Python哈希表和解析式
哈喽,大家好!距离上一篇文章近1个半月了,不是我拖呀~,刚好这个月遇到了工作调整,再加上要照顾10个月的孩子,实属不易,所以就这么长时间没来更新了。这不,我每天码一点点,'滴水成河',努力完成了这篇文章。
1. 封装和解构
1.1 封装
说明: 等号(=)右边有多个数值仅通过逗号分割,就会封装到一个元组,称为封装packing。
# 示例:
x = 1,
y = 1,2
print(type(x), x)
print(type(y), y)
# 输出结果如下:
<class 'tuple'> (1,)
<class 'tuple'> (1, 2)
备注: 如果右边只有一个数值且没有用逗号,其实是一个整数类型,请留意。另外等号右边一定先运行,再赋值给左边。
1.2 解构
说明: 等号(=)右边容器类型的元素与左边通过逗号分割的变量要一 一对应,称为解构unpacking。
x,y = (1,2) # [1,2] {1,2} {'a':1,'b':2}
print(x)
print(y)
# 输出结果如下:
1
2
备注:右边的容器可以是元组、列表、字典、集合等,必须是可迭代对象。
错误示范:
x,y = (1,2,3)
print(x)
print(y)
# 输出结果如下:
ValueError: too many values to unpack (expected 2)
说明:左、右两边个数一定要一致,不然会抛出'ValueError'错误。
剩余变量解构
说明:python3引入了剩余变量解构(rest),'尽可能'收集剩下的数据组成一个列表。
x, *rest = [1,2,3,4,5,6]
print(type(x), x)
print(type(rest), rest) # 剩余没有赋值的就是rest的了
# 输出结果如下:
<class 'int'> 1
<class 'list'> [2, 3, 4, 5, 6]
*rest, y = [1,2,3,4,5,6]
print(type(rest), rest)
print(type(y), y)
# 输出结果如下:
<class 'list'> [1, 2, 3, 4, 5]
<class 'int'> 6
错误示例:
不能单独使用
说明:等号左边只有一个标识符,无法解构。
*rest = [1,2,3,4,5,6]
print(rest) # 输出结果如下:
#语法错误
SyntaxError: starred assignment target must be in a list or tuple
不能多次同时使用
x, *rest1, *rest2, y = [1,2,3,4,5,6]
print(rest1)
print(rest2) # 输出结果如下:
#语法错误,其中一个rest就把剩余元素拿走了,另外一个rest怎么拿?
SyntaxError: two starred expressions in assignment
另外一种丢弃变量下划线:'_'
说明: '_'是合法的标识符,大多场景表示不关心该值。
x, *_, y = [1,2,3,4,5,6]
print(x)
print(_)
print(y)
# 输出结果如下:
1
[2, 3, 4, 5]
6
_, *rest, _ = [1,2,3,4,5,6]
print(_) # '_'是上一次输出值
print(rest)
# 输出结果如下:
6
[2, 3, 4, 5]
2. 集合Set
说明:集合是'可变的、无序的、不重复'的元素集合。
成为集合元素是有条件的:'元素必须可hash、可迭代'
可哈希对象如下(不可变):
- 数值型:int(整数)、float(浮点)、complex(复数)
- 布尔型:True(是)、False(否)
- 字符串:string(字符串)、bytes(字节)
- tuple(元组)
- None(空)
可以通过内置hash函数判断是否可hash:
s1 = [1,2,3]
print(hash(s1))
# 输出结果如下:
TypeError: unhashable type: 'list' # 列表是不可hash的
2.1 初始化
说明:
- set() -> new empty set object,新的空集合
- set(iterable) -> new set object,元素必须可迭代
s = {} # 注意这个是空字典,不是空集合
s1 = set() # 空集合
s2 = set([1,2,3]) # 注意列表里面元素迭代出来的是整数,可hash
s3 = set("abcd")
print(s1)
print(s2)
print(s3)
# 输出结果如下:
set()
{1, 2, 3}
{'c', 'd', 'a', 'b'}
错误示例:
s = set([[1]]) # 列表套列表,迭代出来是列表,不可hash
print(s)
# 输出结果如下:
TypeError: unhashable type: 'list'
2.2 增加
s.add(element)
说明:增加一个元素到集合,如果元素已经存在,则不操作。
s1 = set([1,2,3])
s1.add(4)
print(s1)
# 输出结果如下:
{1, 2, 3, 4}
s.update(*element))
说明:合并一个或多个元素到集合中,元素必须可迭代(把迭代的元素并到集合),和后面讲的并集一样。
s1 = set([1,2,3])
s1.update((4,5,6),[7,8,9])
print(s1)
# 输出结果如下:
{1, 2, 3, 4, 5, 6, 7, 8, 9}
2.3 删除
remove(element)
说明:从集合中移除一个元素,如果元素不存在抛出'KeyError'错误。
s1 = {1,2,3,4,5,6}
s1.remove(6)
print(s1) # 输出结果如下:
{1, 2, 3, 4, 5}
discard(element)
说明:也是从集合中移除一个元素,如果元素不存在不会报异常,啥都不做。
s1 = {1,2,3,4,5,6}
s1.discard(6)
print(s1) # 输出结果如下:
{1, 2, 3, 4, 5}
pop()
说明:因为集合是无序的,所以是删除'任意'一个元素,如果是空集则抛出'KeyError'错误。
s1 = {1,2,3,4,5,6}
print(s1.pop()) # 随机的(因为无序)
print(s1) # 输出结果如下:
1
{2, 3, 4, 5, 6}
clear()
说明:删除所有元素,都不推荐使用的啦。
s1 = {1,2,3,4,5,6}
s1.clear()
print(s1) # 输出结果如下:
set()
2.4 遍历
说明:集合是个容器,是可以遍历的,但是效率都是O(n)。
s1 = {1,2,3}
for s in s1:
print(s)
# 输出结果如下:
1
2
3
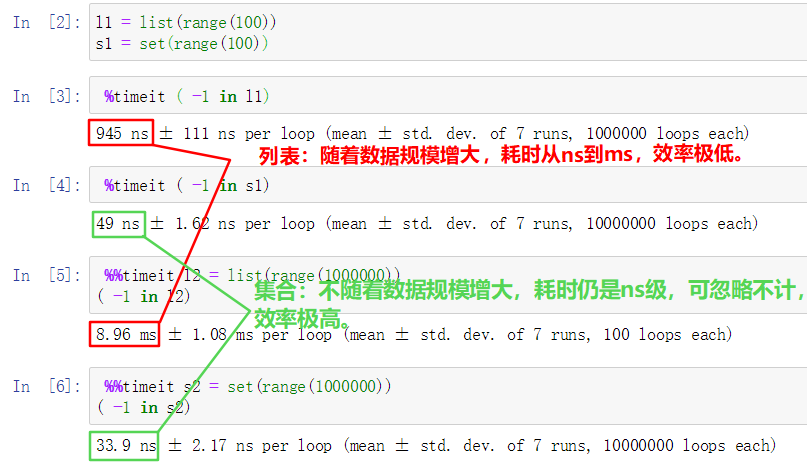
说到这里,你觉得集合set和列表list哪个遍历效率更高呢?
答案是set,因为set的元素是hash值作为key(下面讲的字典也是hash值),查询时间复杂度为O(1),而list是线性数据结构,时间复杂度是O(n)。
大家可以按照如下进行验证下,随着数据规模越来越大,很明显就可以看出哪个效率高。
2.5 并集&交集&差集&对称差集
并集
说明: 将多个集合的所有元素合并在一起组成新的集合。
s1 = {1,2,3}
s2 = {3,4,5}
print(s1.union(s2)) # 输出结果如下:
{1, 2, 3, 4, 5}
备注:还可以使用运算符 '|'、'update(element)'、'|='。
交集
说明: 取多个集合的共同(相交)元素
s1 = {1,2,3}
s2 = {3,4,5}
print(s1.intersection(s2)) # 输出结果如下:
{3}
备注:还可以使用'&'、's.intersection_update(element)'、'&='。
差集
说明:属于一个集合但不属于另一个集合的元素组成的集合。
s1 = {1,2,3}
s2 = {3,4,5}
print(s1.difference(s2)) # 输出结果如下:
{1, 2}
备注:还可以使用'-'、's.difference_update(element)'、'-='.
对称差集
说明:多个集合中,不属于交集元素组成的集合。
s1 = {1,2,3}
s2 = {3,4,5}
print(s1.symmetric_difference(s2)) # 输出结果如下:
{1, 2, 4, 5}
备注:还可以使用''、's1.symmetric_difference_update(s2)'、'='.
3.字典
说明:字典是由任意个item(元素)组成的集合,item是由key:value对组成的二元组。
- 字典是'可变的':支持增删改查;
- 字典是'无序的':key存储是无序的,非线性数据结构(请不要让表面蒙蔽了你哈);
- 字典是'key不重复':key是唯一的,且必须可'hash';
3.1 初始化
# 空字典
d1 = {}
d2 = dict()
# 示例:
d3 = dict(a=1,b=2,c=3)
d4 = dict(d3)
d5 = dict([('a',1),('b',2),('c',3)]) # 元素必须是可迭代的
d6 = {'a':1,'b':2,'c':3}
# 输出结果都是:
{'a': 1, 'b': 2, 'c': 3}
3.2 增删改查
增加&修改元素
1)通过'd[key] = value'方式:
备注:如果key不存在,则新增,key存在则直接覆盖(修改元素)。
# 增加 & 修改
d = {'a':1,'b':2,'c':3}
d['d'] = 4 # 增加
d['a'] = 11 # 修改
print(d) # 输出结果如下:
{'a': 11, 'b': 2, 'c': 3, 'd': 4}
2)通过d.update([E, ]**F) -> None
# 增加 & 修改
d = {'a':1,'b':2,'c':3}
d.update(d=4)
print(d) # 输出结果如下:
{'a': 1, 'b': 2, 'c': 3, 'd': 4}
删除元素
1)d.pop()
- key存在则移除,并返回对应value值。
- key不存在,返回给定的缺省值,否则抛出KeyError。
d = {'a':1,'b':2,'c':3}
print(d.pop('c',None))
print(d) # 输出结果如下:
3
{'a': 1, 'b': 2}
2)d.popitem()
- 删除并返回一个任意的item(key:value)。
- 如果是空字典,抛出KeyError。
d = {'a':1,'b':2,'c':3}
print(d.popitem())
print(d) # 输出结果如下:
('c', 3)
{'a': 1, 'b': 2}
3)d.clear()
- 删除所有item,不推荐使用。
d = {'a':1,'b':2,'c':3}
d.clear()
print(d)
查找元素
- 通过key这个键就可以快速找到value值。
- 时间复杂度是O(1),不会随着数据规模大而降低效率。
正常访问元素:
d = {'a':1,'b':2,'c':3}
print(d['a'])
print(d.get('b')) # 输出结果如下:
1
2
key不存在的处理方式:
d = {'a':1,'b':2,'c':3}
print(d.get('d',None)) # 如果key不存在,缺省返回None
print(d.setdefault('d',100)) # 如果key不存在,则新增key:value对
print(d) # 输出结果如下:
None
100
{'a': 1, 'b': 2, 'c': 3, 'd': 100}
3.3 遍历
遍历键:key
d = {'a':1,'b':2,'c':3}
# 方法1:
for k in d: # 缺省是遍历key
print(k) # 方法2:
for k in d.keys():
print(k) # 方法3:
for k, _ in d.items():
print(k) # 输出结果如下:
a
b
c
遍历值:value
d = {'a':1,'b':2,'c':3}
# 方法1:
for v in d.values():
print(v) # 方法2:
for k in d:
# print(d[k]) # 也可以用
print(d.get(k)) # 方法3:
for _, v in d.items():
print(v) # 输出结果如下:
1
2
3
遍历item:key-value
d = {'a':1,'b':2,'c':3}
for item in d.items():
print(item) # 输出结果如下:
('a', 1)
('b', 2)
('c', 3)
其他问题
这种情况在遍历的时候,不能够删除元素,不能改变字典的size。
d = {'a':1,'b':2,'c':3}
for k in d:
print(d.pop(k)) # 输出结果如下:
RuntimeError: dictionary changed size during iteration
优雅的删除方式:
d = {'a':1,'b':2,'c':3}
key_list = []
for k in d:
key_list.append(k)
for k in key_list:
print('已删除key:', d.pop(k))
然并卵,想要清除,直接用clear()啦。
4.解析式和生成器表达式
4.1 列表解析式
语法
- [ 返回值 for 元素 in 可迭代对象 if 条件 ]
- 列表解析式用中括号'[ ]'表示
- 返回一个新的列表
优点
- 提高效率
- 代码轻量
- 可读性高
示例需求:请从给定区间中提取能够被2整除的元素。
大众普遍的写法:
list = []
for i in range(10):
if i % 2 == 0:
list.append(i)
print(list)
# 输出结果如下:
[0, 2, 4, 6, 8]
再来感受一下简单而优雅的写法:
print([i for i in range(10) if i % 2 == 0])
# 输出结果如下:
[0, 2, 4, 6, 8]
以上就是列表解析式,也叫列表推倒式。
4.2 生成器表达式
语法
- ( 返回值 for 元素 in 可迭代对象 if 条件 )
- 生成器表达式用中括号'( )'表示
- 返回一个生成器对象(generator)
特点:
- 按需计算,就是需要取值的时候才去计算(而列表解析式是一次性计算立即返回所有结果)
- 前期并不怎么占用内存,最后取值多了就跟列表解析式一样;
- 计算耗时极短,本身并不返回结果,返回的是生成器对象;
看下生成器对象是长什么样的(不要认为是元组解析式,哈哈):
x = (i for i in range(10) if i % 2 == 0)
print(type(x))
print(x)
# 输出结果如下:
<class 'generator'> # 生成器
<generator object <genexpr> at 0x000001A143ACBA98> # 生成器对象
那生成器对象是如何计算得到结果:
import time
x = (i for i in range(10) if i % 2 == 0)
for i in range(6): # 仅一次循环取值
time.sleep(0.5)
print(next(x))
time.sleep(1)
print(next(x)) # for循环已经计算完所有结果了,不能取值,故抛出异常
# 输出结果如下:
0
2
4
6
8
StopIteration # 已经超出可迭代范围,抛出异常
备注:生成器表达式只能迭代一次。
4.3 集合解析式
集合解析式和列表解析式语法类似,不做过多解析。
语法:
- { 返回值 for 元素 in 可迭代对象 if 条件 }
- 集合解析式用花括号'{ }'表示
- 返回一个集合
示例:
print({i for i in range(10) if i % 2 == 0})
# 输出结果如下:
{0, 2, 4, 6, 8}
4.4 字典解析式
字典解析式和集合解析式语法类似,不做过多解析。
语法:
- { key:value for 元素 in 可迭代对象 if 条件 }
- 字典解析式用花括号'{ }'表示
- 返回一个字典
示例:
print({i:(i+1) for i in range(10) if i % 2 == 0})
# 输出结果如下:
{0: 1, 2: 3, 4: 5, 6: 7, 8: 9}
总体来说,解析式写起来如果让人简单易懂、又高效,是非常推荐大家使用的。
但有的场景写起来很复杂,那还是得用for...in循环拆分来写。
如果喜欢的我的文章,欢迎关注我的公众号:点滴技术,扫码关注,不定期分享

Python哈希表和解析式的更多相关文章
- 04.python哈希表
python哈希表 集合Set 集合,简称集.由任意个元素构成的集体.高级语言都实现了这个非常重要的数据结构类型. Python中,它是可变的.无序的.不重复的元素的集合. 初始化 set() -&g ...
- Python哈希表的例子:dict、set
dict(字典) Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度. 和list比较,dic ...
- python数据结构与算法——哈希表
哈希表 学习笔记 参考翻译自:<复杂性思考> 及对应的online版本:http://greenteapress.com/complexity/html/thinkcomplexity00 ...
- 用python实现哈希表
哈哈,这是我第一篇博客园的博客.尝试了一下用python实现的哈希表,首先处理冲突的方法是开放地址法,冲突表达式为Hi=(H(key)+1)mod m,m为表长. #! /usr/bin/env py ...
- python数据结构之哈希表
哈希表(Hash table) 众所周知,HashMap是一个用于存储Key-Value键值对的集合,每一个键值对也叫做Entry.这些个键值对(Entry)分散存储在一个数组当中,这个数组就是Has ...
- 【Python算法】哈希存储、哈希表、散列表原理
哈希表的定义: 哈希存储的基本思想是以关键字Key为自变量,通过一定的函数关系(散列函数或哈希函数),计算出对应的函数值(哈希地址),以这个值作为数据元素的地址,并将数据元素存入到相应地址的存储单元中 ...
- 使用python实现哈希表、字典、集合
哈希表 哈希表(Hash Table, 又称为散列表),是一种线性表的存储结构.哈希表由一个直接寻址表和一个哈希函数组成.哈希函数h(k)将元素关键字k作为自变量,返回元素的存储下标. 简单哈希函数: ...
- python code practice(二):KMP算法、二分搜索的实现、哈希表
1.替换空格 题目描述:请实现一个函数,将一个字符串中的每个空格替换成“%20”.例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy. 分析: 将长度为 ...
- Python 中的哈希表
Python 中的哈希表:对字典的理解 有没有想过,Python中的字典为什么这么高效稳定.原因是他是建立在hash表上.了解Python中的hash表有助于更好的理解Python,因为Pytho ...
随机推荐
- 国产操作系统深度deepin V20体验
1. 安装系统 国产操作系统deepin V20 bata版本已经发布.本人第一时间安装和体验.在犹豫很久之后,因为受到最新内核,高版本的bash和Python的诱惑,字体更加和谐等因素,选择升级系统 ...
- UML 建模工具的安装与使用
一. 实验目的1) 学习使用 EA(Enterprise Architect) 开发环境创建模型的一般方法: 2) 理解 EA 界面布局和元素操作的一般技巧: 3) 熟悉 UML 中的各种图的建立和表 ...
- 2020年必须掌握的硬核技能k8s
Kubernetes 是一个软件系统,使你在数以万计的电脑节点上运行软件时就像 所有节点是以单个大节点一样, 它将底层基础设施抽象,这样做同时简化了应用开发.部署,以及对开发和运维团队的管理. Kub ...
- JS 获取GET 参数
对于 URL,我们需要了解更多,因为我们的开发中可能会需要提取URL的部分信息来做不同的事情,事实上这也是与后端交互的一种独特的方式,当然这肯定是安全的,当请求被返回,关于 url 的信息就被记录在了 ...
- 20199308《Linux内核原理与分析》第十一周作业
缓冲区溢出漏洞实验 实验步骤 一.初始设置 1.Ubuntu 和其他一些 Linux 系统中,使用地址空间随机化来随机堆(heap)和栈(stack)的初始地址,这使得猜测准确的内存地址变得十分困难, ...
- Openstack Swift 如何查找 slave node 挂载的 VD 的 IP
1. 在 /etc/swift/container-server.conf 或者 object-server.conf 中的 devices= 一行 可以找到 /srv/node. 在 /srv/no ...
- (转)如何学好C语言
原文:http://coolshell.cn/articles/4102.html 作者:陈皓 有人在酷壳的留言版上询问下面的问题 keep_walker : 今天晚上我看到这篇文章. http ...
- 如何把字符串数组从 Swift 传递给 C
作者:Natasha The Robot,原文链接,原文日期:2016-10-27译者:BigbigChai:校对:walkingway:定稿:CMB Swift 允许我们将原生的字符串直接传递给一个 ...
- Red 编程语言 2019 开发计划:全速前进!
开发四年只会写业务代码,分布式高并发都不会还做程序员? >>> Red 编程语言开发团队昨日发布了一篇 "Full steam ahead" 的文章,对其 2 ...
- React技术栈——Redux
Redux 1.Redux是什么? Redux对于JavaScript应用而言是一个可预测状态的容器.换言之,它是一个应用数据流框架,而不是传统的像underscore.js或者AngularJs ...