python3下scrapy爬虫(第七卷:编辑器内执行scrapy)
之前我们都是在终端切入到scrapy的路境内执行爬虫的,你要多敲多少行的字节,所以这次我们谈谈如何在编辑器里执行,这个你可以用在爬虫中,当你使用PYTHONWEB开发时尽量不要在编辑器内启动端口服务那样不容易关闭服务
先来看下我编写的爬虫文件
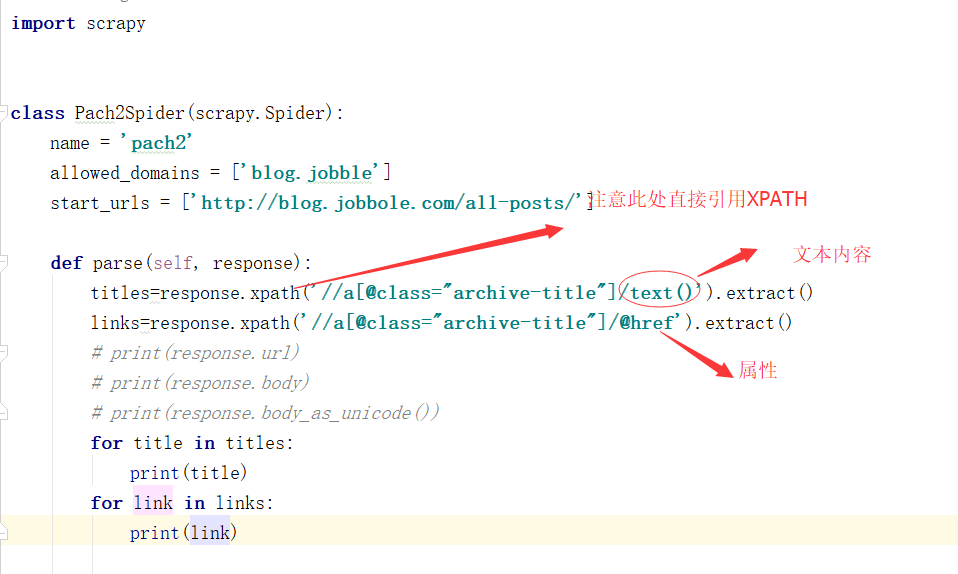
先来看下结果:
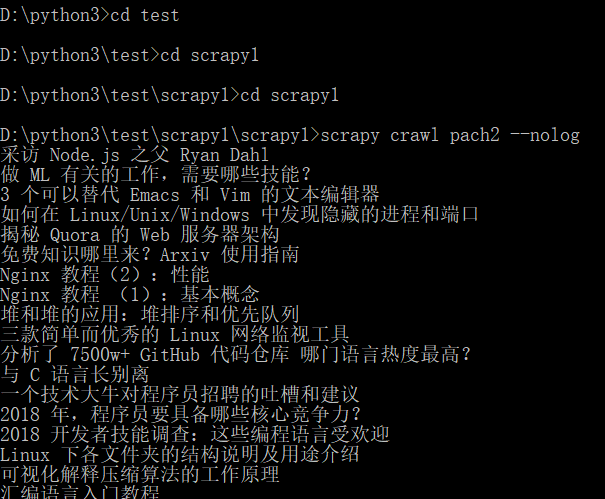
看到了吧不停的切换路径,也同时感到了xpath的强大了吧
总是切换到终端很麻烦,很多人为了炫耀自己的技术的强大都喜欢在终端各种操作,我个人觉得没有意义,明明走直线到家非得拐个弯
现在我们在文件中创建main.py文件 看一下路径 这个文件执行时是调动整个scrapy文件,那么文件创建的路径应该在外,看一下我编辑的位置
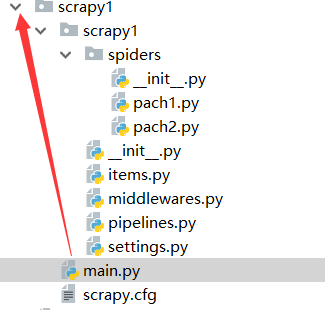
清晰明了 之前我写过pyMySQL的一篇随笔里面函数的用法和这里很相似

现在看下结果 看看哪个方便

python3下scrapy爬虫(第七卷:编辑器内执行scrapy)的更多相关文章
- python3下scrapy爬虫(第五卷:初步抓取网页内容之scrapy全面应用)
现在爬取http://category.dangdang.com/pg1-cid4008149.html网址上的商品价格,名称,评价数量 先准备下下数据:商品名,商品链接,评价数量 第一步:在item ...
- 同时运行多个scrapy爬虫的几种方法(自定义scrapy项目命令)
试想一下,前面做的实验和例子都只有一个spider.然而,现实的开发的爬虫肯定不止一个.既然这样,那么就会有如下几个问题:1.在同一个项目中怎么创建多个爬虫的呢?2.多个爬虫的时候是怎么将他们运行起来 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- python3下scrapy爬虫(第三卷:初步抓取网页内容之抓取网页里的指定数据)
上一卷中我们抓取了网页的所有内容,现在我们抓取下网页的图片名称以及连接 现在我再新建个爬虫文件,名称设置为crawler2 做爬虫的朋友应该知道,网页里的数据都是用文本或者块级标签包裹着的,scrap ...
- python3下scrapy爬虫(第十一卷:scrapy数据存储进mongodb)
说起python爬虫数据存储就不得不说到mongodb,现在我们来试一下scrapy操作mongodb 首先开启mongodb mongod --dbpath=D:\mongodb\db 开启服务后就 ...
- python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
之前我们的爬虫都是单机爬取,也是单机维护REQUEST队列, 看一下单机的流程图: 一台主机控制一个队列,现在我要把它放在多机执行,会产生一个事情就是做重复的爬取,毫无意义,所以分布式爬虫的第一个难点 ...
- python3下scrapy爬虫(第十卷:scrapy数据存储进mysql)
上一卷中我将爬取的数据文件直接写入文本文件中,现在我将数据存储到mysql中,我依然用的是pymysql,这个很麻烦建表需要在外面建 这次代码只需要改变pipyline就行 来 现在看下结果: 对比发 ...
- python3下scrapy爬虫(第六卷:利用cookie模拟登陆抓取个人中心页面)
之前我们爬取的都是那些无需登录就要可以使用的网站但是当我们想爬取自己或他人的个人中心时就需要做登录,一般进入登录页面有两种 ,一个是独立页面登陆,另一个是弹窗,我们先不管验证码登陆的问题 ,现在试一下 ...
- python3下scrapy爬虫(第八卷:循环爬取网页多页数据)
之前我们做的数据爬取都是单页的现在我们来讲讲多页的 一般方式有两种目标URL循环抓取 另一种在主页连接上找规律,现在我用的案例网址就是 通过点击下一页的方式获取多页资源 话不多说全在代码里(因为刚才写 ...
随机推荐
- python语法基础-并发编程-进程-进程理论和进程的开启
############################################## """ 并发编程的相关概念: 进程 1,运行中的程序,就是进程,程序是没有生 ...
- TCP/IP与IETF的RFC
究竟是谁控制着 TCP/IP协议族,又是谁在定义新的标准以及其他类似的事情?事实上, 有四个小组在负责Internet技术. 1) Internet协会(ISOC,Internet Society)是 ...
- Python笔记_第四篇_高阶编程_正则表达式_1.正则表达式简介(re模块)
1. 从一个判断手机号的问题引入: 如果给你一个字符串,去判断是否是一个手机号码,我们通过之前的学习可以有如下代码: # 如果用普通的方式去检验一个电话号码非常麻烦. def checkPhone(s ...
- 计蒜客 一维坐标的移动(BFS)
在一个长度为 n 的坐标轴上,蒜头君想从 A 点 移动到 B 点.他的移动规则如下: 向前一步,坐标增加 1. 向后一步,坐标减少 1. 跳跃一步,使得坐标乘 2. 蒜头君不能移动到坐标小于 0 或大 ...
- 题解 P1829 【[国家集训队]Crash的数字表格 / JZPTAB】
题目 我的第一篇莫比乌斯反演题解 兴奋兴奋兴奋 贡献一个本人自己想的思路,你从未看到过的船新思路 [分析] 显然,题目要求求的是 \(\displaystyle Ans=\sum_{i=1}^n\su ...
- Pmw大控件
Python大控件——Pmw——是合成的控件,以Tkinter控件为基类,是完全在Python内写的.它们可以很方便地增加功能性的应用,而不必写一堆代码.特别是,组合框和内部确认计划的输入字段放在一起 ...
- Spring注解配置和xml配置优缺点比较
Spring注解配置和xml配置优缺点比较 编辑 在昨天发布的文章<spring boot基于注解方式配置datasource>一文中凯哥简单的对xml配置和注解配置进行了比较.然后朋 ...
- Myeclipse 10/2014 配置插件(svn、maven、properties、velocity)的方法
一.配置SVN详细图解 什么是SVN? 管理软件开发过程中的版本控制工具. 下面会以两种方式来介绍怎么安装svn,myeclipse安装SVN插件步骤,以myeclipse 2014为例,第一种是最常 ...
- 数字转中文大写=> 1234=> 一千二百三十四
# -*- coding: utf-8 -*- # 最大值:九兆九千九百九十九亿九千九百九十九万九千九百九十九 import re p = ['', '十', '百', '千', '万', '十', ...
- 吴裕雄--天生自然 PYTHON3开发学习:迭代器与生成器
list=[1,2,3,4] it = iter(list) # 创建迭代器对象 for x in it: print (x, end=" ") import sys # 引入 s ...