HBase LSM树存储引擎详解
1.前提
讲LSM树之前,需要提下三种基本的存储引擎,这样才能清楚LSM树的由来:
- 哈希存储引擎。
- B树存储引擎。
- LSM树(Log-Structured Merge Tree)存储引擎。
2. 哈希存储引擎
哈希存储引擎哈希表的持久化实现,支持增、删、改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储系统。对于key-value的插入以及查询,哈希表的复杂度都是O(1),明显比树的操作O(n)快,如果不需要有序的遍历数据,哈希表就非常适合。代表性的数据库有:Redis,Memcache,以及存储系统Bitcask。
举例Bitcask的哈希表数据结构为:
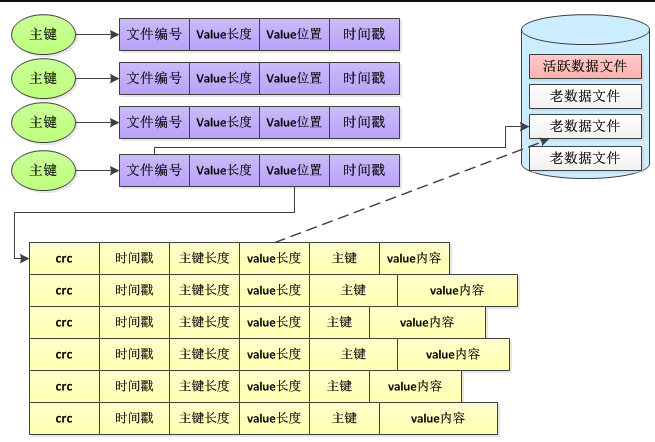
Bitcask数据文件中的数据是一条一条写入操作,记录包含key、value、主键长度、value长度、时间戳以及crc校验值。
数据库所在服务器在内存中采用基于哈希表的索引数据结构,哈希表的作用是通过主键快速地定位到value的位置。哈希表结构中的每一项包含了三个用于定位数据的信息,分别是文件编号(file id),value在文件中的位置(value_pos),value长度(value_sz),通过读取file_id对应文件的value_pos开始的value_sz个字节,这就得到了最终的value值。写入时首先将key-value记录追加到活跃数据文件的末尾,接着更新内存哈希表,因此,每个写操作总共需要进行一次顺序的磁盘写入和一次内存操作。
Bitcask在内存中存储了主键和value的索引信息,磁盘文件中存储了主键和value的实际内容。
3. B树存储引擎
相比哈希存储引擎,B树存储引擎不仅支持随机读取,还支持范围扫描。关系型数据库中通过索引访问数据,在Mysql InnoDB中,有一个称为聚集索引的特殊索引,行的数据存于其中,组织成B+树(B树的一种)数据结构。
B+树的数据结构:
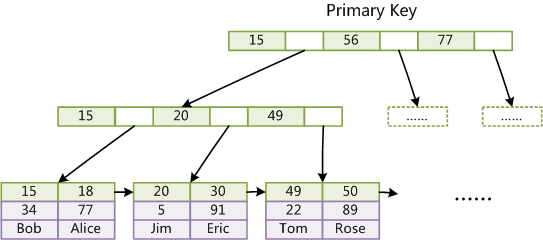
如图所示,MySQL InnoDB按照页面(Page)来组织数据,每个页面对应B+树的一个节点。其中,叶子节点保存每行的完整数据,非叶子节点保存索引信息。数据在每个节点中有序存储,数据库查询时需要从根节点开始二分查找直到叶子节点,每次读取一个节点,如果对应的页面不在内存中,需要从磁盘中读取并缓存起来。B+树的根节点是常驻内存的,因此,B+树一次检索最多需要h-1次磁盘IO,复杂度为O(h)=O(logdN)(N为元素个数,d为每个节点的出度,h为B+树高度)。修改操作首先需要记录提交日志,接着修改内存中的B+树。如果内存中的被修改过的页面超过一定的比率,后台线程会将这些页面刷到磁盘中持久化。
4. LSM树存储引擎
4.1 LSM主题思想
LSM-Tree主题思想为划分不同等级的数。可以想象一份索引由两棵树组成:一个存在于内存(可以使用其他树结构),一个存在于磁盘(如下图)。

LSM树的设计思想非常朴素:将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘,不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作,所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。极端的来说,基于LSM树实现的HBase的写性能比Mysql高了一个数量级,读性能低了一个数量级。
数据首先会插入到内存中的树,为了防止数据丢失,写内存的同时需要暂时持久化到磁盘,即输入数据时数据会以完全有序的形式先存储在日志文件中(对应HBase的MemStore和HLog)。当日志文件被修改时,对应的更新会被先保存在内存中来加速查询。
当内存中树的数据达到阀值时,会进行合并操作。合并操作会从左至右遍历内存中的叶子节点与磁盘中树的叶子节点进行合并,当合并的数据量达到磁盘的存储页的大小时,会将合并的数据持久化到磁盘。同时更新父亲节点对叶子节点的指针(如下图)。
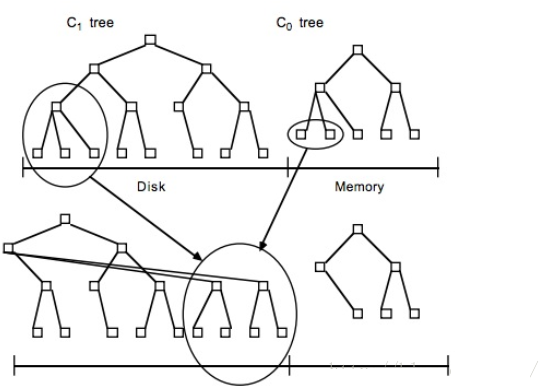
查找通过合并的方式完成,首先搜索内存存储结构,接下来是磁盘存储结构。
LSM树所有节点都是满的并按页存储,经过多次的flush会创建很多数据存储文件,后台线程会将小文件聚合成大文件,因此磁盘的寻道操作就会被限制在一定数目的数据存储文件中,以优化读性能。磁盘上的树结构也可以分割成多个存储文件,因为所有的存储数据都是按照Key有序排列的,因此在现有节点中插入新的关键字不需要重新排序。
LSM-Tree属于传输型,在磁盘传输速率上进行文件的排序和合并以及日志操作,可以更好的拓展到更大的数据规模上,因为它会使用日志文件和一个内存存储结构把随机写操作转化为顺序写,读写独立,不会产生两种操作的竞争。
4.2 LSM树在HBase中的应用
LSM树可以看成n层合并树。在HBase中,它把随机写转换成对MemStore和HFile的连续写。下图展示了LSM树数据写的过程。
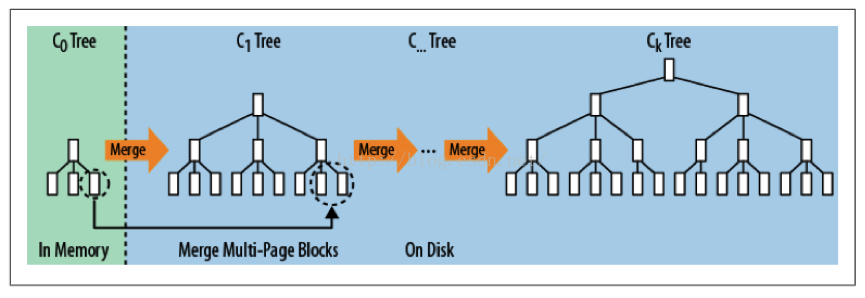
数据写(插入,更新):数据首先顺序写如HLog(WAL),然后写到MemStore,在MemStore中,数据是一个2层B+树(上图中的C0树)。MemStore满了之后,数据会被刷到StoreFile(HFile),在StoreFile中,数据是3层B+树(图2中的C1树),并针对顺序磁盘操作进行优化。
数据读:首先搜索MemStore,如果不再MemStore中,则到StoreFile中寻找。
数据删除:不会去删除磁盘上的数据,而是为数据添加一个删除标记。在随后的major compaction中,被删除的数据和删除标记才会真的被删除。
LSM数据更新只在内存中操作,没有磁盘访问,因此比B+树要快。对于数据读来说,如果读取的是最近访问过的数据,LSM树能减少磁盘访问,提高性能。
总结
参考资料:
https://blog.csdn.net/lifuxiangcaohui/article/details/39962921
https://blog.csdn.net/a_zhenzhen/article/details/78831866
https://blog.csdn.net/liuxiao723846/article/details/52971511
https://blog.csdn.net/u014432433/article/details/51557834
HBase LSM树存储引擎详解的更多相关文章
- MySQL数据库的各种存储引擎详解
原文来自:MySQL数据库的各种存储引擎详解 MySQL有多种存储引擎,每种存储引擎有各自的优缺点,大家可以择优选择使用: MyISAM.InnoDB.MERGE.MEMORY(HEAP).BDB ...
- Linux MySQL 存储引擎详解
MySQL常用的存储引擎为MyISAM.InnoDB.MEMORY.MERGE,其中InnoDB提供事务安全表,其他存储引擎都是非事务安全表. MyISAM是MySQL的默认存储引擎.MyISAM不支 ...
- 主流存储引擎详解:Innodb,Tokudb、Memory、MYISAM、Federated
主流存储引擎: Innodb:推荐使用,主力引擎,使用99%以上的场景 Tokudb:高速写入使用,日用量大量写入eg:500G可压缩为50G.适用于访问日志的写入,相对MYISAM有事务性,相对于I ...
- Mysql—存储引擎详解
存储引擎基本操作 查看数据库支持的所有的存储引擎 mysql> show engines; 查看数据库目前使用的引擎 mysql> show varlables like "%s ...
- MySQL基础篇(05):逻辑架构图解和InnoDB存储引擎详解
本文源码:GitHub·点这里 || GitEE·点这里 一.MySQL逻辑架构 1.逻辑架构图 基于下面的逻辑架构图,可以大致熟悉MySQL各个架构组件之间的协同工作关系. 很经典的C/S架构风格, ...
- MyIASM和Innodb引擎详解
MyIASM 和 Innodb引擎详解 Innodb引擎 Innodb引擎提供了对数据库ACID事务的支持,并且实现了SQL标准的四种隔离级别,关于数据库事务与其隔离级别的内容请见数据库事务与其隔离级 ...
- 如何查看mysql数据库的引擎/MySQL数据库引擎详解
一般情况下,mysql会默认提供多种存储引擎,你可以通过下面的查看: 看你的mysql现在已提供什么存储引擎:mysql> show engines; 看你的mysql当前默认的存储引擎:mys ...
- Kubernetes K8S之存储Volume详解
K8S之存储Volume概述与说明,并详解常用Volume示例 主机配置规划 服务器名称(hostname) 系统版本 配置 内网IP 外网IP(模拟) k8s-master CentOS7.7 2C ...
- AVL树平衡旋转详解
AVL树平衡旋转详解 概述 AVL树又叫做平衡二叉树.前言部分我也有说到,AVL树的前提是二叉排序树(BST或叫做二叉查找树).由于在生成BST树的过程中可能会出现线型树结构,比如插入的顺序是:1, ...
随机推荐
- C#枚举(Enum)小结
枚举概念 枚举类型(也称为枚举)提供了一种有效的方式来定义可能分配给变量的一组已命名整数常量.该类型使用enum关键字声明. 示例代码1 enum Day { Sunday, Monday, Tues ...
- python中json文件处理涉及的四个函数json.dumps()和json.loads()、json.dump()和json.load()的区分
一.概念理解 1.json.dumps()和json.loads()是json格式处理函数(可以这么理解,json是字符串) (1)json.dumps()函数是将一个Python数据类型列表进行js ...
- Python基础之字典
字典初识 字典的认识 首先,我们来认识一下字典: # 定义一个字典 user_dict = {"name": "zhangsan", "age&quo ...
- Linux 基础学习:文件权限与种类
1.文件权限 linux系统中通过 “ls -al”,可查看当前目录的所有文件的详细信息. 第一列代表这个文件的类型与权限: 第一个字符表示文件类型: [d]:表示目录文件 [-]:表示普通文件 [l ...
- iOS 快捷下载和安装并使用CocoaPods
CocoaPods是什么? 当你开发iOS应用时,会经常使用到很多第三方开源类库,比如JSONKit,AFNetWorking等等.可能某个类库又用到其他类库,所以要使用它,手动一个个去下载所需类库十 ...
- VUE中使用geetest滑动验证码
一,准备工作:服务端部署 下载文件gt.gs: https://github.com/GeeTeam/gt3-python-sdk 需要说明的是这里的gt.js文件,它用于加载对应的验证JS库. 1. ...
- day08(字符编码,字符与字节,文件操作)
一,复习 ''' 类型转换 1.数字类型:int() | bool() | float() 2.str与int: int('10') | int('-10') | int('0') | float(' ...
- HSSFWorkbook 导出excel java
public String exportExcelList(){ //创建webbook,对应一个excel文件 HSSFWorkbook wb = new HSSFWorkbook(); //在we ...
- Python操作Excel 之 openpyxl
一.基础 安装openpyxl 模块 pip install openpyxl 或者通过轮子安装 font(字体类):字号.字体颜色.下划线等 fill(填充类):颜色等 border(边框类):设置 ...
- OO第一单元总结——多项式求导
第一次作业分析 1.程序结构分析 类图: 好吧,这一次基本上完全是在面向过程编程,没有看出来任何的面向对象的特性. 复杂度: 可以看到模块间的相互耦合度很高,PolyDerive方法的非结构化程度也不 ...