小师妹学JVM之:逃逸分析和TLAB
简介
逃逸分析我们在JDK14中JVM的性能优化一文中已经讲过了,逃逸分析的结果就是JVM会在栈上分配对象,从而提升效率。如果我们在多线程的环境中,如何提升内存的分配效率呢?快来跟小师妹一起学习TLAB技术吧。
逃逸分析和栈上分配
小师妹:F师兄,从前大家都说对象是在堆中分配的,然后我就信了。上次你居然说可以在栈上分配对象,这个实在是颠覆了我一贯的认知啊。
柏拉图说过:思想永远是宇宙的统治者。只要思想不滑坡,办法总比困难多。别人告诉你的都是一些最基本,最最通用的情况。而师兄我告诉你的则是在优化中的特列情况。
小师妹:F师兄,看起来JVM在提升运行速度方面真的做了不少优化呀。
是呀,Java从最开始被诟病速度慢,到现在执行速度直追C语言。这些运行时优化是必不可少的。还记得我们之前讲的逃逸分析是怎么回事吗?
小师妹:F师兄,这个我知道,如果一个对象的分配是在方法内部,并且没有多线程访问的情况下,那么这个对象其实可以看做是一个本地对象,这样的对象不管创建在哪里都只对本线程中的本方法可见,因此可以直接分配在栈空间中。
对的,栈上分配的对象因为不用考虑同步,所以执行速度肯定会更加快速,这也是为什么JVM会引入栈上分配的原因。
再举一个形象直观的例子。工厂要组装一辆汽车,在buildCar的过程中,需要先创建一个Car对象,然后给它按上轮子。
public static void main(String[] args) {
buildCar();
}
public static void buildCar() {
Wheel whell = new Wheel(); //分配轮子
Car car = new Car(); //分配车子
car.setWheel(whell);
}
}
class Wheel {}
class Car {
private Wheel whell;
public void setWheel(Wheel whell) {
this.whell = whell;
}
}
考虑一下上面的情况,如果假设该车间是一个机器人组装一台车,那么上面方法中创建的Car和Wheel对象,其实只会被这一个机器人访问,其他的机器人根本就不会用到这个车的对象。那么这个对象本质上是对其他机器人隐形的。所以我们可以不在公共空间分配这个对象,而是在私人的栈空间中分配。
逃逸分析还有一个作用就是lock coarsening。同样的,单线程环境中,锁也是不需要的,也可以优化掉。
TLAB简介
小师妹:F师兄,我觉得逃逸分析很好呀,栈上分配也不错。既然又这么厉害的两项技术了,为什么还要用到TLAB呢?
首先这是两个不同的概念,TLAB的全称是Thread-Local Allocation Buffers。Thread-Local大家都知道吧,就是线程的本地变量。而TLAB则是线程的本地分配空间。
逃逸分析和栈上分配只是争对于单线程环境来说的,如果在多线程环境中,不可避免的会有多个线程同时在堆空间中分配对象的情况。
这种情况下如何处理才能提升性能呢?
小师妹:哇,多个线程竞争共享资源,这不是一个典型的锁和同步的问题吗?
锁和同步是为了保证整个资源一次只能被一个线程访问,我们现在的情况是要在资源中为线程划分一定的区域。这种操作并不需要完全的同步,因为heap空间够大,我们可以在这个空间中划分出一块一块的小区域,为每个线程都分一块。这样不就解决了同步的问题了吗?这也可以称作空间换时间。
TLAB详解
小师妹,还记得heap分代技术中的一个中心两个基本点吗?哦,1个Eden Space和2个Suvivor Space吗?
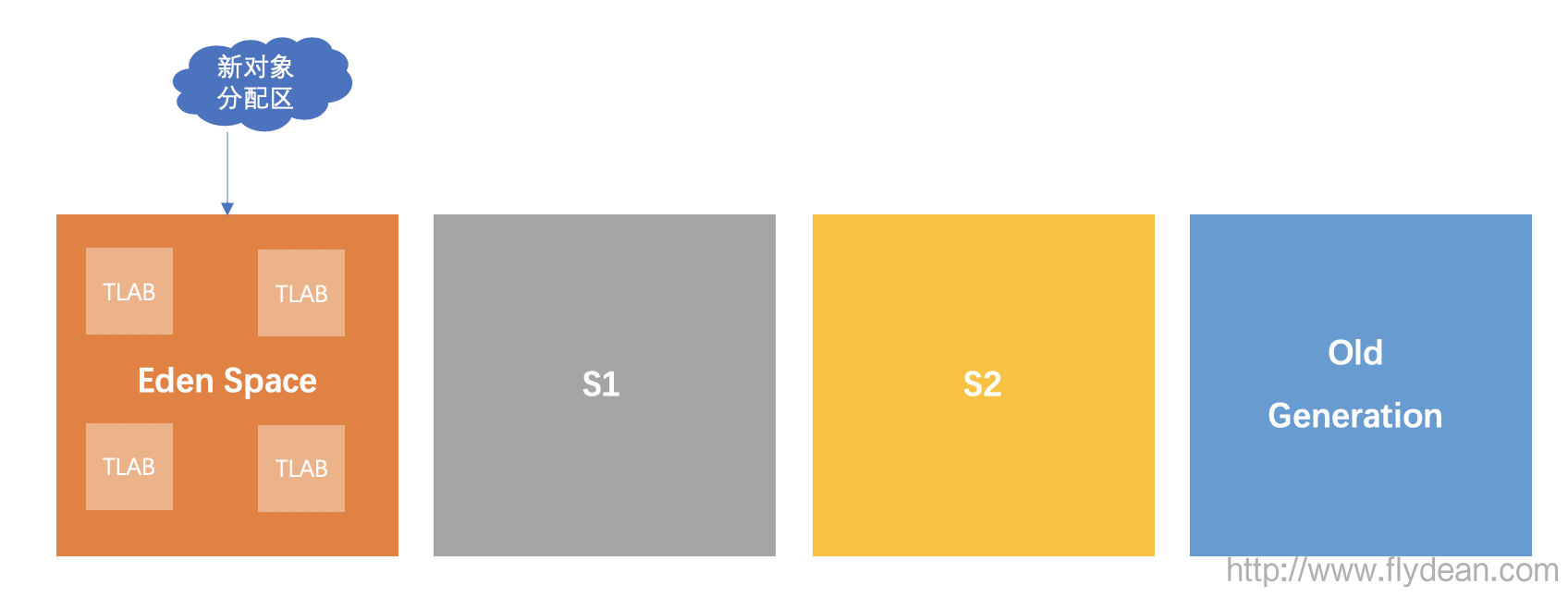
Young Gen被划分为1个Eden Space和2个Suvivor Space。当对象刚刚被创建的时候,是放在Eden space。垃圾回收的时候,会扫描Eden Space和一个Suvivor Space。如果在垃圾回收的时候发现Eden Space中的对象仍然有效,则会将其复制到另外一个Suvivor Space。
就这样不断的扫描,最后经过多次扫描发现任然有效的对象会被放入Old Gen表示其生命周期比较长,可以减少垃圾回收时间。
因为TLAB关注的是新分配的对象,所以TLAB是被分配在Eden区间的,从图上可以看到TLAB是一个一个的连续空间。
然后将这些连续的空间分配个各个线程使用。
因为每一个线程都有自己的独立空间,所以这里不涉及到同步的概念。默认情况下TLAB是开启的,你可以通过:
-XX:-UseTLAB
来关闭它。
设置TLAB空间的大小
小师妹,F师兄,这个TLAB的大小是系统默认的吗?我们可以手动控制它的大小吗?
要解决这个问题,我们还得去看JVM的C++实现,也就是threadLocalAllocBuffer.cpp:
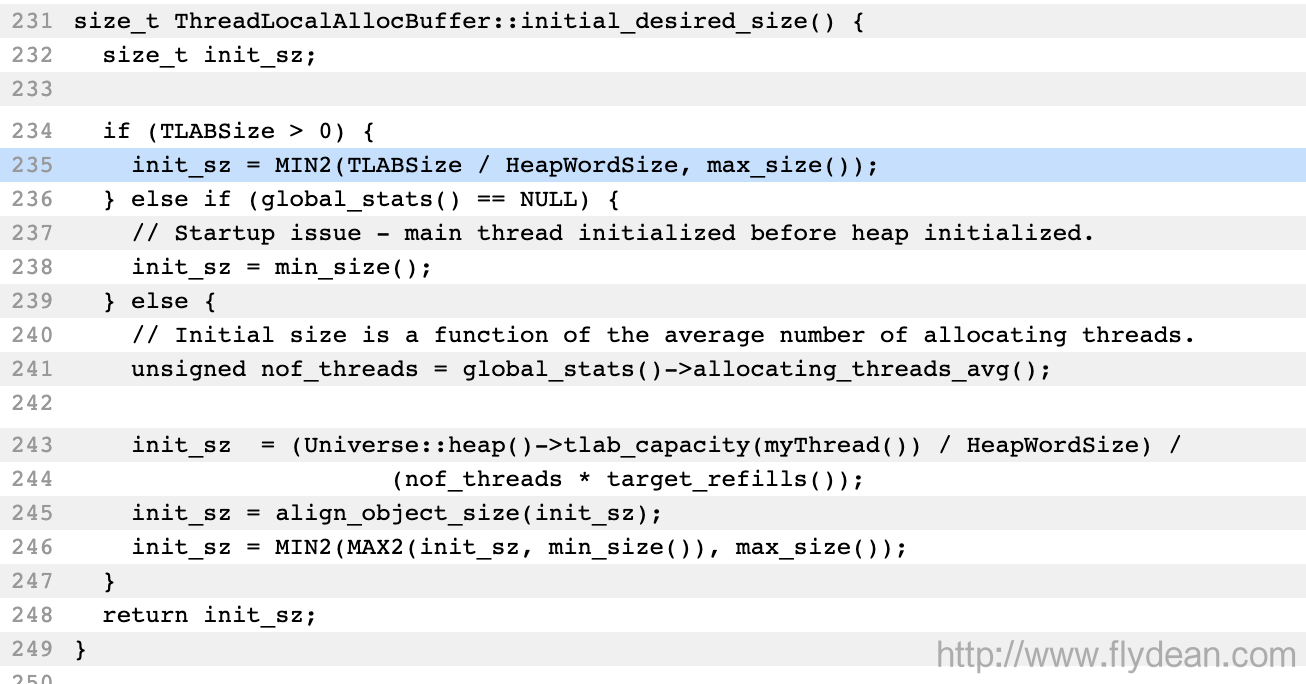
上面的代码可以看到,如果设置了TLAB(默认是0),那么TLAB的大小是定义的TLABSize除以HeapWordSize和max_size()中最小的那个。
HeapWordSize是heap中一个字的大小,我猜它=8。别问我为什么,其实我也是猜的,有人知道答案的话可以留言告诉我。
TLAB的大小可以通过:
-XX:TLABSize
来设置。
如果没有设置TLAB,那么TLAB的大小就是分配线程的平均值。
TLAB的最小值可以通过:
-XX:MinTLABSize
来设置。
默认情况下:
-XX:ResizeTLAB
resize开关是默认开启的,那么JVM可以对TLAB空间大小进行调整。
TLAB中大对象的分配
小师妹:F师兄,我想到了一个问题,既然TLAB是有大小的,如果一个线程中定义了一个非常大的对象,TLAB放不下了,该怎么办呢?
好问题,这种情况下又有两种可能性,我们假设现在的TLAB的大小是100K:
第一种可能性:
目前TLAB被使用了20K,还剩80K的大小,这时候我们创建了一个90K大小的对象,现在90K大小的对象放不进去TLAB,这时候需要直接在heap空间去分配这个对象,这种操作实际上是一种退化操作,官方叫做 slow allocation。
第二中个可能性:
目前TLAB被使用了90K,还剩10K大小,这时候我们创建了一个15K大小的对象。
这个时候就要考虑一下是否仍然进行slow allocation操作。
因为TLAB差不多已经用完了,为了保证后面new出来的对象仍然可以有一个TLAB可用,这时候JVM可以尝试将现在的TLAB Retire掉,然后分配一个新的TLAB空间,把15K的对象放进去。
JVM有个开关,叫做:
-XX:TLABWasteTargetPercent=N
这个开关的默认值是1。表示如果新分配的对象大小如果超出了设置的这个百分百,那么就会执行slow allocation。否则就会分配一个新的TLAB空间。
同时JVM还定义了一个开关:
-XX:TLABWasteIncrement=N
为了防止过多的slow allocation,JVM定义了这个开关(默认值是4),比如说第一次slow allocation的极限值是1%,那么下一次slow allocation的极限值就是%1+4%=5%。
TLAB空间中的浪费
小师妹:F师兄,如果新分配的TLAB空间,那么老的TLAB中没有使用的空间该怎么办呢?
这个叫做TLAB Waste。因为不会再在老的TLAB空间中分配对象了,所以剩余的空间就浪费了。
总结
本文介绍了逃逸分析和TLAB的使用。希望大家能够喜欢。
本文作者:flydean程序那些事
本文链接:http://www.flydean.com/jvm-escapse-tlab/
本文来源:flydean的博客
欢迎关注我的公众号:程序那些事,更多精彩等着您!
小师妹学JVM之:逃逸分析和TLAB的更多相关文章
- 小师妹学JVM之:深入理解JIT和编译优化-你看不懂系列
目录 简介 JIT编译器 Tiered Compilation分层编译 OSR(On-Stack Replacement) Deoptimization 常见的编译优化举例 Inlining内联 Br ...
- 小师妹学JVM之:JDK14中JVM的性能优化
目录 简介 String压缩 分层编译(Tiered Compilation) Code Cache分层 新的JIT编译器Graal 前置编译 压缩对象指针 Zero-Based 压缩指针 Escap ...
- 小师妹学JVM之:JIT中的LogCompilation
目录 简介 LogCompilation简介 LogCompilation的使用 解析LogCompilation文件 总结 简介 我们知道在JVM中为了加快编译速度,引入了JIT即时编译的功能.那么 ...
- 小师妹学JVM之:JIT中的PrintCompilation
目录 简介 PrintCompilation 分析PrintCompilation的结果 总结 简介 上篇文章我们讲到了JIT中的LogCompilation,将编译的日志都收集起来,存到日志文件里面 ...
- 小师妹学JVM之:java的字节码byte code简介
目录 简介 Byte Code的作用 查看Byte Code字节码 java Byte Code是怎么工作的 总结 简介 Byte Code也叫做字节码,是连接java源代码和JVM的桥梁,源代码编译 ...
- 小师妹学JVM之:JIT中的PrintAssembly
目录 简介 使用PrintAssembly 输出过滤 总结 简介 想不想了解JVM最最底层的运行机制?想不想从本质上理解java代码的执行过程?想不想对你的代码进行进一步的优化和性能提升? 如果你的回 ...
- 小师妹学JVM之:JIT中的PrintAssembly续集
目录 简介 JDK8和JDK14中的PrintAssembly JDK8中使用Assembly JDK14中的Assembly 在JMH中使用Assembly 总结 简介 上篇文章和小师妹一起介绍了P ...
- 小师妹学JVM之:cache line对代码性能的影响
目录 简介 一个奇怪的现象 两个问题的答案 CPU cache line inc 和 add 总结 简介 读万卷书不如行万里路,讲了这么多assembly和JVM的原理与优化,今天我们来点不一样的实战 ...
- 小师妹学JVM之:JVM的架构和执行过程
目录 简介 JVM是一种标准 java程序的执行顺序 JVM的架构 类加载系统 运行时数据区域 执行引擎 总结 简介 JVM也叫Java Virtual Machine,它是java程序运行的基础,负 ...
随机推荐
- DynamIQ扫盲文
综述: ARM CPU的架构都基于big.LITTLE大小核技术.而再big.LITTLE的基础上,又添加了DynamIQ.单一Cluster中可以又8个core,且支持不同架构的core,以及支持不 ...
- (Java实现) 洛谷 P1691 有重复元素的排列问题
题目描述 设R={r1,r2,--,rn}是要进行排列的n个元素.其中元素r1,r2,--,rn可能相同.使设计一个算法,列出R的所有不同排列. 给定n以及待排列的n个元素.计算出这n个元素的所有不同 ...
- Java实现 LeetCode 617 合并二叉树(遍历树)
617. 合并二叉树 给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠. 你需要将他们合并为一个新的二叉树.合并的规则是如果两个节点重叠,那么将他们的值相加作为节点 ...
- Java实现算法提高十进制数转八进制数
算法提高 十进制数转八进制数 时间限制:1.0s 内存限制:512.0MB 编写函数,其功能为把一个十进制数转换为其对应的八进制数.程序读入一个十进制数,调用该函数实现数制转换后,输出对应的八进制数. ...
- Java实现 蓝桥杯 算法提高 因式分解
算法提高 8-1因式分解 时间限制:10.0s 内存限制:256.0MB 提交此题 问题描述 设计算法,用户输入合数,程序输出若个素数的乘积.例如,输入6,输出23.输入20,输出22*5. 样例 与 ...
- Java实现 蓝桥杯VIP 基础练习 Huffuman树
基础练习 Huffuman树 问题描述 Huffman树在编码中有着广泛的应用.在这里,我们只关心Huffman树的构造过程. 给出一列数{pi}={p0, p1, -, pn-1},用这列数构造Hu ...
- Java实现 LeetCode 416 分割等和子集
416. 分割等和子集 给定一个只包含正整数的非空数组.是否可以将这个数组分割成两个子集,使得两个子集的元素和相等. 注意: 每个数组中的元素不会超过 100 数组的大小不会超过 200 示例 1: ...
- Java实现 LeetCode 68 文本左右对齐
68. 文本左右对齐 给定一个单词数组和一个长度 maxWidth,重新排版单词,使其成为每行恰好有 maxWidth 个字符,且左右两端对齐的文本. 你应该使用"贪心算法"来放置 ...
- Java实现 洛谷 P1055 ISBN号码
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; public ...
- Flutter upgrade更新版本引发的无法启动调试APP的错误 target:kernel_snapshot failed”
前言 我的主机上的Flutter 本地的分支是在 beta,因为去年想尝鲜Flutter Web,所以一直没切回来stable分支. 早上打开VSCode,右下角弹出了Flutter upgrade的 ...