单机安装EFK(一)
环境信息

前话
去年下半年邻居介绍了一当兵的对象,当时是用生命拒绝的,然后过年回去居然鬼使神差的在一起了?过完年来,已经莫名失联十多天了,毕竟刚开始传说中的热恋就分开,心里难受!!!每天猜测这人是干嘛去了,患得患失,对于我这种一分钟不回复我消息我都觉得对方在出轨(这是被劈腿后遗症,越来越严重)。。。 这跟这篇博文有什么关系呢,没关系!
一、安装Elasticsearch
1、关闭防火墙
yum -y install firewalld
yum -y install iptables-services systemctl stop firewalld
systemctl stop iptables systemctl disable firewalld.service
systemctl disable iptables.service sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
setenforce
wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.tar.gz
tar -zxvf jdk-8u131-linux-x64.tar.gz -C /usr/local
mv /usr/local/jdk1..0_131 /usr/local/java
2)vim /etc/profile
export JAVA_HOME=/usr/local/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:{JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source /etc/profile
[root@rilo ~]# echo $PATH
/usr/local/java/bin:/usr/local/java/jre/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
[root@ip---- ~]# java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) -Bit Server VM (build 25.131-b11, mixed mode)
curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.6.0.tar.gz tar -xvf elasticsearch-6.6..tar.gz cd elasticsearch-6.6./bin ./elasticsearch
useradd ela
chown -R ela.ela elasticsearch-6.6.
nohup ./elasticsearch &
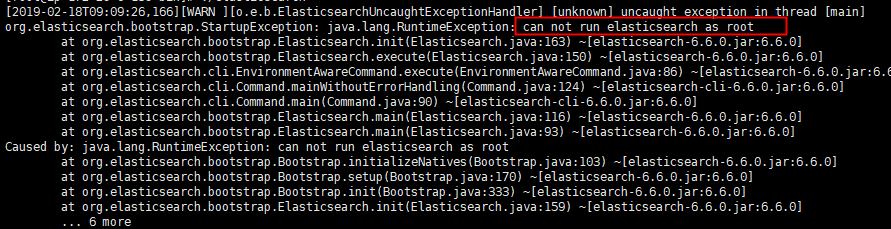

vm.max_map_count =
sysctl -p
network.host: 0.0.0.0
重启服务后,访问:http://13.250.58.192:9200/
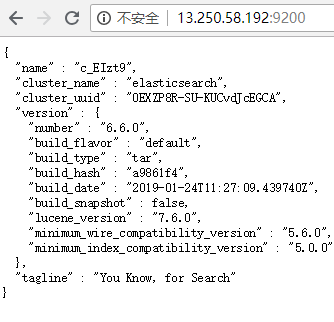
二、安装Kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.6.0-linux-x86_64.tar.gz
tar -zxvf kibana-6.6.-linux-x86_64.tar.gz
cd kibana-6.6.-linux-x86_64
nohup ./bin/kibana &
3、查看Kibana进程
[root@ip---- ~]# ps -ef |grep node
root : pts/ :: ./../node/bin/node --no-warnings ./../src/cli
root : pts/ :: grep --color=auto node
[root@ip---- ~]# netstat -anltp |grep
tcp 127.0.0.1: 0.0.0.0:* LISTEN /./../node/bin
server.host: "0.0.0.0"
三、安装FileBeats
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.6.0-linux-x86_64.tar.gz
tar xzvf filebeat-6.6.-linux-x86_64.tar.gz
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
setup.kibana:
host: "localhost:5601"
output.elasticsearch:
hosts: ["localhost:9200"]
nohup ./filebeat &
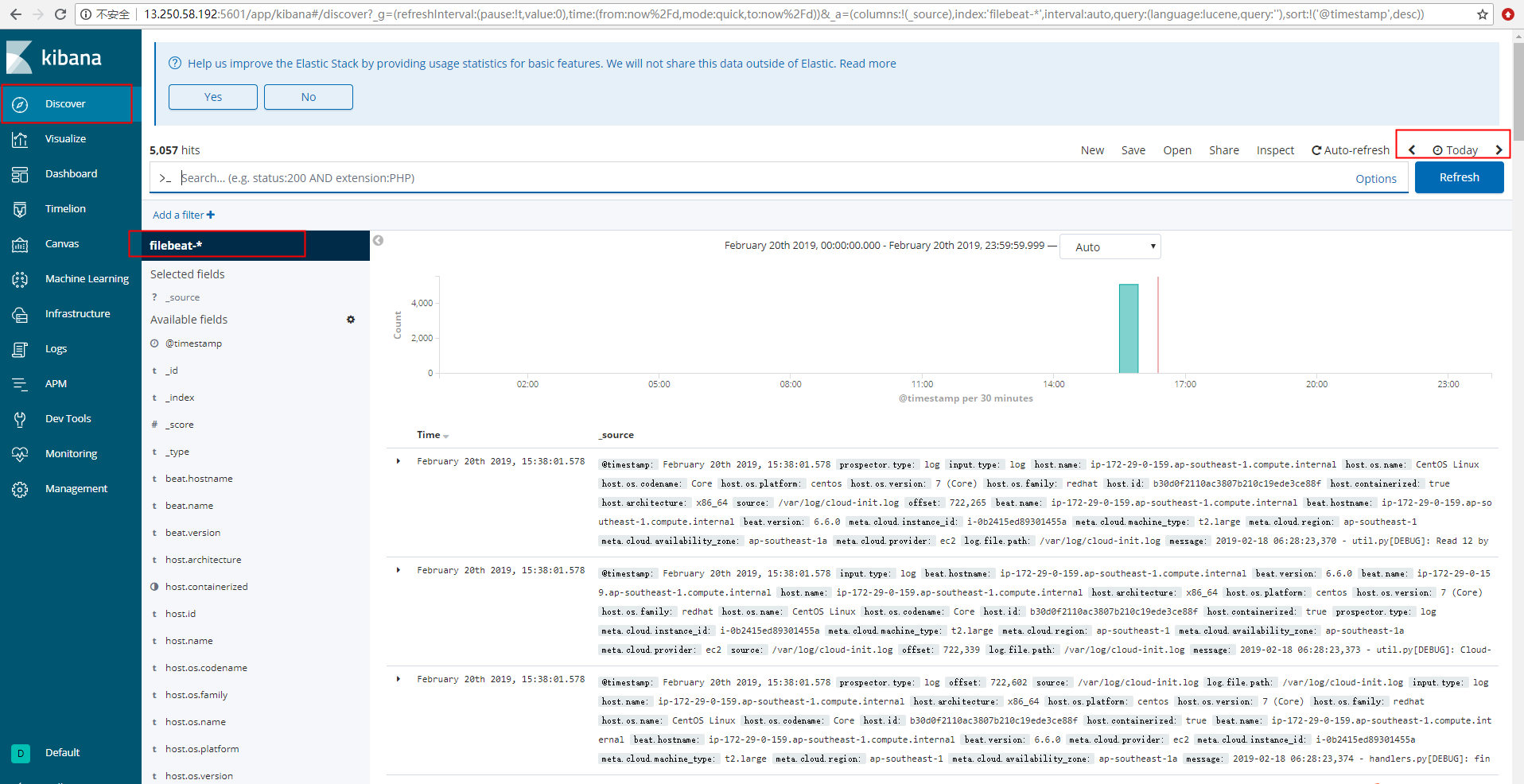
四、查看
单机安装EFK(一)的更多相关文章
- (原) 1.1 Zookeeper单机安装
本文为原创文章,转载请注明出处,谢谢 zookeeper 单机安装配置 1.安装前准备 linux系统(此文环境为Centos6.5) Zookeeper安装包,官网https://zookeeper ...
- Linux下Kafka单机安装配置方法(图文)
Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计.这个独特的设计是什么样的呢 介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了 ...
- Ubuntu 下 Neo4j单机安装和集群环境安装
1. Neo4j简介 Neo4j是一个用Java实现的.高性能的.NoSQL图形数据库.Neo4j 使用图(graph)相关的概念来描述数据模型,通过图中的节点和节点的关系来建模.Neo4j完全兼容A ...
- Hbase单机安装部署
Hbase单机安装部署 http://blogxinxiucan.sh1.newtouch.com/2017/07/27/Hbase单机安装部署/ 下载Hbase Hbase官网下载地址 http:/ ...
- 单机安装Hadoop
单机安装hadoop ------------------------------------------------------------------ 操作系统:centos7 64 位 hado ...
- cenots7单机安装Kubernetes
关于什么是Kubernetes请看另一篇内容:http://www.cnblogs.com/boshen-hzb/p/6482734.html 一.环境搭建 master安装的组件有: docker ...
- Linux下Kafka单机安装配置方法
Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计.这个独特的设计是什么样的呢? 首先让我们看几个基本的消息系统术语: •Kafka将消息以topi ...
- ETCD 单机安装
由于测试的需要,有时需要搭建一个单机版的etcd 环境,为了方便以后搭建查看,现在对单机部署进行记录. 一.部署单机etcd 下载 指定版本的etcd下载地址 ftp://ftp.pbone.net/ ...
- ArcGIS 10.1 for Server安装教程系列—— Linux下的单机安装
http://www.oschina.net/question/565065_81231 因为Linux具有稳定,功能强大等特性,因此常常被用来做为企业内部的服务器,我们的很多用户也是将Ar ...
随机推荐
- jsp页面传中文到后台乱码怎么办?
一般从前台传值到后腰如果传的值是中文的话,又不用post传值方式,到后台显示会显示成乱码的形式.所以以下方法亲测有效防止乱码. 前台jsp页面: var taskTitle = $('#taskTit ...
- Jsの练习-数组其他常用方法 -map() ,filter() ,every() ,some()
map() :映射,对数组中的每一项运行给定函数,返回每次函数调用结果组成的函数. <!DOCTYPE html> <html lang="en"> < ...
- ubuntu Error fetching https://gems.ruby-china.org/: Errno::ECONNREFUSED: Connection refused
排除网络原因的前提下 是 权限问题 用 sudo 来 执行命令即可 sudo gem sources -a https://gems.ruby-china.org/
- 高精度加法——经典题 洛谷p1601
题目背景 无 题目描述 高精度加法,x相当于a+b problem,[b][color=red]不用考虑负数[/color][/b] 输入输出格式 输入格式: 分两行输入a,b<=10^500 ...
- java面向对象编程(八)--抽象类、接口
1.抽象类 1.1抽象类概念 当父类的一些方法不能确定时,可以用abstract关键字来修饰该方法[抽象方法],用abstract来修饰该类[抽象类]. //抽象类的必要性[Demo124.java] ...
- 手机端flex、字体设置、快速点击
;(function flexible (window, document) { var docEl = document.documentElement ♥1 var dpr = window.de ...
- shell 删除颜色代码
sed -r "s/\x1B\[([0-9]{1,2}(;[0-9]{1,2})?)?[m|K]//g"
- Js/Session和Cookies的区别
1.cookies数据存放在客户的浏览器上面,session放在服务器上面.2.cookies不安全,别人可以分析浏览器的数据进行cookies的欺骗,考虑到安全性,应该使用cookie3.sessi ...
- 在IE浏览器中url传参长度问题
1.在这之前我一直以为,应该说是并没有去思考过,url地址传参的长度限制问题:知道在项目材料价格系统中遇到之后,才对这个问题进行了具体的探索.IE中最大的长度限制为2084个,用于get传递数据的长度 ...
- Struts功能详解——ActionMapping对象
Struts功能详解——ActionMapping对象 ActionMapping描述了struts中用户请求路径和Action的映射关系,在struts中每个ActionMapping都是通过pat ...