Dempster–Shafer theory(D-S证据理论)初探
1. 证据理论的发展历程
Dempster在1967年的文献《多值映射导致的上下文概率》中提出上、下概率的概念,并在一系列关于上下概率的文献中进行了拓展和应用,其后又在文献《贝叶斯推理的一般化》中进一步探讨了不满足可加性的概率问题以及统计推理的一般化问题。
Shafer在Dempster研究的基础上提出了证据理论,把Dempster合成规则推广到更为一般的情况,并与1976年出版《证据的数学理论》,这一著作的出版标志着证据理论真正的诞生,为了纪念两位学者对证据理论所做的贡献,人们把证据理论称为Dempster-Shafer证据理论(D-S证据理论)。
自从证据理论诞生以来,在将近四十年的发展中,很多学者对证据理论进行了较为广泛的研究,也取得了丰硕的理论研究结果,D-S证据理论的应用性得到了广泛的证实。
2. 为什么需要D-S证据理论
证据理论自1976年美国学者G.Shafer发表了著作《证据的数学理论》以来,在理论上取得了很大的发展,在应用上也取得了丰富的成果。
证据理论在多分类器融合、不确定性推理、专家意见综合、多准则决策、模式识别、综合诊断等领域中都得到了较好的应用。
证据理论基于人们对客观世界的认识,根据人们掌握的证据和知识,对不确定性事件给出不确定性度量。这样做使得不确定性度量更切近人们的习惯,易于使用。
证据理论对论证合成给出了系统的合成公式,使多个证据合成后得到的基本可信数依然满足证据基本可信数的性质。
Dempster合成公式具有结合律与交换律,使其有利于实现计算和选择合成效果好的、信息质量高的信息源。
0x1:各个领域遇到的不确定性证据和证据冲突问题
1、自动驾驶领域中,多传感器信息融合问题
目前传感器采集到的数据都是带有噪声的,比如:
- LiDAR采集的点云的内部噪声:
- 收集的距离误差
- intensity校准
- 时间对齐
- 点云外部噪声:
- 定位误差
- 运动过程中所带来的点云位置畸变
- 云天雾天的鬼影等等
- Radar采集中的噪声:
- 相对于Radar坐标系下横向速度不准
- 标定不准确(稀疏点无法很好地和车体坐标系进行非常精确的标定)
- 运动补偿不准确带来的误差
- 相机采集的图片中的噪声:
- occlusion
- 逆光
- 低光(HDR可以解决亮度部分问题的同时也会带来新的误差)
- 标定
- 同步等等
一个典型的问题是,现在自动驾驶车在行驶过程中,LiDAR检测到了某个位置有个障碍物,Radar没有检测到,图像没有检测到,那么在这多种传感器的数据源下,我们需要进行一个决策,该位置有没有障碍物,最好可以给出这种决策的不确定性区间是多少。
2、网络安全入侵检测领域中,多源日志和多源告警的融合决策问题
3、数据分析中,不同的分类器的输出结果的综合决策问题
暂无
3. D-S证据理论基本概念
0x1:从概率的四种解释说起
- 客观解释(频率解释):概率描述了一个可以重复出现的事件的客观事实,即该事件可重复出现的频率,如掷骰子。
- 个人主义解释(主观解释、贝叶斯解释):概率反映了个人主义的一种偏好,是个人的主观意愿作用的结果,如赌博。
- 必要性解释(逻辑主义解释):把概率看成命题与命题之间联系程度的度量。这种联系是纯客观的,与人的作用无关,演绎推理是概率推理的一个特例。
- 构造性(constructive)解释:Shafer指出以上三种解释都没有涉及概率推断的构造性特性,证据理论给出概率一种新的构造性解释,认为概率是某人在证据的基础上构造出的他对一命题为真的信任程度(degree of belief),简称信度。
前三种概率满足可加性,即:


根据可加性可知,如果我们相信一个命题为真的程度为S,那么我们必须以 1-S 的程度去相信该命题的反。但是在很多情况下,这是不合理的,例如:”地球以外存在着生命“这一命题,其反命题是:”地球以内不存在生命“。
在实现世界的大部分时候,证据与证据之间都是存在着交叠与冲突的,并不是完美的.i.i.d.关系。
Daldey的不可能性定理指出,在两个基本假设下,不存在一种集结个体概率估计的数学公式满足概率定理。这两个假设如下:
- 个体的概率估计Pi(E)是独立随机变量
- 不论给定的事件E发生或不发生,Pi(E)是独立随机变量
也就是说,如果群体概率估计是个体概率估计的函数,则群体概率估计不满足概率定律,这意味着基于概率的集结模型在Daldey不可能性定理的条件下都将失效。
0x2:证据、识别框架及信度函数
1、证据在D-S理论中的定义
在证据理论中,证据指的是人们分析命题求其基本可信数所依据的事物的属性与客观环境(实证据),还包括人们的经验、知识和对该问题所做的观察和研究。
人们通过对证据的分析得出命题的基本可信数分配函数:m(A)。
笔者注:
D-S理论中的证据概念,是从概率论中随机变量的概念中推广而来的,也可以理解为机器学特征工程中的特征向量。
2、识别框架
对一个判决问题,设人们所能认识到的可能结果用集合Θ表示,那么人们所关心的任一命题都对应于Θ的一个子集。Θ被称为识别框架。
识别框架依赖于人们的认知水平,框架中的元素由人们”已经知道“或”想知道“的知识决定。
笔者注:
识别框架是一个更泛化的理论概念,在经典概率理论中被称为样本空间。它代表了具体问题可能的预测结果集合。
3、命题与基本可信度分配(Mass)
设Θ为识别框架,A为识别框架下的一个命题,如果集函数 m:2Θ → [0,1] 满足:

则称 m 为框架Θ上的基本可信度分配。m(A) 被称为 A 的基本可信数。
基本可信数反映了对 A 本身(而不去管它的任何真子集与前因后果)的信度大小。
命题本质上就是一组证据的集合。
笔者注:
命题表达了我们对待认识的目标对象(识别框架)的一种潜在推测,每一个命题都是识别框架的一个子集,对应一个对现实问题的抽象表征。
基本可信度分配是概率论中完备性的一个泛化推广。基本可信数累加和为1,代表着所有命题共同组合在一起,构成了完整的识别框架。
需要注意的是,和随机事件一样,命题本身是一个集合的概念(离散情况下),所以命题可以有子命题,对命题的可信度分配,同样也有子集的概念。
4、信度函数(Belief)
设Θ为识别框架,集函数 m:2Θ → [0,1] 为框架Θ上的基本可信度分配,则称由:

所定义的函数 Bel:2Θ → [0,1] 为Θ上的信度函数。信度函数表达了对每个命题的信度(考虑前因后果)。
笔者注:
可以看到,信度函数是一系列可信度分配的累计合成结果,这和概率论中随机变量是单个离散随机事件(离散概率)的累计的概念是一致的。
5、信度函数的半可加性
设Θ为识别框架,集函数 Bel:2Θ → [0,1] 是信度函数,当且仅当它满足:
 ,
, ,n为任意自然数
,n为任意自然数
则有下式:

上式为半可加性应满足的条件,满足可加性则一定满足半可加性。
前面说过,贝叶斯信度函数是一种特殊的信度函数,它的所有焦元都是单元素的,所以贝叶斯信度函数是满足完全可加性的。
6、信度函数的焦元
一批证据对一个命题提供支持的话,那么它也应该对该命题的推论提供同样的支持(互信息原理)。所以, 对一个命题的信度应该等于证据对它的所有前提本身提供的支持度之和。
如果 m(A) > 0,则称 A 为信度函数 Bel 的焦元
本质上说,焦元就是信度函数非零的证据集合,或者说焦元就是非零信度分配命题。
几种特殊的信度函数如下:
1)绝对信度函数

称 m(A) 为绝对信度函数,其中 A* ∈ Θ。
2)空信度函数
对一个信度函数而言,如果 m(Θ) = 1,我们将其成为空信度函数。
3)Bayesian信度函数
如果一个信度函数的焦元都为单元素集,我们将其成为 Bayesian信度函数,Bayesian信度函数即为概率函数。
笔者注:
贝叶斯理论最核心的假设就是元素(证据)之间是.i.i.d.独立同分布假设,这个假设在实际问题中很多时候是不成立的。 证据合成理论最大的理论贡献就是在可信度分配的新理论框架下,将证据之间的冲突性问题纳入了考虑和计算范围。
7、众信度函数(Q)
设函数 Q:2Θ → [0,1],且满足下式:

则 Q 被称为众信度函数。众信度函数 Q(A) 反映了包含A的集合的所有基本可信数之和。
笔者注:
信度函数 Bel 是从一个结论的前提这个角度来描述信度的,它计算的结论的前提(也就是证据)的累计合并结果;而相比不同的是,众信度函数 Q 是从一个前提的结论这个角度来描述信度的。
- 信度函数 Bel:结论的前提的累计合并结果,承前。
- 众信度函数 Q:前提的结论的累计合并结果,启后。
8、Bel信度函数和Q众信度函数概念的互相定义
设 Bel:2Θ → [0,1] 为Θ上的信度函数,Q 是它的众信度函数,那么,

该定理说明,Bel 与 Q 可以互相定义,众信度函数从另一个侧面反映了信度。
Dempster合成法则是证据理论的核心,是一个反映证据的联合 作用的法则,该法则可对不同证据源的证据进行合成。
9、似真度函数(plausibility function)
设函数 pl:2Θ → [0,1],且满足下式:

我们称 pl 为似真度函数(plausibility function)。pl(A) 称为 A 的似真度,表示我们不怀疑 A 的程度。pl(A) 包含了所有与 A 相容的那些集合(命题)的基本可信度。pl(A) 是比 Bel(A) 更宽松的一种估计。
10、信度函数合成的Dempster法则
1)双信度函数合成的Dempster法则
设 Bel1 和 Bel2 是同一识别框架Θ上的两个信度函数,m1 和 m2 分别是其对应的基本信度分配,焦元分别为 A1,A2,....,Ak 和 B1,B2,...,Bl,设:

则由下式定义的函数 m:2Θ → [0,1] 是基本信度分配:

并称此为两个信度函数合成的Dempster法则。
由此得到的合成后的基本信度分配m被称为 m1 和 m2 的直和。记为 。所对应的信度函数也被称为 Bel1 和 Bel2 的直和,记为
。所对应的信度函数也被称为 Bel1 和 Bel2 的直和,记为 。
。
(1 - K)-1 称为归一化因子,它的引入实际上是为了避免证据组合时将非零的信度赋给空集,把空集所丢弃的信度分配按比例地补到非空集上,K表示证据间的冲突程度,其值越大说明证据之间的冲突越大。
当 K=1 时,则 m1 和 m2 完全冲突,直和或不存在。
2)多信度函数合成的Dempster法则
设 Bel1,Bel2,...,Beln 是同一识别框架Θ上的信度函数,m1,m2,....,mn 是对应的基本信度分配,如果 存在且脚本可信度分配为m,且
存在且脚本可信度分配为m,且 ,则有:
,则有:
 ,其中
,其中
上式即多个信度函数合成的Dempster法则。
上面公式可以这么理解,命题的合成结果A,等于所有参与合并的命题中,相交于 A 的那些命题的的mass函数值的乘积的和,再除以一个归一化系数 1-K。归一化系数 1-K 中的 K 的含义是证据之间的冲突(the conflict between the evidences, called conflict probability)。
对于归一化系数K来说:
- 一个极端的情况就是,多个命题背后的支持证据彼此间完全冲突,即完全不相交,则Kn无限大,导致最终合成结果为零
- 另一个极端情况是,多个命题背后的支持证据完全重合,即完全相交,则Kn=1,则最终合成结果就等于各个子命题的累乘结果,这其实就是贝叶斯理论的假设前提
- 一般情况下,多个命题背后的支持证据存在部分重合,同时也有各自独立的贡献部分,换句话说,不同命题之间存在相关性
笔者注:
从信度函数合成的Dempster法则公式可以看出,Dempster合成公式是在贝叶斯概率分解公式的基础上,增加了对证据间冲突性的考虑,对彼此存在冲突的证据合成起到归一化的作用。
当组合多个证据时,可通过该公式将证据两两组合。但是该合成法则强调多种证据的协调性,抛弃所有冲突的证据。用上式合成高度冲突的证据时,合成的结果常有悖常理,在极限情况下则无法组合证据。
3)Dempster法则的数学性质
- 交换律:
 ,证据合成并不依赖于合成的顺序。
,证据合成并不依赖于合成的顺序。 结合律:
 ,证据合成次序不影响合成结果。
,证据合成次序不影响合成结果。同一性:存在唯一的幺元m0,对所有的基本信度分配m,有
 ,其中m0是空基本信度分配,即 m0(Θ) = 1,m0(其他) = 0,该性质在现实世界中的意义是某些专家不表态(弃权)时不影响最终结果。
,其中m0是空基本信度分配,即 m0(Θ) = 1,m0(其他) = 0,该性质在现实世界中的意义是某些专家不表态(弃权)时不影响最终结果。极化性:
 ,其中
,其中 表示一种”大于“或”放大“,表示意见相同的地位专家合成的效果是”支持的假设更支持,否定的假设更否定“,向两级增幅地发展。
表示一种”大于“或”放大“,表示意见相同的地位专家合成的效果是”支持的假设更支持,否定的假设更否定“,向两级增幅地发展。证据聚焦性:当两个证据都均以较高的信度支持识别框架中的某一命题时,合成后该命题将具有更高的信度。
11、信任区间
[Bel(A),pl(A)]:表示命题A的信任区间,
- Bel(A):表示似真函数的下限
- pl(A):表示似真函数的上限
例如(0.25,0.85),表示A为真有0.25的信任度,A为假有0.15的信任度,A不确定度为0.6。
0x3:框架的转化
一般来说,对任何一个证据处理人员来讲,他所想到的各种有用的观念、判断,是非常多的,某一框架只能包含其中很少的一部分,所以用单个识别框架来处理问题是很不够的。这种情况下证据处理人员为了进行某种特殊的似真推理,就有必要求助于不同的观念,侧重于不同的特性相应地转换他所使用的识别框架。
粗化与细化就是为适应这个要求而采用的两种转换方法。值得说明的是,框架的转化不是随意的,尽管转化前后两者要强调不同的特性、不同的侧面,而且在其关注的方向上可以具有不同程度的判决,但是两者决不能使用相互矛盾的、互不相容的概念。
细化与粗化就是两种相容的变换,而收缩与扩张就不是相容变换。
1、框架的划分
设Θ是识别框架,δ是Θ的一些子集所构成的集合,满足:

则δ被称为Θ的一个划分。
2、细化与粗化
δ1和δ2都是Θ的划分,对 都存在
都存在 使
使 ,则称δ1是δ2的加细(细分),δ2是δ1的加粗(粗化)。记为
,则称δ1是δ2的加细(细分),δ2是δ1的加粗(粗化)。记为 ,意味着δ2的每一个元素都是δ1的一些元素的并。
,意味着δ2的每一个元素都是δ1的一些元素的并。
对于Θ的任意两个划分δ1和δ2,可以定义另一个


 仍是Θ的一个划分,且有:
仍是Θ的一个划分,且有:

若有另一个划分δ3,满足:

则有:

由以上定理可知,我们所定义的划分既是δ1的加细,又是δ2的加细,而且在既是δ1的加细,又是δ2的加细划分中,又是最粗的,所以称是δ1和δ2最粗的公共加细。读者朋友通过画一个简单的韦恩图,基于集合论的知识就很容易理解这个性质了。
在Θ的所有划分中,最粗的划分是{Θ},即只包含一个元素即Θ本身的一个集合;最细的划分是{{θ} θ∈Θ},即Θ的单点子集的集合。
3、框架相容概念
对框架的细分来讲,是否存在一个极细化的精细框架(ultimate refinement),Shafer理论和贝叶斯理论有着不同的看法:
- 贝叶斯理论假定存在一个不能再细分的框架
- 而Shafer认为,任何一个被细分了的框架都可以继续进行细分
所以在Shafer理论中,有如下的两个框架相容的概念:
定理1:
设Θ1和Θ2为两个识别框架,若这两框架具有一个公共的精细化框架,则称框架Θ1和Θ2是相容的。
显然,根据这个定理,在两个框架中,当其中一个是另一个的精细时,这两个框架必相容。
定理2:
如果在一个框架Θ上加上一个新假设,则Θ的元素必定要减少,设Θ1是由Θ加上一个新假设而得到的识别框架,则Θ1作为可能事件或结果的一个集合,将是可能结果Θ的一个子集。
此时,我们称Θ1是Θ的一个收缩,Θ是Θ1的一个扩张。
笔者注:
识别框架的收缩与扩张,其本质就是概率论中假设空间放缩的一个推广,在贝叶斯理论中,通过引入先验知识,可以显著降低潜在的假设搜索空间,从而让概率评估结果更加符合人们对目标对象的事实依据。
Relevant Link:
https://www.hindawi.com/journals/js/2016/1903792/
4. D-S证据融合算法过程
这一章节,我们通过几个具体的例子,来具体看下,D-S证据融合理论与算法是如何对现实世界的问题进行建模与分析的。
0x1:在光传感探测器的多探测器结果融合问题中,D-S证据融合算法的建模过程
- Null
- Red
- Yellow
- Green
- Red or Yellow
- Red or Green
- Yellow or Green
- Any
以及这些假设相应的可能性(也就是说基本分配函数Mass)。
| Hypothesis | Mass | Belief | Plausibility |
|---|---|---|---|
| Null | 0 | 0 | 0 |
| Red | 0.35 | 0.35 | 0.56 |
| Yellow | 0.25 | 0.25 | 0.45 |
| Green | 0.15 | 0.15 | 0.34 |
| Red or Yellow | 0.06 | 0.66 | 0.85 |
| Red or Green | 0.05 | 0.55 | 0.75 |
| Yellow or Green | 0.04 | 0.44 | 0.65 |
| Any | 0.1 | 1.0 | 1.0 |
- 每个假设的mass函数值都在0和1之间;
- 空集的mass函数值为0,即另外其他的假设mass值得和为1;
- 在所有假设中,使得mass值大于0的命题(例如A),称为焦元(Focal element)
- m(Null) = 0
- m(Red) + m(Yellow) + m(Green) + ... + m(Any) = 1
- 命题A为:Red,那么 Bel(A) = 0.35,因为只有它本身是属于假设 A
- 命题A为:Red or Yellow,那么 Bel(Red or Yellow) = m(Null) + m(Red) + m(Yellow) + m(Red or Yellow) = 0 + 0.35 + 0.25 + 0.06 = 0.66
0x2:在法律目击证人问题中,D-S证据融合算法的Zadeh悖论问题
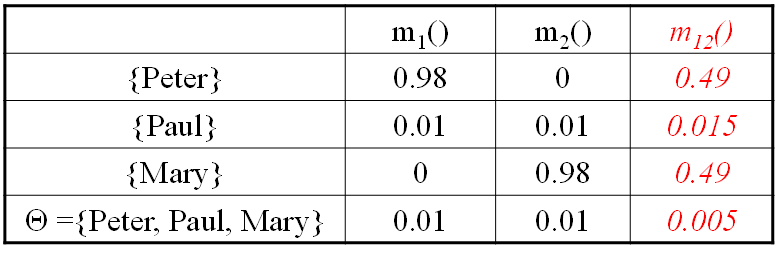
一宗谋杀案有三个犯罪嫌疑人:U = {Peter, Paul, Mary}。两个目击证人(W1,W2)分别指证犯罪嫌疑人,得到两个mass函数 m1 和 m2。

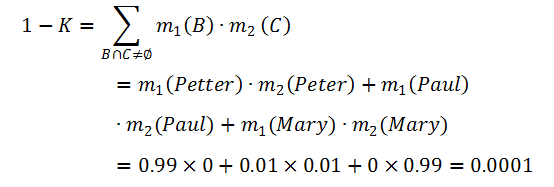
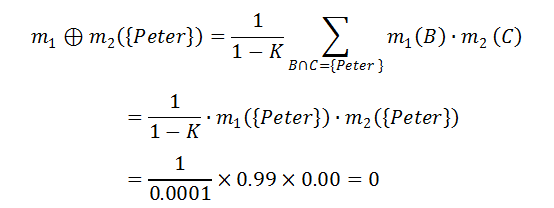
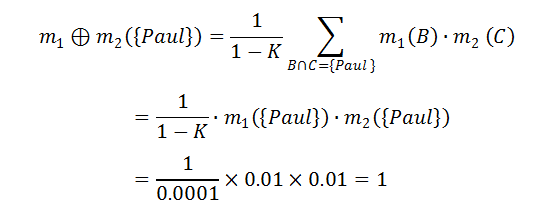
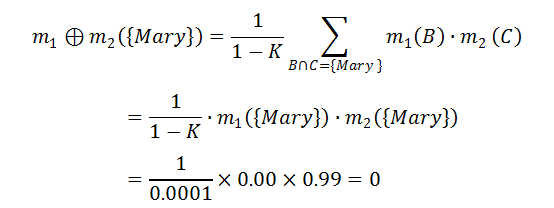
由此,我们得到了如上表所示的组合函数 m12。
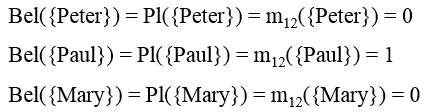

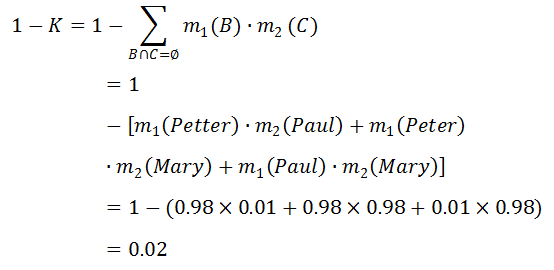
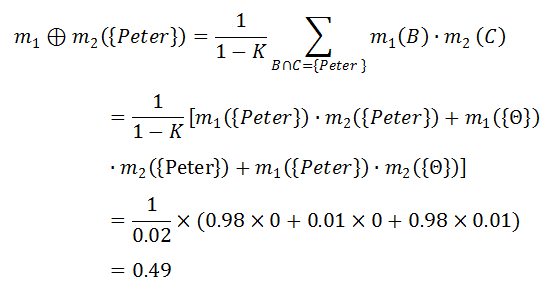
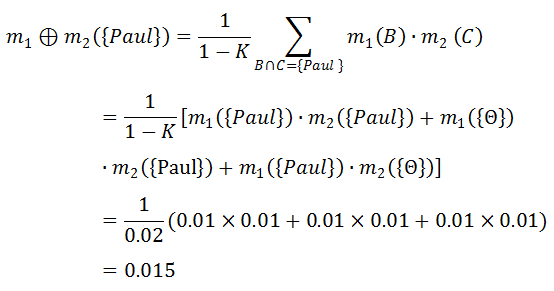
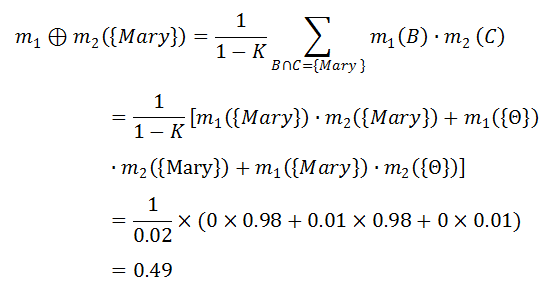
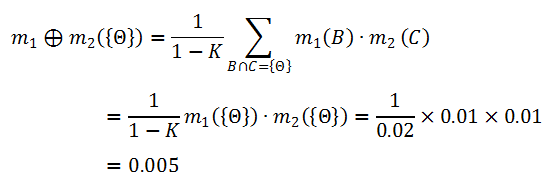

0x3:在自动驾驶问题中,D-S证据融合算法对多感知器的融合作用
以自动驾驶障碍物检测数据融合为例。
首先确定假设空间,对于自动驾驶场景来说,某一个时刻,对一个具体空间的情况,会有一些命题假设:
- 有障碍物A
- 无障碍物B
- 有障碍物或者无障碍物C
- 空集D(既不是有障碍物,也不是无障碍物,就是没法判断)四种情况
第二步确定基本分配概率,即确定每个证据源对于命题空间中每种命题假设发生的概率分布。
比如LiDAR作为证据源之一,在某个时刻对某个位置各个假设的分配概率为:
- A的概率是0.6
- 假设B的概率0.3
- 假设C的0.1
- 假设D的概率为0
分别用可信数来表示如下:
而图像感知器作为另一个证据源之一,在某个时刻对某个位置各个假设的分配概率为:
- A的概率是0.1
- 假设B的概率0.8
- 假设C的0.1
- 假设D的概率为0
分别用可信数来表示如下:
m(A)image = 0.1,m(B)image = 0.8,m(C)image = 0.1,m(C)image = 0
LiDAR和Image证据,对各个命题假设的置信度分配矩阵如下:

第三步是计算归一化常数(1 - K)(K是冲突因子,表示两个集合的冲突性)。
1 - K = 0.51
第三步计算每个命题假设的联合mass:
第四步计算每个命题假设的信度函数(Bel)和似真概率(pl):
| 命题假设 | mL | mI | m{L,I} | bel | pl |
| A | 0.6 | 0.1 | 0.275 | 0.275 | 0.295 |
| B | 0.3 | 0.8 | 0.706 | 0.706 | 0.726 |
| C | 0.1 | 0.1 | 0.020 | 1 | 1 |
| D | 0 | 0 | 0 | 0 | 0 |
0x4:D-S证据合成中,难以辨识模糊程度


0x5:D-S证据合成中,基本概率分配函数的微小变化会使组合结果产生急剧变化


https://blog.csdn.net/zfcjhdq/article/details/51566875
https://www.cnblogs.com/mmgf/p/8025261.html
https://blog.csdn.net/wsyhawl/article/details/78261554
https://www.ixueshu.com/document/889d1a6efed6edd8933d7c8c81103cda318947a18e7f9386.html
https://blog.csdn.net/wsyhawl/article/details/78261554
https://blog.csdn.net/zfcjhdq/article/details/51566875
https://www.cnblogs.com/mmgf/p/8025261.html
https://blog.csdn.net/zfcjhdq/article/details/51566875
https://blog.csdn.net/am45337908/article/details/48832947
https://zhuanlan.zhihu.com/p/99517591
http://dy.163.com/v2/article/detail/ELQG2DUV05311NDJ.html
5. 证据的决策规则
在前面的章节中,我们讨论了基本的证据融合方法以及对命题假设的似真度估计等问题。
这个章节开始,我们继续深入现实世界的复杂场景中,来讨论一下我们如何基于证据融合进行未来决策。
在决策分析中,系统的未来状态在一般情况下难以精确地给出。一般专家根据其掌握的知识与经验对系统状态进行分析,给出系统未来状态的主观估计。
当利用专家群体对系统未来状态进行估计时,就需要对专家群体的预测意见进行合成。
设决策集为:
D = {d1,d2,....,dm}
在不同的系统状态下,选择不同的决策,所获得的报酬(收益)是不同的。第 i 个系统状态,第 j 个决策方案对应的报酬函数为:
r(di,xj),(i = 1,....,m;j = 1,....,n)
在已知上述条件下,如何进行决策,是基于证据理论进行决策要解决的问题。
0x1:基于证据理论的传统证据决策规则
1、基于似真度函数求出各种系统状态的主观概率,然后求出各个决策方案的期望报酬
其过程可以表示如下:
利用似真度函数计算公式:

求出单点似真度:

令:

则 p(x1),...,p(xn) 即可作为各种状态出现的主观概率。
选择与期望报酬最大值对应的决策方案为最佳方案,即:

使用这种决策方案在应用时,应该注意它的假设前提:
它认为似真度越大,其主观概率就越大。但是一般情况下,点函数 pl({xi}) 不能表示基本可信数 m 或信度函数 Bel 所包含的所有信息,点函数 pl({xi}) 越大,m({xi}) 与 Bel({xi}) 不一定越大。
2、M决策法
该方法的思想是先求出各焦元的报酬函数,然后用基本可信数作为主观概率,求出各决策方案的期望报酬作为决策依据。
其过程可以表示如下,令:

则有:

选择与期望报酬最大值对应的决策方案为最佳方案。
使用这种决策方案在应用时,应该注意它的假设前提:
该方法计算对应于焦元的报酬函数,该计算公式是对焦元所包含的状态因素的报酬数值求简单平均值。这也就意味着该方法认为每个焦元内包含的各状态因素其出现的概率是相同的,而一般情况下,各状态出现的概率是不相等的。
0x2:基于焦元分析求解各状态的基本可信数的决策方法
上一个小节末我们说到,由于上述两个假设的存在,使上述两种决策方法存在着局限性。要科学地解决该问题,就是要解决如何在已知各焦元的基本可信度分配的条件下,求解系统各状态的发生概率或基本可信数。
因此有学者提出了,“基于焦元分析求解各状态的基本可信数的决策方法”,对群体专家意见合成得到的基本可信数的焦元进行分析,可分为两种情况来处理,
- 第一种情况是已知所有系统状态因素的基本可信数,即已知 m({xi}),i=1,....,n
- 第二种情况是未知所有系统状态因素的基本可信数
1、第一种情况
系统各状态的基本可信数作为分析计算各状态发生概率的依据。此时 m(Θ) 可能不等于零。m(Θ) 表示对证据的怀疑。
当对系统各状态的基本可信数充分信任时,可用下式定义各状态发生概率:

当对系统各状态的基本可信数有怀疑时,则可将 m(Θ) 均分给各个状态,即可用下式定义各状态发生概率:

2、第二种情况
用逐步求精的方法对基本可信数的焦元进行分析求解构成焦元的状态因素的基本可信数。
首先,对由单个状态因素构成的焦元确定该单个状态因素的基本可信数就是与该焦元对应的基本可信数。
其次,对焦元中含有已知基本可信数的单个状态因素的焦元,可将已知基本可信数的单个状态因素及其基本可信数中提出,这样可以缩小等待进一步分配的焦元所含构成状态因素的数量,并可能缩小未知基本可信数的单个状态因素的数量。
最好,对还不能确定基本可信数的单个状态因素,就要引入新的信息进行判断与求解。
例如,已知:

则可首先确定:

其次可确定:
 与
与

接下来,对 m({x3}) 和 m({x4}) 就要引入新的信息来确定,可向专家咨询:“已知 m({x3, x4}) = 0.2,m({x3}), m({x4})应为多少?”,专家可根据自己的知识,做出进一步的判断。将专家的意见进行合成后,就可得到 m({x3}) 和 m({x4}) 的数值。
当求解出系统各状态的基本可信数 m({xi}) 后,就可用第一种情况下的方法求解各状态发生概率。
求解出各系统状态的发生概率后,计算各个决策方案的期望报酬,选择出最优决策方案,其计算公式如下:

0x3:基于粗糙集的证据决策规则分析
可进一步把证据理论的合成结果转化为规则,在合成结果中发生概率最大的某种状态,就是将要发生的结果。
经过转化后,历史样本就可以看做决策表,可返回历史样本对各个合成规则的不确定性进行分析与评价。
6. D-S证据融合理论的编码示例
0x1:a Python implementation for the Dempster–Shafer concept
"""
Shows different use cases of the library.
""" from __future__ import print_function
from pyds import MassFunction
from itertools import product print('=== creating mass functions ===') m1 = MassFunction({'ab':0.6, 'bc':0.3, 'a':0.1, 'ad':0.0}) # using a dictionary
print('m_1 =', m1) m2 = MassFunction([({'a', 'b', 'c'}, 0.2), ({'a', 'c'}, 0.5), ({'c'}, 0.3)]) # using a list of tuples
print('m_2 =', m2) m3 = MassFunction()
m3['bc'] = 0.8
m3[{}] = 0.2
print('m_3 =', m3, ('(unnormalized mass function)')) #print('\n=== belief, plausibility, and commonality ===')
#print('bel_1({a, b}) =', m1.bel({'a', 'b'}))
#print('pl_1({a, b}) =', m1.pl({'a', 'b'}))
#print('q_1({a, b}) =', m1.q({'a', 'b'}))
#print('bel_1 =', m1.bel()) # entire belief function
#print('bel_3 =', m3.bel())
#print('m_3 from bel_3 =', MassFunction.from_bel(m3.bel())) # construct a mass function from a belief function #print('\n=== frame of discernment, focal sets, and core ===')
#print('frame of discernment of m_1 =', m1.frame())
#print('focal sets of m_1 =', m1.focal())
#print('core of m_1 =', m1.core())
#print('combined core of m_1 and m_3 =', m1.core(m3)) #print('\n=== Dempster\'s combination rule, unnormalized conjunctive combination (exact and approximate) ===')
#print('Dempster\'s combination rule for m_1 and m_2 =', m1 & m2)
#print('Dempster\'s combination rule for m_1 and m_2 (Monte-Carlo, importance sampling) =', m1.combine_conjunctive(m2, sample_count=, importance_sampling=True))
#print('Dempster\'s combination rule for m_1, m_2, and m_3 =', m1.combine_conjunctive(m2, m3))
#print('unnormalized conjunctive combination of m_1 and m_2 =', m1.combine_conjunctive(m2, normalization=False))
#print('unnormalized conjunctive combination of m_1 and m_2 (Monte-Carlo) =', m1.combine_conjunctive(m2, normalization=False, sample_count=))
#print('unnormalized conjunctive combination of m_1, m_2, and m_3 =', m1.combine_conjunctive([m2, m3], normalization=False)) #print('\n=== normalized and unnormalized conditioning ===')
#print('normalized conditioning of m_1 with {a, b} =', m1.condition({'a', 'b'}))
#print('unnormalized conditioning of m_1 with {b, c} =', m1.condition({'b', 'c'}, normalization=False)) #print('\n=== disjunctive combination rule (exact and approximate) ===')
#print('disjunctive combination of m_1 and m_2 =', m1 | m2)
#print('disjunctive combination of m_1 and m_2 (Monte-Carlo) =', m1.combine_disjunctive(m2, sample_count=))
#print('disjunctive combination of m_1, m_2, and m_3 =', m1.combine_disjunctive([m2, m3])) #print('\n=== weight of conflict ===')
#print('weight of conflict between m_1 and m_2 =', m1.conflict(m2))
#print('weight of conflict between m_1 and m_2 (Monte-Carlo) =', m1.conflict(m2, sample_count=))
#print('weight of conflict between m_1, m_2, and m_3 =', m1.conflict([m2, m3])) #print('\n=== pignistic transformation ===')
#print('pignistic transformation of m_1 =', m1.pignistic())
#print('pignistic transformation of m_2 =', m2.pignistic())
#print('pignistic transformation of m_3 =', m3.pignistic()) print('\n=== local conflict uncertainty measure ===')
print('local conflict of m_1 =', m1.local_conflict())
print('entropy of the pignistic transformation of m_3 =', m3.pignistic().local_conflict()) #print('\n=== sampling ===')
#print('random samples drawn from m_1 =', m1.sample(, quantization=False))
#print('sample frequencies of m_1 =', m1.sample(, quantization=False, as_dict=True))
#print('quantization of m_1 =', m1.sample(, as_dict=True)) #print('\n=== map: vacuous extension and projection ===')
#extended = m1.map(lambda h: product(h, {, }))
#print('vacuous extension of m_1 to {1, 2} =', extended)
#projected = extended.map(lambda h: (t[] for t in h))
#print('project m_1 back to its original frame =', projected) #print('\n=== construct belief from data ===')
#hist = {'a':, 'b':, 'c':}
#print('histogram:', hist)
#print('maximum likelihood:', MassFunction.from_samples(hist, 'bayesian', s=))
#print('Laplace smoothing:', MassFunction.from_samples(hist, 'bayesian', s=))
#print('IDM:', MassFunction.from_samples(hist, 'idm'))
#print('MaxBel:', MassFunction.from_samples(hist, 'maxbel'))
#print('MCD:', MassFunction.from_samples(hist, 'mcd'))
这个代码示例涵盖了D-S证据理论主要的定理公式,读者朋友可以通过打开注释以及debug单步调试,帮助我们更好地从代码层面理解抽象的数学公式。
Relevant Link:
https://github.com/reineking/pyds
0x2:simple ADS clickfraud detection
# -*- coding: utf- -*- """
This script implement algorithm from
THESIS "Automatic Detection of Click Fraud in Online Advertisements" AGARWAL
Calculate the belief of fraud
http://repositories.tdl.org/ttu-ir/bitstream/handle/2346/46429/AGARWAL-THESIS.pdf
Import library using pyds (https://github.com/reineking/pyds)
Require: Python3, numpy, scipy, redis (https://github.com/andymccurdy/redis-py)
Author: TrucLK
"""
from pyds import MassFunction
from itertools import product
import redis
import sys
import pprint
import time ################################################
class Config(object):
"""
Redis for store click history
"""
redis_host = '127.0.0.1'
redis_port =
redis_db = # Time for redis key expire
time_to_expire = # Visitor length of checking
visit_length = # weight is an empirically derived value that signifies the strength of the evidence in supporting the user is fraud # caution changing it will change the maximum value of result.
IDWeight = 0.5
UAWeight = 0.4
IPWeight = 0.4 class EcLogger(object):
"""
This is object relate to log
""" def __init__(self):
self.ro = redis.Redis(host=Config.redis_host, port=Config.redis_port, db=Config.redis_db) def record(self, hit): """
Add click to history for checking
""" clickid = self.ro.incr('ec:clicknum') self.ro.zadd('click:ip:' + hit.ip, clickid, int(hit.time))
self.ro.expire('click:ip:' + hit.ip, Config.time_to_expire)
self.ro.zadd('click:cookie:' + hit.cookie, clickid, int(hit.time))
self.ro.expire('click:cookie:' + hit.cookie, Config.time_to_expire)
self.ro.zadd('click:config:' + hit.pubid + ':' + hit.config, clickid, int(hit.time))
self.ro.expire('click:config:' + hit.pubid + ':' + hit.config, Config.time_to_expire)
pass def getClickNumFromIp(self, hit):
"""
Get click time from this IP address in this session
"""
count =
count = self.ro.zcount('click:ip:' + hit.ip, int(hit.time) - Config.visit_length, int(hit.time))
if (count == ):
count =
return count def getClickNumFromCookie(self, hit):
"""
Get click time from this anonymous id in this session
"""
count = self.ro.zcount('click:cookie:' + hit.cookie, int(hit.time) - Config.visit_length, int(hit.time))
if (count == ):
count =
return count def getClickNumFromConfig(self, hit):
"""
Get cliock time from this user agent in this session
"""
count = self.ro.zcount('click:config:' + hit.pubid + ':' + hit.config, int(hit.time) - Config.visit_length,
int(hit.time))
if (count == ):
count =
return count class Hit(object):
"""
It's a simple container.
""" def __init__(self, **kwargs):
for key, value in kwargs.items():
setattr(self, key, value)
super(Hit, self).__init__() class ClickProcessingUnit(object):
"""
Mass functions for Click Fraud Detection
""" def __init__(self, hit, ecLogger):
self.hit = hit
self.ecLogger = ecLogger class ClickProcessingUnitIp(ClickProcessingUnit):
"""
Evidence number of clicks on the ad by ip address
Create mass function for ip address checking
""" def process(self):
numberclick = self.ecLogger.getClickNumFromIp(self.hit)
coefficient_value = Config.IPWeight a = coefficient_value * ( - / numberclick)
b =
ab = - a massfunction = MassFunction({'a': a, 'b': b, 'ab': ab})
return massfunction; class ClickProcessingUnitCookie(ClickProcessingUnit):
"""
Evidence number of clicks on the ad by user ID
Create mass function for id cookie checking
""" def process(self):
numberclick = self.ecLogger.getClickNumFromCookie(self.hit)
coefficient_value = Config.IDWeight a = coefficient_value * ( - / numberclick)
b =
ab = - a massfunction = MassFunction({'a': a, 'b': b, 'ab': ab})
return massfunction; class ClickProcessingUnitConfig(ClickProcessingUnit):
"""
Evidence number of clicks on the ad by user agent
Create mass function for user agent checking
""" def process(self):
numberclick = self.ecLogger.getClickNumFromConfig(self.hit)
coefficient_value = Config.UAWeight a = coefficient_value * ( - / numberclick)
b =
ab = - a massfunction = MassFunction({'a': a, 'b': b, 'ab': ab})
return massfunction class ClickProcessing(object):
"""
Main click processing function
""" def __init__(self, hit, ecLogger):
self.hit = hit
self.ecLogger = ecLogger def process(self):
processingList = self.getListOfProcessing()
m = None
# Loop for list of processing class
for processing in processingList:
# Init first mass function
if not m:
m = processing.process()
else:
# Dempster's rule of combination create a new mass function
m = m & processing.process()
return m def getListOfProcessing(self):
"""
Config list of processing
"""
dict1 = []
dict1.append(ClickProcessingUnitIp(self.hit, self.ecLogger))
dict1.append(ClickProcessingUnitCookie(self.hit, self.ecLogger))
dict1.append(ClickProcessingUnitConfig(self.hit, self.ecLogger))
return dict1 if __name__ == '__main__':
"""
Add click from command line argument
"""
try:
hit = hit = Hit(
ip=sys.argv[],
time=sys.argv[],
config=sys.argv[],
cookie=sys.argv[],
pubid=sys.argv[],
)
ecLogger = EcLogger()
processing = ClickProcessing(hit, ecLogger)
ecLogger.record(hit)
m = processing.process()
print(m.bel('a'))
sys.exit()
except Exception:
print(0.01)
sys.exit()
读者朋友在阅读这段代码的时候,要重点理解信度分配函数部分,

对信度函数的分配,涉及到我们如何对待解决问题进行抽象建模的过程,可以将其简单理解为一种特征工程。
Relevant Link:
https://github.com/afterlastangel/simple_ads_clickfraud_detection/blob/master/clickprocess.py
https://ttu-ir.tdl.org/bitstream/handle/2346/46429/AGARWAL-THESIS.pdf
0x3:integrate the RSS data processed by multiple machine learning algorithms
# -*- coding: utf- -*- import os
import time
import numpy as np
import scipy.io as sio
import sklearn # 测试样本对应的真实格点坐标
def test_real(path):
real1=[]
for i in range(grid_num):
for j in range(grid_test_sample):
real1.append(i+)
real=np.array(real1)
return real # 模型:一共有56个格点,每个格点上训练数据100组,测试数据10组
def read_data(path):
pathtrain = os.path.join(path,'train.mat')
traindataset = sio.loadmat(pathtrain).get('data') # 训练数据 pathtest = os.path.join(path,'test.mat')
testdataset = sio.loadmat(pathtest).get('X_test') # 测试数据
trainlabelset1 = []
for grid in range(grid_num):
for sample in range(grid_train_sample):
local_tmp = grid +
trainlabelset1.append(local_tmp)
trainlabelset = np.array(trainlabelset1) # 训练数据集对应坐标
testlabelset = test_real(path) # 测试数据集对应坐标
return traindataset, trainlabelset, testdataset, testlabelset # KNN Classifier
# KNeighborsClassifier(n_neighbors=, weights=’uniform’, algorithm=’auto’, leaf_size=, p=,
# metric=’minkowski’, metric_params=None, n_jobs=, **kwargs)
def knn_classifier(train_x, train_y):
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier()
model.fit(train_x, train_y)
return model # Logistic Regression Classifier
# LogisticRegression(penalty=’l2’, dual=False, tol=0.0001, C=1.0, fit_intercept=True,
# intercept_scaling=, class_weight=None, random_state=None, solver=’liblinear’,
# max_iter=, multi_class=’ovr’, verbose=, warm_start=False, n_jobs=)
def logistic_regression_classifier(train_x, train_y):
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(penalty='l2')
model.fit(train_x, train_y)
return model # Random Forest Classifier
def random_forest_classifier(train_x, train_y):
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=)
model.fit(train_x, train_y)
return model # Decision Tree Classifier
def decision_tree_classifier(train_x, train_y):
from sklearn import tree
model = tree.DecisionTreeClassifier()
model.fit(train_x, train_y)
return model # GBDT(Gradient Boosting Decision Tree) Classifier
def gradient_boosting_classifier(train_x, train_y):
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier(n_estimators=)
model.fit(train_x, train_y)
return model # SVM Classifier
def svm_classifier(train_x, train_y):
from sklearn.svm import SVC
model = SVC(kernel='rbf', probability=True)
model.fit(train_x, train_y)
return model # SVM Classifier using cross validation
def svm_cross_validation(train_x, train_y):
from sklearn.grid_search import GridSearchCV
from sklearn.svm import SVC
model = SVC(kernel='rbf', probability=True)
param_grid = {'C': [1e-, 1e-, 1e-, , , , ], 'gamma': [0.001, 0.0001]}
grid_search = GridSearchCV(model, param_grid, n_jobs = , verbose=)
grid_search.fit(train_x, train_y)
best_parameters = grid_search.best_estimator_.get_params()
for para, val in best_parameters.items():
print para, val
model = SVC(kernel='rbf', C=best_parameters['C'], gamma=best_parameters['gamma'], probability=True)
model.fit(train_x, train_y)
return model def func_rmse(predict_label,real):
pathlocal=os.path.join(path,'dist1.mat')
local=sio.loadmat(pathlocal).get('dist')#56个格点坐标
tmp = predict_label-np.ones(np.shape(predict_label))
predict_2d = local[map(int,tmp)]
tmp_real = real-np.ones(np.shape(predict_label))
real_2d = local[map(int,tmp_real)]
norm_sqrt = (np.linalg.norm(predict_2d-real_2d,axis=-))**
rmse = np.sqrt(sum(norm_sqrt)/np.shape(predict_label))
return rmse def get_probability(data_chuang):
"""
对窗数据来说,维度为:len_chuang*算法个数
计算每种算法下格点序号出现次数及概率
"""
mygrid = range(,)
cishu_total=[]
for sf in range(len_sf):
cishu=[]
for item in mygrid:
cishu_sf = data_chuang[:,sf].tolist().count(item)
cishu.append(cishu_sf)
cishu = np.array(cishu)
cishu_total.append(cishu)
probio_total = [item/float(len_chuang) for item in cishu_total]
probio_total = np.array(probio_total).transpose()
return probio_total if __name__ == '__main__':
path = os.path.abspath('.')
thresh = 0.5
model_save_file = None
model_save = {}
grid_num =
grid_train_sample =
grid_test_sample = test_classifiers = ['KNN', 'LR', 'RF', 'DT', 'SVM']
classifiers = {
'KNN': knn_classifier,
'LR': logistic_regression_classifier,
'RF': random_forest_classifier,
'DT': decision_tree_classifier,
'SVM': svm_classifier,
'SVMCV': svm_cross_validation,
'GBDT': gradient_boosting_classifier
} print 'reading training and testing data...' train_x, train_y, test_x, test_y = read_data(path)
# print "test_x: ", test_x
# print "test_y: ", test_y
num_train, num_feat = train_x.shape
num_test, num_feat = test_x.shape
is_binary_class = (len(np.unique(train_y)) == ) print '******************** Data Info *********************'
print '#training data: %d, #testing_data: %d, dimension: %d' % (num_train, num_test, num_feat) predict_total2 = []
rmse_total = []
for classifier in test_classifiers:
print '******************* %s ********************' % classifier
start_time = time.time()
model = classifiers[classifier](train_x, train_y)
print 'training took %fs!' % (time.time() - start_time)
predict = model.predict(test_x)
if model_save_file != None:
model_save[classifier] = model
if is_binary_class:
tmp = func_rmse(predict, test_y)
rmse_total.append(tmp)
accuracy = sklearn.metrics.accuracy_score(test_y, predict)
print 'accuracy: %.2f%%' % ( * accuracy)
predict_total2.append(predict)
predict_total1 = np.array(predict_total2)
predict_total = predict_total1.transpose() print "predict_total: ", predict_total """
对已经被机器学习算法进行预测之后的数据矩阵predict_total(维度为:测试样本数*算法数)
滑窗对数据集进行处理,窗长度为len_chuang,每次下滑一格
对窗长度内的数据进行概率计算并DS融合
"""
len_chuang = # 窗数据长度
pre_ds = []
pre_dsjq = []
pre_max = []
pre_test = []
for start in range(, - len_chuang + ): # 滑动窗口
data_chuang = predict_total[start:len_chuang+start, :] # 取出窗长度的数据
len_sf = len(data_chuang[]) # 多算法个数
probio_total = get_probability(data_chuang) # 窗数据矩阵中每种算法对应所有格点出现概率 """
.普通ds
等同于求多种算法概率平均之后,概率最大的格点为所预测格点
"""
init_mean = np.mean(probio_total,) # 每个格点下多种算法提供的平均概率
init_ds = init_mean
# 这部分并没有起到实际作用
for i in range(len_sf-):
init_ds = np.multiply(init_ds,init_mean)
k = sum(init_ds)
bel = init_ds/float(k)
pre_grid = np.argmax(bel)+
pre_ds.append(pre_grid)
"""
.加强ds
求得多种算法的源可信度,得到估计
"""
m_between = np.zeros([len_sf,len_sf])
for i in range(len_sf):
for j in range(len_sf):
m_between[i, j]=sum(np.multiply(probio_total[:,i],probio_total[:,j]))
# m_between两个证据的内积=两个证据中,每个出现事件的概率乘积*(出现事件的交集/并集)
# 对单个事件而不是集合事件而言,等同于对应事件的概率乘积之和
d = np.zeros([len_sf,len_sf])
sim = np.zeros([len_sf,len_sf])
for i in range(len_sf):
for j in range(len_sf):
d[i,j]=np.sqrt(0.5*(m_between[i,i]+m_between[j,j]-*m_between[i,j]))
# d为两个证据间的距离,距离越小表示两个证据提出的意见越一致
sim[i,j]=-d[i,j]
# sim为两个证据之间的相似度,越大代表两个证据之间的一致性越强
sup = np.zeros(len_sf)
for i in range(len_sf):
sup[i]=sum(sim[i,:])-sim[i,i]
# sup为对每个证据的支持度,为两个证据之间的相似度之和减去该证据自己对自己的支持度
# 证据对自己的支持度为1
crd = np.zeros(len_sf)
for i in range(len_sf):
crd[i]=float(sup[i])/sum(sup)
# crd为证据的可信度
# 即为归一化的支持度,其他证据对该证据支持度越高,则可信度越高
A = np.zeros(grid_num)
for i in range(grid_num):
A[i] = sum(np.multiply(probio_total[i,:],crd))
# 将可信度作为源权重,估计所有情况下数据出现的概率
AA = A # 这部分并没有起到实际作用
# 对于所有元素均为0-1的概率值,进行元素对于相乘之后并不改变元素的大小排序
for i in range(len_sf-):
init_ds = np.multiply(AA,A)
# 分子为与某事件有交集的事件概率之乘积
k = sum(init_ds)
# 分母K=∑(所有有交集的事件的概率乘积)
# 或者为1-∑(所有不相交的时间概率乘积)
# 对全部都是单事件而不是集体事件而言,有交集的事件即为事件其本身
# K表示了证据的冲突程度,冲突越大,越接近0,一致性越大,越接近1
bel = init_ds/float(k)
pre_grid = np.argmax(bel)+
pre_dsjq.append(pre_grid)
# 下面两行代码是为了验证多次融合A矩阵并不能起到结果
testgrid = np.where(A == np.max(A))[][]
pre_test.append(testgrid+)
"""
.使用窗数据中出现次数最多的作为正确结果
"""
data_chuang_list = data_chuang.flatten().tolist()
matrix_cishu = max(data_chuang_list,key=data_chuang_list.count)
pre_max.append(matrix_cishu) truth_chuang = test_y[len_chuang-:]
rmse_ds = func_rmse(pre_ds, truth_chuang)
rmse_max = func_rmse(pre_max, truth_chuang)
rmse_dsjq = func_rmse(pre_dsjq, truth_chuang)
rmse_test = func_rmse(pre_test, truth_chuang) print "pre_ds: ", pre_ds
print "rmse_ds: ", rmse_ds
accuracy = sklearn.metrics.accuracy_score(test_y[len_chuang-:], pre_ds)
print 'accuracy: %.2f%%' % ( * accuracy)
基于D-S证据融合算法,对包括KNN、LR、RF、DT、SVM在内的5种算法的概率预测结果(每一个算法的预测结果相当于一个命题假设),进行融合,将融合得到的概率结果作为最终的概率预测结果。

可以看到,融合后的概率预测结果,总体上优于单个算法的预测结果,仅略逊于LR算法,同时规避了LR的过拟合问题。
Relevant Link:
https://github.com/Keats13/dempster_shafer_multi_rss
0x4:A fuzzy machine learning algorithm utilizing Dempster-Shafer and Bayesian Theory
Relevant Link:
https://github.com/aus10powell/fuzzy_dempster_shafer
0x5:Implementation in Python for Dempster Shafer algorythm with application in predicting movies genres by reviews
Relevant Link:
https://github.com/Moldoteck/Dempster-Shafer
Relevant Link:
https://github.com/bpietropaoli/THEGAME-Python
https://github.com/amineremache/dempster-shafer/blob/master/dempster_shafer.py
https://github.com/redaneqrouz/dempster-Shafer/blob/master/dams.py
https://github.com/leokan92/dempster-shafer/blob/master/Dempstershafercomb.py
https://github.com/Zhiming-Huang/Dempster-shafer-combination-rules/blob/master/DS.py
7. D-S理论和贝叶斯理论的区别
笔者在进行相关理论学习和编码开发的过程中,隐约中感觉到D-S理论和Bayesian理论之间存在比较明显的区别,似乎D-S是从贝叶斯理论的基础上发展而来的。但是又不能完全理解其中的脉络,这里权且放一些粗浅的理论,留待将来解决。
- D-S和贝叶斯理论都是基于集合论构建出的理论体系,它们的基本计算单元都是离散集合。
- D-S在离散统计概率的基础上,考虑了随机事件概率之间的冲突性,提出了可信度分配和信度函数等新概念,使得对多源证据的融合成为可能
Dempster–Shafer theory(D-S证据理论)初探的更多相关文章
- d-s证据理论
证据理论是Dempster于1967年首先提出,由他的学生Shafer于1976年进一步发展起来的一种不精确推理理论,也称为Dempster/Shafer 证据理论(D-S证据理论),属于人工智能范畴 ...
- 【GCN】图卷积网络初探——基于图(Graph)的傅里叶变换和卷积
[GCN]图卷积网络初探——基于图(Graph)的傅里叶变换和卷积 2018年11月29日 11:50:38 夏至夏至520 阅读数 5980更多 分类专栏: # MachineLearning ...
- 初探领域驱动设计(2)Repository在DDD中的应用
概述 上一篇我们算是粗略的介绍了一下DDD,我们提到了实体.值类型和领域服务,也稍微讲到了DDD中的分层结构.但这只能算是一个很简单的介绍,并且我们在上篇的末尾还留下了一些问题,其中大家讨论比较多的, ...
- CSharpGL(8)使用3D纹理渲染体数据 (Volume Rendering) 初探
CSharpGL(8)使用3D纹理渲染体数据 (Volume Rendering) 初探 2016-08-13 由于CSharpGL一直在更新,现在这个教程已经不适用最新的代码了.CSharpGL源码 ...
- 从273二手车的M站点初探js模块化编程
前言 这几天在看273M站点时被他们的页面交互方式所吸引,他们的首页是采用三次加载+分页的方式.也就说分为大分页和小分页两种交互.大分页就是通过分页按钮来操作,小分页是通过下拉(向下滑动)时异步加载数 ...
- JavaScript学习(一) —— 环境搭建与JavaScript初探
1.开发环境搭建 本系列教程的开发工具,我们采用HBuilder. 可以去网上下载最新的版本,然后解压一下就能直接用了.学习JavaScript,环境搭建是非常简单的,或者说,只要你有一个浏览器,一个 ...
- .NET文件并发与RabbitMQ(初探RabbitMQ)
本文版权归博客园和作者吴双本人共同所有.欢迎转载,转载和爬虫请注明原文地址:http://www.cnblogs.com/tdws/p/5860668.html 想必MQ这两个字母对于各位前辈们和老司 ...
- React Native初探
前言 很久之前就想研究React Native了,但是一直没有落地的机会,我一直认为一个技术要有落地的场景才有研究的意义,刚好最近迎来了新的APP,在可控的范围内,我们可以在上面做任何想做的事情. P ...
- Introduction to graph theory 图论/脑网络基础
Source: Connected Brain Figure above: Bullmore E, Sporns O. Complex brain networks: graph theoretica ...
随机推荐
- 基于Jquery WeUI的微信开发H5页面控件的经验总结(1)
在微信开发H5页面的时候,往往借助于WeUI或者Jquery WeUI等基础上进行界面效果的开发,由于本人喜欢在Asp.net的Web界面上使用JQuery,因此比较倾向于使用 jQuery WeUI ...
- hdu1495 倒水bfs
题目链接:http://icpc.njust.edu.cn/Problem/Hdu/1495/ 题意:给定三个杯子S,M,N,满足S=M+N,现在要求用最短的次数将S杯中的饮倒平分到两个杯子中.我们首 ...
- Contest 152
2019-09-01 20:59:55 总体感受:最近几次参加contest发现自己的水平还是严重的不够,尤其是在处理一些异常情况的时候,遇到TLE,MLE如何有效的进行Debug是需要去锻炼的. 注 ...
- 超越Mask-RCNN:谷歌大脑的AI,自己写了个目标检测AI
这是一只AI生出的小AI. 谷歌大脑的Quoc Le团队,用神经网络架构搜索 (NAS) ,发现了一个目标检测模型.长这样: △ 看不清请把手机横过来 它的准确率和速度都超过了大前辈Mask-RCNN ...
- php 设置允许跨域请求
php 服务端代码 <?php header('Content-Type: text/html;charset=utf-8'); header('Access-Control-Allow-Ori ...
- Tainted canvases may not be exported的问题解决
项目里使用到用canvas生成海报,在toDataURL报了这个错误Tainted canvases may not be exported. 原因就在于使用了跨域的图片,所以说是被污染的画布.解决方 ...
- 数据库(sqlserver 2005)优化排查之路
查找问题过程是痛苦的,解决完问题是快乐! 兄弟帮助一个公司开发了一个旅游网站(asp.net+sqlsever2005),一直还算稳定,但是最近网站却慢的可以,让人头疼.登录服务器,进入任务管理器,发 ...
- 基于.NetCore3.1搭建项目系列 —— 使用Swagger导出文档 (番外篇)
前言 回顾之前的两篇Swagger做Api接口文档,我们大体上学会了如何在net core3.1的项目基础上,搭建一套自动生产API接口说明文档的框架. 本来在Swagger的基础上,前后端开发人员在 ...
- C# 便捷实现可迭代对象间的赋值
目录 都是迭代,为啥我一定要用foreach 如果换成是字典呢? 关于 foreach 都是迭代,为啥我一定要用foreach 问题起源于本人的一个练手的扑克牌程序:洗完牌之后要发给场上的三人. ...
- STM32F103ZET6时钟
1.STM32F103ZET6时钟说明 STM32F103ZET6的时钟树图如下所示: STM32F103ZET6有很多个时钟源,分别有: HSE:高速外部时钟信号. HSI:高速内部部时钟信号. L ...