Solr 02 - 最详细的solrconfig.xml配置文件解读
solrconfig.xml文件位于SolrCore的conf目录下, 通过solrconfig.xml可以配置SolrCore实例的相关信息, 可不作修改.
这里以4.10.4版本为例, 文件位置:example/solr/collection1/conf/solrconfig.xml;
1 luceneMatchVersion - 指定Lucene版本
<luceneMatchVersion>4.10.4</luceneMatchVersion>
表示Solr底层使用的Lucene的版本, 官方推荐使用新版本的Lucene.
使用注意事项: 如果更改了这个设置, 必须对所有已经创建的索引数据重新索引(re-index), 否则可能出现无法查询的情况.
2 lib - 配置扩展jar包
solrconfig.xml中可以加载一些扩展的jar包, 扩展步骤如下:
(1) 把要扩展的jar包复制到指定目录;
这里将其复制到SolrHome同级目录, 防止项目移动时遗忘了这些jar包, 导致项目出错;
如果有多个SolrHome, 建议把这些jar包放置在SolrHome的上级目录, 这样就不必在每个SolrHome中添加这些jar包, 从而下述路径也就无需修改了;
(2) 复制solr解压文件中的contrib和dist目录到work目录下(与SolrHome同级, 为了后期搭建集群时共用这些jar包, 而不用每次都添加);
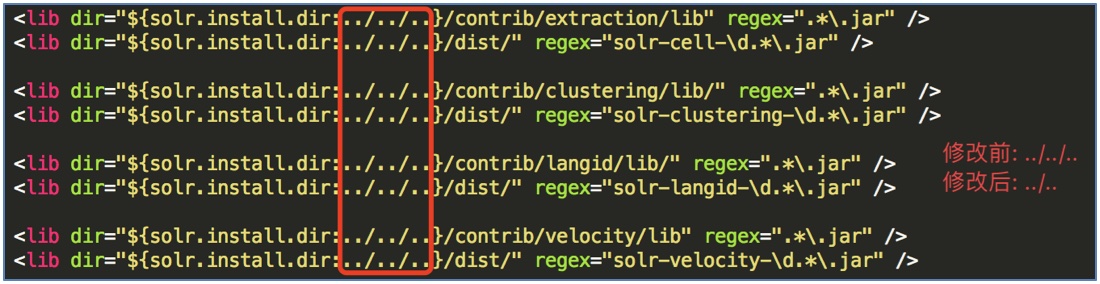
(3) 修改solrconfig.xml文件, 加载扩展的jar包:
solr.install.dir表示${SolrCore}的目录位置, 这里是collection1内的路径;
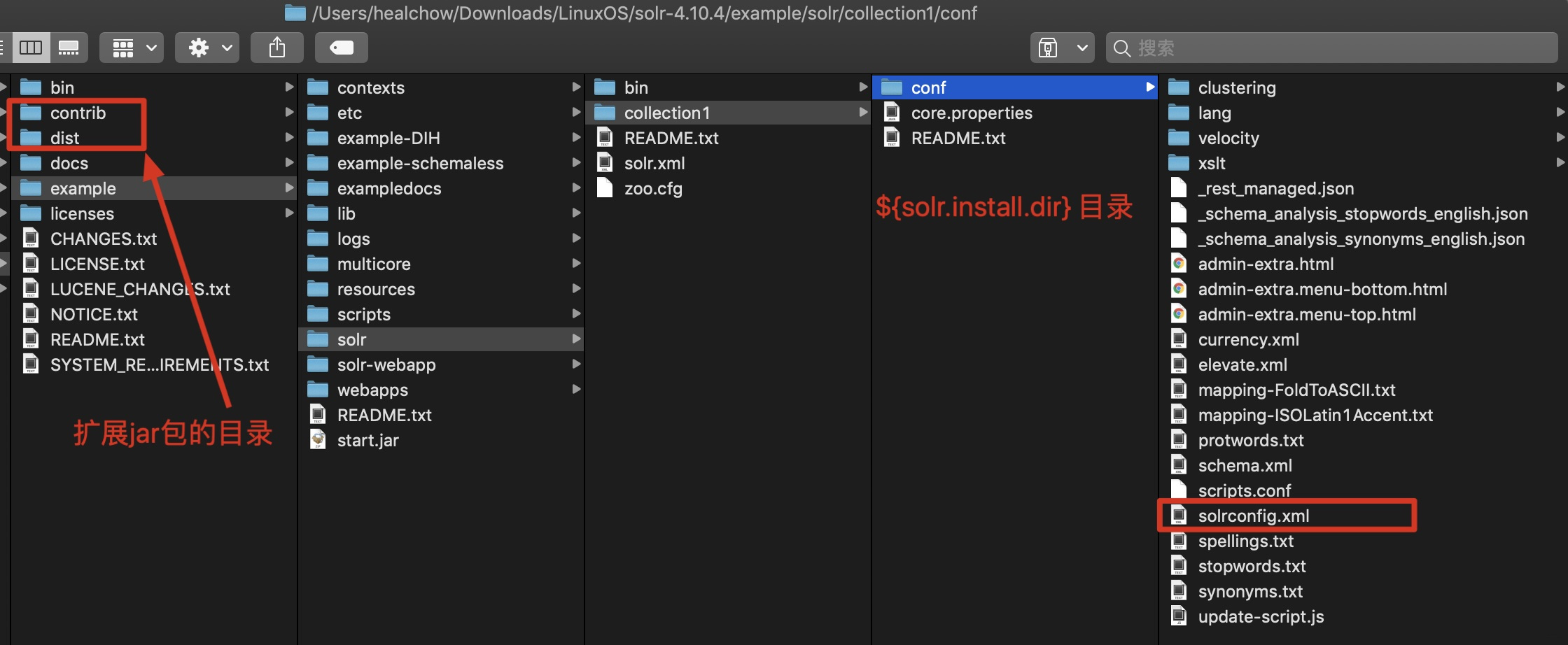
./ 表示当前目录; ../ 表示上一级目录.
这里要将jar包放置在${SolrCore}上一级目录的lib目录下, 需要把 ../../.. 修改为 ../..:
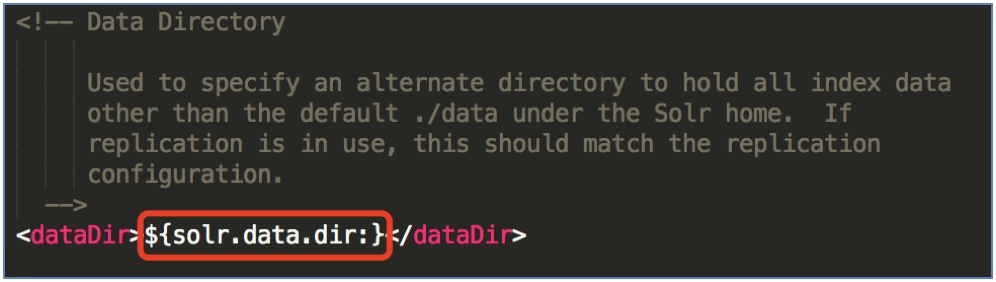
3 dataDir - 索引数据路径
配置SolrCore的data目录.
data目录用来存放当前SolrCore的index索引文件和tlog事务日志文件.
solr.data.dir表示${SolrCore}/data的目录位置.
建议不作修改, 否则配置多个SolrCore时容易出错.
4 directoryFactory - 索引存储工厂
<directoryFactory name="DirectoryFactory"
class="${solr.directoryFactory:solr.NRTCachingDirectoryFactory}">
<!-- These will be used if you are using the solr.HdfsDirectoryFactory,
otherwise they will be ignored. If you don't plan on using hdfs,
you can safely remove this section. -->
<!-- The root directory that collection data should be written to. -->
<str name="solr.hdfs.home">${solr.hdfs.home:}</str>
<!-- The hadoop configuration files to use for the hdfs client. -->
<str name="solr.hdfs.confdir">${solr.hdfs.confdir:}</str>
<!-- Enable/Disable the hdfs cache. -->
<str name="solr.hdfs.blockcache.enabled">${solr.hdfs.blockcache.enabled:true}</str>
<!-- Enable/Disable using one global cache for all SolrCores.
The settings used will be from the first HdfsDirectoryFactory created. -->
<str name="solr.hdfs.blockcache.global">${solr.hdfs.blockcache.global:true}</str>
</directoryFactory>
有以下存储方案:
(1) solr.StandardDirectoryFactory: 这是基于文件系统存储目录的工, 它会基于当前的操作系统和JVM版本选择最好的实现.
(2) solr.NRTCachingDirectoryFactory - 默认方案: 此工厂的设计目的是在内存中存储部分索引, 从而加快近实时搜索(Near-Real-Time)的速度.
(3) solr.MMapDirectoryFactory: 这是Solr 3.1 - 4.0版本在Linux64位系统下的默认实现, 它通过使用虚拟内存和内核特性调用
mmap去访问存储在磁盘中的索引文件, 允许Lucene或Solr直接访问I/O缓存. 如果不需要近实时搜索功能, 使用此工厂是个不错的方案.
(4) solr.NIOFSDirectoryFactory: 适用于多线程, 但据报道, Solr 4.x之前的版本不适用在Windows系统上(慢), 因为JVM还存在bug.
(5) solr.SimpleFSDirectoryFactory: 适用于小型应用程序, 不支持大数据和多线程.
(6) solr.RAMDirectoryFactory: 这是内存存储方案, 不能持久化存储, 在系统重启或服务器crash时数据会丢失. 而且不支持索引复制(不能使用副本).
5 codecFactory - 编解码方式
<codecFactory class="solr.SchemaCodecFactory"/>
<schemaFactory class="ClassicIndexSchemaFactory"/>
Solr中, 编解码可以使用自定义的编解码器, 比如: 想启动per-field DocValues 格式, 可以在solrconfig.xml文件中设置SchemaCodecFactory 的内容:
docValuesFormat="Lucene42": 默认设置, 所有数据会被加载到堆内存中;
docValuesFormat="Disk": 这是另一个实现, 将部分数据存储在磁盘上;
docValuesFormat="SimpleText": 文本格式, 非常慢, 仅仅用于学习测试.
6 indexConfig - 索引配置
indexConfig标签用于设置索引的属性.
(1) maxFieldLength: 对文档建立索引时, 文档字段的最大长度, 超过这个长度的值将被截断. 如果文档很大, 就需要增加这个数值.
这个值设置得过高会导致内存不足异常;
该配置在Solr 4.0版本开始已经移除了, 类似的设置需要在fieldType中定义, 如:
<!-- 限制token最大长度 -->
<filter class="solr.LimitTokenCountFilterFactory" maxTokenCount="10000"/>
(2) writeLockTimeout: IndexWriter等待写锁的最长时间(毫秒).
默认是1000毫秒:
<writeLockTimeout>1000</writeLockTimeout>
(3) maxIndexingThreads: 生成索引时一个IndexWriter可以使用的最大线程数.
<maxIndexingThreads>8</maxIndexingThreads>
默认是8, 当很多个线程到达时, 多出的线程就只能等待运行中的线程结束, 以空出资源.
(4) useCompoundFile: 开启整合文件.
<useCompoundFile>false</useCompoundFile>
开启此选项, Lucene会将多个内部文件整合为若干个大文件, 来减少使用Lucene内部文件的数量. 即使用更少的用于索引的文件, 这有助于减少Solr用到的文件句柄的数目, 代价是降低了性能 ---- 用于索引的文件数变少了.
除非应用程序用完了文件句柄, 否则使用默认值false就可以.
Lucene中默认是true, Solr 3.6开始默认为false.
(5) ramBufferSizeMB: Lucene创建或删除index后, 合并内存中的文档数据、创建新的segment、将内存中的数据刷新到磁盘之前可用的RAM大小.
<ramBufferSizeMB>100</ramBufferSizeMB>
默认是100MB, 较大的值可以提高创建索引的时间, 但会牺牲更多内存.
(6) maxBufferedDocs: 在将内存中的索引数据刷新到磁盘之前, 可以使用的buffer大小.
<maxBufferedDocs>1000</maxBufferedDocs>
默认是1000个文档, 较大的值可以提高创建索引的时间, 但会牺牲更多内存.
说明: ⑤和⑥同时设置时, 优先满足阈值小的选项.
(7) mergePolicyFactory: 合并策略.
<mergePolicyFactory class="solr.TieredMergePolicyFactory">
<!-- 一次最多合并的段的个数 -->
<int name="maxMergeAtOnece">10</int>
<int name="segmentsPerTier">10</int>
</mergePolicyFactory>
配置Lucene中segment (段, 索引信息的呈现方式) 的合并策略:
从Solr/Lucene 3.3开始, 使用TieredMergePolicy;
从Lucene 2.3开始, 默认使用LogByteSizeMergePolicy;
更早的版本使用LogDocMergePolicy.
(8) mergeFactor: 合并因子, 每次合并多少个segment.
<mergeFactor>10</mergeFactor>
默认为10, 此项设置等同于同时设置MaxMergeAtOnce和SegmentsPerTier选项.
越小的值(最小为2)使用的内存越少, 但创建索引的时间也更慢;
值越大, 可以让索引时间变快, 但会用掉更多的内存 ---- 典型的时间与空间的平衡.
(9) mergeScheduler: 合并段的调度器, 控制Lucene如何实现段的合并.
<mergeScheduler class="org.apache.lucene.index.ConcurrentMergeScheduler"/>
从Lucene 2.3开始默认使用ConcurrentMergeScheduler调度器, 可以可以使用单独的线程在后台并行执行合并;
Lucene 2.2之前默认使用SerialMergeScheduler调度器, 并不能并行执行合并.
(10) lockType: 指定Lucene使用哪个LockFactory的实现, 即Lock策略.
<lockType>${solr.lock.type:native}</lockType>
共有3种策略:
single- SingleInstanceLockFactory, 建议用于只读索引(read-only)或不存在其他进程会修改索引的场景;
native- NativeFSLockFactory, 使用操作系统本地文件锁机制, 当同一个JVM中的多个Solr Web应用试图共享同一个索引时, 不能使用;
simple- SimpleFSLockFactory, 普通文件的行锁定方式.
Solr 3.6 之后默认是native策略, 之前的版本使用的是simple策略.
(11) unlockOnStartup: 启动Solr服务时释放锁.
<unlockOnStartup>false</unlockOnStartup>
某些情况下, 索引可能会由于不正确的关机或其他错误而一直处于锁定状态, 导致不能添加和更新索引. 将其设置为 true 可以禁用启动锁定, 从而允许添加和更新操作.
默认为false.
如果设置为true, 在Solr启动时将释放所有的写锁或提交锁 —— 忽略多线程环境中保护索引的锁定机制, 将导致进程可以绕过 Lucene索引的锁机制 直接访问索引, 请慎用.
如果锁类型为signgle, 该配置将不起作用.
(12) termIndexInterval: Lucene将term加载到内存中的频率.
最佳实践: 使用默认值128, 大多数情况下都很有用.
<termIndexInterval>128</termIndexInterval>
(13) nrtMode: 近实时模式.
<nrtMode>true</nrtMode>
默认为true. 设置为true, 将从IndexWriter打开/重新打开IndexReaders, 而不是从文件目录中打开.
在主/从模式的主机中, 将其设置为false;
在SolrCloud集群中, 将其设置为true.
(14) deletionPolicy: 删除策略.
在这里指定自定义的删除策略. 策略类必须实现org.apache.lucene.index.IndexDeletionPolicy.
默认配置如下:
<deletionPolicy class="solr.SolrDeletionPolicy">
<!-- 最多能够保留多少个提交点 -->
<!-- <str name="maxCommitsToKeep">1</str> -->
<!-- 最多能够保留多少个优化提交点-->
<!-- <str name="maxOptimizedCommitsToKeep">0</str> -->
<!-- 达到指定的时间, 就删除所有的提交点. 支持DateMathParser语法, 如: -->
<!--
<str name="maxCommitAge">30MINUTES</str>
<str name="maxCommitAge">1DAY</str>
-->
</deletionPolicy>
Solr 默认的实现类支持删除索引提交点的提交数量, 索引提交点和优化状态的年龄(即内部扫描的次数). 无论如何, 都应该一直保留最新的提交点.
(15) infoStream: Lucene的信息流, 控制索引时的日志信息.
<infoStream file="INFOSTREAM.txt">false</infoStream>
为了便于调试, Lucene提供了InfoStream 用于显示索引时的详细信息.
默认为false. 这里设置为true, Lucene底层的IndexWriter将会把自己的信息流写入Solr的日志, 具体日志信息还要通过log4j.properties文件控制.
(16) checkIntegrityAtMerge: 合并段时的安全检查.
<checkIntegrityAtMerge>false</checkIntegrityAtMerge>
设置为true, 将启用此安全检查 —— 有助于在合并segment时 降低旧segments中损坏的索引转移到新段的风险, 代价是合并的速度将变慢.
7 updateHandler - 更新处理器
Solr默认使用的高可用的updateHandler是:
<updateHandler class="solr.DirectUpdateHandler2">
7.1 updateLog - 索引库的事务日志
<updateLog>
<!-- dir: 事务日志的存储目录 -->
<str name="dir">${solr.ulog.dir:}</str>
</updateLog>
默认路径: ${SOLR_HOME}/data/tlog.
启用事务日志用于实时查询、持久化索引数据、Solr Cloud中副本的恢复...
随着索引库的频繁更新, tlog日志文件会越来越大, 所以建议提交索引时采用硬提交 - 即批量提交的方式 - hard autoCommit.
7.2 autoCommit - 自动(硬)提交策略
这是默认的自动提交策略.
<autoCommit>
<!-- 多少个文档提交一次: 要添加的文档数达到此值时自动触发新的提交 -->
<!-- <maxDocs>10000</maxDocs> -->
<!-- 多少毫秒提交一次: 添加文档操作的时间持续到此值时自动触发新的提交, 与maxDocs配置其一即可 -->
<maxTime>${solr.autoCommit.maxTime:15000}</maxTime>
<!-- 如果为false, 提交操作会将最近的更改信息刷新到磁盘, 但不会立即打开查询器 - 也就是说客户端查询不到;
实时性要求高的项目, 需要设置为true - 在6.0之后的版本中默认为true -->
<openSearcher>true</openSearcher>
</autoCommit>
(1) autoCommit是硬提交, 开启后会进行如下操作:
① 生成一个新的tlog文件, 删除旧的tlog文件;
② 把内存中缓存的文档fsync(OS内部的函数)到磁盘中, 并创建一个index descriptor, 用来记录各个文档的存储位置;
==> 此时就算JVM奔溃或系统宕机, 也不影响这部分数据, 不利之处是: 占用资源较多;
③ 如果<openSearcher>true</openSearcher>, 就会打开查询器, 让此次硬提交的文档可供搜索.
(2) 可选项 - commitWithin - 在指定时间之后强制提交文档:
在Solr 6.x版本中, 支持如下配置:
这个多用在近实时搜索中, 因此默认情况下执行的是软提交 —— 修改后的文档不会被复制到集群中的slave服务器中, 也就存在数据丢失的隐患.
当然可以通过添加参数进行强制硬提交:<commitWithin>
<softCommit>false</softCommit>
</commitWithin>
使用方法类似于: <add commitWithin=10000>, Solr会在10s内提交添加的文档. 其他用法有:
① 在add方法中设置参数, 比如
server.add(doc, 10000);
② 在SolrRequest中设置, 比如:UpdateRequest req = new UpdateRequest();
req.add(doc);
req.setCommitWithin(10000);
req.process(server);
(3) 最佳实践建议:
在频繁添加文档的应用中, 官方建议使用
commitWithin, 而不是启用autoCommit.
通过代码操作时, 请不要使用commit API手动提交, 因为这会触发硬提交, 出现大量的创建、删除tlog文件的操作, 影响IO性能.
如果不配置autoCommit标签, 就只有在代码或命令中指定commit才会更新索引.
如果启用了updateLog, 官方强烈建议使用某种硬提交策略来限制日志的大小.
—— 最佳的自动提交设置: 需要在性能和可见行之间进行权衡.
// 如果要手动提交, 不要使用无参方法, 推荐指定提交策略: 是否等待刷新(建议不等待, 因为会阻塞)、等待可搜索(建议不等待, 因为会阻塞)、软提交
// 这是Solr 4.10版本API中的用法.
solrServer.commit(false, false, true);
7.3 autoSoftCommit - 软提交策略
<autoSoftCommit>
<maxTime>${solr.autoSoftCommit.maxTime:-1}</maxTime>
</autoSoftCommit>
(1) autoSoftCommit是软提交, 配置后会进行如下操作:
① 把内存中缓存的文档fsync(OS内部的函数)到磁盘中, 但不会创建index descriptor——也就是说各个文档的真实存储位置并没有被记录下来;
② 打开文档查询器, 涉及到的索引数据可以被查询到——近实时(NRT)更好;
③ 软提交不会等待后台合并、整理文档等操作, 只确保了修改的可见行, 没有获取到文档的具体存储位置 —— 也就是说如果此时JVM奔溃或系统宕机, 就找不到这些数据了.
(2) 最佳实践建议:
软提交比硬提交更快, 更能做到近实时查询, 但是如果服务器不稳定, 或JVM奔溃, 会导致提交的数据无法被检索到.
8 query - 查询相关配置
8.1 最大布尔子句
maxBooleanClauses: 最大布尔子句: 可以组合在一起形成一个查询的布尔子句数量的上限, 默认的1024已经足够.
<maxBooleanClauses>1024</maxBooleanClauses>
如果应用程序大量使用了通配符或范围查询, 为了避免抛出TooManyClausesException异常, 建议增加这个值.
这个选项会修改所有SolrCores的全局Lucene属性, 如果多个solrconfig.xml文件中的配置不一致, 将以最后初始化的文件为基准.
8.2 查询缓存
(1) 关于缓存:
Solr使用Searcher类来处理查询. 这个类将与索引相关的数据加载到内存中, 根据索引、CPU及内存的大小, 加载过程可能耗时比较久.
要改进这一设计和显著提高性能, Solr引入了一种 "预热" 策略, 就是把这些新的Searcher联机以便为用户提供查询服务之前, 先对它们 "热身".
(2) Solr中有2种缓存实现:
a. 基于LinkedHashMap的LRUCache;
b. 基于ConcurrentHashMap的FastLRUCache.区别: FastLRUCache在单线程操作中具有更快的查询和更慢的添加操作, 因此当缓存的命中率高 ( > 75%) 时通常比LRUCache更快, 并且在多CPU系统的其他场景下可能更快.
(3) 缓存的通用参数:
class: SolrCache的实现类;
size: cache中可保存的最大项;
initialSize: cache的初始化大小, 与java.util.HashMap中entry的容量相关;
autowarmCount: 预热项目数, 打开新的搜索器时, 可以使用多少项旧搜索器中的缓存数据来预填充新搜索器的缓存. 条目多意味着缓存的hit会更多, 就需要更长的预热时间.
(4) 其他说明:
① 对所有缓存模式而言, 设置缓存参数时, 都有必要在内存、CPU和磁盘访问之间进行均衡. Solr Web管理员界面的Statistics对分析缓存的hit-to-miss比例以及微调缓存大小等统计数据都非常有用.
② 并非所有应用程序都会从缓存受益, 实际上一些应用程序反而会由于 "将某个永远用不到的条目存储在缓存中" 这一额外步骤而受到影响.
(1) filterCache: 过滤器缓存.
<filterCache class="solr.FastLRUCache" size="512"
initialSize="512" autowarmCount="0"/>
是SolrIndexSearcher用于过滤 (filter queries, 也就是fq参数) 的缓存: 将得到的文档的id存储为无序的集合DocSets;
结果还能用来facet分片查询 —— 有效提高了Solr的查询性能.
(2) queryResultCache: 查询结果缓存.
<queryResultCache class="solr.LRUCache" size="512"
initialSize="512" autowarmCount="0"/>
缓存查询结果 —— 基于查询、排序和请求的有序的文档范围, 也就是文档id列表.
(3) documentCache: 文档缓存.
<documentCache class="solr.LRUCache" size="512"
initialSize="512" autowarmCount="0"/>
缓存Lucene的Document对象, 也就是每个文档的stored fields - 在schema.xml文件中配置.
由于Lucene内部文档ID是瞬态的(会被更改), 因此该缓存不会自热.
(4) cache: 块连接使用的自定义缓存.
<cache name="perSegFilter" class="solr.search.LRUCache"
size="10" initialSize="0" autowarmCount="10"
regenerator="solr.NoOpRegenerator" />
关于块连接(block join), 待学习...
(5) fieldValueCache: 字段值缓存.
<fieldValueCache class="solr.FastLRUCache" size="512"
autowarmCount="128" showItems="32" />
该缓存用来按照文档的id保存能够快速访问的字段的值, 就算这里不配置, Solr也会默认创建fieldValueCache.
(6) cache: 自定义缓存.
<!-- 自定义缓存的示例: -->
<cache name="myUserCache" class="solr.LRUCache"
size="4096" initialSize="1024" autowarmCount="1024"
regenerator="com.mycompany.MyRegenerator"
/>
自定义缓存的目的是实现用户/应用程序级数据的轻松缓存.
如果需要自热, 则应将regenerator参数指定为solr.CacheRegenerator类的实现类.
filterCache和queryResultCache实现了solr.CacheRegenerator, 所以都可以自热.可以通过
SolrIndexSearcher.getCache(),cacheLookup()和cacheInsert()按名称访问Solr的缓存.
8.3 懒加载Field
enableLazyFieldLoading: 开启懒加载Field.
<enableLazyFieldLoading>true</enableLazyFieldLoading>
性能优化建议: 如果应用程序只会检索文档中的少数几个Field, 可以把这个属性设置为true ---- 没有请求的存储字段(stored fields)将延迟加载.
懒加载大多发生在应用程序返回部分检索结果时, 用户常常会单击其中的一个来查看存储在此索引中的原始文档, 初始往往只需要显示很短的一段信息.
查询很大的Document, 尤其是含有很大的text类型的字段时, 应该避免加载整个文档.
8.4 使用过滤器
useFilterForSortedQuery: 为存储字段使用过滤器.
<useFilterForSortedQuery>true</useFilterForSortedQuery>
通过使用过滤器进行搜索的优化, 如果请求的排序条件不包括文档的得分(score), Solr将检查filterCache以查找与查询匹配的过滤器. 如果找到, 相关的过滤器将作为文档ID的来源, 然后对其ID进行排序返回.
大多数情况下, 除非 经常使用不同的排序规则 并 重复进行相同的查询, 否则这个配置没有多大用处, 可以不用配置.
8.5 query result - 查询结果
(1) queryResultWindowSize: 查询结果窗口大小.
<queryResultWindowSize>20</queryResultWindowSize>
用于queryResultCache的优化. 发起查询请求时, 将手机所请求数文档ID的数量集合.
例如: 搜索特定查询请求并匹配文档10-19, 并且queryWindowSize = 50, Solr将收集并缓存文档0-49.
可以通过缓存实现该范围内的任何其他查询请求.
(2) queryResultMaxDocsCached: 查询结果的最大文档缓存数.
<queryResultMaxDocsCached>200</queryResultMaxDocsCached>
设置查询结果中可以缓存的最大文档数.
8.6 Searcher的监听器
负责查询操作的各类搜索器 (IndexSearcher) 都可以触发相关监听器, 进而采取下一步操作:
① newSearcher - 每当创建新的搜索器时触发, 并且当前的搜索器正在处理请求(也称为被注册了). 它可以用来启动某些缓存, 以防止某些请求的请求时间过长.
② firstSearcher - 创建第一个搜索器时触发, 但这时是没有可用的搜索器来 处理请求 或 加载缓存中的数据的.
(1) QuerySenderListener:
QuerySenderListener使用名为NamedList的数组, 并对序列中的每个NamedList数组执行一个本地查询请求.
<listener event="newSearcher" class="solr.QuerySenderListener">
<arr name="queries">
<!--
<lst><str name="q">solr</str><str name="sort">price asc</str></lst>
<lst><str name="q">rocks</str><str name="sort">weight asc</str></lst>
-->
</arr>
</listener>
<!-- 开启此搜索器, 会导致Solr服务启动较慢 -->
<listener event="firstSearcher" class="solr.QuerySenderListener">
<arr name="queries">
<lst>
<str name="q">static firstSearcher warming in solrconfig.xml</str>
</lst>
</arr>
</listener>
(2) useColdSearcher: 使用冷搜索器.
<useColdSearcher>false</useColdSearcher>
如果搜索请求到来, 并且目前还没有被注册的搜索器, 就立即注册仍在加载缓存(自热)的搜索器并使用它.
默认为false - 所有请求都将阻塞, 直到第一个搜索器完成缓存数据的加载.
(3) maxWarmingSearchers: 最大的搜索器个数, 默认是2.
<maxWarmingSearchers>2</maxWarmingSearchers>
在后台同时预热(加载缓存)的搜索器的最大数量, 这些搜索器事先预热好, 可以随时使用. 如果申请的搜索器个数超出范围将会报错.
对只读的索引库, 建议设置为1-2, 对于可读写的索引库, 根据设备内存和CPU的大小, 可以设置更高的值.
如果频繁读写的索引库中, 此参数较小, 可能会抛出Error opening new searcher. exceeded limit of maxWarmingSearchers=2, try again later.的错误, 尝试将其调高即可解决此问题.
9 requestDispatcher - 请求转发器
9.1 开启handleSelect处理器
<requestDispatcher handleSelect="false" >
Request Dispatcher用来指示SolrCore里的
SolrDispatchFilter处理请求的行为.
handleSelect是一个以前版本中遗留下来的属性, 会影响请求的行为(比如/select?qt=XXX).如果
/select没有注册, 当handleSelect="true"时,SolrDispatchFilter就会把请求转发给qt参数指定的处理器;除非使用
/select显示注册了处理器, 否则当handleSelect="false"时,SolrDispatchFilter会忽略/select请求, 并导致404错误 ---- 使用上更安全.对于新用户不建议使用
handleSelect="true", 但这是默认向后兼容的配置.
9.2 requestParsers - 请求解析器
<requestParsers enableRemoteStreaming="true"
multipartUploadLimitInKB="2048000"
formdataUploadLimitInKB="20480"
addHttpRequestToContext="false"/>
这里配置Solr请求的解析行为, 以及对请求的ContentStreams的限制.
(1)
enableRemoteStreaming- 是否允许使用stream.file和stream.url参数来指定远程streams. 这里介绍的Solr4.10 版本中默认开启了此选项, 授权Solr获取远程文件 ---- 不安全, 官方建议我们要自己确保系统具有身份验证功能.(2)
multipartUploadLimitInKB- 指定Solr允许一个多文件上传的请求中文件的最大大小值, 以KB为单位.(3)
formdataUploadLimitInKB- 指定通过POST请求发送的表单数据(application/x-www-form-urlencoded)的最大值,以KB为单位(4)
addHttpRequestToContext- 设置为true, 它将声明原始的HttpServletRequest对象应该被包括在SolrQueryRequest的上下文集合(context map)中, 这里的SolrQueryRequest是基于httpRequest的请求.
这个HttpServletRequest不会被任何现有的Solr组件使用, 但在开发自定义插件时可能很有用.
9.3 httpCaching - HTTP 缓存
httpCaching 控制HTTP缓存控制头(HTTP cache control headers), 是W3C HTTP规格定义的HTTP响应的缓存过程, 与Solr内部的缓存完全不同, 请勿混淆.
<httpCaching>元素的属性决定了是否允许对一个GET请求进行304响应: 当一个客户端发起一个GET请求, 如果资源从上一次被获取后还没有被修改, 那么它可以在响应头中指定304响应.
304状态码的相关信息可参考: HTTP 304状态码的详细讲解
(1) 默认配置:
<httpCaching never304="true" />
never304: 如果设置为true, 那么即使请求的资源没有被修改, 客户端的GET请求也不会得到304响应.将这个属性设置为true对开发来说是方便的, 因为当通过支持缓存头的Web浏览器或其他用户修补Solr的响应时, 这里的304响应可能会让人混淆.
(2) 示例配置:
<httpCaching never304="false" lastModFrom="openTime" etagSeed="Solr">
<cacheControl>max-age=30, public</cacheControl>
</httpCaching>
如果包含<cacheControl>指令, 将会生成Cache-Control头信息, 如果值包含max-age=, 还会生成Expires头信息 ---- 默认情况下不会生成任何Cache-Control头信息.
即使设置了never304 ="true", 也可以使用<cacheControl>选项。
如果要让Solr能够使用自动生成的HTTP缓存头进行响应, 并正确响应缓存验证请求, 就要把never304的值设置为"false" ⇒ Solr将根据索引的属性生成相关的Last-Modified和ETag头信息.
还可以指定以下选项来限制响应头的信息:
(1)
lastModFrom- 默认值为"openTime"(记录了最后的更改时间), 这意味着Last-Modified值(以及对If-Modified-Since请求的验证)将全部与当前Searcher的openTime相关联.如果希望
lastModFrom与上次修改物理索引的时间精确同步, 可以将其更改为lastModFrom="dirLastMod".(2)
etagSeed="..."- 是一个可以更改的选项, 即使索引没有更改, 改变这个值将强制更改ETag头信息, 从而强制让用户重新获取内容, 比如对配置文件作了重大修改时.
如果使用了never304="true", Solr将忽略 lastModifiedFrom 和 etagSeed 的配置.
10 requestHandler - 请求处理器
Solr通过RequestHandler(请求处理器), 提供类似WebService的功能 —— 通过HTTP请求对索引进行访问.

Solr通过下述步骤选择Request Handler去处理请求:
(1) 传入的查询将根据请求中 qt 参数指定的路径, 按名称分派给特定的Request Handler.
(2) 如果请求路径使用了 /select, 但却没有任何一个Request Handler具有select这个名称, 而requestDispatcher中指定了handleSelect="true", 就会根据qt参数调度Request Handler.
(3) 没有 /的请求, 是这样被执行的: http://host/app/[core/]select?qt=name, 如果没有给出qt参数, 那么将使用配置为 default="true" 的 requestHandler 或者名称为 "standard"(标准处理器)的处理器处理.
(4) 如果要使用配置为 startup="lazy"的处理器, 则在第一个使用这个请求处理器的请求到来之前不会初始化它.
10.1 通过 /select 搜索索引
通过 /select 搜索索引:

① defaults - 默认值:
可以指定查询参数的默认值, 这些都会被请求中的参数覆盖, 也就是说请求中的优先.
<requestHandler name="/select" class="solr.SearchHandler">
<!-- 设置默认的参数值, 可以在请求地址中修改这些参数 -->
<lst name="defaults">
<!-- 调试信息返回到客户端的参数 -->
<str name="echoParams">explicit</str>
<int name="rows">10</int> <!-- 显示的数量 -->
<str name="df">text</str> <!-- 默认的搜索字段 -->
</lst>
</requestHandler>
② appends - 追加值:
除了默认值之外, 还可以指定appends(追加)参数来标识 从查询参数 (或现有的"defaults"的值) 中获取参数值, 然后追加到 multi-val 参数列表中.
下面的例子中, 参数 fq=instock:true 将追加到用户指定的任何查询的fq参数上, 这种分区索引机制独立于所有客户端的过滤查询.
<!--
<lst name="appends">
<str name="fq">inStock:true</str>
</lst>
-->
⇒ 在Solr中, 客户端无法阻止这些追加的值被使用, 所以除非你确定你总是想要它, 否则不要使用这种机制.
③ invariants - 不变量:
这个参数用来设置不会被客户端覆盖的值 ⇒ 在invariants部分定义的值总会被使用, 而不用考虑用户或客户端指定的defaults 或 appends 的值.
下面的例子中, 将修复 facet.field 和 facet.query 参数, 从而限制客户端可以使用的分面(facet, 类似于一种过滤搜索).
<!--
<lst name="invariants">
<str name="facet.field">cat</str>
<str name="facet.field">manu_exact</str>
<str name="facet.query">price:[* TO 500]</str>
<str name="facet.query">price:[500 TO *]</str>
</lst>
-->
默认情况下, Solr中的 facet 是不会打开的, 但如果客户端在请求中指定了facet=true, 那么不管它们指定的 facet.field 或 facet.query 参数是什么, 这里配置的都将是客户端唯一能得到的facet的内容.
⇒ 注意:绝对客户端无法阻止使用这些“不变量”值,因此除非您确定总是需要它,否则不要使用此机制.
④ components - 组件:
在request handler的最后, 是组件 components 的定义: 定义可以用在一个request Handler的搜索组件的列表, 它们仅在 Request Handler 中注册.
<!--
<arr name="components">
<str>nameOfCustomComponent1</str>
<str>nameOfCustomComponent2</str>
</arr>
-->
搜索组件元素只能被用于SearchHandler, 如果不需要默认的SearchComponents列表, 可以完全覆盖该列表, 也可以将组件添加到默认列表中或将其附加到默认列表中.
10.2 通过 /query 搜索索引
Solr中的请求处理器, 默认返回缩进的JSON格式的内容:
<requestHandler name="/query" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<str name="wt">json</str> <!-- 显示的格式 -->
<str name="indent">true</str> <!-- 是否缩进 -->
<str name="df">text</str> <!-- 默认的搜索字段 -->
</lst>
</requestHandler>
10.3 通过 /get 获取索引
RealTimeGetHandler - 实时获取处理器, 保证返回的每个文档的最新存储字段, 而不需要提交或打开新的Searcher.
Solr当前版本的 RealTimeGetHandler 的实现, 需要开启 updateLog 功能.
警告:
如果使用SolrCloud, 就不要在
/get处禁用RealTimeGetHandler, 否则每次触发的Leader选举都将导致选举涉及到的Shard中的所有Replicas被完全同步.同样, Replica的恢复也将始终从Leader中获取完整的索引, 因为如果没有
RealTimeGetHandler的情况下, Replicas将无法进行部分同步.
<requestHandler name="/get" class="solr.RealTimeGetHandler">
<lst name="defaults">
<str name="omitHeader">true</str>
<str name="wt">json</str> <!-- 显示格式 -->
<str name="indent">true</str>
</lst>
</requestHandler>
10.4 通过 /export 导出结果
导出请求处理器用于导出完整排序的结果集, 请不要更改这些默认的配置值.
<requestHandler name="/export" class="solr.SearchHandler">
<lst name="invariants">
<str name="rq">{!xport}</str>
<str name="wt">xsort</str>
<str name="distrib">false</str>
</lst>
<arr name="components">
<str>query</str>
</arr>
</requestHandler>
10.5 通过 /update 修改索引
通过 /update 维护索引, 可以通过使用XML、JSON、CSV或JAVABIN指定的命令对索引进行添加、修改、删除操作.
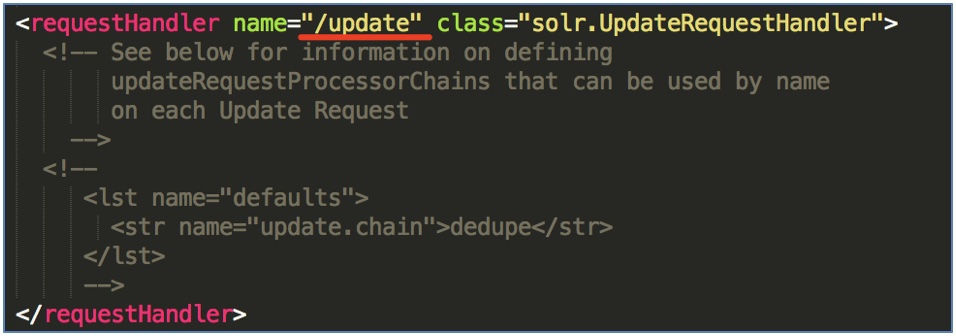
<requestHandler name="/update" class="solr.UpdateRequestHandler">
<!--
<lst name="defaults">
<str name="update.chain">dedupe</str>
</lst>
-->
</requestHandler>
注意事项:
从Solr1.1版本开始,
requestHandlers在请求体中需要包含有效的Content-type(内容类型)头信息, 例如: curl 中这样使用:-H 'Content-type:text/xml;charset= UTF-8'.要覆盖请求体重Content-type并强制使用特定的Content-type, 就需要在请求参数中指定:
?update.contentType=text/csv.如果
wt相应类型参数没有给出, 处理器将选择一个响应格式以匹配输入的内容.
参考资料
版权声明
作者: 马瘦风
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但请保留此段声明, 并在文章页面明显位置给出原文链接, 否则博主保留追究相关人员法律责任的权利.
Solr 02 - 最详细的solrconfig.xml配置文件解读的更多相关文章
- solr4.2 solrconfig.xml配置文件简单介绍
对于solr4.x的每个core有两个很重要的配置文件:solrconfig.xml和schema.xml,下面我们来了解solrconfig.xml配置文件. 具体很详细的内容请细读solrcofi ...
- 全网最详细的hive-site.xml配置文件里如何添加达到Hive与HBase的集成,即Hive通过这些参数去连接HBase(图文详解)
不多说,直接上干货! 一般,普通的情况是 全网最详细的hive-site.xml配置文件里添加<name>hive.cli.print.header</name>和<na ...
- solrconfig.xml配置文件
部分来自http://www.jianshu.com/p/8cf609207497 一.总览 solr的配置重要的有三个:solr.xml.solrConfig.xml.schema.xml solr ...
- 全网最详细的hive-site.xml配置文件里添加<name>hive.cli.print.header</name>和<name>hive.cli.print.current.db</name>前后的变化(图文详解)
不多说,直接上干货! 比如,你是从hive-default.xml.template,复制一份,改名为hive-site.xml 一般是 <configuration> <prope ...
- WEB.xml配置文件解读
1.启动一个WEB项目的时候,WEB容器会去读取它的配置文件web.xml,读取<listener>和<context-param>两个结点. 2.紧急着,容创建一个Servl ...
- 利用SOLR搭建企业搜索平台 之——solr配置solrconfig.xml
来源:http://blog.csdn.net/zx13525079024/article/details/25310781 solrconfig.xml配置文件主要定义了SOLR的一些处理规则,包括 ...
- solrconfig.xml解析
solrconfig.xml配置文件主要定义了SOLR的一些处理规则,包括索引数据的存放位置,更新,删除,查询的一些规则配置.下面将对solrconfig进行详细描述:1 <luceneMatc ...
- solrconfig.xml和schema.xml说明
1. solrconfig.xml solrconfig.xml配置文件主要定义了SOLR的一些处理规则,包括索引数据的存放位置,更新,删除,查询的一些规则配置. 1.1. datadir节点 ...
- 电商指尖---(6)solrconfig.xml配置具体解释
solrconfig.xml配置文件主要定义SOLR理规则,包含索引数据的存放位置,更新,删除,查询的一些规则配置. 能够在tomcat的安装路径下找到这个文件C:\Program Files\Apa ...
随机推荐
- 怎样使用C# MD5加密来增强密码的安全度
一.前言 MD5说明http://zh.wikipedia.org/wiki/MD5 .NET MD5类 官方文档&示例http://msdn.microsoft.com/zh-cn/libr ...
- 微信小程序 + nodeJs(loopback) 实现支付
实现小程序的支付,首先需要去微信官网先了解一下微信小程序支付相关接口文档:https://pay.weixin.qq.com/wiki/doc/api/wxa/wxa_api.php?chapter= ...
- 理解JavaScript【转】
第一题 if (!("a" in window)) { var a = 1; } alert(a); 第二题 var a = 1, b = function a(x ...
- 2018年10月OKR初步规划
OKR(Objectives and Key Results)即目标+关键结果,是一套明确和跟踪目标及其完成情况的管理工具和方法 今天是十月的第一个工作日,也是我归零的第一天,受到一位前辈的启发,我决 ...
- vue-router的学习
一.路由的概述. vue-router是vue.js官方的路由插件,它和vue.js是深度集成的,适用于构建单页面.vue的单页面应用是基于路由和组件的,路由是用于设定访问路径,并将路径和组件映射起来 ...
- jieba库的使用与词频统计
1.词频统计 (1)词频分析是对文章中重要词汇出现的次数进行统计与分析,是文本 挖掘的重要手段.它是文献计量学中传统的和具有代表性的一种内容分析方法,基本原理是通过词出现频次多少的变化,来确定热点及其 ...
- SQL语句基本
基础 创建数据库 CREATE DATABASE database-name 1 删除数据库 drop database dbname 1 备份sql server 创建 备份数据的 device U ...
- Lua学习----零碎知识点
Jit(just in time) 动态即时编译,边运行时边编译---->lua (主要是面向进程) Aot(ahead of time) 静态提前编译,运行前编译---->C#(主要是面 ...
- Senparc之OAuth原理
今天学习了网易云课堂的 盛派的微信开发课程之OAuth微信网页授权:OAuth原理,边听边来波笔记: 1.什么是OAuth? OAuth 你的接口提供给别人使用,你需要提供Oauth,可以让被人使用, ...
- 【XSS】利用 onload 事件监控流量劫持
说到跨站资源监控,首先会联想到『Content Security Policy』.既然 CSP 好用,我们何必自己再搞一套呢.那就先来吐槽下 CSP 的缺陷. 目前的 CSP 日志不详细 用过 CSP ...