TensorRT&Sample&Python[network_api_pytorch_mnist]
本文是基于TensorRT 5.0.2基础上,关于其内部的network_api_pytorch_mnist例子的分析和介绍。
本例子直接基于pytorch进行训练,然后直接导出权重值为字典,此时并未dump该权重;接着基于tensorrt的network进行手动设计网络结构并填充权重。本文核心在于介绍network api的使用
1 引言
假设当前路径为:
TensorRT-5.0.2.6/samples
其对应当前例子文件目录树为:
# tree python
python
├── common.py
├── network_api_pytorch_mnist
│ ├── model.py
│ ├── README.md
│ ├── requirements.txt
│ └── sample.py
2 基于pytorch
其中只有2个文件:
- model:该文件包含用于训练Pytorch MNIST 模型的函数
- sample:该文件使用Pytorch生成的mnist模型去创建一个TensorRT inference engine
首先介绍下model.py
首先下载对应的mnist数据,并放到对应缓存路径下:
'''
i) 去http://yann.lecun.com/exdb/mnist/index.html 下载四个
ii) 放到/tmp/mnist/data/MNIST/raw/
'''
/tmp/mnist/data/MNIST/raw
├── t10k-images-idx3-ubyte.gz
├── t10k-labels-idx1-ubyte.gz
├── train-images-idx3-ubyte.gz
└── train-labels-idx1-ubyte.gz
这样加快model.py读取mnist数据的速度
# 该文件包含用于训练Pytorch MNIST模型的函数
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
import numpy as np
import os
from random import randint
# Network结构,2层卷积+dropout+一层全连接+一层softmax
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 20, kernel_size=5)
self.conv2 = nn.Conv2d(20, 50, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(800, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.max_pool2d(self.conv1(x), kernel_size=2, stride=2)
x = F.max_pool2d(self.conv2(x), kernel_size=2, stride=2)
x = x.view(-1, 800)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
class MnistModel(object):
''' 初始化'''
def __init__(self):
self.batch_size = 64
self.test_batch_size = 100
self.learning_rate = 0.01
self.sgd_momentum = 0.9
self.log_interval = 100
# Fetch MNIST data set.
# 训练时候的数据读取
self.train_loader = torch.utils.data.DataLoader(
datasets.MNIST('/tmp/mnist/data', train=True, download=True, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=self.batch_size,
shuffle=True)
# 测试时候的数据读取
self.test_loader = torch.utils.data.DataLoader(
datasets.MNIST('/tmp/mnist/data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=self.test_batch_size,
shuffle=True)
# 网络结构实例化
self.network = Net()
''' 训练该网络,然后每个epoch之后进行验证.'''
def learn(self, num_epochs=5):
# 每个epoch的训练过程
def train(epoch):
self.network.train() # 开启训练flag
optimizer = optim.SGD(self.network.parameters(), lr=self.learning_rate, momentum=self.sgd_momentum)
for batch, (data, target) in enumerate(self.train_loader):
data, target = Variable(data), Variable(target)
optimizer.zero_grad()
output = self.network(data) # 一次前向
loss = F.nll_loss(output, target) # 计算loss
loss.backward() # 反向计算梯度
optimizer.step()
if batch % self.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch,
batch * len(data),
len(self.train_loader.dataset),
100. * batch / len(self.train_loader),
loss.data.item()))
# 测试该网络
def test(epoch):
self.network.eval() # 开启验证flag
test_loss = 0
correct = 0
for data, target in self.test_loader:
with torch.no_grad():
data, target = Variable(data), Variable(target)
output = self.network(data) # 前向
test_loss += F.nll_loss(output, target).data.item() # 累加loss值
pred = output.data.max(1)[1] # 计算当次预测值
correct += pred.eq(target.data).cpu().sum() # 累加预测正确的
test_loss /= len(self.test_loader)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss,
correct,
len(self.test_loader.dataset),
100. * correct / len(self.test_loader.dataset)))
# 调用上面定义好的训练函数和测试函数
for e in range(num_epochs):
train(e + 1)
test(e + 1)
''' 可视化权重'''
def get_weights(self):
return self.network.state_dict()
''' 随机获取 测试样本队列中 样本 '''
def get_random_testcase(self):
data, target = next(iter(self.test_loader))
case_num = randint(0, len(data) - 1)
test_case = data.numpy()[case_num].ravel().astype(np.float32)
test_name = target.numpy()[case_num]
return test_case, test_name
可以看出,上面的代码就是定义了网络结构,和训练网络的函数方法。下面介绍下sample.py
# 该例子用pytorch编写的MNIST模型去生成一个TensorRT Inference Engine
from PIL import Image
import numpy as np
import pycuda.driver as cuda
import pycuda.autoinit
import tensorrt as trt
import sys, os
sys.path.insert(1, os.path.join(sys.path[0], ".."))
import model
# import common
# 这里将common中的GiB和find_sample_data,do_inference等函数移动到该py文件中,保证自包含。
def GiB(val):
'''以GB为单位,计算所需要的存储值,向左位移10bit表示KB,20bit表示MB '''
return val * 1 << 30
def find_sample_data(description="Runs a TensorRT Python sample", subfolder="", find_files=[]):
'''该函数就是一个参数解析函数。
Parses sample arguments.
Args:
description (str): Description of the sample.
subfolder (str): The subfolder containing data relevant to this sample
find_files (str): A list of filenames to find. Each filename will be replaced with an absolute path.
Returns:
str: Path of data directory.
Raises:
FileNotFoundError
'''
# 为了简洁,这里直接将路径硬编码到代码中。
data_root = kDEFAULT_DATA_ROOT = os.path.abspath("/TensorRT-5.0.2.6/python/data/")
subfolder_path = os.path.join(data_root, subfolder)
if not os.path.exists(subfolder_path):
print("WARNING: " + subfolder_path + " does not exist. Using " + data_root + " instead.")
data_path = subfolder_path if os.path.exists(subfolder_path) else data_root
if not (os.path.exists(data_path)):
raise FileNotFoundError(data_path + " does not exist.")
for index, f in enumerate(find_files):
find_files[index] = os.path.abspath(os.path.join(data_path, f))
if not os.path.exists(find_files[index]):
raise FileNotFoundError(find_files[index] + " does not exist. ")
if find_files:
return data_path, find_files
else:
return data_path
#-----------------
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
class ModelData(object):
INPUT_NAME = "data"
INPUT_SHAPE = (1, 28, 28)
OUTPUT_NAME = "prob"
OUTPUT_SIZE = 10
DTYPE = trt.float32
'''main中第三步:构建engine'''
# 该函数构建的网络结构和上面model.py中一致,只是这里通过训练后的网络模型读取对应的权重值,并填充到network中
# network是TensorRT提供的,weights是Pytorch训练后的模型提供的
def populate_network(network, weights):
'''network支持的方法来自https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/python_api/infer/Graph/Network.html '''
# 基于提供的权重配置网络层
input_tensor = network.add_input(name=ModelData.INPUT_NAME, dtype=ModelData.DTYPE, shape=ModelData.INPUT_SHAPE)
conv1_w = weights['conv1.weight'].numpy()
conv1_b = weights['conv1.bias'].numpy()
conv1 = network.add_convolution(input=input_tensor, num_output_maps=20, kernel_shape=(5, 5), kernel=conv1_w, bias=conv1_b)
conv1.stride = (1, 1)
pool1 = network.add_pooling(input=conv1.get_output(0), type=trt.PoolingType.MAX, window_size=(2, 2))
pool1.stride = (2, 2)
conv2_w = weights['conv2.weight'].numpy()
conv2_b = weights['conv2.bias'].numpy()
conv2 = network.add_convolution(pool1.get_output(0), 50, (5, 5), conv2_w, conv2_b)
conv2.stride = (1, 1)
pool2 = network.add_pooling(conv2.get_output(0), trt.PoolingType.MAX, (2, 2))
pool2.stride = (2, 2)
fc1_w = weights['fc1.weight'].numpy()
fc1_b = weights['fc1.bias'].numpy()
fc1 = network.add_fully_connected(input=pool2.get_output(0), num_outputs=500, kernel=fc1_w, bias=fc1_b)
relu1 = network.add_activation(input=fc1.get_output(0), type=trt.ActivationType.RELU)
fc2_w = weights['fc2.weight'].numpy()
fc2_b = weights['fc2.bias'].numpy()
fc2 = network.add_fully_connected(relu1.get_output(0), ModelData.OUTPUT_SIZE, fc2_w, fc2_b)
fc2.get_output(0).name = ModelData.OUTPUT_NAME
network.mark_output(tensor=fc2.get_output(0))
'''main中第三步:构建engine'''
def build_engine(weights):
'''下面的create_network会返回一个tensorrt.tensorrt.INetworkDefinition对象
https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/python_api/infer/Core/Builder.html?highlight=create_network#tensorrt.Builder.create_network
'''
with trt.Builder(TRT_LOGGER) as builder, \
builder.create_network() as network:
builder.max_workspace_size = GiB(1)
populate_network(network, weights) # 用之前的pytorch模型中的权重来填充network
# 构建并返回一个engine.
return builder.build_cuda_engine(network)
'''main中第四步:分配buffer '''
def allocate_buffers(engine):
inputs = []
outputs = []
bindings = []
stream = cuda.Stream()
for binding in engine:
size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_size
dtype = trt.nptype(engine.get_binding_dtype(binding))
# 分配host和device端的buffer
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
# 将device端的buffer追加到device的bindings.
bindings.append(int(device_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
inputs.append(HostDeviceMem(host_mem, device_mem))
else:
outputs.append(HostDeviceMem(host_mem, device_mem))
return inputs, outputs, bindings, stream
'''main中第五步:选择测试样本 '''
# 用pytorch的DataLoader随机选择一个测试样本
def load_random_test_case(model, pagelocked_buffer):
img, expected_output = model.get_random_testcase()
# 将图片copy到host端的pagelocked buffer
np.copyto(pagelocked_buffer, img)
return expected_output
'''main中第六步:执行inference '''
# 该函数可以适应多个输入/输出;输入和输出格式为HostDeviceMem对象组成的列表
def do_inference(context, bindings, inputs, outputs, stream, batch_size=1):
# 将数据移动到GPU
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]
# 执行inference.
context.execute_async(batch_size=batch_size, bindings=bindings, stream_handle=stream.handle)
# 将结果从 GPU写回到host端
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]
# 同步stream
stream.synchronize()
# 返回host端的输出结果
return [out.host for out in outputs]
def main():
''' 1 - 寻找模型文件,不过次例中未用到该返回值'''
data_path = find_sample_data(description="Runs an MNIST network using a PyTorch model", subfolder="mnist")
''' 2 - 训练该模型'''
mnist_model = model.MnistModel()
mnist_model.learn()
# 获取训练好的权重
weights = mnist_model.get_weights()
''' 3 - 基于build_engine构建engine;用tensorrt来进行inference '''
with build_engine(weights) as engine:
''' 4 - 构建engine, 分配buffers, 创建一个流 '''
inputs, outputs, bindings, stream = allocate_buffers(engine)
with engine.create_execution_context() as context:
''' 5 - 读取测试样本,并归一化'''
case_num = load_random_test_case(mnist_model, pagelocked_buffer=inputs[0].host)
''' 6 -执行inference,do_inference函数会返回一个list类型,此处只有一个元素 '''
[output] = do_inference(context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream)
pred = np.argmax(output)
print("Test Case: " + str(case_num))
print("Prediction: " + str(pred))
if __name__ == '__main__':
main()
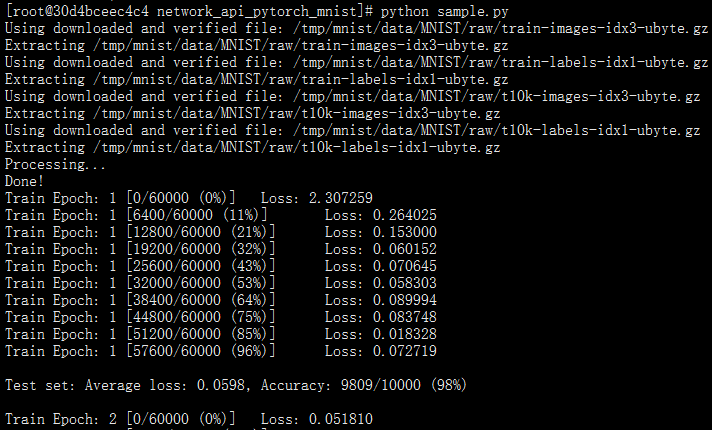
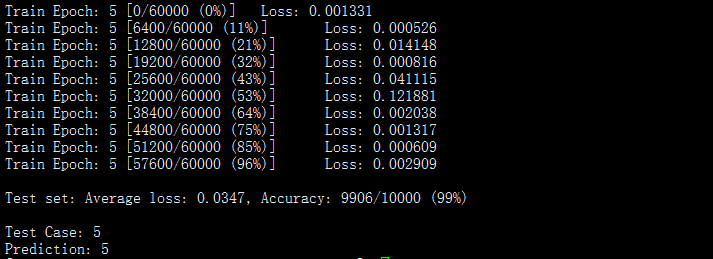
运行结果如下:
TensorRT&Sample&Python[network_api_pytorch_mnist]的更多相关文章
- TensorRT&Sample&Python[yolov3_onnx]
本文是基于TensorRT 5.0.2基础上,关于其内部的yolov3_onnx例子的分析和介绍. 本例子展示一个完整的ONNX的pipline,在tensorrt 5.0的ONNX-TensorRT ...
- TensorRT&Sample&Python[uff_custom_plugin]
本文是基于TensorRT 5.0.2基础上,关于其内部的uff_custom_plugin例子的分析和介绍. 本例子展示如何使用cpp基于tensorrt python绑定和UFF解析器进行编写pl ...
- TensorRT&Sample&Python[fc_plugin_caffe_mnist]
本文是基于TensorRT 5.0.2基础上,关于其内部的fc_plugin_caffe_mnist例子的分析和介绍. 本例子相较于前面例子的不同在于,其还包含cpp代码,且此时依赖项还挺多.该例子展 ...
- TensorRT&Sample&Python[end_to_end_tensorflow_mnist]
本文是基于TensorRT 5.0.2基础上,关于其内部的end_to_end_tensorflow_mnist例子的分析和介绍. 1 引言 假设当前路径为: TensorRT-5.0.2.6/sam ...
- TensorRT&Sample&Python[introductory_parser_samples]
本文是基于TensorRT 5.0.2基础上,关于其内部的introductory_parser_samples例子的分析和介绍. 1 引言 假设当前路径为: TensorRT-5.0.2.6/sam ...
- tensorRT使用python进行网络定义
- Python API vs C++ API of TensorRT
Python API vs C++ API of TensorRT 本质上,C++ API和Python API应该在支持您的需求方面接近相同.pythonapi的主要优点是数据预处理和后处理都很容易 ...
- (原)pytorch中使用TensorRT
转载请注明出处: https://www.cnblogs.com/darkknightzh/p/11332155.html 代码网址: https://github.com/darkknightzh/ ...
- 基于TensorRT 3的自动驾驶快速INT8推理
基于TensorRT 3的自动驾驶快速INT8推理 Fast INT8 Inference for Autonomous Vehicles with TensorRT 3 自主驾驶需要安全性,需要一种 ...
随机推荐
- 补习系列(4)-springboot 参数校验详解
目录 目标 一.PathVariable 校验 二.方法参数校验 三.表单对象校验 四.RequestBody 校验 五.自定义校验规则 六.异常拦截器 参考文档 目标 对于几种常见的入参方式,了解如 ...
- [六] 函数式接口的复合方法示例 predicate 谓词逻辑运算 Function接口 组合运算 比较器 逆序 比较链
复合的方法 有些函数式接口提供了允许复合的方法 也就是可以将Lambda表达式复合成为一个更加复杂的方法 之前的章节中有说到: 接口中的compose, andThen, and, or, negat ...
- SmoOne——开源免费的企业移动OA应用,基于.Net
一.SmoOne是什么一个开源的移动OA应用 二.语言C# 三.开发环境Visual Studio 四.开发平台Smobiler Designer 五.功能该应用开源代码中包含注册.登录.用户信息等基 ...
- [前端]AngularJS 簡易物件修改入門
各位好,今天要來介紹如何簡單的修改網站上AngularJS相關Application的內容 進而做到某些效果.(警告!所有的Web Application都應該在後端加上相關驗證) 透過本篇你可以簡單 ...
- Jquery 强大的表单验证操作
参考资料: 1.https://www.cnblogs.com/linjiqin/p/3431835.html(此篇最佳) 2.https://blog.csdn.net/pengjunlee/art ...
- [日常] nginx的错误日志error_log设置
nginx error_log设置1.error_log syslog:server=192.168.1.1 [级别] //直接发送给远程syslog日志集中服务器2.error_log stderr ...
- MySql 双主多从配置指导
MySql 双主多从配置指导 一.背景 互联网项目为了数据的可靠性和架构的可拓展性经常会用到双主多从的数据库,来实现数据的备份.负载均衡和突发状况时数据库切换. 二.思路 配置两台数据库A.B互为主从 ...
- JS 关于 bind ,call,apply 和arguments p8
关于这3个货,网上有很多文章介绍,我这边还是记录下并加上自己的理解,还有arguments函数内置对象顺便也记录下: 简单的说apply和call 会绑定第一个参数的作用域给调用函数对象实例,并会执行 ...
- git push origin与git push -u origin master的区别
$ git push origin 上面命令表示,将当前分支推送到origin主机的对应分支. 如果当前分支只有一个追踪分支,那么主机名都可以省略. $ git push 如果当前分支与多个主机存在追 ...
- [JS设计模式]:构造函数模式(2)
基本用法 function Car(model, year, miles) { this.model = model; this.year = year; this.miles = miles; th ...