实现nlp文本生成中的beam search解码器
自然语言处理任务,比如caption generation(图片描述文本生成)、机器翻译中,都需要进行词或者字符序列的生成。常见于seq2seq模型或者RNNLM模型中。
这篇博文主要介绍文本生成解码过程中用的greedy search 和beam search算法实现。其中,greedy search 比较简单,着重介绍beam search算法的实现。
我们在文本生成解码时,实际上是想找对最有的文本序列,或者说是概率,可能性最大的文本序列。而要在全局搜索这个最有解空间,往往是不可能的(因为词典太大),建设生成序列长度为N,词典大小为V, 则复杂度为 V^N次方。这实际上是一个NP难题。退而求其次,我们使用启发式算法,来找到可能的最优解,或者说足够好的解。
假设序列数据(假设每个位置词的概率都已经给出):
data = [[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1]]
data = array(data)
1、greedy search decoder
非常简单,我们用argmax就可以实现
# greedy decoder
def greedy_decoder(data):
# 每一行最大概率词的索引
return [argmax(s) for s in data]
完整代码
from numpy import array
from numpy import argmax # greedy decoder
def greedy_decoder(data):
# 每一行最大概率词的索引
return [argmax(s) for s in data] # 定义一个句子,长度为10,词典大小为5
data = [[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1]]
data = array(data)
# 使用greedy search解码
result = greedy_decoder(data)
print(result)
2. beam search
与greedy search不同,beam search返回多个最有可能的解码结果(具体多少个,由参数k执行)。
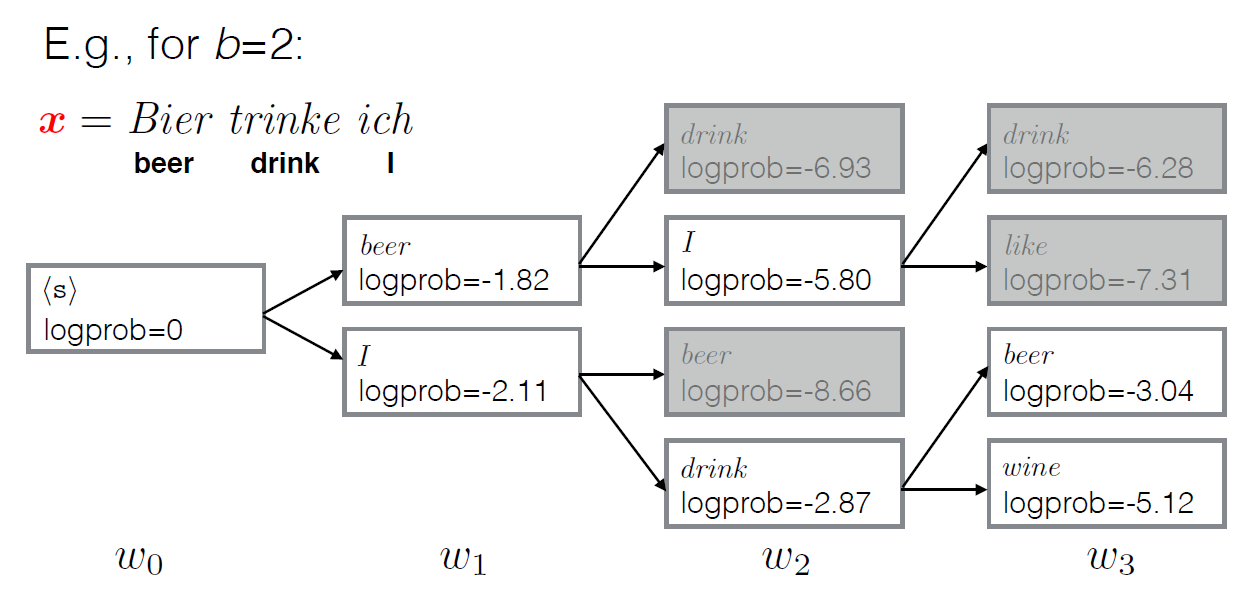
greedy search每一步都都采用最大概率的词,而beam search每一步都保留k个最有可能的结果,在每一步,基于之前的k个可能最优结果,继续搜索下一步。(参考下面示意图理解)
示例图(设置返回解码结果为2个):
from math import log
from numpy import array
from numpy import argmax # beam search
def beam_search_decoder(data, k):
sequences = [[list(), 1.0]]
for row in data:
all_candidates = list()
for i in range(len(sequences)):
seq, score = sequences[i]
for j in range(len(row)):
candidate = [seq + [j], score * -log(row[j])]
all_candidates.append(candidate)
# 所有候选根据分值排序
ordered = sorted(all_candidates, key=lambda tup:tup[1])
# 选择前k个
sequences = ordered[:k]
return sequences # 定义一个句子,长度为10,词典大小为5
data = [[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1]]
data = array(data)
# 解码
result = beam_search_decoder(data, 3)
# print result
for seq in result:
print(seq)
相关资料:
- Argmax on Wikipedia
- Numpy argmax API
- Beam search on Wikipedia
- Beam Search Strategies for Neural Machine Translation, 2017.
- Artificial Intelligence: A Modern Approach (3rd Edition), 2009.
- Neural Network Methods in Natural Language Processing, 2017.
- Handbook of Natural Language Processing and Machine Translation, 2011.
- Pharaoh: a beam search decoder for phrase-based statistical machine translation models, 2004.
实现nlp文本生成中的beam search解码器的更多相关文章
- 斯坦福NLP课程 | 第15讲 - NLP文本生成任务
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- Beam Search
Q: 什么是Beam Search? 它在NLP中的什么场景里会⽤到? 传统的广度优先策略能够找到最优的路径,但是在搜索空间非常大的情况下,内存占用是指数级增长,很容易造成内存溢出,因此提出了beam ...
- 【NLP】选择目标序列:贪心搜索和Beam search
构建seq2seq模型,并训练完成后,我们只要将源句子输入进训练好的模型,执行一次前向传播就能得到目标句子,但是值得注意的是: seq2seq模型的decoder部分实际上相当于一个语言模型,相比于R ...
- NLP相关问题中文本数据特征表达初探
1. NLP问题简介 0x1:NLP问题都包括哪些内涵 人们对真实世界的感知被成为感知世界,而人们用语言表达出自己的感知视为文本数据.那么反过来,NLP,或者更精确地表达为文本挖掘,则是从文本数据出发 ...
- 关于 Image Caption 中测试时用到的 beam search算法
关于beam search 之前组会中没讲清楚的 beam search,这里给一个案例来说明这种搜索算法. 在 Image Caption的测试阶段,为了得到输出的语句,一般会选用两种搜索方式,一种 ...
- 浅谈NLP 文本分类/情感分析 任务中的文本预处理工作
目录 浅谈NLP 文本分类/情感分析 任务中的文本预处理工作 前言 NLP相关的文本预处理 浅谈NLP 文本分类/情感分析 任务中的文本预处理工作 前言 之所以心血来潮想写这篇博客,是因为最近在关注N ...
- Beam Search快速理解及代码解析(上)
Beam Search 简单介绍一下在文本生成任务中常用的解码策略Beam Search(集束搜索). 生成式任务相比普通的分类.tagging等NLP任务会复杂不少.在生成的时候,模型的输出是一个时 ...
- Beam Search快速理解及代码解析
目录 Beam Search快速理解及代码解析(上) Beam Search 贪心搜索 Beam Search Beam Search代码解析 准备初始输入 序列扩展 准备输出 总结 Beam Sea ...
- 使用 paddle来进行文本生成
paddle 简单介绍 paddle 是百度在2016年9月份开源的深度学习框架. 就我最近体验的感受来说的它具有几大优点: 1. 本身内嵌了许多和实际业务非常贴近的模型比如个性化推荐,情感分析,词向 ...
随机推荐
- jquery.lazyload插件实现图片延迟加载详解
什么是LazyLoad技术? 在页面上图片比较多的时候,打开一张页面必然引起与服务器大数据量的交互.尤其是对于高清晰的图片,占了几百K的空间.Lazy Load 是一个用 JavaScript 编写的 ...
- 如何利用mount命令挂载另一台服务器上的目录
文件服务器(被挂载机):192.168.1.100 操作机(挂载到机):192.168.1.200 也就是说,你在操作机上进行的操作,实际上都到文件服务器上去了: 1. 开启NFS服务: 在文件服务器 ...
- 可简单避免的三个 JavaScript 发布错误
Web应用程序开发是倾向于在客户端运行所有用户逻辑和交互代码,让服务器暴露REST或者RPC接口.编译器是针对JS作为一个平台,第二版ECMAScript正是考虑到这一点在设计.客户端框架例如Back ...
- undefined reference to 'pthread_create'问题解决 -- 转
文章出处:http://blog.csdn.net/llqkk/article/details/2854558 由于是Linux新手,所以现在才开始接触线程编程,照着GUN/Linux编程指南中的一个 ...
- redis写定时任务获取root权限
前提: 1.redis由root用户启动. 2.开启cron的时候,/var/spool/cron linux机器下默认的计划任务,linux会定时去执行里面的任务. 启动服务 :/sbin/serv ...
- python概念-其实只要简单了解一下,但是却讲了将近两个小时的知识点:元类
说实话,我真心不太想总结这个东西,算了,炒一下egon的吧 1 引子 1 class Foo: 2 pass 3 4 f1=Foo() #f1是通过Foo类实例化的对象 python中一切皆是对象,类 ...
- Android手动回收bitmap,引发Canvas: trying to use a recycled bitmap处理
在做Android的开发的时候,在ListView 或是 GridView中需要加载大量的图片,为了避免加载过多的图片引起OutOfMemory错误,设置了一个图片缓存列表 Map<String ...
- weblogica domain目录 环境变量 如何启动weblogic server
手工启动weblogic server
- JavaScript入门--慕课网学习笔记
JAVASCRIPT—(慕课网)入门篇 我们来看看如何写入JS代码?你只需一步操作,使用<script>标签在HTML网页中插入JavaScript代码.注意, <script&g ...
- Oracle Certified Java Programmer 经典题目分析(二)
...接上篇 what is reserved(保留) words in java? A. run B. default C. implement D. import Java 关键字列表 (依字母排 ...