2019-05-25 Python之Mongodb的使用
Mongodb学习总结:
one.插入数据pass
two.查看数据pass
three.修改数据pass
four.数据排序pass
five.删除数据pass
一.安装Mongodb
https://www.cnblogs.com/ymzm204/p/10947055.html
二.测试Mongodb
(1)引入相关库
import pymongo
(2)连接数据库
client = pymongo.MongoClient(host='localhost', port=27017
(3)写入数据并且输出
import pymongo myclient = pymongo.MongoClient(host='localhost', port=27017) #连接
my_set1 = myclient.University.test #连接University,如果没有则创建一个数据库
my_set2 = myclient.University.test2 #连接University,如果没有则创建一个数据库
dblist = myclient.list_database_names() #所有的数据库名字列表
print(dblist) #查看已有的数据库
my_set1.insert_one({"name":"zhangsan"}) #插入一个数据
my_set2.insert_one({"name":"zhangsan"})
for i in my_set1.find():
print(i) #输出
(4)结果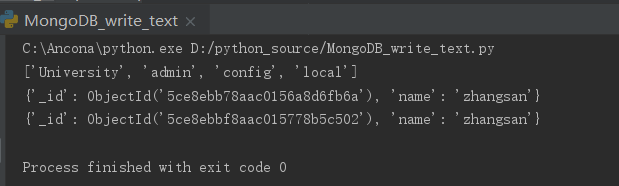
三.实例运用——爬取中国大学排名并写入数据库,外加查询and创新
(1)爬取过程中到的数据写入数据库
from bs4 import BeautifulSoup
import requests
import pandas as pd
import pymongo def client_Mongodb(port, path):
myclient = pymongo.MongoClient(host='localhost', port=port) # 连接
my_set = myclient.path # 连接path,如果没有则创建一个数据库
return my_set def save_mongo(result):
myclient = pymongo.MongoClient(host='localhost', port=27017)
my_set = myclient.University.ranking
try:
if my_set.product.insert_one(result): #如果保存成功
pass#print("数据保存成功")
except Exception:
print("数据保存失败") def save_list_to_Mongodb(lists):
my_set = client_Mongodb(27017, 'University.ranking')
product = {
'排名': lists[0],
'学校名称': lists[1],
'省份': lists[2],
'总分': lists[3],
'生源质量(新生高考成绩得分)': lists[4],
'培养结果(毕业生就业率': lists[5],
'社会声誉(社会捐赠收入·千元': lists[6],
'科研规模(论文数量·篇)': lists[7],
'科研质量(论文质量·FWCI)': lists[8],
'顶尖成果(高被引论文·篇)': lists[9],
'顶尖人才(高被引学者·人)': lists[10],
'科技服务(企业科研经费·千元': lists[11],
'成果转化(技术转让收入·千元)': lists[12],
'学生国际化(留学生比例)': lists[13],
} # 字典类型数据
save_mongo(product) def getHTMLText(url):
try:
r = requests.get(url, timeout=10)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return "" def filUnivList(soup):
data = soup.find_all('tr')
for tr in data:
ltd = tr.find_all('td')
if len(ltd) == 0:
continue
singleUniv = []
for td in ltd:
singleUniv.append(td.string)
save_list_to_Mongodb(singleUniv) def main():
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
html = getHTMLText(url)
soup = BeautifulSoup(html, "html.parser")
filUnivList(soup)
print("完成")
for i in pymongo.MongoClient(host='localhost', port=27017).University.ranking.product.find():
print(i) # 输出
main()
结果:
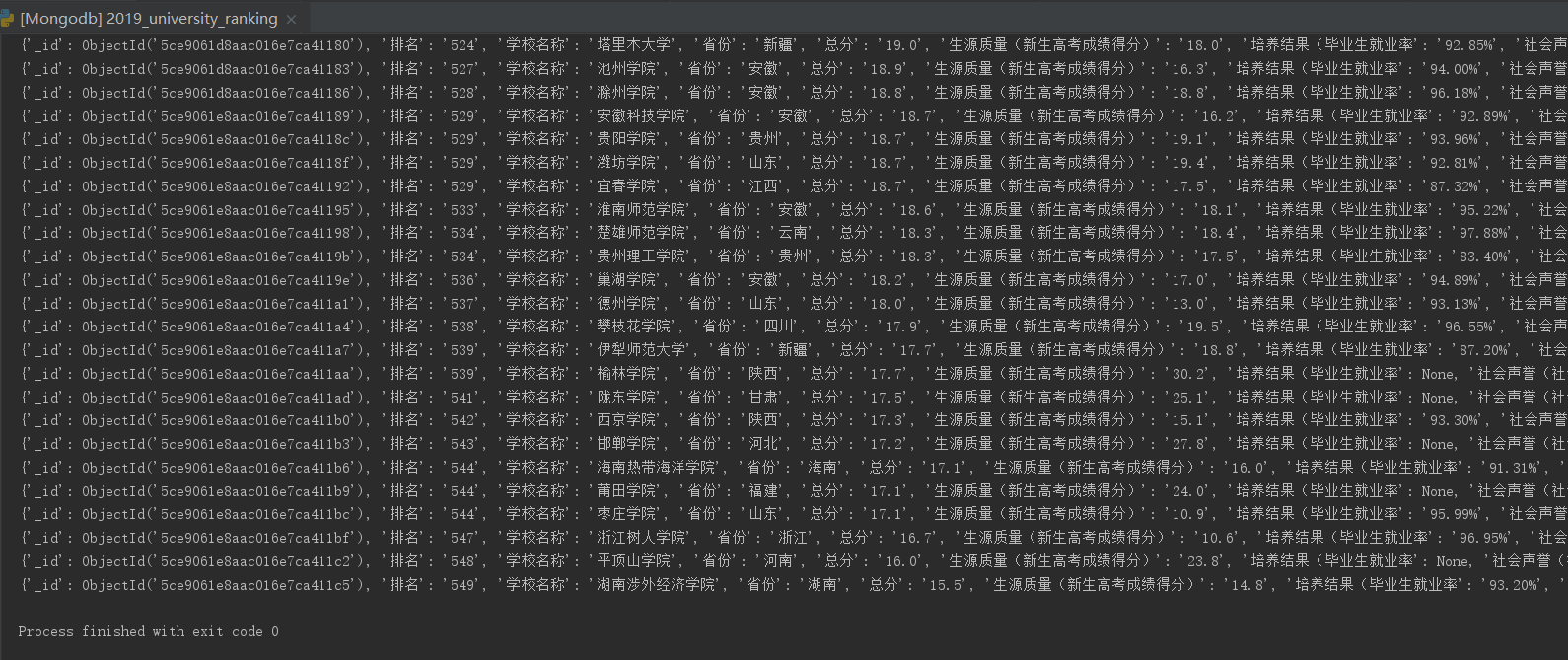
(2)csv格式文件写入到Mongodb数据库中
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/10/21 11:31
# @Author : deli Guo
# @Site :
# @File : csv文件存入mongoDB.py
# @Software : PyCharm # 导包
import pymongo
import csv # 创建连接MongoDB数据库函数
def connection():
# 1:连接本地MongoDB数据库服务
myclient = pymongo.MongoClient("localhost")
# 2:连接本地数据库(guazidata)。没有时会自动创建
db = myclient.University
# 3:创建集合
my_set = db.ranking.product_test
# 4:看情况是否选择清空
my_set.delete_many({})
return my_set #返回集合 def insertToMongoDB(my_set):
# 打开文件guazi.csv
with open("E://testcsv.csv", 'r') as csvfile:
# 调用csv中的DictReader函数直接获取数据为字典形式
reader = csv.DictReader(csvfile)
# 创建一个counts计数一下 看自己一共添加了了多少条数据
counts = 0
for each in reader:
# 将数据中需要转换类型的数据转换类型。原本全是字符串(string)。
'''each['index']=int(each['index'])
each['价格']=float(each['价格'])
each['原价']=float(each['原价'])
each['上牌时间']=int(each['上牌时间'])
each['表显里程']=float(each['表显里程'])
each['排量']=float(each['排量'])
each['过户数量']=int(each['过户数量'])
'''
my_set.insert_one(each)
counts += 1
print('成功添加了'+str(counts)+'条数据 ')
# 创建主函数
def main():
my_set = connection()
insertToMongoDB(my_set)
# 判断是不是调用的main函数。这样以后调用的时候就可以防止不会多次调用 或者函数调用错误
if __name__=='__main__':
main()
(3)查询某大学排名,查询某省份所有大学,排序X条件的大学
(one)
import pymongo myclient = pymongo.MongoClient(host='localhost', port=27017)#连接
mydb = myclient.University #数据库
mycol = mydb.ranking.product_test #集合 myquery = {"学校名称": "广东技术师范大学"}
for i in mycol.find(myquery):
print(i)
输出结果:{'_id': ObjectId('5cea018c8aac013e249fe115'), '': '286', '排名': '287', '学校名称': '广东技术师范大学', '省份': '广东',..........................省略..}
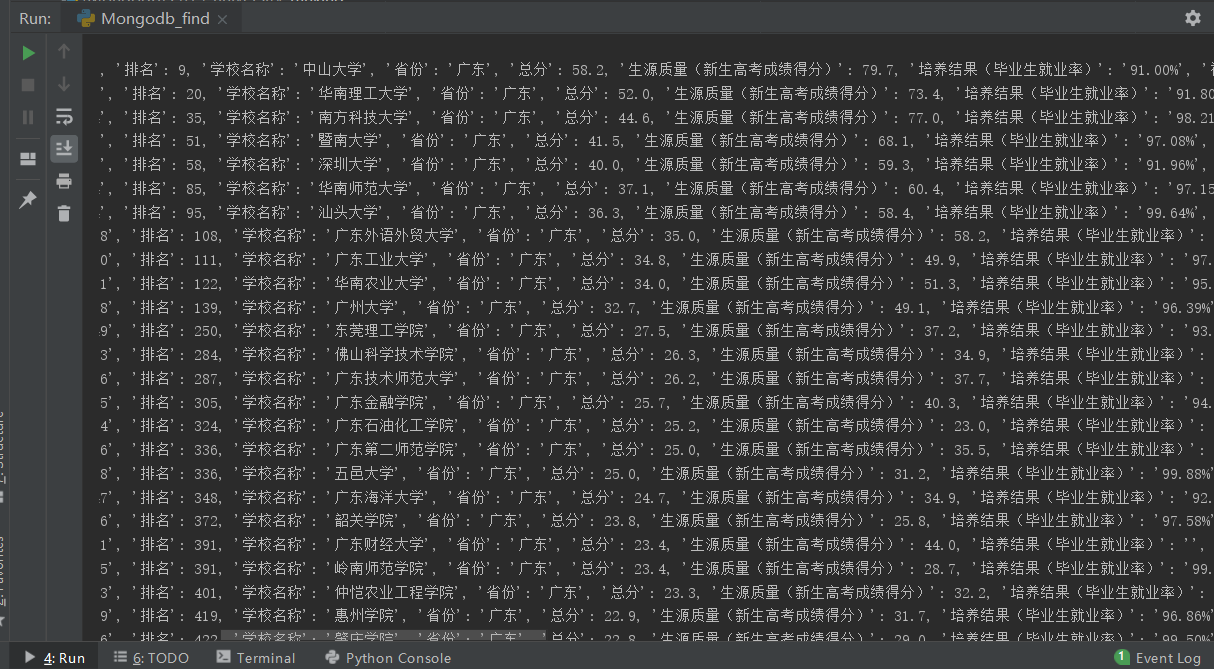
(two)
myquery = {"省份": "广东"}
输出结果:
(three)降序,条件为省份为 广 字开头
myquery = {"省份": { "$regex": "广"}}
for i in mycol.find(myquery).sort("排名", -1):
print(i)
输出:可以发现 降序指按第一个数字为准,猜测原因:“排名”数据保存到数据库时候是以 str 形式保存的,为此,修改为int可能会有效 下面为已经更改类型后的测试

(4)综合算法得出新排名并保存为一个新表
思路:添加新字段,同时根据算法添加新数据。
import pymongo
import re myclient = pymongo.MongoClient(host='localhost', port=27017)
my_set = myclient.University
my_doc = my_set.ranking.product_test
#my_doc.insert_one({"name": "{}"}) weight = [0.9, 0.9, 0.8, 0.0001, 0.001, 1, 0.01, 1, 0.00001, 0.0001, 1] #权重 注意不要是str
i = 0
my_set.ranking.product_new = my_doc for c in my_doc.find(): #所有的数据,分行获取,处理
temp_data_list = []
k = 0 # 设置k的初始值
for b in c.values(): #字典里所有的值
temp_data_list.append(b) #把值加入到列表
temp_data_list2 = temp_data_list[5:16] #获取列表里面有用数据 第 6-15 个 for data in range(len(temp_data_list2)): #进一步数据处理
if temp_data_list2[data] == '': #把 None 补为0
temp_data_list2[data] = '' #这里有个小坑,不能赋值 为0 因为下面要去除 %和其他符号,提取数字,0为int,不是str,会有错误
temp_data_list2[data] = float(re.sub("[^\d.]", "", temp_data_list2[data])) #正则表达式中'[^\d.]'表示除了数字和.),并用""替换,然后返回的就是只剩下数字的字符串 去除有 > 号的干扰,并转换为float
k += temp_data_list2[data] * weight[data] #算法
b = '%.2f' % k #改为小数点后两位
#my_doc.update_one({}, {'$unset': {'新排名': ''}})
my_doc.update_one({'_id': c['_id']}, {'$set': {'新总分': b}})
i += 1
print("已更新{}条数据".format(i))
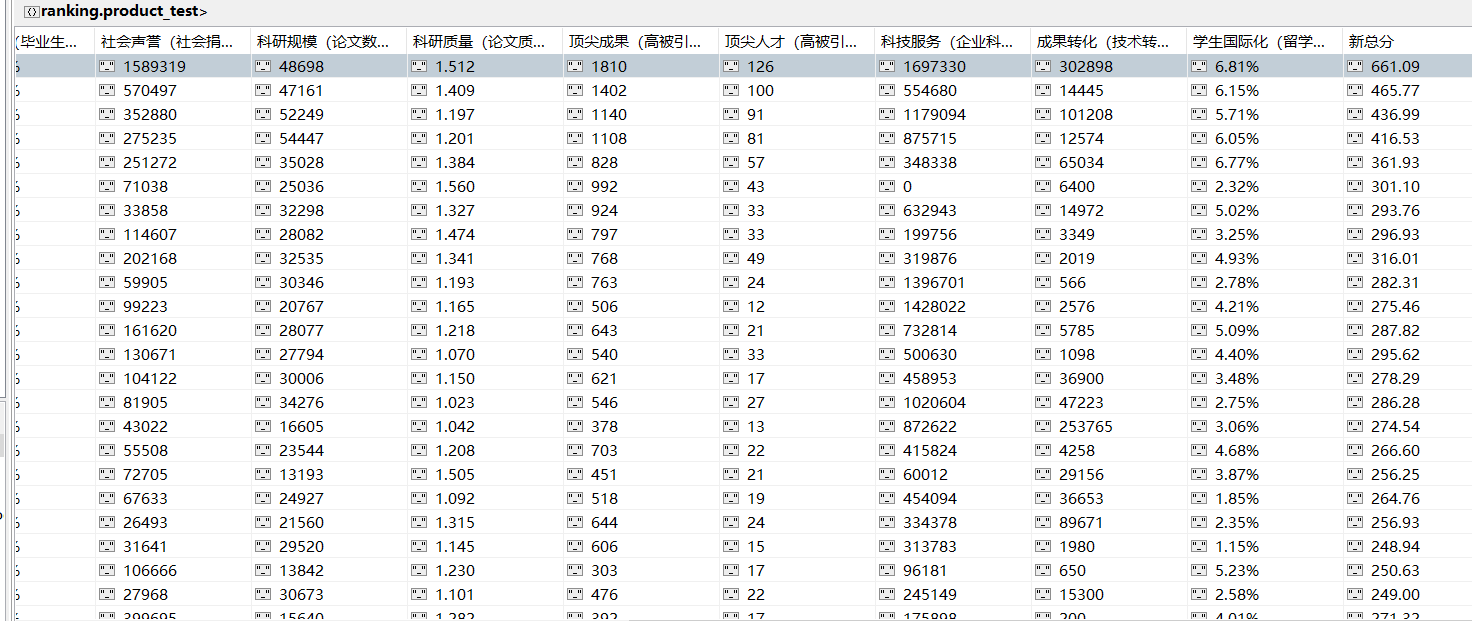
存在的小问题:部分值为空,在使用算法时候需要注意
1.部分value竟然不是str, (124 中央民族大学)
2.存在>号,需要处理
2019-05-25 Python之Mongodb的使用的更多相关文章
- python爬虫27 | 当Python遇到MongoDB的时候,存储av女优的数据变得如此顺滑爽~
上次 我们知道了怎么操作 MySQL 数据库 python爬虫26 | 把数据爬取下来之后就存储到你的MySQL数据库. MySQL 有些年头了 开源又成熟又牛逼 所以现在很多企业都在使用 MySQL ...
- Python 操作 mongodb 数据库
原文地址:https://serholiu.com/python-mongodb 这几天在学习Python Web开发,于 是做准备做一个博客来练练手,当然,只是练手的,博客界有WordPress这样 ...
- python 连 mongodb
这几天在学习Python Web开发,于是做准备做一个博客来练练手,当然,只是练手的,博客界有WordPress这样的好玩意儿,何必还自己造车呢?决定使用Tornado这个框架,然后数据库方面决定顺便 ...
- python操作三大主流数据库(10)python操作mongodb数据库④mongodb新闻项目实战
python操作mongodb数据库④mongodb新闻项目实战 参考文档:http://flask-mongoengine.readthedocs.io/en/latest/ 目录: [root@n ...
- 爬虫入门【8】Python连接MongoDB的用法简介
MongoDB的连接和数据存取 MongoDB是一种跨平台,面向文档的NoSQL数据库,提供高性能,高可用性并且易于扩展. 包含数据库,集合,文档等几个重要概念. 我们在这里不介绍MongoDB的特点 ...
- 【转】Python操作MongoDB
Python 操作 MongoDB 请给作者点赞--> 原文链接 这篇文章主要介绍了使用Python脚本操作MongoDB的教程,MongoDB作为非关系型数据库得到了很大的宣传力度,而市面 ...
- Python与Mongodb交互
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统 MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案 MongoDB 将数据存储为一个文档,数据结构由键值 ...
- python操作mongodb
# python操作mongodb # 首先,引入第三方模块pymongo,该模块是python用来操作mongodb的 import pymongo # 第二步,设置ip地址,以及表格名称,表格名字 ...
- [2019.03.25]Linux中的查找
TMUX天下第一 全世界所有用CLI Linux的人都应该用TMUX,我爱它! ======================== 以下是正文 ======================== Linu ...
- 使用Python操作MongoDB
MongoDB简介(摘自:http://www.runoob.com/mongodb/mongodb-intro.html) MongoDB 由C++语言编写,是一个基于分布式文件存储的开源数据库系统 ...
随机推荐
- select_related prefetch_related
# select_related与prefetch_related# # select_related帮你直接连表操作 查询数据 括号内只能放外键字段# # res = models.Book.obj ...
- python浅学【网络服务中间件】之Memcached
一.缓存的由来: 提升性能 绝大多数情况下,select 是出现性能问题最大的地方.一方面,select 会有很多像 join.group.order.like 等这样丰富的语义,而这些语义是非常耗性 ...
- JavaScript----简介及基础语法
##JavaScript *概念:一门客户端脚本语言 *运行在客户端浏览器中的.每一个浏览器都有JavaScript的解析引擎. *脚本语言:不需要编译,直接就可以被浏览器解析执行. *功能: *可以 ...
- NBL小可爱纪念赛「 第一弹 」 游记(部分题解)
比赛链接 洛谷:禁止含有侮辱性质的比赛 . ??? 反正我觉得,gyx挺危险的 不说废话. 首先,比赛经验,前几个小时不打,跟着刷榜. 一看 T1. 发现是道水题,直接切掉了. 然后看到了 T2. 感 ...
- ELK 环境搭建总结
开始动手前的说明 我搭建这一套环境的时候是基于docker搭建的,用到了docker-compose,所以开始前要先安装好docker . docker-compose,并简单的了解docker . ...
- Hive面试准备
Hive与HBase的区别Hive架构原理Hive的数据模型及各模块的应用场景Hive支持的文件格式和压缩格式及各自特点Hive内外表的区分方法及内外部差异Hive视图如何创建.特点及应用场景Hive ...
- TensorFlow 多 GPU 处理并行数据
Multi-GPU processing with data parallelism If you write your software in a language like C++ for a s ...
- 如何查看自己项目中vue的版本号和cli的版本号
查看Vue版本号 代码方式 npm list vue 其他方式 找到package.json文件夹 找"dependencies"然后就可以看到你装的vue的版本了 查看cli版本 ...
- Crash
一.Crash类型 crash 一般产生自 iOS 的微内核 Mach,然后在 BSD 层转换成 UNIX SIGABRT 信号,以标准 POSIX 信号的形式提供给用户.NSException 是使 ...
- 【API知识】SpringBoot项目中@EnableXXX的原理
@EnableXX注解的使用场景 SpringBoot为开发人员提供了很多便利,例如如果想要定时功能,只要添加@EnableSchedule,即可配合@Schedule注解实现定时任务功能,不需要额外 ...