Spark内部执行机制
Spark内部执行机制
1.1 内部执行流程
如下图1为分布式集群上spark应用程序的一般执行框架。主要由sparkcontext(spark上下文)、cluster manager(资源管理器)和▪executor(单个节点的执行进程)。其中cluster manager负责整个集群的统一资源管理。executor是应用执行的主要进程,内部含有多个task线程以及内存空间。

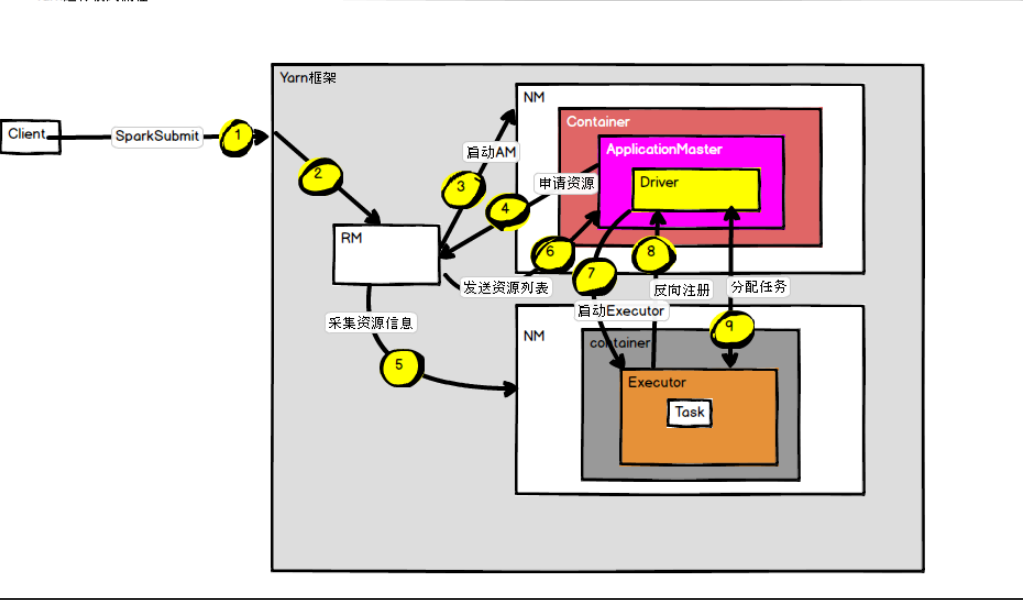
详细流程图如下图2:

- (1) 应用程序在使用spark-submit提交后,根据提交时的参数设置(deploy mode)在相应位置初始化sparkcontext,即spark的运行环境,并创建DAG Scheduler和Task Scheduer,Driver根据应用程序执行代码,将整个程序根据action算子划分成多个job,每个job内部构建DAG图,DAG Scheduler将DAG图划分为多个stage,同时每个stage内部划分为多个task,DAG Scheduler将taskset传给Task Scheduer,Task Scheduer负责集群上task的调度。至于stage和task的关系以及是如何划分的我们后面再详细讲。
- (2) Driver根据sparkcontext中的资源需求向resource manager申请资源,包括executor数及内存资源。
- (3) 资源管理器收到请求后在满足条件的work node节点上创建executor进程。
- (4) Executor创建完成后会向driver反向注册,以便driver可以分配task给他执行。
- (5) 当程序执行完后,driver向resource manager注销所申请的资源。
下面这张图更好理解:
1.2 job、stage、task的关系
Job、stage和task是spark任务执行流程中的三个基本单位。其中job是最大的单位,Job是spark应用的action算子催生的;stage是由job拆分,在单个job内是根据shuffle算子来拆分stage的,单个stage内部可根据操作数据的分区数划分成多个task。如下图3所示

2. RDD 的执行流程
上一节我们介绍了spark应用程序的大概执行流程,由于spark应用程序中的数据块基本都是RDD,本节我们来看下应用程序中RDD的执行流程。
2.1 RDD 从创建到执行
RDD从创建到执行的流程如下图4所示

- (1) 首先针对一段应用代码,driver会以action算子为边界生成响应的DAG图
- (2) DAG Scheduler从DAG图的末端开始,以图中的shuffle算子为边界来划分stage,stage划分完成后,将每个stage划分为多个task,DAG Scheduler将taskSet传给Task Scheduler来调用
- (3) Task Scheduler根据一定的调度算法,将接收到的task池中的task分给work node节点中的executor执行
这里我们看到RDD的执行流程中,DAG Scheduler和Task Scheduler起到非常关键的作用个,因此下面我们来看下DAG Scheduer和Task Scheduler的工作流程。
2.2 DAG Scheduler工作流程
DAG Scheduler是一个高级的scheduler 层,他实现了基于stage的调度,他为每一个job划分stage,并将单个stage分成多个task,然后他会将stage作为taskSet提交给底层的Task Scheduler,由Task Scheduler执行。
DAG的工作原理如下图5:

针对左边的一段代码,DAG Scheduler根据collect(action算子)将其划分到一个job中,在此job内部,划分stage,如上右图所示。DAG Scheduler在DAG图中从末端开始查找shuffle算子,上图中将reduceByKey为stage的分界,shuffle算子只有一个,因此分成两个stage。前一个stage中,RDD在map完成以后执行shuffle write将结果写到内存或磁盘上,后一个stage首先执行shuffle read读取数据在执行reduceByKey,即shuffle操作。
2.3 TASK Scheduler工作流程
Task Scheduler是sparkContext中除了DAG Scheduler的另一个非常重要的调度器,task Scheduler负责将DAGS cheduer产生的task调度到executor中执行。如下图6所示,Task Scheduler 负责将TaskSetPool中的task调度到executor中执行,一般的调度模式是FIFO(先进先出),也可以按照FAIR(公平调度)的调度模式,具体根据配置而定。其中FIFO:顾名思义是先进先出队列的调度模式,而FAIR则是根据权重来判断,权重可以根据资源的占用率来分,如可设占用较少资源的task的权重较高。这样就可以在资源较少时,调用后来的权重较高的task先执行了。至于每个executor中同时执行的task数则是由分配给每个executor中cpu的核数决定的。

Spark内部执行机制的更多相关文章
- 【JS】JavaScript引擎的内部执行机制
近期在复习JavaScript,看到setTimeout函数时.想起曾经刚学时,在一本书上看过setTimeout()里的回调函数执行的间隔时间有昌不是后面设置的值.曾经没想太多.网上看了JS大 ...
- 【Spark 深入学习 04】再说Spark底层运行机制
本节内容 · spark底层执行机制 · 细说RDD构建过程 · Job Stage的划分算法 · Task最佳计算位置算法 一.spark底层执行机制 对于Spark底层的运行原理,找到了一副很好的 ...
- 2.Spark Streaming运行机制和架构
1 解密Spark Streaming运行机制 上节课我们谈到了技术界的寻龙点穴.这就像过去的风水一样,每个领域都有自己的龙脉,Spark就是龙脉之所在,它的龙穴或者关键点就是SparkStreami ...
- 探索JavaScript执行机制
前言 不论是工作还是面试,我们可能都经常会碰到需要知道代码的执行顺序的场景,所以打算花点时间彻底搞懂JavaScript的执行机制. 如果这篇文章有帮助到你,️关注+点赞️鼓励一下作者,文章公众号首发 ...
- IIS 内部运行机制及Asp.Net执行过程详解
一直以来对一个Asp.net页面穿过IIS后就返回给浏览器一个HTML页面感觉很是神奇.虽然做技术这么长时间了,也曾经大致了解过一点来龙去脉,但是如果你真的问起我比较详细的过程,我还真的回答不上来,好 ...
- 通过案例对 spark streaming 透彻理解三板斧之三:spark streaming运行机制与架构
本期内容: 1. Spark Streaming Job架构与运行机制 2. Spark Streaming 容错架构与运行机制 事实上时间是不存在的,是由人的感官系统感觉时间的存在而已,是一种虚幻的 ...
- 通过案例对 spark streaming 透彻理解三板斧之二:spark streaming运行机制
本期内容: 1. Spark Streaming架构 2. Spark Streaming运行机制 Spark大数据分析框架的核心部件: spark Core.spark Streaming流计算. ...
- Spark内存管理机制
Spark内存管理机制 Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色.理解 Spark 内存管理的基本原理,有助于更好地开发 Spark 应用程序和进行 ...
- 深入浅出Spark的Checkpoint机制
1 Overview 当第一次碰到 Spark,尤其是 Checkpoint 的时候难免有点一脸懵逼,不禁要问,Checkpoint 到底是什么.所以,当我们在说 Checkpoint 的时候,我们到 ...
随机推荐
- 一个老鸟发的公司内部整理的 Android 学习路线图
基础工具部分: 中文手册,我猜测是Maven中文手册,可是我并没有找到这样的资源,欢迎知道的朋友告诉我: Android部分有 『第三方库集合』,我没能找到资源地址: 书籍我大多是给的豆瓣链接,如果觉 ...
- Redis 简介与命令操作
redis 是 key-value 的数据,所以每个数据都是一个键值对,键的类型是字符串: 值的类型分为五种:string.hash.list.set(集合).zset(有序集合). 数据操作的全部命 ...
- error while loading shared libraries: libopencv_core.so.3.4: cannot open shared object file: No such file or directory
1. 将CMakeLists.txt 文件中 find_package(OpenCV REQURED)补充完整为带版本号的:find_package(OpenCV 2.4.9 REQURED) 2. ...
- 切换npm源地址
全局安装nrm (npm源管理工具) npm install -g nrm 查看所有的源地址 * 代表当前的源地址 nrm ls * npm ----- https://registry.npmj ...
- 基于Spring注解搭建SpringMVC项目
在2018寒冬,我下岗了,因为我的左脚先迈进了公司的大门.这不是重点,重点是我扑到了老板小姨子的怀里. 网上好多教程都是基于XML的SpringMVC,想找一篇注解的,但是写的很模糊,我刚好学到这里, ...
- AES加密解密算法
class Aes { /** * AES加密 * @param $data * @param $secret_key * @return string */ public static functi ...
- go语言实现生产者-消费者
前言: 之前在学习操作系统的时候,就知道生产者-消费者,但是概念是模模糊糊的,好像是一直没搞明白. 其实很简单嘛,生产者生产,消费者进行消费,就是如此简单.了解了一下go语言的goroute,感觉实现 ...
- CentOS下MySQL安装失败,报socket '/tmp/mysql.sock错误解决方法
1.在centos里安装mysql数据库后,登录时提示‘/tmp/mysql.sock’ 第一种解决办法:采用ln链接方式进行处理 ln -s /var/lib/mysql/mysql.sock /t ...
- vue环境下新建项目
1.之前电脑上安装了node和npm,查看下版本信息. 2.现在安装vue-cli脚手架,可以全局安装: npm install --global vue-cli 之前自己电脑没有安装过webpac ...
- selenium+python自动化测试,上传文件怎样实现
其实上传图片操作与输入框的输入是一样的,一种是在输入框中输入字符信息,一种是在输入文件格式的信息,下面是用代码实现上传文件, from selenium import webdriverfrom ti ...