Elasticsearch 6.x 入门测试
首先听一下官方的话:
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
我尝试了使用Java作为Client向ES操作,结果发现这个家伙要引入大量的JAR包,而且还必须是JDK1.8!!!!!我只好使用python操作ES写入和操作数据了。
1、创建mapping
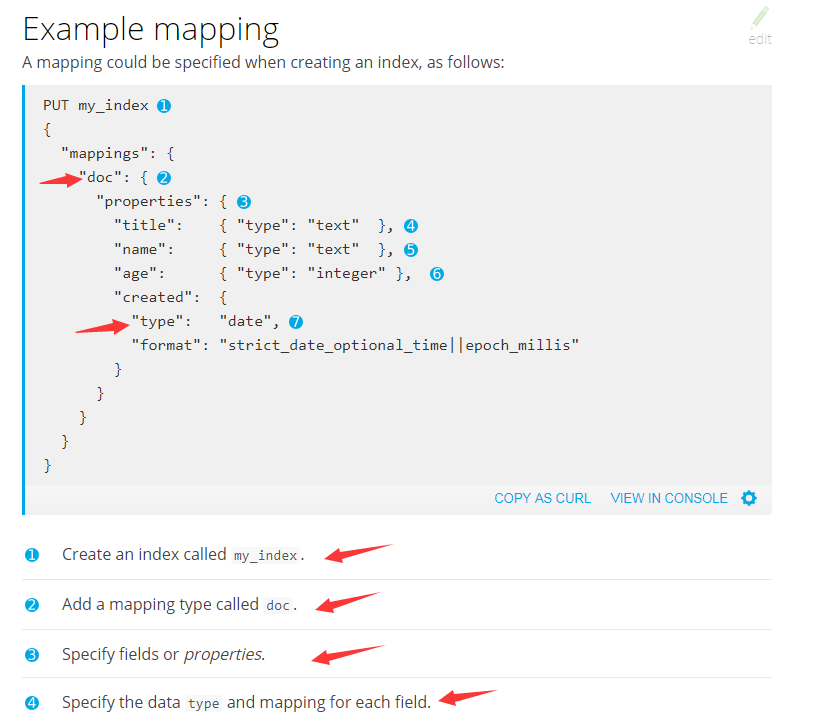
参考地址:
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-get-mapping.html
对应的python是这样的:
from elasticsearch import Elasticsearch
es_servers = [{
"host": "10.10.6.225",
"port": ""
}]
# 使用文档在这里:http://elasticsearch-py.readthedocs.io/en/master/
es = Elasticsearch(es_servers)
# 初始化索引的Mappings设置
_index_mappings = {
"mappings": {
"doc": {
"properties": {
"title": {"type": "text"},
"name": {"type": "text"},
"age": {"type": "integer"},
"created": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
}
}
}
# 如果索引不存在,则创建索引
if es.indices.exists(index='blog_index') is not True:
es.indices.create(index='blog_index', body=_index_mappings)
2、查看mapping
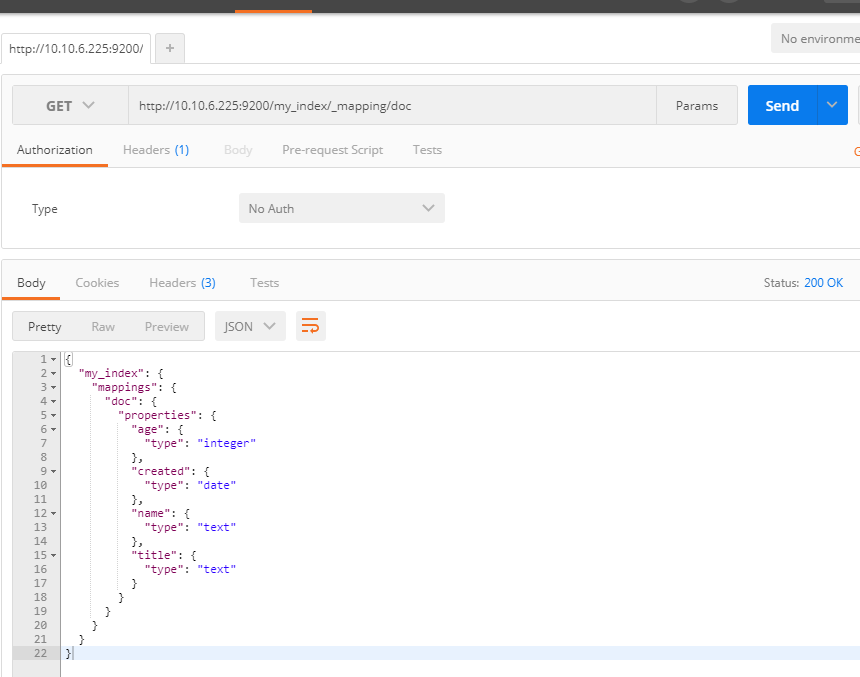
URL:http://10.10.6.225:9200/my_index/_mapping/doc
方式:GET
返回:
{
"my_index": {
"mappings": {
"doc": {
"properties": {
"age": {
"type": "integer"
},
"created": {
"type": "date"
},
"name": {
"type": "text"
},
"title": {
"type": "text"
}
}
}
}
}
}
参考网址:https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-get-mapping.html
python的脚本在这里:
# pip install elasticsearch
from elasticsearch import Elasticsearch
es_servers = [{
"host": "10.10.6.225",
"port": ""
}]
# 使用文档在这里:http://elasticsearch-py.readthedocs.io/en/master/
es = Elasticsearch(es_servers)
print(es.indices.get(index='blog_index')['blog_index']['mappings'])
返回:
C:\Python36\python.exe D:/Work/ELK/run.py
{'doc': {'properties': {'age': {'type': 'integer'}, 'created': {'type': 'date'}, 'name': {'type': 'text'}, 'title': {'type': 'text'}}}} Process finished with exit code 0
3、如果你想更新Mapping,那么就看看这里吧:

就是不行,不行,作废,重导入!!!!!
4、上传一些数据玩玩吧!
# pip install elasticsearch
import time
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk es_servers = [{
"host": "10.10.6.225",
"port": ""
}]
# 使用文档在这里:http://elasticsearch-py.readthedocs.io/en/master/
es = Elasticsearch(es_servers)
index_name = 'blog_index'
doc_type_name = 'doc' # 创建ACTIONS
ACTIONS = [] line_list = [
{'age': 25, 'created': '2018-02-09 12:00:01', 'name': '黄海', 'title': '厉害了我的国'},
{'age': 32, 'created': '2018-02-19 12:00:01', 'name': '李勇', 'title': '红海行动'},
{'age': 25, 'created': '2018-02-13 12:00:01', 'name': '赵志', 'title': '湄公河行动'},
{'age': 22, 'created': '2018-02-03 12:00:01', 'name': '李四', 'title': '极品相师'},
{'age': 18, 'created': '2018-02-01 12:00:01', 'name': '刘勇', 'title': '乡村爱情故事'}, {'age': 43, 'created': '2018-01-01 12:00:01', 'name': '刘勇', 'title': '乡村爱情故事'},
{'age': 28, 'created': '2018-01-02 12:00:01', 'name': '刘勇', 'title': '乡村爱情故事'},
{'age': 23, 'created': '2018-01-04 12:00:01', 'name': '刘勇', 'title': '乡村爱情故事'},
{'age': 22, 'created': '2018-03-01 12:00:01', 'name': '刘勇', 'title': '乡村爱情故事'},
{'age': 21, 'created': '2018-03-01 12:00:01', 'name': '刘勇', 'title': '乡村爱情故事'},
{'age': 25, 'created': '2018-03-01 12:00:01', 'name': '刘勇', 'title': '乡村爱情故事'},
{'age': 34, 'created': '2018-03-01 12:00:01', 'name': '刘勇', 'title': '乡村爱情故事'}, {'age': 33, 'created': '2017-04-01 12:00:01', 'name': '刘勇', 'title': '乡村爱情故事'},
{'age': 54, 'created': '2017-04-01 12:00:01', 'name': '刘勇', 'title': '乡村爱情故事'},
{'age': 25, 'created': '2017-04-01 12:00:01', 'name': '刘勇', 'title': '乡村爱情故事'}
]
for line in line_list:
action = {
"_index": index_name,
"_type": doc_type_name,
"_source": {
"age": line['age'],
"created": line['created'],
"name": line['name'],
"title": line['title']
}
}
ACTIONS.append(action)
# 批量处理
success, _ = bulk(es, ACTIONS, index=index_name, raise_on_error=True)

5、按时间段进行聚合测试
from elasticsearch import Elasticsearch
es_servers = [{
"host": "10.10.6.225",
"port": ""
}]
# 使用文档在这里:http://elasticsearch-py.readthedocs.io/en/master/
es = Elasticsearch(es_servers)
print(es.indices.get(index='blog_index')['blog_index']['mappings'])
body= {
"size" : 0,
"aggs": {
"sales": {
"date_histogram": {
"field": "created",
"interval": "month",
"format": "yyyy-MM"
}
}
}
}
res = es.search(index="blog_index", body=body)
print(res)

打完收工!
Elasticsearch 6.x 入门测试的更多相关文章
- Elasticsearch全文检索工具入门
Elasticsearch全文检索工具入门: 1.下载对应系统版本的文件 elasticsearch-2.4.0.zip 1.1运行elasticsearch-2.4.0\elasticsearch- ...
- 最新版本elasticsearch本地搭建入门篇
最新版本elasticsearch本地搭建入门篇 项目介绍 最近工作用到elasticsearch,主要是用于网站搜索,和应用搜索. 工欲善其事,必先利其器. 自己开始关注elasticsearch, ...
- elasticsearch.net search入门使用指南中文版(翻译)
elasticsearch.net search入门使用指南中文版,elasticsearch.Net是一个非常底层且灵活的客户端,它不在意你如何的构建自己的请求和响应.它非常抽象,因此所有的elas ...
- elasticsearch.net search入门使用指南中文版
原文:http://edu.dmeiyang.com/book/nestusing.html elasticsearch.net为什么会有两个客户端? Elasticsearch.Net是一个非常底层 ...
- Elasticsearch学习记录(入门篇)
Elasticsearch学习记录(入门篇) 1. Elasticsearch的请求与结果 请求结构 curl -X<VERB> '<PROTOCOL>://<HOST& ...
- ElasticSearch极简入门总结
一,目录 安装es 项目添加maven依赖 es客户端组件注入到spring容器中 es与mysql表结构对比 索引的删除创建 文档的crud es能快速搜索的核心-倒排索引 基于倒排索引的精确搜索. ...
- Springboot整合ElasticSearch进行简单的测试及用Kibana进行查看
一.前言 搜索引擎还是在电商项目.百度.还有技术博客中广泛应用,使用最多的还是ElasticSearch,Solr在大数据量下检索性能不如ElasticSearch.今天和大家一起搭建一下,小编是看完 ...
- (转)开源分布式搜索平台ELK(Elasticsearch+Logstash+Kibana)入门学习资源索引
Github, Soundcloud, FogCreek, Stackoverflow, Foursquare,等公司通过elasticsearch提供搜索或大规模日志分析可视化等服务.博主近4个月搜 ...
- Elasticsearch【快速入门】
前言:毕设项目还要求加了这个做大数据搜索,正好自己也比较感兴趣,就一起来学习学习吧! Elasticsearch 简介 Elasticsearch 是一个分布式.RESTful 风格的搜索和数据分析引 ...
随机推荐
- python线程进程
多道技术: 多道程序设计技术 所谓多道程序设计技术,就是指允许多个程序同时进入内存并运行.即同时把多个程序放入内存,并允许它们交替在CPU中运行,它们共享系统中的各种硬.软件资源.当一道程序因I/O请 ...
- NATS_06:NATS队列验证与监控
1. NATS 之 Queueing(队列)模式验证 主要以下讲的都是基于 NATS 服务已经开启了(没有开启的请运行:gnatsd 启动):还有请注意所有运行的 go 文件都是在 $GOPATH/s ...
- printf与fprintf函数的区别
printf是标准输出流的输出函数,用来向屏幕这样的标准输出设备输出,而fprintf则是向文件输出,将输出的内容输出到硬盘上的文件或是相当于文件的设备上 printf是有缓冲的输出,fprintf没 ...
- [转载]strtok函数和strtok_r函数
1.一个应用实例 网络上一个比较经典的例子是将字符串切分,存入结构体中.如,现有结构体 typedef struct person{ char name[25]; char sex[1 ...
- 出了一个js的题。
class test { set xx(v){ console.log('i am set'); this.__ok = v; } get xx(){ console.log('i am get'); ...
- 洛谷P3960 [NOIP2017] 列队
数据结构题还是挺好玩的 注意到每次只变动三个点:(x,y),(x,m),(n,m),其他地方都是整块移动. 可以开n+1个线段树,前n个存每行前m-1个人,最后一个存第m列的人. (x,y)位置的人出 ...
- classList属性
1.传统方法: 在操作类名的时候,需要通过className属性添加.删除和替换类名.如下面例子: ? 1 <div class="bd user disabled"> ...
- Java编程思想 4th 第2章 一切都是对象
Java是基于C++的,但Java是一种更纯粹的面向对象程序设计语言,和C++不同的是,Java只支持面向对象编程,因此Java的编程风格也是纯OOP风格的,即一切都是类,所有事情通过类对象协作来完成 ...
- 对web标准的理解,以及对w3c组织的认识
(1)web标准规范要求,书写标签必须闭合.标签小写.不乱嵌套,可提高搜索机器人对网页内容的搜索几率.--- SEO(2)建议使用外链css和js脚本,从而达到结构与行为.结构与表现的分离,提高页面的 ...
- 工具推荐:Backdoor-apk,安卓APK文件后门测试工具
工具推荐:Backdoor-apk,安卓APK文件后门测试工具 Backdoor-apk可以看成是一个shell脚本程序,它简化了在Android APK文件中添加后门的过程.安全研究人员在使用该工具 ...