于是将自己(node2)填充到node1的hold中(cas_fill)。然后将元素node1从栈中弹出(cas_take)。这样线程T1就得到了node1.hold.item也就是node2的元素e2,线程T2就得到了node1.item也就是e1,从而达到了交换的目的。
算法描述就是下图展示的内容。
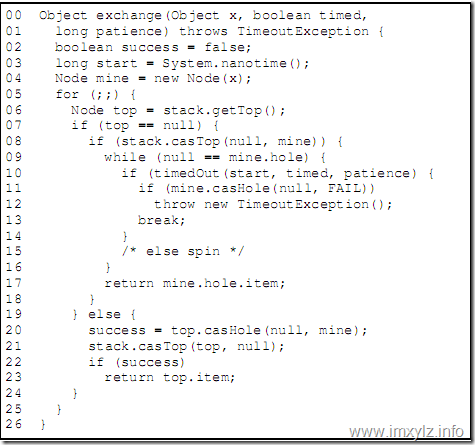
JDK 5就是采用类似的思想实现的Exchanger。JDK 6以后为了支持多线程多对象同时Exchanger了就进行了改造(为了支持更好的并发),采用ConcurrentHashMap的思想,将Stack分割成很多的片段(或者说插槽Slot),线程Id(Thread.getId())hash相同的落在同一个Slot上,这样在默认32个Slot上就有很好的吞吐量。当然会根据机器CPU内核的数量有一定的优化,有兴趣的可以去了解下Exchanger的源码。
至于Exchanger的使用,在JDK文档上有个例子,讲述的是两个线程交换数据缓冲区的例子(实际上仍然可以认为是生产者/消费者模型)。
Exchanger<DataBuffer> exchanger = new Exchanger<DataBuffer>();
DataBuffer initialEmptyBuffer =
 a made-up type
a made-up typeDataBuffer initialFullBuffer =
class FillingLoop implements Runnable {
public void run() {
DataBuffer currentBuffer = initialEmptyBuffer;
try {
while (currentBuffer != null) {
addToBuffer(currentBuffer);
if (currentBuffer.isFull())
currentBuffer = exchanger.exchange(currentBuffer);
}
} catch (InterruptedException ex) { handle }
}
}
class EmptyingLoop implements Runnable {
public void run() {
DataBuffer currentBuffer = initialFullBuffer;
try {
while (currentBuffer != null) {
takeFromBuffer(currentBuffer);
if (currentBuffer.isEmpty())
currentBuffer = exchanger.exchange(currentBuffer);
}
} catch (InterruptedException ex) { handle }
}
}
void start() {
new Thread(new FillingLoop()).start();
new Thread(new EmptyingLoop()).start();
}
}
Exchanger实现的是一种数据分片的思想,这在大数据情况下将数据分成一定的片段并且多线程执行的情况下有一定的使用价值。
最近一直推托工作忙,更新频度越来越低了,好在现在的工作还有点个人时间,以后争取多更新下吧,至少也要把这个专辑写完。
十二、线程安全的List/Set
本小节是《并发容器》的最后一部分,这一个小节描述的是针对List/Set接口的一个线程版本。
在《并发队列与Queue简介》中介绍了并发容器的一个概括,主要描述的是Queue的实现。其中特别提到一点LinkedList是List/Queue的实现,但是LinkedList确实非线程安全的。不管BlockingQueue还是ConcurrentMap的实现,我们发现都是针对链表的实现,当然尽可能的使用CAS或者Lock的特性,同时都有通过锁部分容器来提供并发的特性。而对于List或者Set而言,增、删操作其实都是针对整个容器,因此每次操作都不可避免的需要锁定整个容器空间,性能肯定会大打折扣。要实现一个线程安全的List/Set,只需要在修改操作的时候进行同步即可,比如使用java.util.Collections.synchronizedList(List<T>)或者java.util.Collections.synchronizedSet(Set<T>)。当然也可以使用Lock来实现线程安全的List/Set。
通常情况下我们的高并发都发生在“多读少写”的情况,因此如果能够实现一种更优秀的算法这对生产环境还是很有好处的。ReadWriteLock当然是一种实现。CopyOnWriteArrayList/CopyOnWriteArraySet确实另外一种思路。
CopyOnWriteArrayList/CopyOnWriteArraySet的基本思想是一旦对容器有修改,那么就“复制”一份新的集合,在新的集合上修改,然后将新集合复制给旧的引用。当然了这部分少不了要加锁。显然对于CopyOnWriteArrayList/CopyOnWriteArraySet来说最大的好处就是“读”操作不需要锁了。
我们来看看源码。
private volatile transient Object[] array;
public E get(int index) {
return (E)(getArray()[index]);
}
private static int indexOf(Object o, Object[] elements,
int index, int fence) {
if (o == null) {
for (int i = index; i < fence; i++)
if (elements[i] == null)
return i;
} else {
for (int i = index; i < fence; i++)
if (o.equals(elements[i]))
return i;
}
return -1;
}
public Iterator<E> iterator() {
return new COWIterator<E>(getArray(), 0);
}
public void clear() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
setArray(new Object[0]);
} finally {
lock.unlock();
}
}
对于上述代码,有几点说明:
- List仍然是基于数组的实现,因为只有数组是最快的。
- 为了保证无锁的读操作能够看到写操作的变化,因此数组array是volatile类型的。
- get/indexOf/iterator等操作都是无锁的,同时也可以看到所操作的都是某一时刻array的镜像(这得益于数组是不可变化的)
- add/set/remove/clear等元素变化的都是需要加锁的,这里使用的是ReentrantLock。
这里有一段有意思的代码片段。
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
Object oldValue = elements[index];
if (oldValue != element) {
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len);
newElements[index] = element;
setArray(newElements);
} else {
// Not quite a no-op; ensures volatile write semantics
setArray(elements);
}
return (E)oldValue;
} finally {
lock.unlock();
}
}
final void setArray(Object[] a) {
array = a;
}
对于set操作,如果元素有变化,修改后setArray(newElements);将新数组赋值还好理解。那么如果一个元素没有变化,也就是上述代码的else部分,为什么还需要进行一个无谓的setArray操作?毕竟setArray操作没有改变任何数据。
对于这个问题也是很有意思,有一封邮件讨论了此问题(1、2、3)。
大致的意思是,尽管没有改变任何数据,但是为了保持“volatile”的语义,任何一个读操作都应该是一个写操作的结果,也就是读操作看到的数据一定是某个写操作的结果(尽管写操作没有改变数据本身)。所以这里即使不设置也没有问题,仅仅是为了一个语义上的补充(个人理解)。
这里还有一个有意思的讨论,说什么addIfAbsent在元素没有变化的时候为什么没有setArray操作?这个要看怎么理解addIfAbsent的语义了。如果说addIfAbsent语义是”写“或者”不写“操作,而把”不写“操作当作一次”读“操作的话,那么”读“操作就不需要保持volatile语义了。
对于CopyOnWriteArraySet而言就简单多了,只是持有一个CopyOnWriteArrayList,仅仅在add/addAll的时候检测元素是否存在,如果存在就不加入集合中。
/**
* Creates an empty set.
*/
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
public boolean add(E e) {
return al.addIfAbsent(e);
}
在使用上CopyOnWriteArrayList/CopyOnWriteArraySet就简单多了,和List/Set基本相同,这里就不再介绍了。
整个并发容器结束了,接下来好好规划下线程池部分,然后进入最后一部分的梳理。
Java多线程(六) —— 线程并发库之并发容器的更多相关文章
- Java多线程(六) 线程系列总结
多线程系列终于终结得差不多,本人对该系列所做的总结大致如下: 线程锁模块耗费了大量的时间,底层的AQS实现比较复杂.仍然没有时间总结源码部分,能够坚持写下这么几个篇幅的内容真心佩服自己....希望继续 ...
- Java多线程父子线程关系 多线程中篇(六)
有的时候对于Java多线程,我们会听到“父线程.子线程”的概念. 严格的说,Java中不存在实质上的父子关系 没有方法可以获取一个线程的父线程,也没有方法可以获取一个线程所有的子线程 子线程的消亡与父 ...
- Java多线程之线程的同步
Java多线程之线程的同步 实际开发中我们也经常提到说线程安全问题,那么什么是线程安全问题呢? 线程不安全就是说在多线程编程中出现了错误情况,由于系统的线程调度具有一定的随机性,当使用多个线程来访问同 ...
- Java多线程与线程池技术
一.序言 Java多线程编程线程池被广泛使用,甚至成为了标配. 线程池本质是池化技术的应用,和连接池类似,创建连接与关闭连接属于耗时操作,创建线程与销毁线程也属于重操作,为了提高效率,先提前创建好一批 ...
- Java多线程之线程其他类
Java多线程之线程其他类 实际编码中除了前面讲到的常用的类之外,还有几个其他类也有可能用得到,这里来统一整理一下: 1,Callable接口和Future接口 JDK1.5以后提供了上面这2个接口, ...
- Java多线程之线程的控制
Java多线程之线程的控制 线程中的7 种非常重要的状态: 初始New.可运行Runnable.运行Running.阻塞Blocked.锁池lock_pool.等待队列wait_pool.结束Dea ...
- Java多线程之线程的生命周期
Java多线程之线程的生命周期 一.前言 当线程被创建并启动以后,它既不是一启动就进入了执行状态,也不是一直处于执行状态.在线程的生命周期中,它要经过新建(New).就绪(Runnable).运行(R ...
- Java多线程| 01 | 线程概述
Java多线程| 01 | 线程概述 线程相关概念 进程与线程 进程:进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是操作系统进行资源分配与调度的基本单位.可以把进程简单的理解 ...
- Java 多线程:线程池
Java 多线程:线程池 作者:Grey 原文地址: 博客园:Java 多线程:线程池 CSDN:Java 多线程:线程池 工作原理 线程池内部是通过队列结合线程实现的,当我们利用线程池执行任务时: ...
随机推荐
- js,jsp里将数据库Date类型获取出来后格式化显示于界面
js:new Date(rowdata.updateTime).format("yyyy-MM-dd hh:mm:ss") jsp: <fmt:formatDate valu ...
- java中object数据怎么转换成json数据
可以通过这个(json-lib-2.3-jdk15.jar)jar里的方法转换 JSONObject json = JSONObject.fromObject(Object); 如果对象数组 JSON ...
- MySQL数据库常用操作语法
1. 数据库初始化配置 1.1. 创建数据库 create database apps character set utf8 collate utf8_bin;创建数据库”app“,指定编码为utf8 ...
- Appium安卓与环境配置
下载与安装: Appium-desktop项目地址:https://github.com/appium/appium-desktop 下载地址:https://github.com/appium/ap ...
- charles工具教程
本文的内容主要包括: Charles 的简介 如何安装 Charles 将 Charles 设置成系统代理 Charles 主界面介绍 过滤网络请求 截取 iPhone 上的网络封包 截取 Https ...
- First Day!
刚申请博客第一天,多多关照! 小弟,给各位大佬递茶! 出现什么错误, 还请明确指出! 现在, 正在找工作, 如果有老哥, 公司缺人, 何不让老弟我去试试! 不入前端, 不知水深. 一入前端, 如入泥潭 ...
- Java的POI的封装与应用
Java对Excel表格的导出一直是对我有种可怕噩梦的东西,每次对要建立行与列,并一个一个放值,我是从心底拒绝的. 处于项目需求,需要导出表格,于是找到网上一版很好的开发, <不想用POI?几行 ...
- Netty源码分析第5章(ByteBuf)---->第10节: SocketChannel读取数据过程
Netty源码分析第五章: ByteBuf 第十节: SocketChannel读取数据过程 我们第三章分析过客户端接入的流程, 这一小节带大家剖析客户端发送数据, Server读取数据的流程: 首先 ...
- 欧拉筛——$O(n)$复杂度的质数筛法
欧拉筛法可以以\(O(n)\)的时间,空间复杂度求出\(1-n\)范围内的所有质数. 其核心思想是每个合数仅会被其最小的质因数筛去一次. See this website for more detai ...
- Workbook对象的方法总结(二)
(1).Worksheet 对象有 row_dimensions 和 column_dimensions 属性,控制行高和列宽. 例如: >>> sheet.row_dimensio ...