Hadoop案例(十一)MapReduce的API使用
一学生成绩---增强版
数据信息
computer,huangxiaoming,,,,,,,
computer,xuzheng,,,,,
computer,huangbo,,,,
english,zhaobenshan,,,,,,,
english,liuyifei,,,,,,,
algorithm,liuyifei,,,,,,,
computer,huangjiaju,,,,,
english,liuyifei,,,,,,,
english,huangdatou,,,,,,,
algorithm,huanglei,,,,,,,
algorithm,huangjiaju,,,,,,,
computer,huangdatou,,,,,,,
english,zhouqi,,,,,,,,,,,
english,huangbo,,,,,,,
algorithm,liutao,,,,,
computer,huangzitao,,,,,,,
math,wangbaoqiang,,,,,,,
computer,liujialing,,,,,,,,,
computer,liuyifei,,,,,,,
computer,liutao,,,,,,,,
computer,huanglei,,,,,,,
english,liujialing,,,,,,,
math,huanglei,,,,,,,
math,huangjiaju,,,,,,,
math,liutao,,,,,,,
english,huanglei,,,,,,,,
math,xuzheng,,,,,,,
math,huangxiaoming,,,,,,,,
math,liujialing,,,,,,,,
english,huangxiaoming,,,,,,,
algorithm,huangdatou,,,,,,,
algorithm,huangzitao,,,,,,,,
数据解释
数据字段个数不固定:
第一个是课程名称,总共四个课程,computer,math,english,algorithm,
第二个是学生姓名,后面是每次考试的分数
统计需求
1、统计每门课程的参考人数和课程平均分
2、统计每门课程参考学生的平均分,并且按课程存入不同的结果文件,要求一门课程一个结果文件,并且按平均分从高到低排序,分数保留一位小数
3、求出每门课程参考学生成绩最高的学生的信息:课程,姓名和平均分
第一题
MRAvgScore1.java
/**
* 需求:统计每门课程的参考人数和课程平均分
* */
public class MRAvgScore1 { public static void main(String[] args) throws Exception { Configuration conf1 = new Configuration();
Configuration conf2 = new Configuration(); Job job1 = Job.getInstance(conf1);
Job job2 = Job.getInstance(conf2); job1.setJarByClass(MRAvgScore1.class);
job1.setMapperClass(AvgScoreMapper1.class);
//job.setReducerClass(MFReducer.class); job1.setOutputKeyClass(Text.class);
job1.setOutputValueClass(DoubleWritable.class); Path inputPath1 = new Path("D:\\MR\\hw\\work3\\input");
Path outputPath1 = new Path("D:\\MR\\hw\\work3\\output_hw1_1"); FileInputFormat.setInputPaths(job1, inputPath1);
FileOutputFormat.setOutputPath(job1, outputPath1); job2.setMapperClass(AvgScoreMapper2.class);
job2.setReducerClass(AvgScoreReducer2.class); job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(DoubleWritable.class); Path inputPath2 = new Path("D:\\MR\\hw\\work3\\output_hw1_1");
Path outputPath2 = new Path("D:\\MR\\hw\\work3\\output_hw1_end"); FileInputFormat.setInputPaths(job2, inputPath2);
FileOutputFormat.setOutputPath(job2, outputPath2); JobControl control = new JobControl("AvgScore"); ControlledJob aJob = new ControlledJob(job1.getConfiguration());
ControlledJob bJob = new ControlledJob(job2.getConfiguration()); bJob.addDependingJob(aJob); control.addJob(aJob);
control.addJob(bJob); Thread thread = new Thread(control);
thread.start(); while(!control.allFinished()) {
thread.sleep();
}
System.exit(); } /**
* 数据类型:computer,huangxiaoming,85,86,41,75,93,42,85
*
* 需求:统计每门课程的参考人数和课程平均分
*
* 分析:以课程名称+姓名作为key,以平均分数作为value
* */
public static class AvgScoreMapper1 extends Mapper<LongWritable, Text, Text, DoubleWritable>{ @Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException { String[] splits = value.toString().split(",");
//拼接成要输出的key
String outKey = splits[]+"\t"+splits[];
int length = splits.length;
int sum = ;
//求出成绩的总和
for(int i=;i<length;i++) {
sum += Integer.parseInt(splits[i]);
}
//求出平均分
double outValue = sum / (length - ); context.write(new Text(outKey), new DoubleWritable(outValue)); } } /**
* 对第一次MapReduce输出的结果进一步计算,第一步输出结果样式为
* math huangjiaju 82.0
* math huanglei 74.0
* math huangxiaoming 83.0
* math liujialing 72.0
* math liutao 56.0
* math wangbaoqiang 72.0
* math xuzheng 69.0
*
* 需求:统计每门课程的参考人数和课程平均分
* 分析:以课程名称作为key,以分数作为value进行 输出
*
* */
public static class AvgScoreMapper2 extends Mapper<LongWritable, Text, Text, DoubleWritable>{ @Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException { String[] splits = value.toString().split("\t");
String outKey = splits[];
String outValue = splits[]; context.write(new Text(outKey), new DoubleWritable(Double.parseDouble(outValue)));
} } /**
* 针对同一门课程,对values进行遍历计数,看看有多少人参加了考试,并计算出平均成绩
* */
public static class AvgScoreReducer2 extends Reducer<Text, DoubleWritable, Text, Text>{ @Override
protected void reduce(Text key, Iterable<DoubleWritable> values,
Context context) throws IOException, InterruptedException { int count = ;
double sum = ;
for(DoubleWritable value : values) {
count++;
sum += value.get();
} double avg = sum / count;
String outValue = count + "\t" + avg;
context.write(key, new Text(outValue));
} } }
第二题
MRAvgScore2.java
public class MRAvgScore2 {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(MRAvgScore2.class);
job.setMapperClass(ScoreMapper3.class);
job.setReducerClass(ScoreReducer3.class);
job.setOutputKeyClass(StudentBean.class);
job.setOutputValueClass(NullWritable.class);
job.setPartitionerClass(CoursePartitioner.class);
job.setNumReduceTasks();
Path inputPath = new Path("D:\\MR\\hw\\work3\\output_hw1_1");
Path outputPath = new Path("D:\\MR\\hw\\work3\\output_hw2_1");
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
boolean isDone = job.waitForCompletion(true);
System.exit(isDone ? : );
}
public static class ScoreMapper3 extends Mapper<LongWritable, Text, StudentBean, NullWritable>{
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String[] splits = value.toString().split("\t");
double score = Double.parseDouble(splits[]);
DecimalFormat df = new DecimalFormat("#.0");
df.format(score);
StudentBean student = new StudentBean(splits[],splits[],score);
context.write(student, NullWritable.get());
}
}
public static class ScoreReducer3 extends Reducer<StudentBean, NullWritable, StudentBean, NullWritable>{
@Override
protected void reduce(StudentBean key, Iterable<NullWritable> values,Context context)
throws IOException, InterruptedException {
for(NullWritable nvl : values){
context.write(key, nvl);
}
}
}
}
StudentBean.java
public class StudentBean implements WritableComparable<StudentBean>{
private String course;
private String name;
private double avgScore;
public String getCourse() {
return course;
}
public void setCourse(String course) {
this.course = course;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getavgScore() {
return avgScore;
}
public void setavgScore(double avgScore) {
this.avgScore = avgScore;
}
public StudentBean(String course, String name, double avgScore) {
super();
this.course = course;
this.name = name;
this.avgScore = avgScore;
}
public StudentBean() {
super();
}
@Override
public String toString() {
return course + "\t" + name + "\t" + avgScore;
}
@Override
public void readFields(DataInput in) throws IOException {
course = in.readUTF();
name = in.readUTF();
avgScore = in.readDouble();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(course);
out.writeUTF(name);
out.writeDouble(avgScore);
}
@Override
public int compareTo(StudentBean stu) {
double diffent = this.avgScore - stu.avgScore;
if(diffent == ) {
return ;
}else {
return diffent > ? - : ;
}
}
}
第三题
MRScore3.java
二影评案例
数据及需求
数据格式
movies.dat 3884条数据
1::Toy Story (1995)::Animation|Children's|Comedy
2::Jumanji (1995)::Adventure|Children's|Fantasy
3::Grumpier Old Men (1995)::Comedy|Romance
4::Waiting to Exhale (1995)::Comedy|Drama
5::Father of the Bride Part II (1995)::Comedy
6::Heat (1995)::Action|Crime|Thriller
7::Sabrina (1995)::Comedy|Romance
8::Tom and Huck (1995)::Adventure|Children's
9::Sudden Death (1995)::Action
10::GoldenEye (1995)::Action|Adventure|Thriller
users.dat 6041条数据
1::F::1::10::48067
2::M::56::16::70072
3::M::25::15::55117
4::M::45::7::02460
5::M::25::20::55455
6::F::50::9::55117
7::M::35::1::06810
8::M::25::12::11413
9::M::25::17::61614
10::F::35::1::95370
ratings.dat 1000210条数据
1::1193::5::978300760
1::661::3::978302109
1::914::3::978301968
1::3408::4::978300275
1::2355::5::978824291
1::1197::3::978302268
1::1287::5::978302039
1::2804::5::978300719
1::594::4::978302268
1::919::4::978301368
数据解释
1、users.dat 数据格式为: 2::M::56::16::70072
对应字段为:UserID BigInt, Gender String, Age Int, Occupation String, Zipcode String
对应字段中文解释:用户id,性别,年龄,职业,邮政编码
2、movies.dat 数据格式为: 2::Jumanji (1995)::Adventure|Children's|Fantasy
对应字段为:MovieID BigInt, Title String, Genres String
对应字段中文解释:电影ID,电影名字,电影类型
3、ratings.dat 数据格式为: 1::1193::5::978300760
对应字段为:UserID BigInt, MovieID BigInt, Rating Double, Timestamped String
对应字段中文解释:用户ID,电影ID,评分,评分时间戳
用户ID,电影ID,评分,评分时间戳,性别,年龄,职业,邮政编码,电影名字,电影类型
userid, movieId, rate, ts, gender, age, occupation, zipcode, movieName, movieType
需求统计
(1)求被评分次数最多的10部电影,并给出评分次数(电影名,评分次数)
(2)分别求男性,女性当中评分最高的10部电影(性别,电影名,评分)
(3)求movieid = 2116这部电影各年龄段(因为年龄就只有7个,就按这个7个分就好了)的平均影评(年龄段,评分)
(4)求最喜欢看电影(影评次数最多)的那位女性评最高分的10部电影的平均影评分(人,电影名,影评)
(5)求好片(评分>=4.0)最多的那个年份的最好看的10部电影
(6)求1997年上映的电影中,评分最高的10部Comedy类电影
(7)该影评库中各种类型电影中评价最高的5部电影(类型,电影名,平均影评分)
(8)各年评分最高的电影类型(年份,类型,影评分)
(9)每个地区最高评分的电影名,把结果存入HDFS(地区,电影名,电影评分)
代码实现
1、求被评分次数最多的10部电影,并给出评分次数(电影名,评分次数)
分析:此问题涉及到2个文件,ratings.dat和movies.dat,2个文件数据量倾斜比较严重,此处应该使用mapjoin方法,先将数据量较小的文件预先加载到内存中
MovieMR1_1.java
MovieMR1_2.java
MovieRating.java
2、分别求男性,女性当中评分最高的10部电影(性别,电影名,评分)
分析:此问题涉及到3个表的联合查询,需要先将2个小表的数据预先加载到内存中,再进行查询
对三表进行联合
MoviesThreeTableJoin.java
三表联合之后的数据为
1000::1023::5::975041651::Winnie the Pooh and the Blustery Day (1968)::Animation|Children's::F::25::6::90027
1000::1029::3::975041859::Dumbo (1941)::Animation|Children's|Musical::F::25::6::90027
1000::1036::4::975040964::Die Hard (1988)::Action|Thriller::F::25::6::90027
1000::1104::5::975042421::Streetcar Named Desire, A (1951)::Drama::F::25::6::90027
1000::110::5::975040841::Braveheart (1995)::Action|Drama|War::F::25::6::90027
1000::1196::3::975040841::Star Wars: Episode V - The Empire Strikes Back (1980)::Action|Adventure|Drama|Sci-Fi|War::F::25::6::90027
1000::1198::5::975040841::Raiders of the Lost Ark (1981)::Action|Adventure::F::25::6::90027
1000::1200::4::975041125::Aliens (1986)::Action|Sci-Fi|Thriller|War::F::25::6::90027
1000::1201::5::975041025::Good, The Bad and The Ugly, The (1966)::Action|Western::F::25::6::90027
1000::1210::5::975040629::Star Wars: Episode VI - Return of the Jedi (1983)::Action|Adventure|Romance|Sci-Fi|War::F::25::6::90027
字段解释
1000 :: 1036 :: 4 :: 975040964 :: Die Hard (1988) :: Action|Thriller :: F :: 25 :: 6 :: 90027 用户ID 电影ID 评分 评分时间戳 电影名字 电影类型 性别 年龄 职业 邮政编码 0 1 2 3 4 5 6 7 8 9
要分别求男性,女性当中评分最高的10部电影(性别,电影名,评分)
1、以性别和电影名分组,以电影名+性别为key,以评分为value进行计算;
2、以性别+电影名+评分作为对象,以性别分组,以评分降序进行输出TOP10
业务逻辑:MoviesDemo2.java
对象:MoviesSexBean.java
分组:MoviesSexGC.java
3、求movieid = 2116这部电影各年龄段(因为年龄就只有7个,就按这个7个分就好了)的平均影评(年龄段,评分)
以第二部三表联合之后的文件进行操作
4、求最喜欢看电影(影评次数最多)的那位女性评最高分的10部电影的平均影评分(人,电影名,影评)
1000 :: 1036 :: 4 :: 975040964 :: Die Hard (1988) :: Action|Thriller :: F :: 25 :: 6 :: 90027 用户ID 电影ID 评分 评分时间戳 电影名字 电影类型 性别 年龄 职业 邮政编码 0 1 2 3 4 5 6 7 8 9
(1)求出评论次数最多的女性ID
MoviesDemo4_1.java
三 销售数据
第一题
下面是三种商品的销售数据
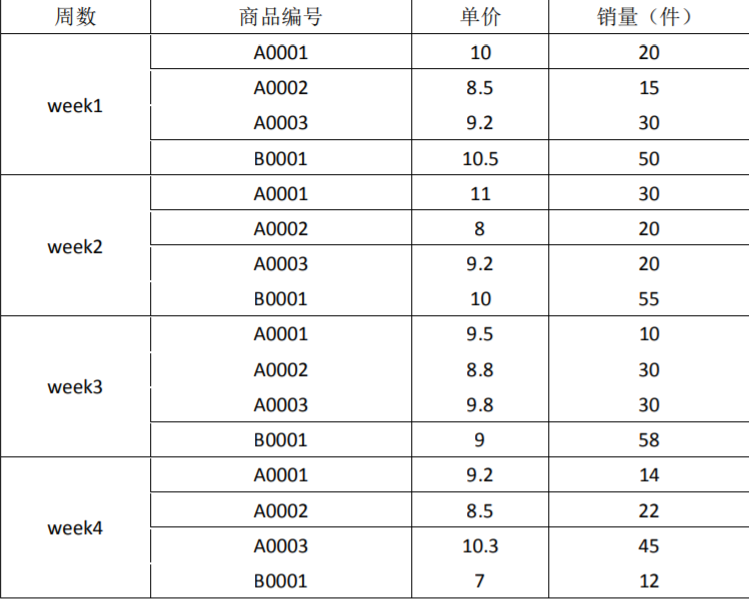
要求:根据以上数据,用 MapReduce 统计出如下数据:
1、每种商品的销售总金额,并降序排序
2、每种商品销售额最多的三周
第二题:MapReduce 题
现有如下数据文件需要处理:
格式:CSV
数据样例:
user_a,location_a,2018-01-01 08:00:00,60
user_a,location_a,2018-01-01 09:00:00,60
user_a,location_b,2018-01-01 10:00:00,60
user_a,location_a,2018-01-01 11:00:00,60
字段:用户 ID,位置 ID,开始时间,停留时长(分钟)
数据意义:某个用户在某个位置从某个时刻开始停留了多长时间
处理逻辑: 对同一个用户,在同一个位置,连续的多条记录进行合并
合并原则:开始时间取最早的,停留时长加和
要求:请编写 MapReduce 程序实现
其他:只有数据样例,没有数据。
UserLocationMR.java
UserLocation.java
UserLocationGC.java
第三题:MapReduce 题--倒排索引
概念: 倒排索引(Inverted Index),也常被称为反向索引、置入档案或反向档案,是一种索引方法, 被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档 检索系统中最常用的数据结构。了解详情可自行百度
有两份数据:
mapreduce-4-1.txt
huangbo love xuzheng
huangxiaoming love baby huangxiaoming love yangmi
liangchaowei love liujialing
huangxiaoming xuzheng huangbo wangbaoqiang
mapreduce-4-2.txt
hello huangbo
hello xuzheng
hello huangxiaoming
题目一:编写 MapReduce 求出以下格式的结果数据:统计每个关键词在每个文档中当中的 第几行出现了多少次 例如,huangxiaoming 关键词的格式:
huangixaoming mapreduce-4-1.txt:2,2; mapreduce-4-1.txt:4,1;mapreduce-4-2.txt:3,1
以上答案的意义:
关键词 huangxiaoming 在第一份文档 mapreduce-4-1.txt 中的第 2 行出现了 2 次
关键词 huangxiaoming 在第一份文档 mapreduce-4-1.txt 中的第 4 行出现了 1 次
关键词 huangxiaoming 在第二份文档 mapreduce-4-2.txt 中的第 3 行出现了 1 次
题目二:编写 MapReduce 程序求出每个关键词在每个文档出现了多少次,并且按照出现次 数降序排序
例如:
huangixaoming mapreduce-4-1.txt,3;mapreduce-4-2.txt,1
以上答案的含义: 表示关键词 huangxiaoming 在第一份文档 mapreduce-4-1.txt 中出现了 3 次,在第二份文档mapreduce-4-2.txt 中出现了 1 次
四求共同好友
数据格式
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J,K
以上是数据:
A:B,C,D,F,E,O
表示:B,C,D,E,F,O是A用户的好友。
1 public class SharedFriend {
2 /*
3 第一阶段的map函数主要完成以下任务
4 1.遍历原始文件中每行<所有朋友>信息
5 2.遍历“朋友”集合,以每个“朋友”为键,原来的“人”为值 即输出<朋友,人>
6 */
7 static class SharedFriendMapper01 extends Mapper<LongWritable, Text, Text, Text>{
8 @Override
9 protected void map(LongWritable key, Text value,Context context)
10 throws IOException, InterruptedException {
11 String line = value.toString();
12 String[] person_friends = line.split(":");
13 String person = person_friends[0];
14 String[] friends = person_friends[1].split(",");
15
16 for(String friend : friends){
17 context.write(new Text(friend), new Text(person));
18 }
19 }
20 }
21
22 /*
23 第一阶段的reduce函数主要完成以下任务
24 1.对所有传过来的<朋友,list(人)>进行拼接,输出<朋友,拥有这名朋友的所有人>
25 */
26 static class SharedFriendReducer01 extends Reducer<Text, Text, Text, Text>{
27 @Override
28 protected void reduce(Text key, Iterable<Text> values,Context context)
29 throws IOException, InterruptedException {
30 StringBuffer sb = new StringBuffer();
31 for(Text friend : values){
32 sb.append(friend.toString()).append(",");
33 }
34 sb.deleteCharAt(sb.length()-1);
35 context.write(key, new Text(sb.toString()));
36 }
37 }
38
39 /*
40 第二阶段的map函数主要完成以下任务
41 1.将上一阶段reduce输出的<朋友,拥有这名朋友的所有人>信息中的 “拥有这名朋友的所有人”进行排序 ,以防出现B-C C-B这样的重复
42 2.将 “拥有这名朋友的所有人”进行两两配对,并将配对后的字符串当做键,“朋友”当做值输出,即输出<人-人,共同朋友>
43 */
44 static class SharedFriendMapper02 extends Mapper<LongWritable, Text, Text, Text>{
45 @Override
46 protected void map(LongWritable key, Text value,Context context)
47 throws IOException, InterruptedException {
48 String line = value.toString();
49 String[] friend_persons = line.split("\t");
50 String friend = friend_persons[0];
51 String[] persons = friend_persons[1].split(",");
52 Arrays.sort(persons); //排序
53
54 //两两配对
55 for(int i=0;i<persons.length-1;i++){
56 for(int j=i+1;j<persons.length;j++){
57 context.write(new Text(persons[i]+"-"+persons[j]+":"), new Text(friend));
58 }
59 }
60 }
61 }
62
63 /*
64 第二阶段的reduce函数主要完成以下任务
65 1.<人-人,list(共同朋友)> 中的“共同好友”进行拼接 最后输出<人-人,两人的所有共同好友>
66 */
67 static class SharedFriendReducer02 extends Reducer<Text, Text, Text, Text>{
68 @Override
69 protected void reduce(Text key, Iterable<Text> values,Context context)
70 throws IOException, InterruptedException {
71 StringBuffer sb = new StringBuffer();
72 Set<String> set = new HashSet<String>();
73 for(Text friend : values){
74 if(!set.contains(friend.toString()))
75 set.add(friend.toString());
76 }
77 for(String friend : set){
78 sb.append(friend.toString()).append(",");
79 }
80 sb.deleteCharAt(sb.length()-1);
81
82 context.write(key, new Text(sb.toString()));
83 }
84 }
85
86 public static void main(String[] args)throws Exception {
87 Configuration conf = new Configuration();
88
89 //第一阶段
90 Job job1 = Job.getInstance(conf);
91 job1.setJarByClass(SharedFriend.class);
92 job1.setMapperClass(SharedFriendMapper01.class);
93 job1.setReducerClass(SharedFriendReducer01.class);
94
95 job1.setOutputKeyClass(Text.class);
96 job1.setOutputValueClass(Text.class);
97
98 FileInputFormat.setInputPaths(job1, new Path("H:/大数据/mapreduce/sharedfriend/input"));
99 FileOutputFormat.setOutputPath(job1, new Path("H:/大数据/mapreduce/sharedfriend/output"));
100
101 boolean res1 = job1.waitForCompletion(true);
102
103 //第二阶段
104 Job job2 = Job.getInstance(conf);
105 job2.setJarByClass(SharedFriend.class);
106 job2.setMapperClass(SharedFriendMapper02.class);
107 job2.setReducerClass(SharedFriendReducer02.class);
108
109 job2.setOutputKeyClass(Text.class);
110 job2.setOutputValueClass(Text.class);
111
112 FileInputFormat.setInputPaths(job2, new Path("H:/大数据/mapreduce/sharedfriend/output"));
113 FileOutputFormat.setOutputPath(job2, new Path("H:/大数据/mapreduce/sharedfriend/output01"));
114
115 boolean res2 = job2.waitForCompletion(true);
116
117 System.exit(res1?0:1);
118 }
119 }
第一阶段输出结果
第二阶段输出结果
Hadoop案例(十一)MapReduce的API使用的更多相关文章
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- hadoop笔记之MapReduce的应用案例(利用MapReduce进行排序)
MapReduce的应用案例(利用MapReduce进行排序) MapReduce的应用案例(利用MapReduce进行排序) 思路: Reduce之后直接进行结果合并 具体样例: 程序名:Sort. ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之网页排序(二十八)
不多说,直接上代码. Map output bytes=247 Map output materialized bytes=275 Input split bytes=139 Combine inpu ...
- Hadoop MapReduce编程 API入门系列之倒排索引(二十四)
不多说,直接上代码. 2016-12-12 21:54:04,509 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JV ...
- Hadoop MapReduce编程 API入门系列之二次排序(十六)
不多说,直接上代码. -- ::, INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with pr ...
- Hadoop MapReduce编程 API入门系列之最短路径(十五)
不多说,直接上代码. ======================================= Iteration: 1= Input path: out/shortestpath/input. ...
- Hadoop MapReduce编程 API入门系列之多个Job迭代式MapReduce运行(十二)
推荐 MapReduce分析明星微博数据 http://git.oschina.net/ljc520313/codeexample/tree/master/bigdata/hadoop/mapredu ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
随机推荐
- python基础之02列表/元组/字典/set集合
python中内置的数据类型有列表(list)元组(tuple)字典(directory). 1 list list是一种可变的有序的集合.来看一个list实例: #第一种方法: >>&g ...
- Ansible8:Playbook循环
目录 1.with_items 2.with_nested嵌套循环 3.with_dict 4.with_fileglob文件匹配遍历 5.with_lines 6.with_subelement遍历 ...
- JavaScript setInterval 与 setTimeout 区别
setInterval:一直循环调用函数,不会停止:需要用 clearInterval 去停止 setTimeout:只调用一次
- soj1036. Crypto Columns
1036. Crypto Columns Constraints Time Limit: 1 secs, Memory Limit: 32 MB Description The columnar en ...
- Linux dig命令
dig(Domain Information Groper),和nslookup作用有些类似,都是DNS查询工具 1.dig命令格式 dig @dnsserver name querytype 如果你 ...
- mogodb的安装与配置
下载:https://www.mongodb.com/https://www.mongodb.com/ 安装:一直next,中间选择custom,选择自己的安装路径,最后安装成功. 配置:打开安装好的 ...
- UNIX网络编程 第3章 套接字编程简介
套接字结构类型和相关的格式转换函数
- python 面试题3
注:本面试题来源于网络. 1.python下多线程的限制以及多进程中传递参数的方式 python多线程有个全局解释器锁(global interpreter lock),这个锁的意思是任一时间只能有一 ...
- Shiro认证的另一种方式
今天在学习shiro的时候使用另一种shiro验证的方式. 总体的思路是: (1)先在自己的方法中进行身份的验证以及给出提示信息.(前提是将自己的验证方法设为匿名可访问) (2)当验证成功之后到Shi ...
- C++面试常见问题
转载:https://zhuanlan.zhihu.com/p/34016871?utm_source=qq&utm_medium=social 1.在C++ 程序中调用被C 编译器编译后的函 ...