Elasticsearch学习笔记(十一)Mapping原理
一、Mapping的功能作用
Mapping是定义如何存储和索引一个document及其所包含字段的过程。
Mapping是index和type的元数据,每个type都有自己的一个mapping,决定了字段的数据类型和建立倒排索引的行为以及搜索的行为。mapping设置字段的数据类型的时候也设置了该字段是否为exact value还是full text
Elasticsearch将值分为exact value和full text。
exact value: ,在建立倒排索引的时候,分词的时候,是将整个值一起作为一个关键词建立到倒排索引中的。当针对exact value的字段进行搜索的时候用bool布尔值进行判断
full text:会经历各种各样的处理,分词,normaliztion(时态转换,同义词转换,大小写转换),才会建立到倒排索引中,当针对full value的字段进行搜索的时候,需要计算相关度评分
exact value和full text类型的field就决定了,在一个搜索过来的时候,对exact value field或者是full text field进行搜索的行为也是不一样的,会跟建立倒排索引的行为保持一致;比如说exact value搜索的时候,就是直接按照整个值进行匹配,full text query string,也会进行分词和normalization再去倒排索引中去搜索
1、Mapping Type(ES 7.0将移除)
每个索引都有一个mapping类型以决定document如何被索引,也就是定义了一个document的索引规则
一个mapping type包括:
(1)Meta-fields:
Meta-fields被用于自定义如何处理关联的document元数据。
例如:meta-fields包括document的_index,_type,_id,_source等字段
(2) Fields/Properties:
mapping type包括与document相关的字段或属性列表
每个document都有一个_type元字段包含了type的名称。_type字段联合document的_id字段生成_uid字段。所以带有相同_id但是type不同的document可以存在同一个索引内。
ES7.0移除mapping type的原因:
(1)index类比为数据库中一个库,type类比为数据库中的一个表。但是数据库中两个不同的表中,相同名称的字段是没有关系。但是,在Elasticsearch的索引中不同的mapping type的同一个相同名称的字段都是由同一个Lucense字段提供支持。也就说,两个不同mapping type的相同名称的字段都保存在同一个Lucence字段中,而且这两个字段必须是同一个类型的数据(比如通知为date类型的数据)
(2)同一个索引中存储少量字段和没有字段的不同的实体存储会导致稀疏数据,从而干扰Lucence有效压缩document的能力
一种可选的操作是一个index下只有一个type。
2、字段数据类型(Field datatypes)
(1)每个字段都有自己的数据类型,可以是:
1)一个简单的类型,就像text,keyword,data,long,double,boolean或者ip
2)一种支持JSON的层次结构特性的类型(就像对象或嵌套)
3)或者有专门用途的类型像geo_point,geo_shape海阔卓completion
一个string字段可以被索引成全文搜索的text字段并作为排序或者聚合的keyword字段,这么做的目的是多字段。大部分数据类型通过fields参数都可以支持多字段。
3、设置防止mapping激增
索引中定义太多的字段可能会导致mapping的激增,从而引起内存的错误和难以恢复的情况。这个问题可能比预期的更新普遍。例如:如果如果每个新的document被插入同时引入新的字段,这个在动态mapping里面十分普遍。每当document里面包含新的字段,这些将结束于索引的映射.如果数据量很少的话,这些都不用担心,但是这个会成为一个mapping增长的问题。通过相关设置可以限制mapping手动或者动态创建的字段数量,以防止mapping的激增。
index.mapping.total_fields.limit :一个索引包含字段的最大数量,默认为1000
index.mapping.depth.limit: 设置一个字段的最大深度,表示字段可以包含的内部对象的数量,默认为20
index.mapping.nested_fields.limit:设置一个索引嵌套字段的最大数量,默认我50 。索引一个包含100个嵌套字段的文档实际上索引了101个文档,因为每个嵌套的文档被索引为一个单独的隐藏文档。
4、动态映射(Dynamic mapping)
字段和mapping类型在索引使用之前不需要事先定义。由于动态mapping,新增字段名称可以被自动添加,仅仅通过索引一个document。新字段可以被添加到顶级的mapping type中和内部的对象和嵌套的字段当中.
动态映射规则可以被配置以自定义用于新字段的映射过程
例如:
true or false --> boolean
123 --> long
123.45 --> double
2017-01-01 --> date
"hello world" --> string/text
5、精确映射(Explicit mapping)
我们对自己的数据要比Elasticsearch猜测更清楚多,及时刚开始的时候动态映射可以被充分使用,当时在某些时候我们想要指定我们自己的精确映射。
当创建一个索引的时候,可以创建字段映射,并且通过PUT mapping API可以给已经存在的索引添加新的字段。
6、更新存在的字段映射(field mappings)
除了文档记录之外,已经存在的字段映射field mappings不能够被修改。如果改变这些mapping就意味着已经被索引的document将失效。相反,可以创建正确的mapping的索引并且重新索引数据到当前的新索引。
只能创建index时手动建立mapping,或者新增field mapping,但是不能update field mapping
例如:
curl -XPUT 'localhost:9200/my_index?pretty' -H 'Content-Type: application/json' -d'
//添加一个索引:my_index
{
"mappings": {
"doc": { //添加一个mapping type:doc
"properties": {
"title": { //指定字段或属性
"type": "text" // 指定每个字段的数据类型和mapping
},
"name": { "type": "text" },
"age": { "type": "integer" },
"created": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
}
}
}
}
}
PUT /website/_mapping/article
{
"properties" : {
"new_field" : {
"type" : "string",
"index": "not_analyzed"
}
}
}
7、查看mapping
GET /index/_mapping/type
测试mapping
GET /website/_analyze
{
"field": "content",
"text": "my-dogs"
}
二、Mapping的工作机制
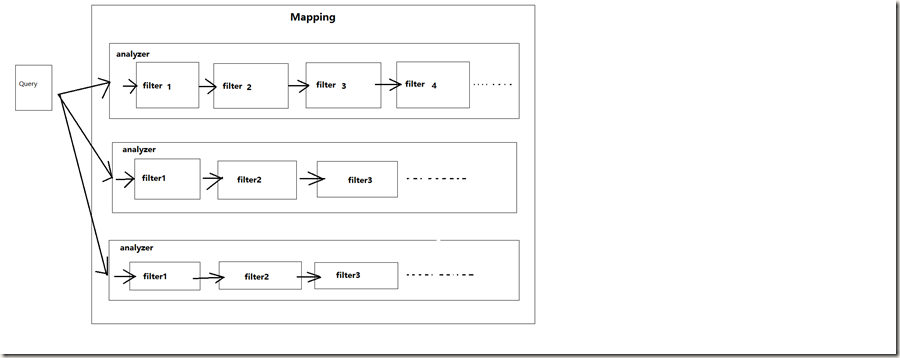
每个mapping有一至多个analyzer构成,每个analyzer由一至多个顺序排列的filter组成。在进行搜索文档的时候,将字段内存传给相应的analyzer处理。analyzer内部根据filter顺序依次进行处理
三、自定义Dynamic mapping
1、定制dynamic策略
true:遇到陌生字段,就进行dynamic mapping
false:遇到陌生字段,就忽略
strict:遇到陌生字段,就报错
PUT /my_index
{
"mappings": {
"my_type": {
"dynamic": "strict",
"properties": {
"title": {
"type": "text"
},
"address": {
"type": "object",
"dynamic": "true"
}
}
}
}
}
测试1:
PUT /my_index/my_type/1
{ // dynamic:strict
"title": "my article",
"content": "this is my article", //新增字段
"address": { // dynamic:true
"province": "guangdong",
"city": "guangzhou"
}
}
{
"error": {
"root_cause": [
{
"type": "strict_dynamic_mapping_exception",
"reason": "mapping set to strict, dynamic introduction of [content] within [my_type] is not allowed"
}
],
"type": "strict_dynamic_mapping_exception",
"reason": "mapping set to strict, dynamic introduction of [content] within [my_type] is not allowed"
},
"status": 400
}
测试2:
PUT /my_index/my_type/1
{
"title": "my article",
"address": {
"province": "guangdong",
"city": "guangzhou"
}
}
GET /my_index/_mapping/my_type
{
"my_index": {
"mappings": {
"my_type": {
"dynamic": "strict",
"properties": {
"address": {
"dynamic": "true",
"properties": {
"city": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"province": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"title": {
"type": "text"
}
}
}
}
}
}
2、定制dynamic mapping策略
(1)date_detection
默认会按照一定格式识别date,比如yyyy-MM-dd。但是如果某个field先过来一个2017-01-01的值,就会被自动dynamic mapping成date,后面如果再来一个"hello world"之类的值,就会报错。可以手动关闭某个type的date_detection,如果有需要,自己手动指定某个field为date类型。
PUT /my_index/_mapping/my_type
{
"date_detection": false
}
(2)定制自己的dynamic mapping template(type level)
PUT /my_index
{
"mappings": {
"my_type": {
"dynamic_templates": [
{ "en": {
"match": "*_en",
"match_mapping_type": "string",
"mapping": {
"type": "string",
"analyzer": "english"
}
}}
]
}}}
1)测试1:
PUT /my_index/my_type/1
{
"title": "this is my first article"
}
title没有匹配到任何的dynamic模板,默认就是standard分词器,不会过滤停用词,is会进入倒排索引,用is来搜索是可以搜索到的
2)测试2:
PUT /my_index/my_type/2
{
"title_en": "this is my first article"
}
title_en匹配到了dynamic模板,就是english分词器,会过滤停用词,is这种停用词就会被过滤掉,用is来搜索就搜索不到了
(3)定制自己的default mapping template(index level)
PUT /my_index
{
"mappings": {
"_default_": {
"_all": { "enabled": false }
},
"blog": {
"_all": { "enabled": true }
}
}
}
Elasticsearch学习笔记(十一)Mapping原理的更多相关文章
- SQLite学习笔记(十一)&&虚拟机原理
前言 我们知道任何一种关系型数据库管理系统都支持SQL(Structured Query Language),相对于文件管理系统,用户不用关心数据在数据库内部如何存取,也不需要知道底层的存储 ...
- elasticsearch学习笔记——相关插件和使用场景
logstash-input-jdbc学习 ES(elasticsearch缩写)的一大优点就是开源,插件众多.所以扩展起来非常的方便,这也造成了它的生态系统越来越强大.这种开源分享的思想真是与天朝格 ...
- Elasticsearch学习笔记一
Elasticsearch Elasticsearch(以下简称ES)是一款Java语言开发的基于Lucene的高效全文搜索引擎.它提供了一个分布式多用户能力的基于RESTful web接口的全文搜索 ...
- 机器学习实战(Machine Learning in Action)学习笔记————03.决策树原理、源码解析及测试
机器学习实战(Machine Learning in Action)学习笔记————03.决策树原理.源码解析及测试 关键字:决策树.python.源码解析.测试作者:米仓山下时间:2018-10-2 ...
- python3.4学习笔记(十一) 列表、数组实例
python3.4学习笔记(十一) 列表.数组实例 #python列表,数组类型要相同,python不需要指定数据类型,可以把各种类型打包进去#python列表可以包含整数,浮点数,字符串,对象#创建 ...
- Go语言学习笔记十一: 切片(slice)
Go语言学习笔记十一: 切片(slice) 切片这个概念我是从python语言中学到的,当时感觉这个东西真的比较好用.不像java语言写起来就比较繁琐.不过我觉得未来java语法也会支持的. 定义切片 ...
- ElasticSearch学习笔记(超详细)
文章目录 初识ElasticSearch 什么是ElasticSearch ElasticSearch特点 ElasticSearch用途 ElasticSearch底层实现 ElasticSearc ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- Sqlite学习笔记(四)&&SQLite-WAL原理
Sqlite学习笔记(三)&&WAL性能测试中列出了几种典型场景下WAL的性能数据,了解到WAL确实有性能优势,这篇文章将会详细分析WAL的原理,做到知其然,更要知其所以然. WAL是 ...
- Sqlite学习笔记(四)&&SQLite-WAL原理(转)
Sqlite学习笔记(三)&&WAL性能测试中列出了几种典型场景下WAL的性能数据,了解到WAL确实有性能优势,这篇文章将会详细分析WAL的原理,做到知其然,更要知其所以然. WAL是 ...
随机推荐
- 【原创】大叔经验分享(28)ELK分析nginx日志
提前安装好elk(elasticsearch.logstach.kibana) 一 启动logstash $LOGSTASH_HOME默认位于/usr/share/logstash或/opt/logs ...
- C#+EntityFramework编程方式详细之Code First
Code First Code First模式即“代码优先”模式,是从EF4.1开始新建加入的功能.使用Code First模式进行EF开发时只需要编写对应的数据类,然后自动生成数据库. Code F ...
- 如何新建PDF文档,新建PDF文档的方法
新建PDF文件的话,有两种方式,一种是直接通过使用PDF编辑器http://bianji.xjpdf.com/来新建PDF文件,,还有一种就是将PDF文件转换成Word文件,然后在Word文件中添加, ...
- 四.property
将一个类的函数定义成特性以后,对象再去使用的时候obj.name,根本无法察觉自己的name是执行了一个函数然后计算出来的,这种特性的使用方式遵循了统一访问的原则 # 例一:BMI指数(bmi是计算而 ...
- 金蝶k/3 K3云之家消息查询发送是否成功SQL语句
金蝶k/3 K3云之家消息查询发送是否成功SQL语句 1是成功,0是还在轮询中未发送,4是发送失败 select * into #tempUserID from ( union select t_Gr ...
- Spring Boot整合邮件发送
概述 Spring Boot下面整合了邮件服务器,使用Spring Boot能够轻松实现邮件发送:整理下最近使用Spring Boot发送邮件和注意事项: Maven包依赖 <dependenc ...
- php memcached-gui工具
转载: https://github.com/mailopl/memcached-gui/blob/master/memcached.php 适用于在服务端查看memcache内存数据 php代码: ...
- js分析 快速定位 js 代码, 还原被混淆压缩的 js 代码
-1.目录 0.参考 1.页面表现 2. 慢镜头观察:低速网络请求 3. 从头到尾调试:Fiddler 拦截 index.html 并添加 debugger; 4. 快速定位 js 代码 5. 还原被 ...
- C#使用FileSystemWatcher控件实现的文件监控功能示例
本文实例讲述了C#使用FileSystemWatcher控件实现的文件监控功能.分享给大家供大家参考,具体如下: FileSystemWatcher 可以使用FileSystemWatcher组件监视 ...
- 识别拖动与点击操作之zepto的bug
问题描述:给页面<a>标签绑定了tap事件,在移动设备上点击按钮貌似一切正常,可以响应.但是,把页面上下滑动几次之后,或者在滑动时手指滑动出移动屏幕之外,之后再点击按钮,就会发现第一次点击 ...