Oracle_CDC异步Autolog online redo部署示例
一、CDC简介
Oracle CDC (Change Data Capture)变化数据捕获,是一种数据增量处理技术。CDC特性是在Oracle9i数据库中引入的。CDC能够帮助你识别从上次提取之后发生变化的数据。利用CDC,在对源表进行INSERT、UPDATE或DELETE等操作的同时就可以提取数据,并且变化的数据被保存在数据库的变化表中。这样就可以捕获发生变化的数据,然后利用数据库视图以一种可控的方式提供给目标系统。
CDC体系结构基于发布者/订阅者模型。发布者捕捉变化数据并提供给订阅者。订阅者使用从发布者那里获得的变化数据。出于安全原因,发布者和订阅者不应该是相同的数据库用户。通常CDC系统拥有一个发布者和多个订阅者。
CDC几个重要基本概念:
源表(Source Table):业务数据库的需要捕获数据的源表
变化表(Change Table):保存从源表捕获的变化数据(包括各种DML产生的数据)
变化集(Change Set):是保证事务一致性的数据集合。一个变化集对应多个变化表
订阅视图(subscription View):提供给读取变化表数据的视图
订阅窗口(subscription Window):定义了查看变化数据的时间范围.就象一个观察变化数据的滑动窗口。变化数据处理完成后,可以对清除订阅窗口。

注:上图来自官方文档英文版三方翻译软件直接译文。
二、CDC的同步与异步模式
1、同步模式
1.1 Synchronous Change Data Capture Configuration(同步复制)
2、异步模式
2.1 Asynchronous HotLog Configuration(异步在线日志CDC)
2.2 Asynchronous Distributed HotLog Configuration(异步分布式CDC)
2.3 Asynchronous AutoLog Mode
2.3.1 Asynchronous AutoLog Archive Change Data Capture Configuration(归档日志CDC)
2.3.2 Asynchronous Autolog Online Change Data Capture Configuration(异步在线日志复制CDC)
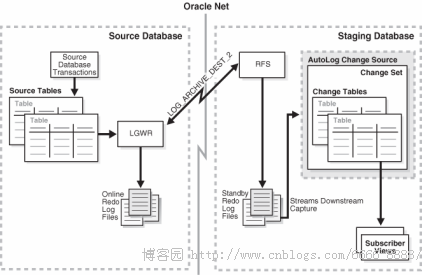
在异步 AutoLog 模式下,数据变化通过redo transport services服务从redo log files 或者 archived log files 进行捕捉。Redo Transport Services自动捕捉日志从源库到中间库。配置这种模式,我们需要设置数据库参数LOG_ARCHIVE_DEST_2,LOG_ARCHIVE_DEST_1 做本地日志的归档目录。源数据库的发布者(Publisher)配置日志传输服务,然后从源数据库拷贝 Redo Log Files 到中间库,在中间库自动地注册 Redo log Files 进行数据同步。AutoLog模式从redo log files捕捉就是异步AutoLog Online模式,如果从Archived Log 捕捉就是异步AutoLog Archive模式。
如果设置了AutoLog Online 模式,日志传输服务会从源库拷贝Redo Log到中间库或者目标库的standby redo log。源库事务提交后,中间库的变化集被填充数据。在中间库,只能有一个AutoLog Online Change Source,也只能包含一个Change set.
如果设置了AutoLog Archive 模式,日志传输服务是拷贝归档日志到中间库,等中间库接受到归档日志后,Change set 才被填充。
上图显示的是 AutoLog Online 配置模式,LGWR 进程拷贝redo data到中间库的Standby Redo Log。LGWR 进程是用Oracle Net网络发送数据给中间库 RFS进程。中间库的RFS进程会写redo data到standby redo log. 变化数据再通过Oracle Stream downstream的方式填充变化数据到change tables中。
其实我们可以发现这个日志传输和应用的模式,和我们的Data Guard配置非常相似,只是多了一步Stream的配置过程。
三、CDC的模式对比
同步CDC模式(Synchronous Mode)通过在源数据上建立trigger的方式来捕获增量数据,因此可以做到实时抽取增量数据,如果在晚上定义作业来完成,对源系统的影响不大。
异步HotLog模式( Asynchronous HotLog Mode )直接从source database的online archive log file中抽取增量数据,由于需要解析日志文件,会有一定的时间延迟。变化表(change table)也必须在源库中生成。该模式由于是在源数据库中解析日志,对源数据库也会造成一定的压力,但是可以选择在非业务高峰期完成。
异步分布式HotLog模式(Asynchronous Distributed HotLog Mode)和异步HotLog模式相比,主要是将多个source database的archive log解析出增量数据,然后传递一个staging database中处理,便于集中式数据管理。Staging Database实际上起到一个接受数据源,然后做数据传递。
异步AutoLog模式(Asynchronous AutoLog Mode)则是直接把source database的online redo log传递到staging database,然后在staging database的online standby redo log执行日志分析,这样的架构对源库性能影响最小、数据传递性能最大。
四、异步Autolog online redo部署示例
其他说明:CDC的生产数据库,我们称为Source端,目标机器,用于做数据仓库的机器,我们称作Stage端。
示例环境:

执行异步AutoLog发布
Step 1 Source Database DBA: Prepare to copy redo log files from the source database.
1.1 source端配置tnsnames.ora
source_cs11g =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.11.128)(PORT = 1521))
)
(CONNECT_DATA =
(SID = cs11g)
)
)
targdb =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.11.129)(PORT = 1521))
)
(CONNECT_DATA =
(SID = csorcl)
)
)
1.2 设置source端初始化参数
alter system set undo_retention=3600;
alter system set log_archive_dest_1 ="location=D:\archivelog mandatory reopen=5";
alter system set log_archive_dest_2 ="service=targdb lgwr async optional noregister reopen=5 valid_for=(online_logfile,primary_role)";
alter system set log_archive_dest_state_1=enable;
alter system set log_archive_dest_state_2=enable;
alter system set log_archive_format='%t_%s_%r.arc' scope=spfile;
alter system set global_names=TRUE scope=BOTH;
alter system set remote_login_passwordfile=shared scope=spfile;
--重启实例
shutdown immediate
Startup;
--注意如果未启用归档模式需要先设置为归档模式
Startup mount;
Alter database archivelog;
Alter database open;
archive log list;
--演示source端创建初始表数据
Conn testus/testmm;
Create table cdctest(id number(10) primary key,name varchar2(30));
Insert into testus.cdctest values(1,'第1行');
Insert into testus.cdctest values(2,'第2行');
Commit;
Step 2 Staging Database DBA: Set the database initialization parameters.
--设置Stage端初始化参数
alter system set global_names=TRUE scope=BOTH;
alter system set undo_retention=3600 scope=BOTH;
Alter system set log_archive_dest_1="location=/archivelog mandatory reopen=5 valid_for=(ONLINE_LOGFILE,primary_role)";
alter system set log_archive_dest_2="location=/archivelog2 mandatory valid_for=(standby_logfile,primary_role)";
alter system set remote_login_passwordfile=shared scope=spfile;
alter system set log_archive_format='%t_%s_%r.arc' scope=spfile;
--重启实例
shutdown immediate
Startup;
--注意如果未启用归档模式需要先设置为归档模式
Startup mount;
Alter database archivelog;
Alter database open;
archive log list;
--注:Stage端/archivelog 存放的是本地库的归档日志,/archivelog2存放的是传过来的source端的归档日志。
Step 3 Source Database DBA: Alter the source database.
--Source端,设置FORCE LOGGING日志模式(可选) 与 最小的数据库级SUPPLEMENTAL LOG(必选)
alter database force logging;
alter database add supplemental log data;
--查询
SQL>SELECT supplemental_log_data_min LOG_MIN, supplemental_log_data_pk LOG_PK, supplemental_log_data_ui LOG_UI, supplemental_log_data_fk LOG_FK, supplemental_log_data_all LOG_ALL, force_logging FORCE_LOG FROM v$database;
LOG_MIN LOG LOG LOG LOG FOR
-------- --- --- --- --- ---
YES NO NO NO NO YES
Step 4 Staging Database DBA: Create Standby Redo Log Files
--stage端创建备用重做日志文件。注意group数要比source 端的log的group数多1.原来有3组,所以要建4组standby redo log.
ALTER DATABASE ADD STANDBY LOGFILE GROUP 4 ('/u01/app/oracle/oradata/cs11g/slog04.log') SIZE 50M;
ALTER DATABASE ADD STANDBY LOGFILE GROUP 5 ('/u01/app/oracle/oradata/cs11g/slog05.log') SIZE 50M;
ALTER DATABASE ADD STANDBY LOGFILE GROUP 6 ('/u01/app/oracle/oradata/cs11g/slog06.log') SIZE 50M;
ALTER DATABASE ADD STANDBY LOGFILE GROUP 7 ('/u01/app/oracle/oradata/cs11g/slog07.log') SIZE 50M;
--查询
SQL>SELECT group#, bytes, status FROM v$standby_log;
---------- ---------- ----------
4 52428800 UNASSIGNED
5 52428800 UNASSIGNED
6 52428800 UNASSIGNED
7 52428800 UNASSIGNED
Step 5 Staging Database DBA: Create and grant privileges to the publisher.
--Stage端,创建发布者并授权
--创建stream adminstrator(在stage 端执行),从原理图中,我们看出,当log(无论是online还是archivelog)到stage 端之后,由downstream capture进程进行挖掘。因此我们要在stage 端先创建stream administrator.downstream capture用来产生stage 端的change source(注意,除了异步HotLog模式,其他模式的change source都在stage 端),stage change set,和stage change table。
create tablespace ts_cdcpub datafile '/u01/app/oracle/oradata/cs11g/ts_cdcpub01.dbf' size 50M;
CREATE USER cdcpub IDENTIFIED BY cdcpub DEFAULT TABLESPACE ts_cdcpub QUOTA UNLIMITED ON SYSTEM QUOTA UNLIMITED ON SYSAUX;
GRANT CREATE SESSION TO cdcpub;
GRANT CREATE TABLE TO cdcpub;
GRANT CREATE TABLESPACE TO cdcpub;
GRANT UNLIMITED TABLESPACE TO cdcpub;
GRANT SELECT_CATALOG_ROLE TO cdcpub;
GRANT EXECUTE_CATALOG_ROLE TO cdcpub;
GRANT DBA TO cdcpub;
GRANT CREATE SEQUENCE TO cdcpub;
GRANT EXECUTE on DBMS_CDC_PUBLISH TO cdcpub;
EXECUTE DBMS_STREAMS_AUTH.GRANT_ADMIN_PRIVILEGE(grantee => 'cdcpub');
Step 6 Source Database DBA: Build the LogMiner data dictionary.
--source端生成LogMiner数据字典,获取数据字典构建的SCN值,后续会用到此scn号。注意要先执行了第6步才能执行第7步。
SET SERVEROUTPUT ON
VARIABLE f_scn NUMBER;
BEGIN
:f_scn := 0;
DBMS_CAPTURE_ADM.BUILD(:f_scn);
DBMS_OUTPUT.PUT_LINE('The first_scn value is ' || :f_scn);
END;
/
The first_scn value is 1392305
Step 7 Source Database DBA: Prepare the source tables.
--source端准备源表
注意在source端的每一个source table都必须准备实例化,如果不准备实例化,在stage端的capture会出现问题,无法capture source table的变化。
SQL> Desc testus.cdctest;
名称 是否为空? 类型
----------------------------------------- -------- ----------------------------
ID NOT NULL NUMBER(10)
NAME VARCHAR2(30)
--查询
SQL> SELECT table_name, scn, supplemental_log_data_pk PK, supplemental_log_data_ui UI, supplemental_log_data_fk FK, supplemental_log_data_all "ALL" FROM dba_capture_prepared_tables;
未选定行
--准备source tables
exec dbms_capture_adm.prepare_table_instantiation('testus.cdctest');
--查询
SQL>SELECT table_name, scn, supplemental_log_data_pk PK, supplemental_log_data_ui UI, supplemental_log_data_fk FK, supplemental_log_data_all "ALL" FROM dba_capture_prepared_tables;
TABLE_NAME SCN PK UI FK ALL
------------------------------ ---------- -------- -------- -------- --------
CDCTEST 1393349 IMPLICIT IMPLICIT IMPLICIT NO
Step 8 Source Database DBA: Get the global name of the source database.
--source端,获取source端的全局名称,用于在Stage端创建AutoLog改变源
SQL> SELECT GLOBAL_NAME FROM GLOBAL_NAME;
GLOBAL_NAME
--------------------------------------------------
CS11G
Step 9 Staging Database Publisher: Identify each change source database and create the change sources.
--Stage端,识别改变源数据库并创建改变源
SQL>conn cdcpub/cdcpub;
BEGIN
DBMS_CDC_PUBLISH.CREATE_AUTOLOG_CHANGE_SOURCE(
change_source_name => 'CHICAGO',
description => 'test source',
source_database => 'CS11G',
first_scn => 1392305,
online_log =>'y');
END;
/
Step 10 Staging Database Publisher: Create change sets.
--Stage端,创建变更集(Change Set).注意当CDC创建了change set的时候,stream的capture和apply进程也被同时创建了,但是仅仅是创建,还未启动。
--以下示例显示如何创建一个名为CHICAGO_DAILY从当前开始捕获更改的更改集,并继续无限地捕获更改数据。(如果在将来的某个时间,发布者决定停止捕获此更改集的更改数据,应该禁用更改集然后删除它。)
SQL>conn cdcpub/cdcpub;
BEGIN
DBMS_CDC_PUBLISH.CREATE_CHANGE_SET(
change_set_name => 'CHICAGO_DAILY',
description => 'change set for testus.CDCTEST info',
change_source_name => 'CHICAGO',
stop_on_ddl => 'y');
END;
/
Step 11 Staging Database Publisher: Create the change tables.
--Stage端,创建变更表(Change Table).change table是publisher做的最后一个事情,期间可以过滤某些字段,或者某些表。
--此示例创建一个cdctest_ct在更改集中命名的更改表CHICAGO_DAILY。该column_type_list参数标识更改表捕获的列。capture_values示例中的设置表示对于更新操作,更改数据将为每个更改的行包含两个单独的行:一行将包含更新发生前的行值,另一行将包含更新发生后的行值。
SQL>conn cdcpub/cdcpub
BEGIN
DBMS_CDC_PUBLISH.CREATE_CHANGE_TABLE(
owner => 'cdcpub',
change_table_name => 'cdctest_ct',
change_set_name => 'CHICAGO_DAILY',
source_schema => 'testus',
source_table => 'cdctest',
column_type_list => 'id NUMBER(10), NAME VARCHAR2(30)',
capture_values => 'both',
rs_id => 'y',
row_id => 'n',
user_id => 'n',
timestamp => 'n',
object_id => 'n',
source_colmap => 'n',
target_colmap => 'y',
options_string => 'TABLESPACE ts_cdcpub');
END;
/
--SYS用户查询:
SQL>SELECT change_set_name, source_schema_name, source_table_name FROM CDC_CHANGE_TABLES$;
CHANGE_SET_NAME SOURCE_SCHEMA_NAME SOURCE_TABLE_NAME
CHICAGO_DAILY testus CDCTEST
Step 12 Staging Database Publisher: Enable the change set.
--Stage端,激活变更集(Change Set).注意当change set is enabled,Streams capture进程和apply进程将启动。(这时oracle的流捕获和应用进程启动)
SQL>SELECT set_name, change_source_name, capture_enabled FROM cdc_change_sets$;
SET_NAME CHANGE_SOURCE_NAME C
------------------------------ ------------------------------ --------
SYNC_SET SYNC_SOURCE Y
CHICAGO_DAILY CHICAGO N
--启用变更集
SQL>conn cdcpub/cdcpub;
BEGIN
DBMS_CDC_PUBLISH.ALTER_CHANGE_SET(
change_set_name => 'CHICAGO_DAILY',
enable_capture => 'y');
END;
/
--查询
SQL>SELECT set_name, change_source_name, capture_enabled FROM cdc_change_sets$;
SET_NAME CHANGE_SOURCE_NAME C
------------------------------ ------------------------------ -----
SYNC_SET SYNC_SOURCE Y
CHICAGO_DAILY CHICAGO Y
Step 13 Source Database DBA: Switch the redo log files at the source database.
--source端,切换重做日志,oracle开始捕获数据。
alter system switch logfile;
Step 14 Staging Database Publisher: Grant access to subscribers.
--Stage端,创建订阅者并赋权。如果没有此步骤,订阅者将无法访问任何变更数据。
create user subs1 identified by subs1 default tablespace users;
grant connect,resource to subs1;
grant select on cdcpub.cdctest_ct to subs1;
订阅变更数据
Step 1 Find the source tables for which the subscriber has access privileges.
--查找订阅者能够访问的源表
SQL>conn cdcpub/cdcpub;
SQL>SELECT * FROM ALL_SOURCE_TABLES;
SOURCE_SCHEMA_NAME SOURCE_TABLE_NAME
------------------------------ ------------------------------
testus CDCTEST
Step 2 Find the change set names and columns for which the subscriber has access privileges.
--查找订阅者能够访问改变集名称与列信息
SQL>conn cdcpub/cdcpub;
SQL>SELECT UNIQUE CHANGE_SET_NAME, COLUMN_NAME, PUB_ID FROM ALL_PUBLISHED_COLUMNS WHERE SOURCE_SCHEMA_NAME ='testus' AND SOURCE_TABLE_NAME = 'CDCTEST';
CHANGE_SET_NAME COLUMN_NAME PUB_ID
------------------------------ ------------------------------ --------------------------
CHICAGO_DAILY NAME 87562
CHICAGO_DAILY ID 87562
Step 3 Create a subscription.
--创建订阅集(subscription)
conn subs1/subs1;
BEGIN
DBMS_CDC_subsCRIBE.CREATE_subsCRIPTION(
change_set_name => 'CHICAGO_DAILY',
description => 'Change data for CDCTEST',
subscription_name => 'CDCTEST_SUB');
END;
/
Step 4 Subscribe to a source table and the columns in the source table.
--订阅表(订阅源表及源表中的相关字段)
conn subs1/subs1;
BEGIN
DBMS_CDC_subsCRIBE.subsCRIBE(
subscription_name => 'CDCTEST_SUB',
source_schema => 'testus',
source_table => 'CDCTEST',
column_list => 'ID , NAME',
subscriber_view => 'CDCTEST_VIEW');
END;
/
--注意:如果setp 2查出的pub_id有多个,需要定义多个订阅表


Step 5 Activate the subscription.
--激活订阅.无论是订阅一个还是多个源表,订阅者只需要调用ACTIVATE_SUBSCRIPTION一次该过程。
conn subs1/subs1;
BEGIN
DBMS_CDC_subsCRIBE.ACTIVATE_subsCRIPTION(
subscription_name => 'CDCTEST_SUB');
END;
/
Step 6 Get the next set of change data.
--获取下一组变更数据
conn subs1/subs1;
BEGIN
DBMS_CDC_SUBSCRIBE.EXTEND_WINDOW(
subscription_name => 'CDCTEST_SUB');
END;
/
Step 7 Read and query the contents of the subscriber views.
--验证订阅者使用SELECT订阅者视图上的SQL 语句来查询更改数据
--source端
Insert into testus.cdctest values(4,'第4行');
Commit;
--注意执行后要执行第6步
--Stage端,获取变更数据
Select * from subs1.cdctest_view;

--所有变化的数据查询
Select * from CDCPUB.CDCTEST_CT;

Step 8 Indicate that the current set of change data is no longer needed.
--清理不要的数据集
BEGIN
DBMS_CDC_SUBSCRIBE.PURGE_WINDOW(
subscription_name => 'CDCTEST_SUB');
END;
/
Step 9 Repeat Steps 6 through 8.
--只要订阅者对其他变更数据感兴趣,订阅者就重复步骤6到8。,
Step 10 End the subscription.
--结束订阅
BEGIN
DBMS_CDC_SUBSCRIBE.DROP_SUBSCRIPTION(
subscription_name => 'CDCTEST_SUB');
END;
/
六、常见问题
1、清理change tables
当任何订阅者不再需要change tables时,通过自动删除更改表中的数据来处理所有存储管理。Change Data Capture会在作业队列中启动一个作业,该作业每24小时运行一次,以处理清除。此作业可能会出现许多问题(例如,如果删除或更改了计划),则此自动处理取决于作业队列进程正在运行以及存在的Change Data Capture作业。此外,在逻辑备用环境中,不提交清除作业。
默认dba_scheduler_jobs名称:CDC$_DEFAULT_PURGE_JOB
2、查看捕获进程与应用进程的状态与错误信息
SELECT CAPTURE_NAME,status, CAPTURE_TYPE from dba_capture;
select apply_name,status from dba_apply;
select * from DBA_APPLY_ERROR
3、创建变更集(Change Set)时报错
错误:
ERROR at line 1:
ORA-26764: invalid parameter "DOWNSTREAM_REAL_TIME_MINE" for local capture
"CDC$C_EMP_DEPT_SET"
ORA-06512: at "SYS.DBMS_LOGREP_UTIL", line 69
ORA-06512: at "SYS.DBMS_CAPTURE_ADM", line 181
ORA-06512: at line 1
ORA-06512: at "SYS.DBMS_CDC_PUBLISH", line 705
ORA-06512: at line 2
处理:source和target 端实例名一致导致,使用nid更新Stage端实例名即可。
4、磁盘空间不足导致的错误
发布者可以查看警报日志的内容,以确定为给定的更改集返回哪个错误以及哪个SCN未被处理。例如,警报日志可能包含以下行(其中LCR指的是逻辑更改记录):
Change Data Capture has encountered error number: 1688 for change set:
CHICAGO_DAILY
Change Data Capture did not process LCR with scn 219337
发布者可以通过查询DBA_APPLY_ERROR错误消息文本的视图来确定与警报日志中指定的错误号相关联的消息,其中视图APPLY_NAME中的DBA_APPLY_ERROR视图等于APPLY_NAME警报日志中指定的更改集。例如:
SQL> SELECT ERROR_MESSAGE FROM DBA_APPLY_ERROR
WHERE APPLY_NAME =
(SELECT APPLY_NAME FROM ALL_CHANGE_SETS WHERE SET_NAME ='CHICAGO_DAILY');
ERROR_MESSAGE
--------------------------------------------------------------------------------
ORA-01688: unable to extend table LOGADMIN.CT1 partition P1 by 32 in tablespace
TS_CHICAGO_DAILY
在采取措施修复导致错误的问题后,发布者可以尝试从错误中恢复。例如,发布者可以尝试CHICAGO_DAILY在出现以下调用的错误后恢复更改集:
BEGIN
DBMS_CDC_PUBLISH.ALTER_CHANGE_SET(
change_set_name => 'CHICAGO_DAILY',
recover_after_error => 'y');
END;
/
如果恢复未成功,则会返回错误,发布者可以采取进一步操作来尝试解决问题。发布者可以根据需要多次重试恢复过程以解决问题。
注意:恢复成功后,发布者必须记住启用更改集。启用后,更改数据捕获操作将继续执行发生错误的逻辑更改记录(LCR)。没有变更数据会丢失。
5、由于DDL语句而导致的错误
假设TRUNCATE TABLE针对PRODUCTS源表发出SQL 语句并将stop_on_ddl参数设置为'Y',则尝试启用更改集时会返回以下错误:
ERROR at line 1:
ORA-31468: cannot process DDL change record
ORA-06512: at "SYS.DBMS_CDC_PUBLISH", line 79
ORA-06512: at line 2
警报日志将包含类似于以下内容的行:
Change Data Capture received DDL for change set PRODUCTS_SET
Change Data Capture received DDL and stopping: truncate table products
Change Data Capture did not process LCR with scn 219777
Streams Apply Server P001 pid=19 OS id=11730 stopped
Streams Apply Reader P000 pid=17 OS id=11726 stopped
Streams Apply Server P000 pid=17 OS id=11726 stopped
Streams Apply Server P001 pid=19 OS id=11730 stopped
Streams AP01 with pid=15, OS id=11722 stopped
由于该TRUNCATE TABLE语句会从表中删除所有行,因此发布者希望在采取操作重新启用更改数据捕获处理之前通知订阅者。他或她可能会建议订阅者清除和扩展他们的订阅窗口。然后,发布者可以通过更改更改集并指定remove_ddl => 'Y'参数以及参数来尝试恢复更改数据捕获处理recover_after_error=> 'Y',如下所示:
BEGIN
DBMS_CDC_PUBLISH.ALTER_CHANGE_SET(
change_set_name => 'CHICAGO_DAILY',
recover_after_error => 'y',
remove_ddl => 'y');
END;
/
此过程完成后,警报日志将包含类似于以下内容的行:
change Data Capture received DDL and ignoring: truncate table products
The scn for the truncate statement is 202998
现在,发布者必须启用更改集。TRUNCATE TABLE语句之后发生的所有更改数据都将反映在更改表中。没有变更数据会丢失。
参考文档:
1、《Oracle系统电子书-Oracle 变化数据捕获》
2、 Oracle 11g CDC官网文档: https://docs.oracle.com/cd/E11882_01/server.112/e25554/cdc.htm#DWHSG016
3、 其他参考:网络文章,内容及链接较多,不一一贴上,感谢前辈们的整理。另建议英语好的看官可直接参考官网文档,官方文档是超级详细的。
Oracle_CDC异步Autolog online redo部署示例的更多相关文章
- Oracle CDC简介及异步在线日志CDC部署示例
摘要 最近由于工作需要,花时间研究了一下Oracle CDC功能和LogMiner工具,希望能找到一种稳定.高效的技术来实现Oracle增量数据抽取功能.以下是个人的部分学习总结和部署实践. 1. O ...
- 从K8S部署示例进一步理解容器化编排技术的强大
概念 Kubernetes,也称为K8s,生产级别的容器编排系统,是一个用于自动化部署.扩展和管理容器化应用程序的开源系统.K8s是一个go语言开发,docker也是go语言开发,可见go语言的是未来 ...
- 一个简单的Kubernetes应用部署示例
说明 我们通过一个示例来演示一下kubernetes部署应用的基本配置. 这个示例相对比较简单,就是一个tomcat应用加上一个mysql数据库 在tomcat里运行一个简单的webappp,这个ap ...
- django-celery定时任务以及异步任务and服务器部署并且运行全部过程
Celery 应用Celery之前,我想大家都已经了解了,什么是Celery,Celery可以做什么,等等一些关于Celery的问题,在这里我就不一一解释了. 应用之前,要确保环境中添加了Celery ...
- SpringCloudAlibaba微服务docker容器打包和部署示例实战
概述 我们使用前面<SpringCloudAlibaba注册中心与配置中心之利器Nacos实战与源码分析(中)>的两个微服务示例,分别是库存微服务和订单微服务,基于Nacos注册中心和配置 ...
- python fabric实现远程操作和部署示例
https://www.jb51.net/article/48434.htm 近期接手越来越多的东西,发布和运维的工作相当机械,加上频率还蛮高,导致时间浪费还是优点多.修复bug什么的,测试,提交版本 ...
- 160328、rabbitMQ集群部署示例
环境:Centos 6.5 x86_64MQ网址:http://www.rabbitmq.com/SERVER101\SERVER102 SERVER103 一.单节点安装 #yum install ...
- ssl 在nginx上的部署示例
server { listen 80; listen 443 ssl; server_name [DOMAIN]; ssl on; ssl_certificate /work/ss ...
- 和我一起,重零开始学习Ant Design Pro开发解决方案(二)部署示例项目
随机推荐
- CSS3动画效果transition
1.transition的浏览器支持情况 IE10+支持,IE6\7\8\9都不支持!目前,其他浏览器最新版本都支持,不需要再加前缀 -webkit- 之类的了 2. 还是一步一步说说怎么用trans ...
- Flutter绘制波浪
以上动画是仿照 里面的物理动画还未仿写 代码见 https://github.com/dnoyeb/syk_flutter
- vue上传图片 base64+canvas压缩图片
这是先将图片 base64转码 在拿canvas压缩的
- ABP拦截器之AuthorizationInterceptor
在整体介绍这个部分之前,如果对ABP中的权限控制还没有一个很明确的认知,请先阅读这篇文章,然后在读下面的内容. AuthorizationInterceptor看这个名字我们就知道这个拦截器拦截用户一 ...
- 2019春招面试高频题(Java版),持续更新(答案来自互联网)
第一模块--并发与多线程 Java多线程方法: 实现Runnable接口, 继承thread类, 使用线程池 操作系统层面的进程与线程(对JAVA多线程和高并发有了解吗?) 计算机资源=存储资源+计算 ...
- react native输入框定位在底部(虚拟键盘弹起)
1.通过Keyboard获取键盘高度,改变定位的bottom 缺点:虚拟键盘完全弹起时,才会获取到键盘高度,定位稍有延迟,而且键盘收起时,定位会出现悬空状态,然后再回到底部 import React, ...
- Microsoft Connect 2018 Summary
https://www.microsoft.com/en-us/connectevent/
- poj-3177(无向图缩点)
题意:给你n个点,m条边的无向联通图,问你最少增加几条边,使得这个图每对点至少有两条路径 解题思路:考虑每个环内的点必定有>=2条路径,所以先把这个无向图中的环去掉,用并查集缩环,然后剩下的图一 ...
- JDK源代码学习-基础类
一.概述 1.Java,是一套语言规范,例如规定了变量如何定义.控制语句如何写等,提供基本的语法规范.JDK是java自带的一套调用组件,是对基本java语法规范的进一步封装,jdk中都是使用java ...
- 【linux】工作中linux系统常用命令操作整理
1.Linux如何查看端口 使用lsof(list open files)命令,lsof -i:端口号 用于查看某一端口的占用情况,比如查看8000端口使用情况,lsof -i:8000. 或者使用n ...