【深度学习与TensorFlow 2.0】卷积神经网络(CNN)
注:在很长一段时间,MNIST数据集都是机器学习界很多分类算法的benchmark,这个数据集被Hinton称为机器学习界的果蝇(学生物的同学应该都知道果蝇这种模式生物对生物学研究的重要性)。初学深度学习,在这个数据集上训练一个有效的卷积神经网络就相当于学习编程的时候打印出一行“Hello World!”。下面基于与MNIST数据集非常类似的另一个数据集Fashion-MNIST数据集来构建一个多层感知机,并介绍一些TF构建神经网络时的基本概念。
0. Fashion-MNIST数据集
MNIST数据集在机器学习算法中被广泛使用,下面这句话能概况其重要性和地位:
In fact, MNIST is often the first dataset researchers try. "If it doesn't work on MNIST, it won't work at all", they said. "Well, if it does work on MNIST, it may still fail on others."
Fashion-MNIST数据集是由ZALANDO实验室制作,发表于2017年。在该数据集的介绍中,列出了MNIST数据集的不足之处:
- MNIST太容易了,卷积神经网络可以达到99.7%的正确率,传统的分类算法也能很轻易的达到97%的正确率;
- 被过度使用了;
- 不能很好的代表现代计算机视觉任务.
Fashion-MNIST数据集的规格(28×28像素的灰度图片,10个不同类型),数据量(训练集包括60000张图片,测试集包括10000张图片)都与MNIST保持一致。差别是,MNIST的数据是手写数字0-9,Fashion-MNIST的数据是不同类型的衣服和鞋的图片。
下面是该数据集中的标签:
| Label | Description |
|---|---|
| 0 | T-shirt/top |
| 1 | Trouser |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
下面是一些例子:

图0-1:Fashion-MNIST 中的图片示例
1. 多层感知机
线性回归相当于是单层网络,深度学习主要关注多层网络。多层感知机在单层网络的基础上引入了一到多个隐藏层,隐藏层位于输入层和输出层之间。
1.1 导入依赖的包
下面导入了一些必要的 package(包括前面安装的 tensorflow-datasets),并且输出了当前使用的 TensorFlow(TF) 的版本号。如果不是最新的 TF,可以使用下面的命令安装最新的TF。
pip install tensorflow==2.1.0 # 安装最新版的TF
Tips: 如果国外的源安装比较慢,可以使用下面的命令来指定国内的源安装:
# 利用清华大学 pypi 镜像更新pip
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pip -U
# 将清华大学 pypi 镜像设为默认源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
from __future__ import absolute_import, division, print_function, unicode_literals # TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras # Helper libraries
import numpy as np
import matplotlib.pyplot as plt print(tf.__version__) # 2.1.0
1.2 导入数据集
TF中包含了调用一些常用数据集的API:boston_housing, cifar10, cifar100, fashion_mnist, imdb, mnist, reuters
Fashion-MNIST数据集与MNIST数据集相同,train_dataset 中包含60000张图片用来做训练集,test_dataset 中包含10000张图片用来做测试集.
fashion_mnist = keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data() # 得到4个Numpy Array
下面是所有衣服或鞋的名称,其顺序与其前面列出的该数据集的标签顺序相同:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
可以利用一些常用的函数来查看数据集的信息:
print(type(train_images)) # <class 'numpy.ndarray'> # 整个训练集的维度信息
print(train_images.shape) # (60000, 28, 28)
# 总样本数
print(len(train_labels)) # 6000
# 单个样本的维度信息
print(train_images[0].shape) # (28, 28)
1.3 数据的预处理
原始数据中图片的每个像素由[0, 255]区间上的整数表示。为了更好的训练模型,需要将所有的值都标准化到区间[0, 1]。
- 经过测试,如果不做这一步,最终在测试集的准确率会下降大概8% - 5%。
train_images = train_images / 255.0 test_images = test_images / 255.0
预处理后的数据同样可以表示一张图片,下面取出测试集中的一张图片并显示:
plt.figure(figsize=(5, 5))
plt.imshow(test_images[0], cmap=plt.cm.binary)
plt.colorbar()
plt.grid(False)
# plt.show()
plt.tight_layout()
plt.savefig('demo_single_img.png', dpi=100)
图1-1:标准化后的图片
取出训练集中前25张图片:
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
# plt.show()
plt.tight_layout()
plt.savefig('demo_25_img.png', dpi=100)

图1-2:训练集中前25张图片
1.4 建立模型
准备好数据之后,就可以构建神经网络模型了。主要包括构建网络和编译两部分。
1.4.1 构建网络
在构建网络时需要明确以下参数:
- 网络中包含的总层数;
- 每一层的类型:例如Flattten,Dense等;
- 每一层中包含的神经单元的个数;
- 每一层使用的激活函数:例如Relu,Softmax等,不设置该参数表示不对该层进行任何非线性变换.
下面时构建网络的代码:
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10)
])
该网络一共有3层(下面假设仅输入单个样本,即一张图片):
- 第一层是Flatten层(下图中的L0,输入层):输入的单个样本是一个28*28的矩阵(矩阵每一个元素的值表示图片中对应的一个像素点的值),输出一个长度为784的向量;
- 第二层是Dense层(下图中的L1,隐藏层):输入是上一层的输出,即长度为784的向量;该层具有128个神经单元,激活函数为Relu,输出为一个长度为128的向量;
- 第三层是Dense层(下图中的L2,输出层):输入是上一层的输出;该层具有10个神经单元,未设置激活函数,输出为一个长度为10的向量,也是该网络的输出层.
注:在第一层网络中需要指定input_shape参数,该参数不包含batch_size的信息,与单个样本的维度信息相同;最后一层未设置激活函数得到的向量被称为logits,官方解释如下
对数 (logits)
分类模型生成的原始(非标准化)预测向量,通常会传递给标准化函数。如果模型要解决多类别分类问题,则对数通常变成 softmax 函数的输入。之后,softmax 函数会生成一个(标准化)概率向量,对应于每个可能的类别。https://developers.google.cn/machine-learning/glossary
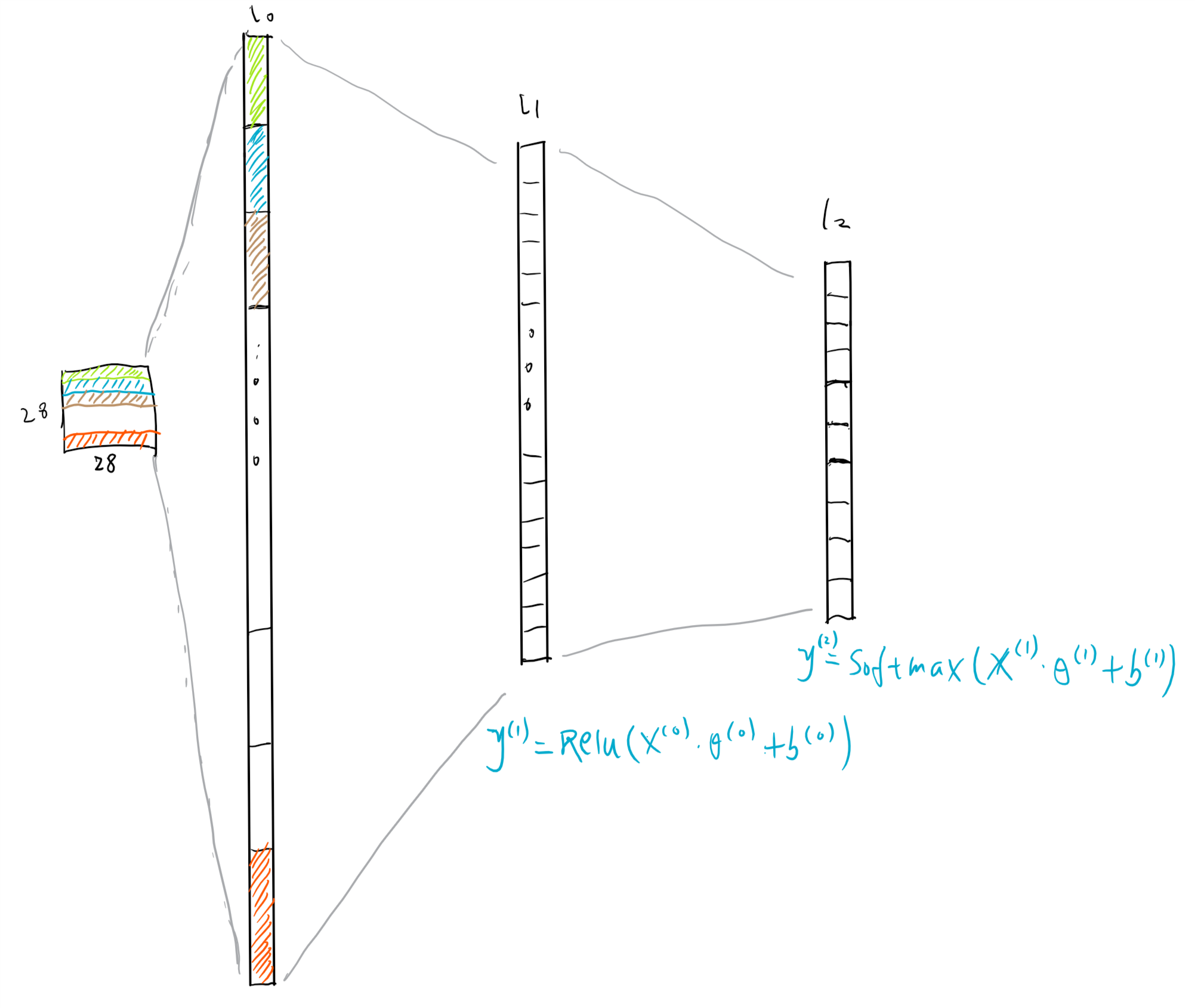
图1-3:网络的结构
上图中上角标表示层的编号,$\theta$表示各层的参数,$b$表示各层的偏执单元。
1.4.2 编译
网络构建好之后,需要编译。在编译过程中需要确定以下几个参数:
- 损失函数(Loss function):用来优化参数,评价模型预测值与样本标签之间的差别;
- 优化器(Optimizer):根据误差和梯度更新参数,从而最小化误差;
- 评估标准(Metrics):同样用于评价模型的好坏.
损失函数与评估标准的异同:
- 都是评价模型好坏的方式,且具有高度的相关性;
- 损失函数必须可导,是待训练参数的函数,模型的训练过程就是基于损失函数的优化过程;
- 评估标准不一定可导,具有更好的可解释性,例如分类问题中分类的准确率.
下面是编译的代码:
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
1.5 训练模型
建立好模型之后,就可以训练模型了。因为是使用梯度下降来训练模型,因此除了训练集,还需要指定两个参数:
- 批次大小(batch size):单次训练模型使用的样本数(下面设置该值为32,也就是每次训练只使用全部训练集中的32个样本,使用完所有训练集样本需要训练60000/32=1875次);
- 训练迭代次数(epochs):在整个训练集上训练的次数,如果该值为10且批次大小为32,那么参数总共会更新10*1875次,训练集中的每张图片会被用到10次,;
下面是训练模型的代码:
model.fit(train_images, train_labels, batch_size=32, epochs=10)
下面是训练过程中的输出:
Train on 60000 samples
Epoch 1/10
60000/60000 [==============================] - 5s 85us/sample - loss: 0.5038 - accuracy: 0.8235
Epoch 2/10
60000/60000 [==============================] - 4s 68us/sample - loss: 0.3825 - accuracy: 0.8629
Epoch 3/10
60000/60000 [==============================] - 5s 75us/sample - loss: 0.3440 - accuracy: 0.8746
Epoch 4/10
60000/60000 [==============================] - 4s 73us/sample - loss: 0.3181 - accuracy: 0.8827
Epoch 5/10
60000/60000 [==============================] - 4s 72us/sample - loss: 0.3011 - accuracy: 0.8887
Epoch 6/10
60000/60000 [==============================] - 4s 67us/sample - loss: 0.2863 - accuracy: 0.8924
Epoch 7/10
60000/60000 [==============================] - 4s 71us/sample - loss: 0.2727 - accuracy: 0.8984
Epoch 8/10
60000/60000 [==============================] - 4s 68us/sample - loss: 0.2611 - accuracy: 0.9026
Epoch 9/10
60000/60000 [==============================] - 4s 68us/sample - loss: 0.2503 - accuracy: 0.9058
Epoch 10/10
60000/60000 [==============================] - 4s 69us/sample - loss: 0.2431 - accuracy: 0.9094
<tensorflow.python.keras.callbacks.History at 0x7f48d69ed780>
可以看到随着迭代次数的增加,损失函数的值在下降,分类的准确率在上升。最后该模型在训练集上的分类准确率为91%.
1.6 模型的最终评价
前面是在训练集中训练模型,训练的终止条件是人为设定的训练次数。训练停止后,模型在训练集上的分类准确率为91%。如果我们认为现在模型训练已经完成,最后一步就是在测试集上评价模型。测试集中包含的数据是模型之前从未见过新样本,如果在测试集上表现好,说明该模型有很好的泛化能力,学习到了这类数据的本质特征。
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
下面是输出:
10000/10000 - 0s - loss: 0.3512 - accuracy: 0.8805 Test accuracy: 0.8805
最终在测试集中分类准确率为88%.
1.7 使用模型进行预测以及结果的可视化
下面从测试集取一个 batch 的样本(32个样本)进行预测,并将真实的label保存在test_labels中,最终得到第一个样本的预测分类与真实分类都是6.
为了做预测,在模型的后面添加一个softmax层,将logits转换成概率,这样可解释性更好:
probability_model = tf.keras.Sequential([model, tf.keras.layers.Softmax()])
# 预测测试集中图片的类型
predictions = probability_model.predict(test_images) # 取出第一个预测值,并查看对应的label
print(predictions[0])
print(np.argmax(predictions[0]))
print(test_labels[0])
下面是输出结果:
[1.5879639e-08 1.1686364e-10 2.4405375e-08 2.9096781e-10 4.6984933e-08
5.7084635e-03 3.3691771e-07 1.2553993e-02 4.3468383e-08 9.8173714e-01]
9
9
下面对部分结果进行可视化:
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array, true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([]) plt.imshow(img, cmap=plt.cm.binary) predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red' plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color) def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array, true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array) thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
检查测试集中的第一个样本
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.savefig('demo_single_img2.png', dpi=100)
plt.show()
结果显示该样本有98%的概率为最后一类:
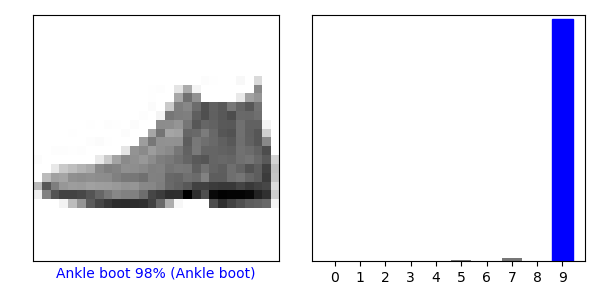
图1-4:测试集中单个样本预测结果的可视化
画出前15个样本:
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.savefig('demo_15_img2.png', dpi=100)
plt.show()
结果如下:
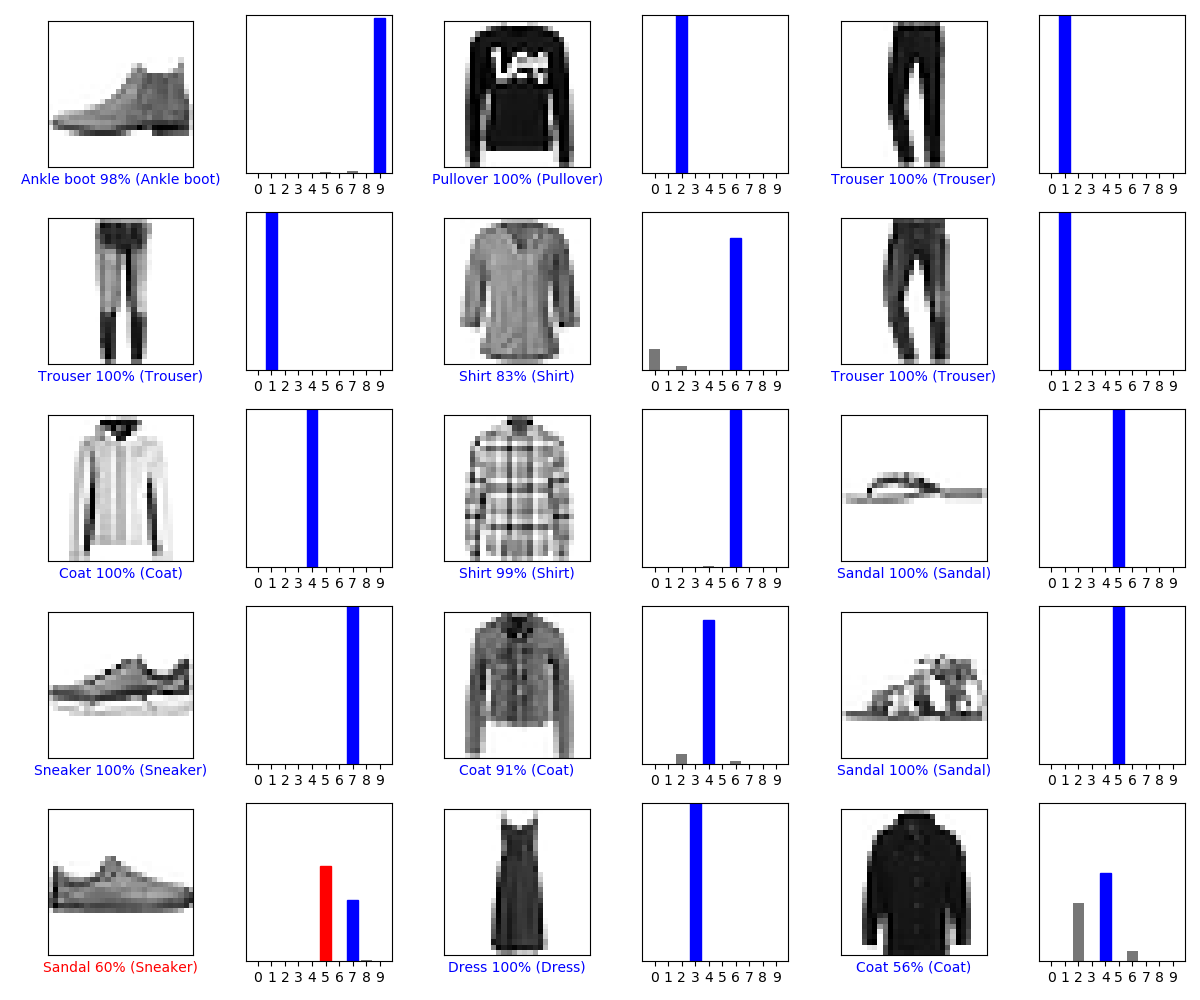
图1-5:测试集中部分预测结果的可视化
上图中,蓝色字体表示预测正确,蓝色柱状图表示正确的类;红色表示预测错误。第13个样本本来属于Sneaker,但是以60%的概率被预测为Sandal.
2. 小结
构建深度学习模型的一般流程
- 准备数据集:明确数据的特征、标签和样本总数,将数据集拆分成训练集和测试集(有时候还会包括验证集),数据的预处理(例如标准化等操作);
- 定义网络结构:在 Keras 和 TF 中,层(layer)是网络的基本结构,所有的网络类型都可以使用基本类型的层搭建起来。这里需要确定网络的层数,每一层的类型、激活函数、神经单元的个数等超参数;
- 编译模型:编译构建好的网络,需要明确三个参数,损失函数(loss function)、优化器(optimizer)和评估标准(metrics);
- 训练模型:需要指定批次大小(batch size)和迭代次数(epochs);
- 评价模型:在测试集上评价模型的效果.
更多与层有关的操作
参考:https://keras.io/layers/about-keras-layers/
https://tensorflow.google.cn/api_docs/python/tf/keras/layers
损失函数的选择
https://tensorflow.google.cn/api_docs/python/tf/keras/losses
- 两分类:binary crossentropy
- 对分类问题:categorical crossentropy
- 回归问题:mean-squared error
优化器的选择
参考:https://keras.io/optimizers/
https://tensorflow.google.cn/api_docs/python/tf/keras/optimizers
现在用的比较多的是RMSprop和Adam
度量
https://tensorflow.google.cn/api_docs/python/tf/keras/metrics
Reference
https://github.com/zalandoresearch/fashion-mnist#why-we-made-fashion-mnist
https://arxiv.org/abs/1708.07747
https://datascience.stackexchange.com/questions/13663/neural-networks-loss-and-accuracy-correlation
http://cs231n.stanford.edu/slides/2019/cs231n_2019_lecture05.pdf
https://blogs.nvidia.com/blog/2018/09/05/whats-the-difference-between-a-cnn-and-an-rnn/
https://github.com/OnlyBelter/examples/blob/master/courses/udacity_intro_to_tensorflow_for_deep_learning/l03c01_classifying_images_of_clothing.ipynb,代码
https://github.com/keras-team/keras-docs-zh,一些名词的翻译参考了该文档
Deep Learning with Python, by François Chollet, 2017.11
https://tensorflow.google.cn/tutorials/keras/classification
《动手学深度学习》,阿斯顿·张、李沐等,人民邮电出版社,2019.6
修改记录
2020.3.17 更新代码,修正typo,分离CNN部分另成一篇
【深度学习与TensorFlow 2.0】卷积神经网络(CNN)的更多相关文章
- 神经网络与深度学习笔记 Chapter 6之卷积神经网络
深度学习 Introducing convolutional networks:卷积神经网络介绍 卷积神经网络中有三个基本的概念:局部感受野(local receptive fields), 共享权重 ...
- UFLDL深度学习笔记 (六)卷积神经网络
UFLDL深度学习笔记 (六)卷积神经网络 1. 主要思路 "UFLDL 卷积神经网络"主要讲解了对大尺寸图像应用前面所讨论神经网络学习的方法,其中的变化有两条,第一,对大尺寸图像 ...
- 深度学习方法(五):卷积神经网络CNN经典模型整理Lenet,Alexnet,Googlenet,VGG,Deep Residual Learning
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 关于卷积神经网络CNN,网络和文献中 ...
- 【深度学习与TensorFlow 2.0】入门篇
注:因为毕业论文需要用到相关知识,借着 TF 2.0 发布的时机,重新捡起深度学习.在此,也推荐一下优达学城与 TensorFlow 合作发布的TF 2.0入门课程,下面的例子就来自该课程. 原文发布 ...
- 深度学习基础-基于Numpy的卷积神经网络(CNN)实现
本文是深度学习入门: 基于Python的实现.神经网络与深度学习(NNDL)以及动手学深度学习的读书笔记.本文将介绍基于Numpy的卷积神经网络(Convolutional Networks,CNN) ...
- 吴裕雄--天生自然python Google深度学习框架:图像识别与卷积神经网络
- 【原创 深度学习与TensorFlow 动手实践系列 - 1】第一课:深度学习总体介绍
最近一直在研究机器学习,看过两本机器学习的书,然后又看到深度学习,对深度学习产生了浓厚的兴趣,希望短时间内可以做到深度学习的入门和实践,因此写一个深度学习系列吧,通过实践来掌握<深度学习> ...
- 深度学习方法(十):卷积神经网络结构变化——Maxout Networks,Network In Network,Global Average Pooling
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 最近接下来几篇博文会回到神经网络结构 ...
- 深度学习方法(十一):卷积神经网络结构变化——Google Inception V1-V4,Xception(depthwise convolution)
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.机器学习技术感兴趣的同学加入. 上一篇讲了深度学习方法(十) ...
随机推荐
- angularjs和jquery前端发送以http请求formdata数据
formdata是比较常见的前端发送给后端的请求,不仅可以上传数据,而且同时可以上传文件. jquery使用http请求上传formdata数据的方法: var formdata = new Form ...
- BZOJ.5397.circular(随机化 贪心)
BZOJ 感觉自己完全没做过环上选线段的问题(除了一个2-SAT),所以来具体写一写qwq. 基本完全抄自remoon的题解qwq... (下标从\(0\sim m-1\)) 拆环为链,对于原线段\( ...
- 2018-2019-2 网络对抗技术 20162329 Exp2 后门原理与实践
目录 1.实践基础 1.1.什么是后门 1.2.基础问题 2.实践内容 2.1.使用netcat获取主机操作Shell,cron启动 2.2.使用socat获取主机操作Shell, 任务计划启动 2. ...
- android 第三次作业
android studio音乐播放器 一.实现功能: 1.读取本地SD中的所有音频文件 2.歌单列表展示,并显示音频具体信息 3.进度条显示当前播放进度,可滑动加速 4.点击歌单进行播放 5.实现暂 ...
- React修改state(非redux)中数组和对象里边的某一个属性的值
在使用React时,会经常需要处理state里边设置的初始值以达到我们的实际需求,比如从接口获取到列表数据后要赋值给定义的列表初始值,然后数据驱动view视图进而呈现在我们眼前,这种最简单的赋值方式实 ...
- React+Ant Design设置左侧菜单导航路由的显示与隐藏(与权限无关)
最近在学习react时,用到了很流行的UI框架Ant Design,也了解了一下Ant Design Pro,发现它们都有导航组件,Ant Design框架的导航菜单在这里,Ant Design Pr ...
- 929. Unique Email Addresses
929. Unique Email Addresses Easy 22766FavoriteShare Every email consists of a local name and a domai ...
- framework7 入门(数据绑定)
数据绑定是用template7,官网,framework7内置template7,不用单独下载,下面介绍一些简单的绑定 当你的数据是个数组 return{ data:function(){ let i ...
- 获取安卓应用APK包名的方法
应用商店按照符合Android标准的原则进行设计,使用包名(Package Name)作为应用的唯一标识.即:包名必须唯一,一个包名代表一个应用,不允许两个应用使用同样的包名.包名主要用于系统识别应用 ...
- 发一些Java面试题,上海尚学堂Java学员面试遇到的真题,值得学习
1. 下面哪些是Thread类的方法() A start() B run() C exit() D getPriority() 答案:ABD 解析:看Java AP ...