Concurrency Managed Workqueue(二)CMWQ概述
一、前言
一种新的机制出现的原因往往是为了解决实际的问题,虽然linux kernel中已经提供了workqueue的机制,那么为何还要引入cmwq呢?也就是说:旧的workqueue机制存在什么样的问题?在新的cmwq又是如何解决这些问题的呢?它接口是如何呈现的呢(驱动工程师最关心这个了)?如何兼容旧的驱动呢?本文希望可以解开这些谜题。
本文的代码来自linux kernel 4.0。
二、为何需要CMWQ?
内核中很多场景需要异步执行环境(在驱动中尤其常见),这时候,我们需要定义一个work(执行哪一个函数)并挂入workqueue。处理该work的线程叫做worker,不断的处理队列中的work,当处理完毕后则休眠,队列中有work的时候就醒来处理,如此周而复始。一切看起来比较完美,问题出在哪里呢?
(1)内核线程数量太多。如果没有足够的内核知识,程序员有可能会错误的使用workqueue机制,从而导致这个机制被玩坏。例如明明可以使用default workqueue,偏偏自己创建属于自己的workqueue,这样一来,对于那些比较大型的系统(CPU个数比较多),很可能内核启动结束后就耗尽了PID space(default最大值是65535),这种情况下,你让user space的程序情何以堪?虽然default最大值是可以修改的,从而扩大PID space来解决这个问题,不过系统太多的task会对整体performance造成负面影响。
(2)尽管消耗了很多资源,但是并发性如何呢?我们先看single threaded的workqueue,这种情况完全没有并发的概念,任何的work都是排队执行,如果正在执行的work很慢,例如4~5秒的时间,那么队列中的其他work除了等待别无选择。multi threaded(更准确的是per-CPU threaded)情况当然会好一些(毕竟多消耗了资源),但是对并发仍然处理的不是很好。对于multi threaded workqueue,虽然创建了thread pool,但是thread pool的数目是固定的:每个oneline的cpu上运行一个,而且是严格的绑定关系。也就是说本来线程池是一个很好的概念,但是传统workqueue上的线程池(或者叫做worker pool)却分割了每个线程,线程之间不能互通有无。例如cpu0上的worker thread由于处理work而进入阻塞状态,那么该worker thread处理的work queue中的其他work都阻塞住,不能转移到其他cpu上的worker thread去,更有甚者,cpu0上随后挂入的work也接受同样的命运(在某个cpu上schedule的work一定会运行在那个cpu上),不能去其他空闲的worker thread上执行。由于不能提供很好的并发性,有些内核模块(fscache)甚至自己创建了thread pool(slow work也曾经短暂的出现在kernel中)。
(3)dead lock问题。我们举一个简单的例子:我们知道,系统有default workqueue,如果没有特别需求,驱动工程师都喜欢用这个workqueue。我们的驱动模块在处理release(userspace close该设备)函数的时候,由于使用了workqueue,那么一般会flush整个workqueue,以便确保本driver的所有事宜都已经处理完毕(在close的时候很有可能有pending的work,因此要flush),大概的代码如下:
获取锁A
flush workqueue
释放锁A
flush work是一个长期过程,因此很有可能被调度出去,这样调用close的进程被阻塞,等到keventd_wq这个内核线程组完成flush操作后就会wakeup该进程。但是这个default workqueue使用很广,其他的模块也可能会schedule work到该workqueue中,并且如果这些模块的work也需要获取锁A,那么就会deadlock(keventd_wq阻塞,再也无法唤醒等待flush的进程)。解决这个问题的方法是创建多个workqueue,但是这样又回到了内核线程数量大多的问题上来。
我们再看一个例子:假设某个驱动模块比较复杂,使用了两个work struct,分别是A和B,如果work A依赖 work B的执行结果,那么,如果这两个work都schedule到一个worker thread的时候就出现问题,由于worker thread不能并发的执行work A和work B,因此该驱动模块会死锁。Multi threaded workqueue能减轻这个问题,但是无法解决该问题,毕竟work A和work B还是有机会调度到一个cpu上执行。造成这些问题的根本原因是众多的work竞争一个执行上下文导致的。
(4)二元化的线程池机制。基本上workqueue也是thread pool的一种,但是创建的线程数目是二元化的设定:要么是1,要么是number of CPU,但是,有些场景中,创建number of CPU太多,而创建一个线程又太少,这时候,勉强使用了single threaded workqueue,但是不得不接受串行处理work,使用multi threaded workqueue吧,占用资源太多。二元化的线程池机制让用户无所适从。
三、CMWQ如何解决问题的呢?
1、设计原则。在进行CMWQ的时候遵循下面两个原则:
(1)和旧的workqueue接口兼容。
(2)明确的划分了workqueue的前端接口和后端实现机制。CMWQ的整体架构如下:
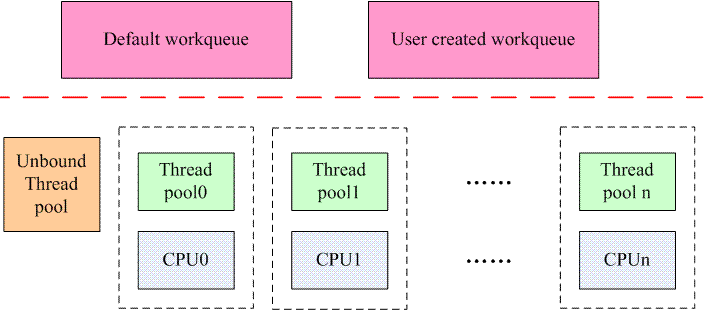
对于workqueue的用户而言,前端的操作包括二种,一个是创建workqueue。可以选择创建自己的workqueue,当然也可以不创建而是使用系统缺省的workqueue。另外一个操作就是将指定的work添加到workqueue。在旧的workqueue机制中,workqueue和worker thread是密切联系的概念,对于single workqueue,创建一个系统范围的worker thread,对于multi workqueue,创建per-CPU的worker thread,一切都是固定死的。针对这样的设计,我们可以进一步思考其合理性。workqueue用户的需求就是一个异步执行的环境,把创建workqueue和创建worker thread绑定起来大大限定了资源的使用,其实具体后台是如何处理work,是否否启动了多个thread,如何管理多个线程之间的协调,workqueue的用户并不关心。
基于这样的思考,在CMWQ中,将这种固定的关系被打破,提出了worker pool这样的概念(其实就是一种thread pool的概念),也就是说,系统中存在若干worker pool,不和特定的workqueue关联,而是所有的workqueue共享。用户可以创建workqueue(不创建worker pool)并通过flag来约束挂入该workqueue上work的处理方式。workqueue会根据其flag将work交付给系统中某个worker pool处理。例如如果该workqueue是bounded类型并且设定了high priority,那么挂入该workqueue的work将由per cpu的highpri worker-pool来处理。
让所有的workqueue共享系统中的worker pool,即减少了资源的浪费(没有创建那么多的kernel thread),又保证了灵活的并发性(worker pool会根据情况灵活的创建thread来处理work)。
3、如何解决线程数目过多的问题?
在CMWQ中,用户可以根据自己的需求创建workqueue,但是已经和后端的线程池是否创建worker线程无关了,是否创建新的work线程是由worker线程池来管理。系统中的线程池包括两种:
(1)和特定CPU绑定的线程池。这种线程池有两种,一种叫做normal thread pool,另外一种叫做high priority thread pool,分别用来管理普通的worker thread和高优先级的worker thread,而这两种thread分别用来处理普通的和高优先级的work。这种类型的线程池数目是固定的,和系统中cpu的数目相关,如果系统有n个cpu,如果都是online的,那么会创建2n个线程池。
(2)unbound 线程池,可以运行在任意的cpu上。这种thread pool是动态创建的,是和thread pool的属性相关,包括该thread pool创建worker thread的优先级(nice value),可以运行的cpu链表等。如果系统中已经有了相同属性的thread pool,那么不需要创建新的线程池,否则需要创建。
OK,上面讲了线程池的创建,了解到创建workqueue和创建worker thread这两个事件已经解除关联,用户创建workqueue仅仅是选择一个或者多个线程池而已,对于bound thread pool,每个cpu有两个thread pool,关系是固定的,对于unbound thread pool,有可能根据属性动态创建thread pool。那么worker thread pool如何创建worker thread呢?是否会数目过多呢?
缺省情况下,创建thread pool的时候会创建一个worker thread来处理work,随着work的提交以及work的执行情况,thread pool会动态创建worker thread。具体创建worker thread的策略为何?本质上这是一个需要在并发性和系统资源消耗上进行平衡的问题,CMWQ使用了一个非常简单的策略:当thread pool中处于运行状态的worker thread等于0,并且有需要处理的work的时候,thread pool就会创建新的worker线程。当worker线程处于idle的时候,不会立刻销毁它,而是保持一段时间,如果这时候有创建新的worker的需求的时候,那么直接wakeup idle的worker即可。一段时间过去仍然没有事情处理,那么该worker thread会被销毁。
4、如何解决并发问题?
我们用某个cpu上的bound workqueue来描述该问题。假设有A B C D四个work在该cpu上运行,缺省的情况下,thread pool会创建一个worker来处理这四个work。在旧的workqueue中,A B C D四个work毫无疑问是串行在cpu上执行,假设B work阻塞了,那么C D都是无法执行下去,一直要等到B解除阻塞并执行完毕。
对于CMWQ,当B work阻塞了,thread pool可以感知到这一事件,这时候它会创建一个新的worker thread来处理C D这两个work,从而解决了并发的问题。由于解决了并发问题,实际上也解决了由于竞争一个execution context而引入的各种问题(例如dead lock)。
四、接口API
1、初始化work的接口保持不变,可以静态或者动态创建work。
2、调度work执行也保持和旧的workqueue一致。
3、创建workqueue。和旧的create_workqueue接口不同,CMWQ采用了alloc_workqueue这样的接口符号,相关的接口定义如下:
#define alloc_workqueue(fmt, flags, max_active, args...) \
__alloc_workqueue_key((fmt), (flags), (max_active), NULL, NULL, ##args)#define alloc_ordered_workqueue(fmt, flags, args...) \
alloc_workqueue(fmt, WQ_UNBOUND | __WQ_ORDERED | (flags), 1, ##args)#define create_freezable_workqueue(name) \
alloc_workqueue("%s", WQ_FREEZABLE | WQ_UNBOUND | WQ_MEM_RECLAIM, 1, (name))#define create_workqueue(name) \
alloc_workqueue("%s", WQ_MEM_RECLAIM, 1, (name))#define create_singlethread_workqueue(name) \
alloc_ordered_workqueue("%s", WQ_MEM_RECLAIM, name)
在描述这些workqueue的接口之前,我们需要准备一些workqueue flag的知识。
标有WQ_UNBOUND这个flag的workqueue说明其work的处理不需要绑定在特定的CPU上执行,workqueue需要关联一个系统中的unbound
worker thread
pool。如果系统中能找到匹配的线程池(根据workqueue的属性(attribute)),那么就选择一个,如果找不到适合的线程池,workqueue就会创建一个worker
thread pool来处理work。
WQ_FREEZABLE是一个和电源管理相关的内容。在系统Hibernation或者suspend的时候,有一个步骤就是冻结用户空间的进程以及部分(标注freezable的)内核线程(包括workqueue的worker
thread)。标记WQ_FREEZABLE的workqueue需要参与到进程冻结的过程中,worker
thread被冻结的时候,会处理完当前所有的work,一旦冻结完成,那么就不会启动新的work的执行,直到进程被解冻。
和WQ_MEM_RECLAIM这个flag相关的概念是rescuer thread。前面我们描述解决并发问题的时候说到:对于A B C
D四个work,当正在处理的B work被阻塞后,worker pool会创建一个新的worker
thread来处理其他的work,但是,在memory资源比较紧张的时候,创建worker thread未必能够成功,这时候,如果B
work是依赖C或者D work的执行结果的时候,系统进入dead lock。这种状态是由于不能创建新的worker
thread导致的,如何解决呢?对于每一个标记WQ_MEM_RECLAIM flag的work queue,系统都会创建一个rescuer
thread,当发生这种情况的时候,C或者D work会被rescuer thread接手处理,从而解除了dead lock。
WQ_HIGHPRI说明挂入该workqueue的work是属于高优先级的work,需要高优先级(比较低的nice value)的worker thread来处理。
WQ_CPU_INTENSIVE这个flag说明挂入该workqueue的work是属于特别消耗cpu的那一类。为何要提供这样的flag呢?我们还是用老例子来说明。对于A
B C D四个work,B是cpu intersive的,当thread正在处理B work的时候,该worker thread一直执行B
work,因为它是cpu intensive的,特别吃cpu,这时候,thread
pool是不会创建新的worker的,因为当前还有一个worker是running状态,正在处理B work。这时候C
Dwork实际上是得不到执行,影响了并发。
了解了上面的内容,那么基本上alloc_workqueue中flag参数就明白了,下面我们转向max_active这个参数。系统不能允许创建太多的thread来处理挂入某个workqueue的work,最多能创建的线程数目是定义在max_active参数中。
除了alloc_workqueue接口API之外,还可以通过alloc_ordered_workqueue这个接口API来创建一个严格串行执行work的一个workqueue,并且该workqueue是unbound类型的。create_*的接口都是为了兼容过去接口而设立的,大家可以自行理解,这里就不多说了。
Concurrency Managed Workqueue(二)CMWQ概述的更多相关文章
- Concurrency Managed Workqueue(一)workqueue基本概念
一.前言 workqueue是一个驱动工程师常用的工具,在旧的内核中(指2.6.36之前的内核版本)workqueue代码比较简单(大概800行),在2.6.36内核版本中引入了CMWQ(Concur ...
- Concurrency Managed Workqueue(三)创建workqueue代码分析
一.前言 本文主要以__alloc_workqueue_key函数为主线,描述CMWQ中的创建一个workqueue实例的代码过程. 二.WQ_POWER_EFFICIENT的处理 __alloc_w ...
- Concurrency Managed Workqueue(四)workqueue如何处理work
一.前言 本文主要讲述下面两部分的内容: 1.将work挂入workqueue的处理过程 2.如何处理挂入workqueue的work 二.用户将一个work挂入workqueue 1.queue_w ...
- (转)SQL SERVER的锁机制(二)——概述(锁的兼容性与可以锁定的资源)
二.完整的锁兼容性矩阵(见下图) 对上图的是代码说明:见下图. 三.下表列出了数据库引擎可以锁定的资源. 名称 资源 缩写 编码 呈现锁定时,描述该资源的方式 说明 数据行 RID RID 9 文件编 ...
- 二 J2EE 概述
一 WEB 应用 1. WEB 应用工作方式:B/S 模式 (浏览器/服务器模式) 2. WEB 应用结构组成: a. WEB 服务器:是安装在 WEB 服务器计算机上的一个软件包,负责接收用户请求并 ...
- kubernetes进阶之二:概述
一:kubernetes是什么 Kubernetes一个用于容器集群的自动化部署.扩容以及运维的开源平台.通过Kubernetes,你可以快速有效地响应用户需求;快速而有预期地部署你的应用; 极速地扩 ...
- SQL SERVER的锁机制(二)——概述(锁的兼容性与可以锁定的资源)
二.完整的锁兼容性矩阵(见下图) 对上图的是代码说明:见下图. 三.下表列出了数据库引擎可以锁定的资源. 名称 资源 缩写 编码 呈现锁定时,描述该资源的方式 说明 数据行 RID RID 9 文件编 ...
- Apache Shiro系列二,概述 —— 基本概念
做任何事情,首先要双方就一些概念的理解达成一致,这样大家就有共同语言,后续的沟通效率会高一些. #,Authentication,认证,也就是验证用户的身份,就是确定你是不是你,比如通过用户名.密码的 ...
- Nagios学习笔记二:Nagios概述
1.简介 Nagios是插件式的结构,它本身没有任何监控功能,所有的监控都是通过插件进行的,因此其是高度模块化和富于弹性的.Nagios监控的对象可分为两类:主机和服务.主机通常指的是物理主机,如服务 ...
随机推荐
- 理解js中的new
new 操作符 在有上面的基础概念的介绍之后,在加上new操作符,我们就能完成传统面向对象的class + new的方式创建对象,在Javascript中,我们将这类方式成为Pseudoclassic ...
- Java基础(十二):包(package)
一.Java 包(package): 为了更好地组织类,Java 提供了包机制,用于区别类名的命名空间.包的作用: 1.把功能相似或相关的类或接口组织在同一个包中,方便类的查找和使用. 2.如同文件夹 ...
- EasyUI-Tooltip(提示框)学习
引子: if($("#BLUETOOTH_a")){ $("#BLUETOOTH_a").tooltip({ position: 'right', conten ...
- UML建模学习1:UML统一建模语言简单介绍
一什么是UML? Unified Modeling Language(UML又称为统一建模语言或标准建模语言)是国际对象管理组织OMG制定的一个通 用的.可视化建模语言标准.能够用来描写叙述(spec ...
- Pascal's Triangle I,II
题目来自于Leetcode https://leetcode.com/problems/pascals-triangle/ Given numRows, generate the first numR ...
- css样式记录
样式一 #sideBar,#blog_post_info_block { display: none; } #under_post_news { display: none; } /*评论框大小*/ ...
- WPF 同一个程序 只允许 同时运行一个
方法2 当程序已经运行了 再运行这个程序时,则显示当前这个窗体 http://code.3rbang.com/cshape-run-one/ VS2013附件:http://fil ...
- ZH奶酪:Yii PHP sum SQL查询语句
例子: $sql = 'SELECT SUM(o.price) as `sum` FROM `order` o WHERE o.customer_id ='.$profile->id; $ret ...
- Windows 之 手机访问 PC 端本地部署的站点
测试网页在手机上的显示工具我们可以使用谷歌内核的浏览器,打开开发者工具(F12),在device那里选择设备,然后刷新来查看网页在手机上的显示效果. 但毕竟是模拟的,如果想要在真机上调试该怎么办呢. ...
- 关于Haxe3新特性“内联构造方法”的解释
学习过C/C++的童鞋们应该了解inline即内联机制的意义,Haxe语言也很好的支持内联机制,让开发者可以自己在空间效率和时间效率上进行取舍. 从Haxe3开始,构造方法也可以使用inline关键字 ...