Adversarial Examples for Semantic Segmentation and Object Detection 阅读笔记
Adversarial Examples for Semantic Segmentation and Object Detection
(语义分割和目标检测中的对抗样本)
作者:Cihang Xie, Jianyu Wang, Zhishuai Zhang, Yuyin Zhou, Lingxi Xie, Alan Yuille, Department of Computer Science, The Johns Hopkins University, Baltimore, MD 21218 USA Baidu Research USA, Sunnyvale, CA 94089 USA
机构:The Johns Hopkins University(美国约翰霍普金斯大学)
全文链接:https://arxiv.org/abs/1703.08603
摘要:对抗样本:给自然图片加入视觉不可见的噪声,可能导致深层网络无法对图像进行正确分类。

如上样本x的label为熊猫,在对x添加部分干扰后,在人眼中仍然分为熊猫,但对深度模型,却将其错分为长臂猿,且给出了高达99.3%的置信度。
在本文中,我们将对抗样本扩展到语义分割和目标检测中。分割和检测都是建立在对图像目标分类的基础上,比如分割是对目标区域或者像素进行分类,目标检测是对目标proposal分类。思考是否能在一组像素/proposal的基础上优化损失函数,以产生对抗样本。以此为基础,本文提出了一种新的算法:密度对抗生成网络 (DAG),它产生了大量的对抗样本,并应用于最先进的分割和检测深度网络上。实验发现,对抗样本可以在具有不同训练数据、不同架构、甚至不同识别任务的网络之间传递的特性(对抗样本是相对鲁棒的, 即神经网络A生成的对抗样本,在神经网路B下仍然是,即使B是不同的网络结构、超参、和训练数据。因此,神经网络含有一些内在的盲点和非显示的特征,其结构与数据分布相关)。实验证明:具有相同结构的网络的可移植性更强大。对非均匀扰动进行累加,能获得更好的传递性,为黑盒对抗攻击提供了一种有效的方法。
介绍:深度网络在视觉识别和特征表示方面取得了成功,但它们往往对输入图像的微小扰动非常敏感。添加视觉上不可感知的噪声会导致图像分类失败。这些添加噪声的图像,通常被称为对抗样本。噪声落在大的高维特征空间的一些区域,而这些区域在训练过程中没有被探索。因此,研究这一问题不仅有助于理解深层网络的工作机制,而且为提高网络训练的鲁棒性提供了机会。
本文生成了用于语义分割和目标检测的对抗样本,并展示了它们的可移植性。这个问题很难,因为需要考虑更多目标(例如像素或proposal)的数量级。
基于每个目标都需要经历一个单独的分类的过程,作者提出了DAG。DAG是一种同时考虑所有目标并优化整体损失函数的算法。它的实现很简单,只需要为每个目标指定一个对抗性标签,并执行迭代梯度反向传播。
在检测中产生对抗样本比在分割中更困难,因为在目标检测中,目标的数量要大几个数量级。对于有k个像素的图像,可能的proposal数量是O(k^2),而像素只有O(k)。如果只考虑proposal的一个子集,在提取出一组新的proposal后,扰动图像仍然可以被正确识别。为了增加攻击的鲁棒性,在优化中改变IOU率来保护一个在持续增加的合理的proposal数量。在实验中验证了当原始图像上的proposal足够密集时,扰动图像上产生的新proposal很可能也会产生错误的识别结果。
随着网络,数据,任务的差异增大,DAG产生的扰动在一定程度上的传递难度增大,但DAG产生的扰动在一定程度上能够传递。有趣的是,加入两个或更多的扰动可以显著提高可移植性,为一些未知结构和/或属性的网络实施黑盒对抗攻击提供了一种有效的方法。
本文算法:
1. DAG。
X代表图片。
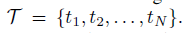 代表X的N个检测目标
代表X的N个检测目标
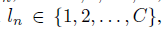 代表N个检测目标的标签,用
代表N个检测目标的标签,用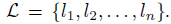 表示。
表示。
f( X, tn) ∈RC 去表示X的第n个目标的分类分数向量(在softmax之前)。生成对抗样本的目标是,对所有目标的预测结果都为错。比如对于每个n:
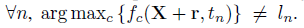
这里的r代表加入X的噪声。
为了这个目的,干脆给每个目标加入一个对抗标签l’n。l’n是从其他错误标签里随机选的。
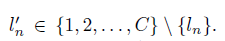 用
用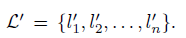 表示。
表示。
函数π用来表示这一随机选择排列函数。π: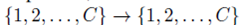 。
。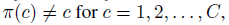 所以:
所以: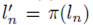 。
。
包括所有目标的损失函数可以写为:
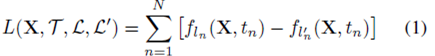
通过是的所有目标都被错误预测能够使得L最小化:抑制正确分类,促进期望分类(即对抗分类)。
使用梯度下降来实现最优化。在第m次迭代中,表示当前图像(可能在添加了几个扰动之后)为Xm。把正确预测的叫做active target set: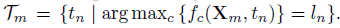
然后计算关于输入数据的梯度,然后累积所有这些扰动: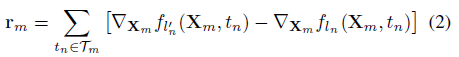
注意:就算m增大时, 这样就大大减少了开销。
这样就大大减少了开销。
为了避免数值不稳定,标准化: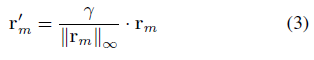
γ=0.5是固定的超参数。
然后,我们将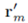 添加到当前图像Xm,并继续下一个迭代。
添加到当前图像Xm,并继续下一个迭代。
如果所有的目标都被预测为期望结果(即对抗结果),则算法终止 ,即,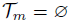 ;或达到最大迭代次数,分割任务设为200,检测任务设为150。
;或达到最大迭代次数,分割任务设为200,检测任务设为150。
最后的扰动r=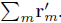 。注意,在实践中我们通常会把原图
。注意,在实践中我们通常会把原图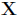 减 去均值
减 去均值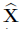 作为输入图像。所以最终的对抗图像是
作为输入图像。所以最终的对抗图像是 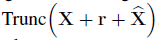 。
。 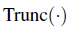 代表把每个像素归一化到[0,255]之间。
代表把每个像素归一化到[0,255]之间。
算法流程如下:

2. 为目标检测算法选择输入proposal。
DAG算法的一个关键问题是选择一个合理的τ集作为目标。
在语义分割任务中这个问题容易,目标是对所有像素产生不正确的分类,因此我们可以将每个像素设置为一个单独的目标,比如对图像点阵进行密集采样,这样计算复杂度与像素总数成正比。
在场景中的目标检测中,目标选择就很难了。因为整个可能的目标(边界盒子的proposal)在数量级上比语义分割大。用简单点的方法,只考虑通过一个sideway网络产生的proposal。比如:regional proposal 网络(RPN,是fast-RCNN结构中的一部分)。但是发现在对抗扰动r加入到原图像X中时,可能会因为新的输入X+r产生一个新的proposal,而且网络可能仍然能够正确地对这些新提议进行分类。为了解决这一问题,我们通过增加RPN中NMS(非极大值抑制)的阈值,使proposal变得非常密集。
在实践中把IOU从0.7调到0.9,每张图片的proposal从300张上升到3000张。使用这个更密集的目标集τ,最有可能的目标边界框,至少和一个输入proposal之间的距离只有一个像素,这样可以使得分类错误在相邻边界框之间转移。
从技术上讲,考虑RPN生成的proposal,保留所有positive proposals并丢弃其余的。positive proposals满足以下两个条件:(1)与最接近的真实物体框之间的IOU大于0.1。(2)对应的ground-truth的类别的置信度得分大于0:1。如果两个条件都适用于多个ground-truth 目标,选择IOU大的。proposals的标签被定义为相应的置信度类。该策略旨在为算法1选择高质量的目标。
3. 定量评估。
通过测量识别准确率的下降来评估本文方法,即使用原始测试图像和添加对抗性扰动后的图像,分别测量:均值IOU(mIOU)用于语义分割,均值平均精度(mAP)用于目标检测。
Adversarial Examples for Semantic Segmentation and Object Detection 阅读笔记的更多相关文章
- [YOLO]《You Only Look Once: Unified, Real-Time Object Detection》笔记
一.简单介绍 目标检测(Objection Detection)算是计算机视觉任务中比较常见的一个任务,该任务主要是对图像中特定的目标进行定位,通常是由一个矩形框来框出目标. 在深度学习CNN之前,传 ...
- Flow-Guided Feature Aggregation for Video Object Detection论文笔记
摘要 目前检测的准确率受物体视频中变化的影响,如运动模糊,镜头失焦等.现有工作是想要在框的级别上寻找时序信息,但这样的方法通常不能端到端训练.我们提出了flow-guided feature aggr ...
- Ubuntu18.04下安装、测试tensorflow/models Tensorflow Object Detection API 笔记
参考:https://www.jianshu.com/p/1ed2d9ce6a88 安装 安装conda+tensorflow库 下载protoc linux x64版,https://github. ...
- 《MIDINET: A CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORK FOR SYMBOLIC-DOMAIN MUSIC GENERATION》论文阅读笔记
出处 arXiv.org (引用量暂时只有3,too new)2017.7 SourceCode:https://github.com/RichardYang40148/MidiNet Abstrac ...
- JDK源码阅读:Object类阅读笔记
Object 1. @HotSpotIntrinsicCandidate @HotSpotIntrinsicCandidate public final native Class<?> g ...
- semantic segmentation 和instance segmentation
作者:周博磊链接:https://www.zhihu.com/question/51704852/answer/127120264来源:知乎著作权归作者所有,转载请联系作者获得授权. 图1. 这张图清 ...
- 论文阅读笔记五十五:DenseBox: Unifying Landmark Localization with End to End Object Detection(CVPR2015)
论文原址:https://arxiv.org/abs/1509.04874 github:https://github.com/CaptainEven/DenseBox 摘要 本文先提出了一个问题:如 ...
- 目标检测(一)RCNN--Rich feature hierarchies for accurate object detection and semantic segmentation(v5)
作者:Ross Girshick,Jeff Donahue,Trevor Darrell,Jitendra Malik 该论文提出了一种简单且可扩展的检测算法,在VOC2012数据集上取得的mAP比当 ...
- 目标检测--Rich feature hierarchies for accurate object detection and semantic segmentation(CVPR 2014)
Rich feature hierarchies for accurate object detection and semantic segmentation 作者: Ross Girshick J ...
随机推荐
- VirtualBox中安装CentOS 7_Linux
准备条件 在自己真实机上已经安装了VirtualBox虚拟机,具体安装方法可以参考Linux公社的文章. 下载CentOS-7的镜像 1. 在虚拟机中创建虚拟电脑 如图点击新建按钮,开始新建虚拟机电脑 ...
- Qt线程—QThread的使用--run和movetoThread的用法
Qt使用线程主要有两种方法: 方法一:继承QThread,重写run()的方法 QThread是一个非常便利的跨平台的对平台原生线程的抽象.启动一个线程是很简单的.让我们看一个简短的代码:生成一个在线 ...
- mysql查询表是否存在
查询表是否存在 SHOW TABLES LIKE "表名" tp5查询表是否存在 Db::query('SHOW TABLES LIKE "表名"');
- java非阻塞NIO和阻塞IO
1 非阻塞NIO和阻塞IO 1.1 定义 阻塞IO:线程被阻塞,去处理一个读取和写入,中间如果有等待时间,则线程被占用,也不能处理其他任务: 非阻塞IO(new I ...
- Codeforces 741 D - Arpa’s letter-marked tree and Mehrdad’s Dokhtar-kosh paths
D - Arpa’s letter-marked tree and Mehrdad’s Dokhtar-kosh paths 思路: 树上启发式合并 从根节点出发到每个位置的每个字符的奇偶性记为每个位 ...
- font-spider-plus,字体压缩插件使用笔记
font-spider-plus使用笔记, fsp是一个腾讯的大佬改版后的font-soider 主要思路是 采集线上网页使用到的字体,从字体文件中分离出来,完成大幅度压缩, 1,npm i font ...
- 人生苦短,我用python(目录)
一.python基础篇 python中闭包及延时绑定问题 python中的装饰器.生成器 二.前端 bootstrap框架 BOM&DOM JavaScript中的词法分析 三.数据库 mys ...
- git不提交某个文件
在版本库中的文件,即使维护在.gitignore也不管用了.要先移除. 比如Constants.java,进入到这个文件目录下: 第一步:git rm -r -n —cached Constants. ...
- WDA基础十五:POPUP WINDOW
1.组件控制器定义属性: 2.实现popup方法: METHOD stock_popup . DATA: l_cmp_api TYPE REF TO if_wd_component, l_window ...
- vue-cli使用swiper插件
使用的教程https://blog.csdn.net/lbpro0412/article/details/82465067