tensorflow Tensorboard2-【老鱼学tensorflow】
前面我们用Tensorboard显示了tensorflow的程序结构,本节主要用Tensorboard显示各个参数值的变化以及损失函数的值的变化。
这里的核心函数有:
histogram
例如:
tf.summary.histogram(layer_name + "/weights", Weights)
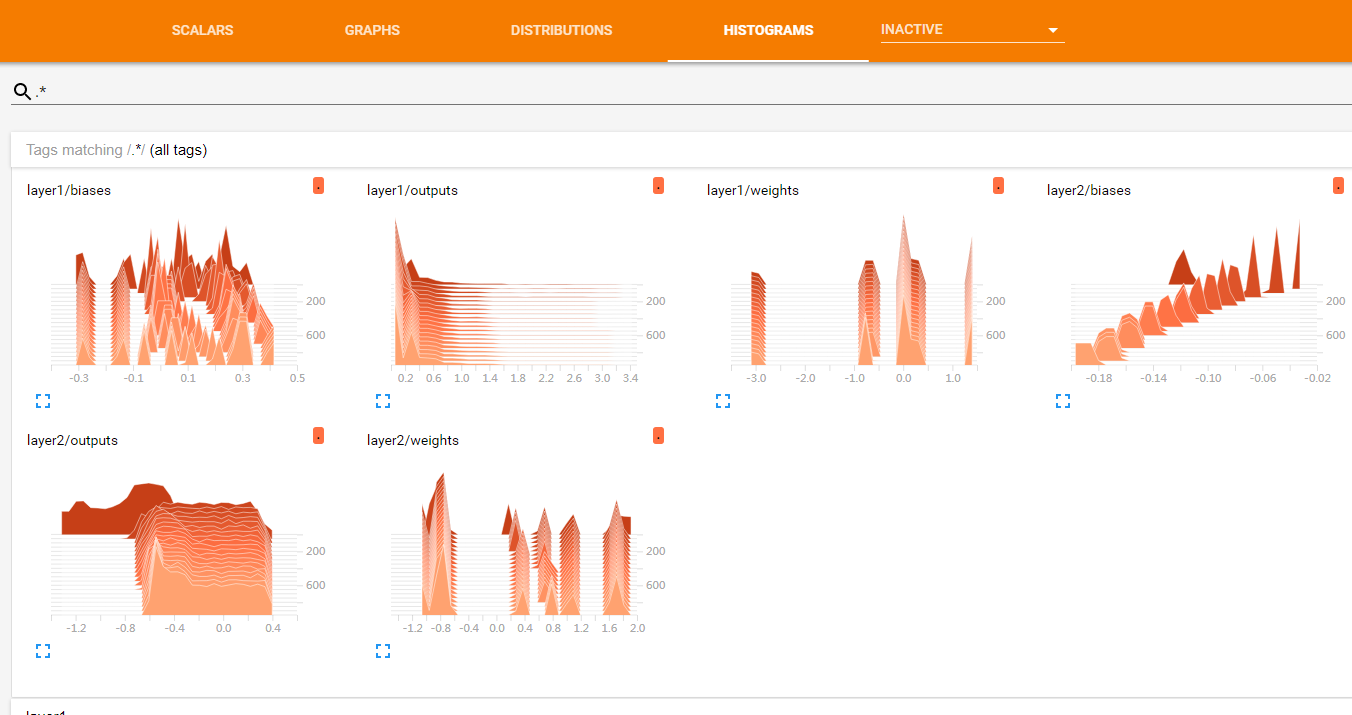
这里用tf.summary.histogram函数来显示二维数据在不同网络层的变化情况,其中第一个参数是名字,可以用/来进行分层显示,第二个参数就是相应变量的值。
scalar
tf.summary.scalar('loss', loss)
用scalar来显示单个值。
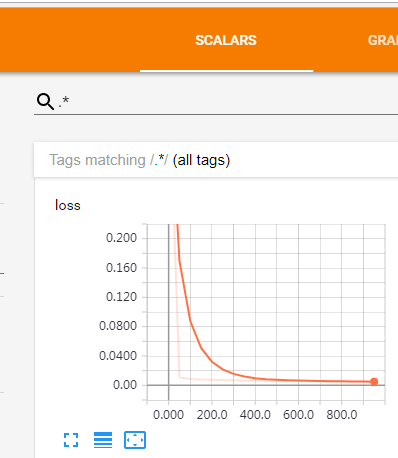
尽管是单个值,但因为会在不同的循环下有不同的值,因此还是会有一系列的点组成的曲线,在这里可以查看损失值是否在逐步递减。
这样我们就不需要用matplot来额外地画图了。
merge all & writer
要把所有的summary合并在一起并在适当的时候进行输出:
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("E:/todel/data/tensorflow", sess.graph)
最后在训练循环中进行输出:
result = sess.run(merged, feed_dict={xs:x_data, ys:y_data})
writer.add_summary(result, i)
完整的代码
import tensorflow as tf
import matplotlib.pyplot as plt
def add_layer(inputs, in_size, out_size, n_layer, activation_function=None):
"""
添加层
:param inputs: 输入数据
:param in_size: 输入数据的列数
:param out_size: 输出数据的列数
:param activation_function: 激励函数
:return:
"""
layer_name = 'layer%s' % n_layer
# 定义权重,初始时使用随机变量,可以简单理解为在进行梯度下降时的随机初始点,这个随机初始点要比0值好,因为如果是0值的话,反复计算就一直是固定在0中,导致可能下降不到其它位置去。
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
tf.summary.histogram(layer_name + "/weights", Weights)
# 偏置shape为1行out_size列
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
tf.summary.histogram(layer_name + "/biases", biases)
# 建立神经网络线性公式:inputs * Weights + biases,我们大脑中的神经元的传递基本上也是类似这样的线性公式,这里的权重就是每个神经元传递某信号的强弱系数,偏置值是指这个神经元的原先所拥有的电位高低值
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function is None:
# 如果没有设置激活函数,则直接就把当前信号原封不动地传递出去
outputs = Wx_plus_b
else:
# 如果设置了激活函数,则会由此激活函数来对信号进行传递或抑制
outputs = activation_function(Wx_plus_b)
tf.summary.histogram(layer_name + "/outputs", outputs)
return outputs
import numpy as np
# 创建一列(相当于只有一个属性值),300行的x值,这里np.newaxis用于新建出列数据,使其shape为(300, 1)
x_data = np.linspace(-1, 1, 300)[:,np.newaxis]
# 增加噪点,噪点的均值为0,标准差为0.05,形状跟x_data一样
noise = np.random.normal(0, 0.05, x_data.shape)
# 定义y的函数为二次曲线的函数,但同时增加了一些噪点数据
y_data = np.square(x_data) - 0.5 + noise
# 定义输入值,这里定义输入值的目的是为了能够使程序比较灵活,可以在神经网络启动时接收不同的实际输入值,这里输入的结构为输入的行数不国定,但列就是1列的值
xs = tf.placeholder(tf.float32, [None, 1], name='x_input')
ys = tf.placeholder(tf.float32, [None, 1], name='y_input')
# 定义一个隐藏层,输入为xs,输入size为1列,因为x_data就只有1个属性值,输出size我们假定输出的神经元有10个神经元的隐藏层,激励函数用relu
l1 = add_layer(xs, 1, 10, n_layer=1, activation_function=tf.nn.relu)
# 定义输出层,输入为l1,输入size为10列,也就是l1的列数,输出size为1,因为这里直接输出为类似y_data了,因此为1列,假定没有激励函数,也就是输出是啥就直接传递出去了。
predition = add_layer(l1, 10, 1, n_layer=2, activation_function=None)
# 定义损失函数为差值平方和的平均值
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - predition), axis=1))
tf.summary.scalar('loss', loss)
# 进行逐步优化的梯度下降优化器,学习效率为0.1,以最小化损失函数的方式进行优化
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 初始化所有定义的变量
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("E:/todel/data/tensorflow", sess.graph)
# 学习1000次
for i in range(1000):
sess.run(train_step, feed_dict={xs:x_data, ys:y_data})
# 打印期间的误差值,看这个误差值是否在减少
if i % 50 == 0:
result = sess.run(merged, feed_dict={xs:x_data, ys:y_data})
writer.add_summary(result, i)
最后在相应的目录下输入如下的命令显示Tensorboard中的图形:
tensorboard --logdir tensorflow
显示的图形为:
tensorflow Tensorboard2-【老鱼学tensorflow】的更多相关文章
- tensorflow卷积神经网络-【老鱼学tensorflow】
前面我们曾有篇文章中提到过关于用tensorflow训练手写2828像素点的数字的识别,在那篇文章中我们把手写数字图像直接碾压成了一个784列的数据进行识别,但实际上,这个图像是2828长宽结构的,我 ...
- tensorflow RNN循环神经网络 (分类例子)-【老鱼学tensorflow】
之前我们学习过用CNN(卷积神经网络)来识别手写字,在CNN中是把图片看成了二维矩阵,然后在二维矩阵中堆叠高度值来进行识别. 而在RNN中增添了时间的维度,因为我们会发现有些图片或者语言或语音等会在时 ...
- tensorflow保存读取-【老鱼学tensorflow】
当我们对模型进行了训练后,就需要把模型保存起来,便于在预测时直接用已经训练好的模型进行预测. 保存模型的权重和偏置值 假设我们已经训练好了模型,其中有关于weights和biases的值,例如: im ...
- tensorflow用dropout解决over fitting-【老鱼学tensorflow】
在机器学习中可能会存在过拟合的问题,表现为在训练集上表现很好,但在测试集中表现不如训练集中的那么好. 图中黑色曲线是正常模型,绿色曲线就是overfitting模型.尽管绿色曲线很精确的区分了所有的训 ...
- tensorflow分类-【老鱼学tensorflow】
前面我们学习过回归问题,比如对于房价的预测,因为其预测值是个连续的值,因此属于回归问题. 但还有一类问题属于分类的问题,比如我们根据一张图片来辨别它是一只猫还是一只狗.某篇文章的内容是属于体育新闻还是 ...
- tensorflow Tensorboard可视化-【老鱼学tensorflow】
tensorflow自带了可视化的工具:Tensorboard.有了这个可视化工具,可以让我们在调整各项参数时有了可视化的依据. 本次我们先用Tensorboard来可视化Tensorflow的结构. ...
- tensorflow优化器-【老鱼学tensorflow】
tensorflow中的优化器主要是各种求解方程的方法,我们知道求解非线性方程有各种方法,比如二分法.牛顿法.割线法等,类似的,tensorflow中的优化器也只是在求解方程时的各种方法. 比较常用的 ...
- tensorflow安装-【老鱼学tensorflow】
TensorFlow是谷歌基于DistBelief进行研发的第二代人工智能学习系统,其命名来源于本身的运行原理.Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,Tensor ...
- tensorflow例子-【老鱼学tensorflow】
本节主要用一个例子来讲述一下基本的tensorflow用法. 在这个例子中,我们首先伪造一些线性数据点,其实这些数据中本身就隐藏了一些规律,但我们假装不知道是什么规律,然后想通过神经网络来揭示这个规律 ...
随机推荐
- shell脚本备份日志文件
crontab -e crontab -l service crond restart 55 7 * * * /data/app/autoprice7/resin-pro-3.1.15/log_old ...
- 2017-12-19python全栈9期第四天第二节之列表的增删查改之元祖是只读列表、可循环查询、可切片、儿子不能改、孙子可以改
#!/user/bin/python# -*- coding:utf-8 -*-tu = ('zs','ls','ww',[1,2,3,4,5,'zxcvb'],'zl')print(tu[3])pr ...
- SVG---DEMO
SVG代码: <svg id="circle" data-name="circle_1" xmlns="http://www.w3.org/20 ...
- SQL Server 游标的使用示例
Ø 简介 本文主要记录 MSSQL 中的游标使用示例,在有必要时方便借鉴查阅.游标一般定义在某段功能性的 SQL 语句中,或者存储过程中.之所以选择用它,是因为有时候无法使用简单的 SQL 语句满足 ...
- windows查看已连接WIFI密码
找到wifi图标. 右键,选择打开“网络和internet设置”,选择状态. 选择更改适配器设置. 选择你所连接的WIFI网络. 右键,选择状态. 选择无线属性. 选择安全. 勾选显示字符.
- Windows 查找txt后缀 文件复制
Windows 查找文件 并且复制目录 for /f "delims==" %a in ('dir /b /s F:\F\*.TXT')do copy /-y "%a&q ...
- Linux的快捷键一
- spring基于XML的声明式事务控制
<?xml version="1.0" encoding="utf-8" ?><beans xmlns="http://www.sp ...
- JDK开发环境配置
1. 新建 -> 变量名“JAVA_HOME”, 变量值“C:\Program Files\Java\jdk1.8.0_112”(即JDK的安装路径) 2. 编辑 -> 变量名“Path” ...
- Corn Fields POJ - 3254 (状压dp)
题目链接: Corn Fields POJ - 3254 题目大意:给你一个n*m的矩阵,矩阵的元素只包括0和1,0代表当前的位置不能放置人,1代表当前的位置可以放人,当你决定放人的时候,这个人的四 ...