MapReduce的原理及执行过程
MapReduce简介
- MapReduce是一种分布式计算模型,是Google提出的,主要用于搜索领域,解决海量数据的计算问题。
- MR有两个阶段组成:Map和Reduce,用户只需实现map()和reduce()两个函数,即可实现分布式计算。
MapReduce执行流程
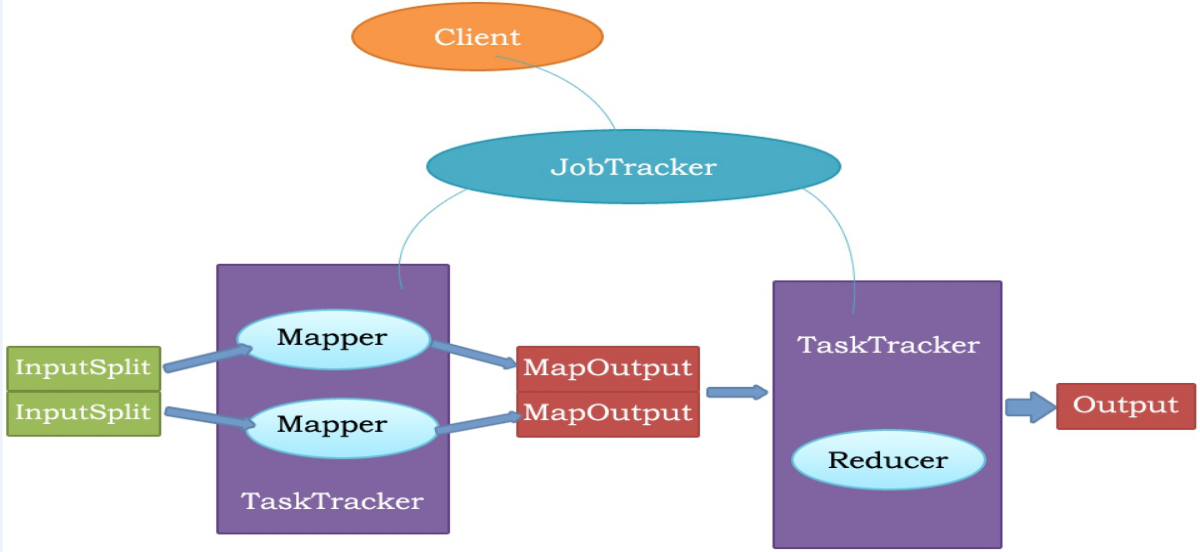
MapReduce原理
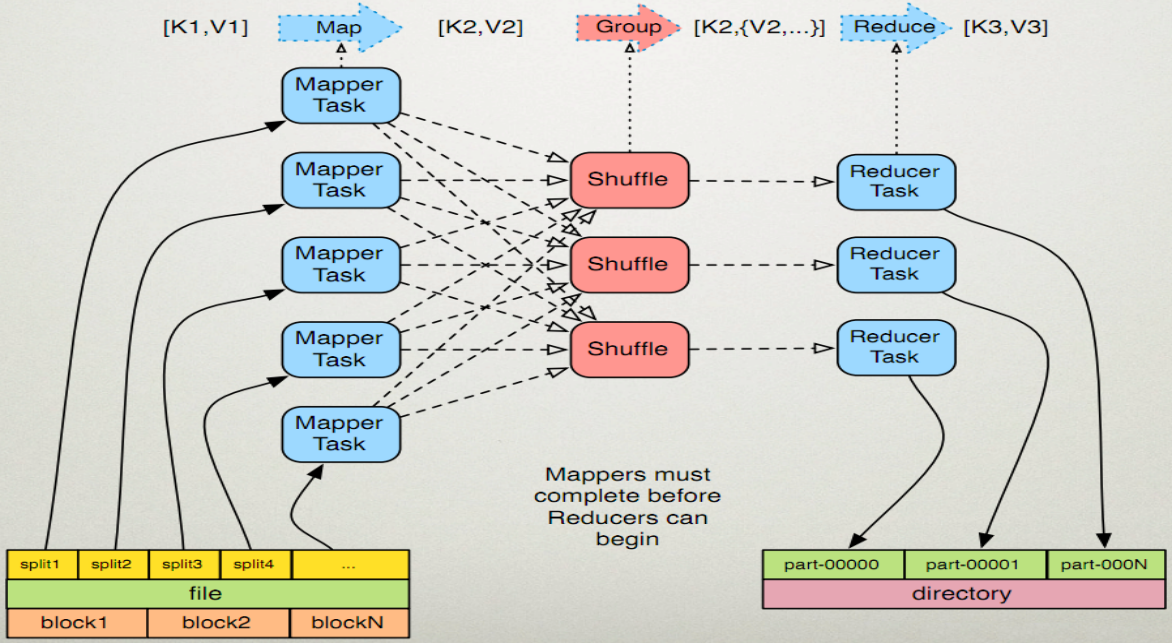
MapReduce的执行步骤:
1、Map任务处理
1.1 读取HDFS中的文件。每一行解析成一个<k,v>。每一个键值对调用一次map函数。 <0,hello you> <10,hello me>
1.2 覆盖map(),接收1.1产生的<k,v>,进行处理,转换为新的<k,v>输出。 <hello,1> <you,1> <hello,1> <me,1>
1.3 对1.2输出的<k,v>进行分区。默认分为一个区。详见《Partitioner》
1.4 对不同分区中的数据进行排序(按照k)、分组。分组指的是相同key的value放到一个集合中。 排序后:<hello,1> <hello,1> <me,1> <you,1> 分组后:<hello,{1,1}><me,{1}><you,{1}>
1.5 (可选)对分组后的数据进行归约。详见《Combiner》
2、Reduce任务处理
2.1 多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点上。(shuffle)详见《shuffle过程分析》
2.2 对多个map的输出进行合并、排序。覆盖reduce函数,接收的是分组后的数据,实现自己的业务逻辑, <hello,2> <me,1> <you,1>
处理后,产生新的<k,v>输出。
2.3 对reduce输出的<k,v>写到HDFS中。
Java代码实现
注:要导入org.apache.hadoop.fs.FileUtil.java。
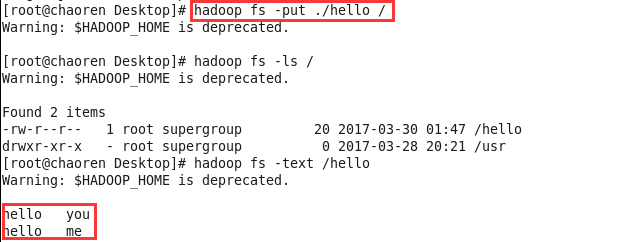
1、先创建一个hello文件,上传到HDFS中
2、然后再编写代码,实现文件中的单词个数统计(代码中被注释掉的代码,是可以省略的,不省略也行)
package mapreduce; import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class WordCountApp {
static final String INPUT_PATH = "hdfs://chaoren:9000/hello";
static final String OUT_PATH = "hdfs://chaoren:9000/out"; public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf);
Path outPath = new Path(OUT_PATH);
if (fileSystem.exists(outPath)) {
fileSystem.delete(outPath, true);
} Job job = new Job(conf, WordCountApp.class.getSimpleName()); // 1.1指定读取的文件位于哪里
FileInputFormat.setInputPaths(job, INPUT_PATH);
// 指定如何对输入的文件进行格式化,把输入文件每一行解析成键值对
//job.setInputFormatClass(TextInputFormat.class); // 1.2指定自定义的map类
job.setMapperClass(MyMapper.class);
// map输出的<k,v>类型。如果<k3,v3>的类型与<k2,v2>类型一致,则可以省略
//job.setOutputKeyClass(Text.class);
//job.setOutputValueClass(LongWritable.class); // 1.3分区
//job.setPartitionerClass(org.apache.hadoop.mapreduce.lib.partition.HashPartitioner.class);
// 有一个reduce任务运行
//job.setNumReduceTasks(1); // 1.4排序、分组 // 1.5归约 // 2.2指定自定义reduce类
job.setReducerClass(MyReducer.class);
// 指定reduce的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); // 2.3指定写出到哪里
FileOutputFormat.setOutputPath(job, outPath);
// 指定输出文件的格式化类
//job.setOutputFormatClass(TextOutputFormat.class); // 把job提交给jobtracker运行
job.waitForCompletion(true);
} /**
*
* KEYIN 即K1 表示行的偏移量
* VALUEIN 即V1 表示行文本内容
* KEYOUT 即K2 表示行中出现的单词
* VALUEOUT 即V2 表示行中出现的单词的次数,固定值1
*
*/
static class MyMapper extends
Mapper<LongWritable, Text, Text, LongWritable> {
protected void map(LongWritable k1, Text v1, Context context)
throws java.io.IOException, InterruptedException {
String[] splited = v1.toString().split("\t");
for (String word : splited) {
context.write(new Text(word), new LongWritable(1));
}
};
} /**
* KEYIN 即K2 表示行中出现的单词
* VALUEIN 即V2 表示出现的单词的次数
* KEYOUT 即K3 表示行中出现的不同单词
* VALUEOUT 即V3 表示行中出现的不同单词的总次数
*/
static class MyReducer extends
Reducer<Text, LongWritable, Text, LongWritable> {
protected void reduce(Text k2, java.lang.Iterable<LongWritable> v2s,
Context ctx) throws java.io.IOException,
InterruptedException {
long times = 0L;
for (LongWritable count : v2s) {
times += count.get();
}
ctx.write(k2, new LongWritable(times));
};
}
}
3、运行成功后,可以在Linux中查看操作的结果

MapReduce的原理及执行过程的更多相关文章
- 通过源码了解ASP.NET MVC 几种Filter的执行过程
一.前言 之前也阅读过MVC的源码,并了解过各个模块的运行原理和执行过程,但都没有形成文章(所以也忘得特别快),总感觉分析源码是大神的工作,而且很多人觉得平时根本不需要知道这些,会用就行了.其实阅读源 ...
- 通过源码了解ASP.NET MVC 几种Filter的执行过程 在Winform中菜单动态添加“最近使用文件”
通过源码了解ASP.NET MVC 几种Filter的执行过程 一.前言 之前也阅读过MVC的源码,并了解过各个模块的运行原理和执行过程,但都没有形成文章(所以也忘得特别快),总感觉分析源码是大神 ...
- MapReduce概述,原理,执行过程
MapReduce概述 MapReduce是一种分布式计算模型,运行时不会在一台机器上运行.hadoop是分布式的,它是运行在很多的TaskTracker之上的. 在我们的TaskTracker上面跑 ...
- Hadoop MapReduce执行过程详解(带hadoop例子)
https://my.oschina.net/itblog/blog/275294 摘要: 本文通过一个例子,详细介绍Hadoop 的 MapReduce过程. 分析MapReduce执行过程 Map ...
- Web APi之过滤器执行过程原理解析【二】(十一)
前言 上一节我们详细讲解了过滤器的创建过程以及粗略的介绍了五种过滤器,用此五种过滤器对实现对执行Action方法各个时期的拦截非常重要.这一节我们简单将讲述在Action方法上.控制器上.全局上以及授 ...
- 四、Struts2的执行过程和原理
执行过程和原理(可能面试题) 学习目标:熟知struts2的执行过程(下图记住).源码可以不看 a.过滤器的初始化 .StrutsPrepareAndExecuteFilter是一个过滤器,过滤器就有 ...
- 分析MapReduce执行过程
分析MapReduce执行过程 MapReduce运行的时候,会通过Mapper运行的任务读取HDFS中的数据文件,然后调用自己的方法,处理数据,最后输出. Reducer任务会接收Mapper任务输 ...
- JSP起源、JSP的运行原理、JSP的执行过程
JSP起源 在很多动态网页中,绝大部分内容都是固定不变的,只有局部内容需要动态产生和改变. 如果使用Servlet程序来输出只有局部内容需要动态改变的网页,其中所有的静态内容也需要程序员用Java程序 ...
- Hadoop学习之Mapreduce执行过程详解
一.MapReduce执行过程 MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入,大体执行流程如下图所示: ...
随机推荐
- python---堡垒机开发
一:堡垒机需求分析 注意: 虽然我们在中间使用防火墙服务器对流量进行拦截和转发也可以起到过滤作用,但是我们无法去获取到完整,正确的操作记录.因为无论是客户端还是服务器端(管理员可能会去修改记录,而且可 ...
- openresty/1.11.2.1性能测试
测试数据 ab -n -c -k http://127.0.0.1/get_cache_value nginx.conf lua_shared_dict cache_ngx 128m; server ...
- git 第一次关联远程仓库
1.首先需要先git pull origin master 2.然后合并两个无关的仓库 git pull origin master --allow-unrelated-histories
- Centos7系统中安装Nginx1.8.0
Nginx的安装 tar -zxvf nginx-1.8.0.tar.gz cd nginx-1.8.0 ./configure make make install /usr/local/nginx/ ...
- 一些达成共识的JavaScript编码约定[转]
如果你的代码易于阅读,那么代码中bug也将会很少,因为一些bug可以很容被调试,并且,其他开发者参与你项目时的门槛也会比较低.因此,如果项目中有多人参与,采取一个有共识的编码风格约定非常有必要.与其他 ...
- WPF控件收集
1.Extended WPF Toolkit 2.Fluent Ribbon Control Suite 3.WPF Ribbon Control 4.Telerik RadControls for ...
- 给Ubuntu替换阿里的源
1. 阿里巴巴镜像源站点 有所有linux的源的镜像加速. 点击查看介绍 2. 具体配置方法在这里 copy: ubuntu 18.04(bionic) 配置如下 创建自己的配置文件,比如创建文件 / ...
- FPGA基础知识8(FPGA静态时序分析)
任何学FPGA的人都跑不掉的一个问题就是进行静态时序分析.静态时序分析的公式,老实说很晦涩,而且总能看到不同的版本,内容又不那么一致,为了彻底解决这个问题,我研究了一天,终于找到了一种很简单的解读办法 ...
- 24、List三个子类的特点
List的三个子类的特点 因为三个类都实现了List接口,所以里面的方法都差不多,那这三个类都有什么特点呢? ArrayList:底层数据结构是数组,查询快,增删慢.线程不安全,效率高. Vector ...
- 【译】第一篇 Replication:复制简介
本篇文章是SQL Server Replication系列的第一篇,详细内容请参考原文. 复制这个词来自拉丁语中的"replicare",意味着重复.Replication des ...