MapReduce编程:数字排序
问题描述
将乱序数字按照升序排序。

思路描述
按照mapreduce的默认排序,依次输出key值。
代码
package org.apache.hadoop.examples; import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class sort {
public sort() {
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); String fileAddress = "hdfs://localhost:9000/user/hadoop/"; //String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
String[] otherArgs = new String[]{fileAddress+"number.txt", fileAddress+"output"};
if(otherArgs.length < 2) {
System.err.println("Usage: sort <in> [<in>...] <out>");
System.exit(2);
} Job job = Job.getInstance(conf, "sort");
job.setJarByClass(sort.class);
job.setMapperClass(sort.TokenizerMapper.class);
//job.setCombinerClass(sort.SortReducer.class);
job.setReducerClass(sort.SortReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class); for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
} FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
} public static class TokenizerMapper extends Mapper<Object, Text, IntWritable, IntWritable> { public TokenizerMapper() {
} public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString()); while(itr.hasMoreTokens()) {
context.write(new IntWritable(Integer.parseInt(itr.nextToken())), new IntWritable(1));
} }
} public static class SortReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable> { private static IntWritable num = new IntWritable(1); public SortReducer() {
} public void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { for(Iterator<IntWritable> i$ = values.iterator(); i$.hasNext();i$.next()) {
context.write(num, key);
}
num = new IntWritable(num.get()+1);
}
} }

注:不能有combiner操作。
不然就会变成
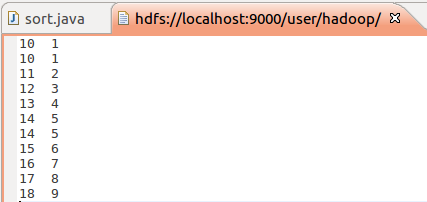
MapReduce编程:数字排序的更多相关文章
- 【原创】MapReduce编程系列之二元排序
普通排序实现 普通排序的实现利用了按姓名的排序,调用了默认的对key的HashPartition函数来实现数据的分组.partition操作之后写入磁盘时会对数据进行排序操作(对一个分区内的数据作排序 ...
- Hadoop MapReduce编程学习
一直在搞spark,也没时间弄hadoop,不过Hadoop基本的编程我觉得我还是要会吧,看到一篇不错的文章,不过应该应用于hadoop2.0以前,因为代码中有 conf.set("map ...
- hadoop2.2编程:使用MapReduce编程实例(转)
原文链接:http://www.cnblogs.com/xia520pi/archive/2012/06/04/2534533.html 从网上搜到的一篇hadoop的编程实例,对于初学者真是帮助太大 ...
- MapReduce编程基础
MapReduce编程基础 1. WordCount示例及MapReduce程序框架 2. MapReduce程序执行流程 3. 深入学习MapReduce编程(1) 4. 参考资料及代码下载 & ...
- MapReduce编程模型及其在Hadoop上的实现
转自:https://www.zybuluo.com/frank-shaw/note/206604 MapReduce基本过程 关于MapReduce中数据流的传输过程,下图是一个经典演示: 关于上 ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- 基于Hadoop 2.6.0运行数字排序的计算
上个博客写了Hadoop2.6.0的环境部署,下面写一个简单的基于数字排序的小程序,真正实现分布式的计算,原理就是对多个文件中的数字进行排序,每个文件中每个数字占一行,排序原理是按行读取后分块进行排序 ...
- [Hadoop入门] - 1 Ubuntu系统 Hadoop介绍 MapReduce编程思想
Ubuntu系统 (我用到版本号是140.4) ubuntu系统是一个以桌面应用为主的Linux操作系统,Ubuntu基于Debian发行版和GNOME桌面环境.Ubuntu的目标在于为一般用户提供一 ...
- mapreduce编程模型你知道多少?
上次新霸哥给大家介绍了一些hadoop的相关知识,发现大家对hadoop有了一定的了解,但是还有很多的朋友对mapreduce很模糊,下面新霸哥将带你共同学习mapreduce编程模型. mapred ...
随机推荐
- python练习题-day26
#bim(property) class People: def __init__(self,name,weight,height): self.name=name self.weight=weigh ...
- redis集群及相关的使用
从redis 3.0之后版本支持redis-cluster集群,Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接. 1.所有的redis节点彼此互 ...
- vue中loding
<template> <div class="mf-loading-container" v-show="ifShow"> <im ...
- Linux安装常见问题
目录 1. SSL connect error 2. ERROR: certificate error 1. SSL connect error # fatal: unable to access ' ...
- office word memo
显示左侧目录树 office 和 wps 的差异 wps 的版本:视窗 ->文档结构图 office 的版本: 视图 ->导航窗格
- 使用datagrid时json的格式
EasyUI的DataGrid要求返回的JSON数据集是这样的形式: {"total":总记录数量,"rows":[数据记录数组]}. 例如: {"t ...
- 北京大学Cousera学习笔记--7-计算导论与C语言基础--基本数据类型&变量&常量
1.整形数据 1.基本型(int 4B).短整型(short 2B).长整型(long 4B) VC环境下 sizeof运算符用于计算某种类型的对象在内存中所占的字节数 ,用法:size(int) ...
- web前端设计最好用的工具
一.FSCapture FastStone Capture(FSCapture)是经典好用的屏幕截图软件,还具有图像编辑和屏幕录制两大功能,可以捕捉全屏图像,或者活动窗口.窗口内的控件对象截图.支持手 ...
- kendo upload必填验证
@using Kendo.Mvc.UI @using StudentManage.Common.Helper @model StudentManage.Models.Home.ImportDataFr ...
- codeforces-4
这题使用到了类似于双数据 Maximal Continuous #include<iostream> #include<algorithm> #include<stdio ...