利用python实现两个文件夹的同步
其实无论windows还是Linux,简单地去实现两个两个文件夹的同步只需系统自带的复制命令加参数就可以了。
- WINDOWS :
xcopy 源文件夹\* 目标文件夹 /s /e /y
- Linux :
cp -r 源文件夹/* 目标文件夹
这里使用python来实现这些基本功能,并增加一些去重之类的增强功能。
1、复制源文件夹中文件至目标文件夹
要想同步两个文件夹中的数据,基本思路首先需要遍历源文件夹中的信息,将源文件夹中的文件复制到目标文件夹。
遍历文件夹采用os中的listdir函数就可以了。
import os path_s = 'F:\\test\\s'
path_t = 'F:\\test\\t' for filename in os.listdir(path_s):
filename_s = path_s+os.sep+filename
print '[*] Source :',filename_s
filename_t = path_t+os.sep+filename
print '[*] Target :',filename_t
with open(filename_s,'rb') as f_s:
with open(filename_t,'wb') as f_t:
f_t.write(f_s.read())
但是很明显这里没有考虑源文件夹中还会存在文件夹甚至多重文件夹的情况。
2、源文件夹中存在多重文件夹
一个简单的思路就是:在遍历源文件夹内的文件时,先判定当前文件这是文件还是文件夹。如果当前文件是文件夹的话,开始遍历此文件夹内的文件,如果里面还有文件夹,遍历这个文件夹,依次类推。利用递归的方法,代码如下:
import os path_s = 'F:\\test\\s'
path_t = 'F:\\test\\t' def copy_file(paths,patht):
for filename in os.listdir(paths):
filename_s = paths+os.sep+filename
filename_t = patht+os.sep+filename
if os.path.isdir(filename_s):
if not os.path.exists(filename_t):
os.mkdir(filename_t) #在目标文件夹中创建对应的文件夹
copy_file(filename_s,filename_t) # 递归
else:
print '[*] Source :',filename_s print '[*] Target :',filename_t
with open(filename_s,'rb') as f_s:
with open(filename_t,'wb') as f_t:
f_t.write(f_s.read()) copy_file(path_s,path_t)
目前,简单的文件夹复制功能已经实现了。
3、目标文件夹中已有文件不再复制
一个简单的方法就是在目标文件夹中复制文件之前先利用函数“os.path.exists”判定这个文件是否存在。
import os path_s = 'F:\\test\\s'
path_t = 'F:\\test\\t' def copy_file(paths,patht):
for filename in os.listdir(paths):
filename_s = paths+os.sep+filename
filename_t = patht+os.sep+filename
if os.path.isdir(filename_s):
if not os.path.exists(filename_t):
os.mkdir(filename_t)
copy_file(filename_s,filename_t)
else:
if os.path.exists(filename_t):
print '[*] "%s" already exists! ' % filename_t
else:
print '[*] Source :',filename_s print '[*] Target :',filename_t
with open(filename_s,'rb') as f_s:
with open(filename_t,'wb') as f_t:
f_t.write(f_s.read()) copy_file(path_s,path_t)
这个办法避免了一部分已有文件的重复复制操作,减少了部分不必要的读写操作,但是却无法消除内容相同但名称、路径不同的重复文件。
4、利用MD5判定重复文件
目前判定两个文件是否相同,除了按字节逐个对比这个笨方法外,简单常用的办法就是利用MD5和CRC校验,或是按一定规律挑取文件的指定位置的数据块就行对比。
这次利用文件的MD5值,将目标文件夹中已有文件的MD5值保存到列表或字典中,每在源文件夹中读取一个文件就判定该文件的MD5值是否已经存在于MD5列表,没有的话再进行复制操作,并将该文件的MD5值写入列表。
import os
import hashlib path_s = 'F:\\test\\s'
path_t = 'F:\\test\\t'
list_file = {} def create_file_list(path):
for name in os.listdir(path):
filename = path+os.sep+name
if os.path.isdir(filename):
create_file_list(filename)
else:
with open(filename,'rb') as f:
md5 = hashlib.md5(f.read()).hexdigest()
if md5 not in list_file:
list_file[md5] = 1 def copy_file(paths,patht):
for filename in os.listdir(paths):
filename_s = paths+os.sep+filename
filename_t = patht+os.sep+filename
if os.path.isdir(filename_s):
if not os.path.exists(filename_t):
os.mkdir(filename_t)
copy_file(filename_s,filename_t)
else:
if os.path.exists(filename_t):
print '[*] "%s" already exists! ' % filename_t
else:
with open(filename_s,'rb') as f_s:
data = f_s.read()
file_md5 = hashlib.md5(data).hexdigest()
if file_md5 not in list_file:
list_file[file_md5] = 1
print '[*] Source :',filename_s
print '[*] Target :',filename_t
with open(filename_t,'wb') as f_t:
f_t.write(data)
else:
print '[*] "%s"\'s MD5 already exists! ' % filename_t create_file_list(path_t)
copy_file(path_s,path_t)
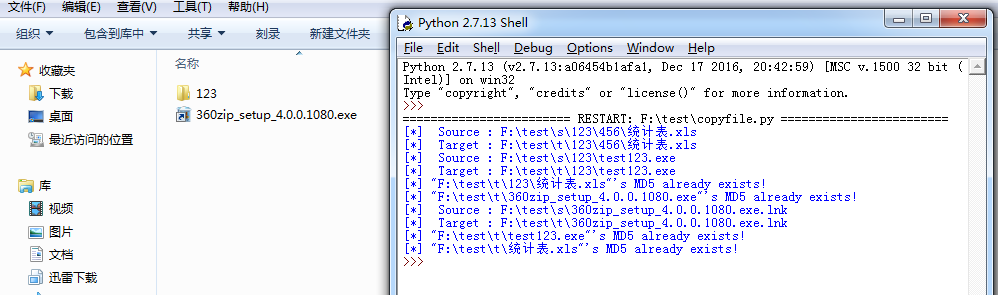
如下图,运行后内容相同的几个文件,只有第一次读取到的时候才写入目标文件夹,其他路径下的文件并没有复制到目标文件夹。
利用python实现两个文件夹的同步的更多相关文章
- 基于Python——实现两个文件夹中的文件拷贝
[背景]当复制一个文件夹中的某文件到另一个文件夹中时是一件很容易的事情,可是如果存在很多文件夹中的文件需要一一拷贝,就会变的很繁琐,稍有不慎就会遗漏,今天就用Python来解决这个问题—— [代码实现 ...
- 利用python合并两个文件
1格式如下 在做利用zabbix的api来批量添加主机的时候,需要处理ip和hostname,在借用别人写的py程序的基础上,自己有改装了以下脚本,为自己使用.需要时ip和hostname为一个统一格 ...
- 利用Python批量重命名文件夹下文件
#!/usr/bin/python # -*- coding: UTF-8 -*- # -*- coding:utf8 -*- import os from string import digits ...
- 使用python实现两个文件夹里文件的对比(包含内容的对比)
#-*-coding:utf-8-*- #=============================================================================== ...
- Python批量复制迁移文件夹
前言 Python可以利用shutil库进行对文件夹,文件的迁移.而在本次的实践当中,难点在于目标文件夹的名称和数据源文件夹的名称,需要利用 工作单位提供的中间数据去进行对比连接起来. 例如:目标源的 ...
- Path,Files巩固,题目:从键盘接收两个文件夹路径,把其中一个文件夹中(包含内容)拷贝到另一个文件夹中
这个题目用传统的File,InputStream可以做,但是如果用Files,Path类做,虽然思路上会困难一些,但是代码简洁了很多,以下是代码: import java.io.IOException ...
- 利用 Python 进行批量更改文件后缀
利用 Python 进行批量更改文件后缀 代码 import os files = os.listdir('.') for file_name in files: portion = os.path. ...
- Linux下对比两个文件夹的方法
最近拿到一份源代码,要命的是这份源代码是浅克隆模式的git包,所以无法完整显示里面的修改的内容. 今天花了一点点时间,找了一个在Linux对比两个文件夹的方法. 其实方法很简单,用meld 去对比两个 ...
- Python模糊查询本地文件夹去除文件后缀(7行代码)
Python模糊查询本地文件夹去除文件后缀 import os,re def fuzzy_search(path): word= input('请输入要查询的内容:') for filename in ...
随机推荐
- leetcode python 041首个缺失正数
##限定时间复杂度O(n)num=[0,5,3,1,2,-2,4,8,5,6]num=set(num)d=1for i in range(1,len(num)+1): if d in num: ...
- java实现链栈
package linkstack; /** * Created by Administrator on 2019/4/18. */ public class LinkStack { private ...
- Python中字符串的处理方法
1.字符串 word = '字符串' sentence = "这是一个句子." paragraph = """这是一个段落, 可以由多行组成" ...
- Markdown中特殊字符的转义字符
上次在用Markdown记笔记时,当正文中写到<PROJECT>_<PATH>_<FILE>_H_时,<>里的内容显示显示不出来,就算用' '也显示不出 ...
- 初学者--oracle安装完后出现的一些问题
对于初学者安装数据库后,立马回运行数据库,看是否安装成功,但oracle安装完成,其中有些都是默认状态,所以需要手动修改和添加.例如这个问题 1.pl/sql developer was not te ...
- 查询数据库游标使用情况以及sql
----查询游标使用情况以及游标最大数---- SELECT MAX(A.VALUE) AS HIGHEST_OPEN_CUR, P.VALUE AS MAX_OPEN_CUR FROM V$SESS ...
- 基本矩张量与strike.dip.rake的对应
basefp1=[ ]; M(,:)=[ ]; basefp2=[ -];M(,:)=[ - ]; basefp3=[ ];M(,:)=[ ]; basefp4=[ -];M(,:)=[ ]; bas ...
- Displaylink安卓驱动
Displaylink安卓驱动 2019年最新版V2.3.1
- 泊爷带你学go -- redis连接池的操作
package main import ( "common" "fmt" "proto" "strconv" " ...
- 闪付卡(QuickPass)隐私泄露原理
0×00 前言 说到闪付卡,首先要从EMV开始,EMV是由Europay,MasterCard和VISA制定的基于IC卡的支付标准规范.目前基于EMV卡的非接触式支付的实现有三个:VISA的payWa ...