全局唯一ID生成器
分布式环境中,如何保证生成的id是唯一不重复的?
twitter,开源出了一个snowflake算法,现在很多企业都按照该算法作为参照,实现了自己的一套id生成器。
该算法的主要思路为:
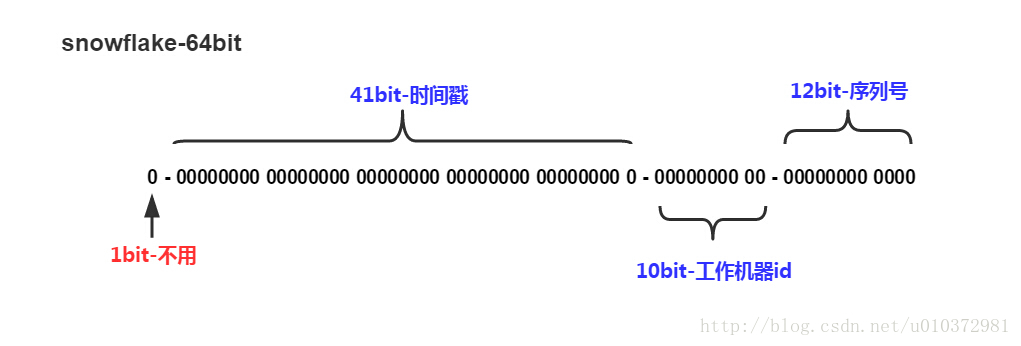
刚好64位的long型数据。
上图中主要由4个部分组成:
第一部分,1位为标识位,不用。
第二部分,41位,用来记录当前时间与标记时间twepoch的毫秒数的差值,41位的时间截,可以使用69年,T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69
第三部分,10位,用来记录当前节点的信息,支持2的10次方台机器
第四部分,12位,用来支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号
java代码
- /**
- * Twitter_Snowflake<br>
- * SnowFlake的结构如下(每部分用-分开):<br>
- * 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000 <br>
- * SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分)
- */
- public class SnowflakeIdWorker {
- /** 开始时间截 (2015-01-01) */
- private final long twepoch = 1420041600000L;
- /** 机器id所占的位数 */
- private final long workerIdBits = 5L;
- /** 数据标识id所占的位数 */
- private final long datacenterIdBits = 5L;
- /** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */
- private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
- /** 支持的最大数据标识id,结果是31 */
- private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
- /** 序列在id中占的位数 */
- private final long sequenceBits = 12L;
- /** 机器ID向左移12位 */
- private final long workerIdShift = sequenceBits;
- /** 数据标识id向左移17位(12+5) */
- private final long datacenterIdShift = sequenceBits + workerIdBits;
- /** 时间截向左移22位(5+5+12) */
- private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
- /** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */
- private final long sequenceMask = -1L ^ (-1L << sequenceBits);
- /** 工作机器ID(0~31) */
- private long workerId;
- /** 数据中心ID(0~31) */
- private long datacenterId;
- /** 毫秒内序列(0~4095) */
- private long sequence = 0L;
- /** 上次生成ID的时间截 */
- private long lastTimestamp = -1L;
- /**
- * 构造函数
- * @param workerId 工作ID (0~31)
- * @param datacenterId 数据中心ID (0~31)
- */
- public SnowflakeIdWorker(long workerId, long datacenterId) {
- if (workerId > maxWorkerId || workerId < 0) {
- throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
- }
- if (datacenterId > maxDatacenterId || datacenterId < 0) {
- throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
- }
- this.workerId = workerId;
- this.datacenterId = datacenterId;
- }
- /**
- * 获得下一个ID (该方法是线程安全的)
- * @return SnowflakeId
- */
- public synchronized long nextId() {
- long timestamp = timeGen();
- //如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
- if (timestamp < lastTimestamp) {
- throw new RuntimeException(
- String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
- }
- //如果是同一时间生成的,则进行毫秒内序列
- if (lastTimestamp == timestamp) {
- sequence = (sequence + 1) & sequenceMask;
- //毫秒内序列溢出
- if (sequence == 0) {
- //阻塞到下一个毫秒,获得新的时间戳
- timestamp = tilNextMillis(lastTimestamp);
- }
- }
- //时间戳改变,毫秒内序列重置
- else {
- sequence = 0L;
- }
- //上次生成ID的时间截
- lastTimestamp = timestamp;
- //移位并通过或运算拼到一起组成64位的ID
- return ((timestamp - twepoch) << timestampLeftShift) //
- | (datacenterId << datacenterIdShift) //
- | (workerId << workerIdShift) //
- | sequence;
- }
- /**
- * 阻塞到下一个毫秒,直到获得新的时间戳
- * @param lastTimestamp 上次生成ID的时间截
- * @return 当前时间戳
- */
- protected long tilNextMillis(long lastTimestamp) {
- long timestamp = timeGen();
- while (timestamp <= lastTimestamp) {
- timestamp = timeGen();
- }
- return timestamp;
- }
- /**
- * 返回以毫秒为单位的当前时间
- * @return 当前时间(毫秒)
- */
- protected long timeGen() {
- return System.currentTimeMillis();
- }
- }
/**
* Twitter_Snowflake<br>
* SnowFlake的结构如下(每部分用-分开):<br>
* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000 <br>
* SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分)
*/
public class SnowflakeIdWorker { /** 开始时间截 (2015-01-01) */
private final long twepoch = 1420041600000L; /** 机器id所占的位数 */
private final long workerIdBits = 5L; /** 数据标识id所占的位数 */
private final long datacenterIdBits = 5L; /** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */
private final long maxWorkerId = -1L ^ (-1L << workerIdBits); /** 支持的最大数据标识id,结果是31 */
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits); /** 序列在id中占的位数 */
private final long sequenceBits = 12L; /** 机器ID向左移12位 */
private final long workerIdShift = sequenceBits; /** 数据标识id向左移17位(12+5) */
private final long datacenterIdShift = sequenceBits + workerIdBits; /** 时间截向左移22位(5+5+12) */
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits; /** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */
private final long sequenceMask = -1L ^ (-1L << sequenceBits); /** 工作机器ID(0~31) */
private long workerId; /** 数据中心ID(0~31) */
private long datacenterId; /** 毫秒内序列(0~4095) */
private long sequence = 0L; /** 上次生成ID的时间截 */
private long lastTimestamp = -1L; /**
* 构造函数
* @param workerId 工作ID (0~31)
* @param datacenterId 数据中心ID (0~31)
*/
public SnowflakeIdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
} /**
* 获得下一个ID (该方法是线程安全的)
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen(); //如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
} //如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
}
//时间戳改变,毫秒内序列重置
else {
sequence = 0L;
} //上次生成ID的时间截
lastTimestamp = timestamp; //移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
} /**
* 阻塞到下一个毫秒,直到获得新的时间戳
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
} /**
* 返回以毫秒为单位的当前时间
* @return 当前时间(毫秒)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
}
全局唯一ID生成器的更多相关文章
- Spring Boot集成全局唯一ID生成器
流水号生成器(全局唯一 ID生成器)是服务化系统的基础设施,其在保障系统的正确运行和高可用方面发挥着重要作用.而关于流水号生成算法首屈一指的当属 Snowflake雪花算法,然而 Snowflake本 ...
- 全局唯一ID生成器(Snowflake ID组成) 分析
Snowflake ID组成 Snowflake ID有64bits长,由以下三部分组成: time—42bits,精确到ms,那就意味着其可以表示长达(2^42-1)/(1000360024*365 ...
- 常见的生成全局唯一id有哪些?他们各有什么优缺点?
分布式系统中全局唯一id是我们经常用到的,生成全局id方法由很多,我们选择的时候也比较纠结.每种方式都有各自的使用场景,如果我们熟悉各种方式及优缺点,使用的时候才会更方便.下面我们就一起来看一下常见的 ...
- 全局唯一ID设计
在分布式系统中,经常需要使用全局唯一ID查找对应的数据.产生这种ID需要保证系统全局唯一,而且要高性能以及占用相对较少的空间. 全局唯一ID在数据库中一般会被设成主键,这样为了保证数据插入时索引的快速 ...
- 高并发分布式系统中生成全局唯一Id汇总
数据在分片时,典型的是分库分表,就有一个全局ID生成的问题.单纯的生成全局ID并不是什么难题,但是生成的ID通常要满足分片的一些要求: 1 不能有单点故障. 2 以时间为序,或者ID里包含时间 ...
- 如何在高并发分布式系统中生成全局唯一Id(转)
http://www.cnblogs.com/heyuquan/p/global-guid-identity-maxId.html 又一个多月没冒泡了,其实最近学了些东西,但是没有安排时间整理成博文, ...
- 游戏服务器生成全局唯一ID的几种方法
在服务器系统开发时,为了适应数据大并发的请求,我们往往需要对数据进行异步存储,特别是在做分布式系统时,这个时候就不能等待插入数据库返回了取自动id了,而是需要在插入数据库之前生成一个全局的唯一id,使 ...
- (转)如何在高并发分布式系统中生成全局唯一Id
又一个多月没冒泡了,其实最近学了些东西,但是没有安排时间整理成博文,后续再奉上.最近还写了一个发邮件的组件以及性能测试请看 <NET开发邮件发送功能的全面教程(含邮件组件源码)> ,还弄了 ...
- 全局唯一ID发号器的几个思路
标识(ID / Identifier)是无处不在的,生成标识的主体是人,那么它就是一个命名过程,如果是计算机,那么它就是一个生成过程.如何保证分布式系统下,并行生成标识的唯一与标识的命名空间有着密不可 ...
随机推荐
- win7、8上走网络打印机(需找驱动包,不能自动)
不多说,直接上干货! 简而言之,就是, 第一步是,将电脑与打印机联上网,进行匹配,即连上网可以查找到打印机的型号. 第二步是,安装驱动. D:\Driver\HP LJP2015 PCL6(注意,这个 ...
- 解决chrome,下载在文件夹中显示,调用错误的关联程序
https://blog.csdn.net/qq_32337527/article/details/81778732?utm_source=blogxgwz0
- 11 - JavaSE之GUI
GUI(念法 gu yi) AWT AWT(Abstract Window Toolkit 抽象窗口开发包,在C# 或者 linux窗口开发类之上又封装一层,达到跨平台的目的)包括了很多类和接口,用于 ...
- Web服务端性能提升实践
随着互联网的不断发展,日常生活中越来越多的需求通过网络来实现,从衣食住行到金融教育,从口袋到身份,人们无时无刻不依赖着网络,而且越来越多的人通过网络来完成自己的需求. 作为直接面对来自客户请求的Web ...
- java HashMap源码分析(JDK8)
这两天在复习JAVA的知识点,想更深层次的了解一下JAVA,所以就看了看JAVA的源码,把自己的分析写在这里,也当做是笔记吧,方便记忆.写的不对的地方也请大家多多指教. JDK1.6中HashMap采 ...
- 2019.2.1 现有vue-cli项目引入ESLint
ESLint 不管是多人合作还是个人项目,代码规范是很重要的.这样做不仅可以很大程度地避免基本语法错误,也保证了代码的可读性. 可能在早期建立项目的时候,因为一些原因没有引入eslint.单元测试等, ...
- CUBA China 最新进展
各位关注CUBA平台的朋友,你们好! 距上次发布动态我们又沉默了大概两个月时间,这期间我们一直在翻译CUBA平台的文档.CUBA平台的开发文档相当丰富,所以这需要耗费较多的时间,至少比我们预想的时间要 ...
- C# 谁改了我的代码
本文告诉大家一个特殊的做法,可以修改一个字符串常量 我们来写一个简单的程序,把一个常量字符串输出 private const string str = "lindexi"; sta ...
- JavaScript unshift()函数移入数据到数组第一位
你不仅可以 shift(移出)数组中的第一个元素,你也可以 unshift(移入)一个元素到数组的头部. .unshift() 函数用起来就像 .push() 函数一样, 但不是在数组的末尾添加元素, ...
- Storm框架:如何实现crontab定时任务
Storm除了能对消息流进行处理,还能实现crontab定时任务. 只要在bolt中配置TOPOLOGY_TICK_TUPLE_FREQ_SECS项即可实现. @Override public Map ...