02 HDFS 分布式环境实战
HDFS的主要设计理念
1、存储超大文件 这里的“超大文件”是指几百MB、GB甚至TB级别的文件。
2、最高效的访问模式是 一次写入、多次读取(流式数据访问)
3、运行在普通廉价的服务器上 HDFS设计理念之一就是让它能运行在普通的硬件之上,即便硬件出现故障,也可以通过容错策略来保证数据的高可用。
HDFS的缺点
1、将HDFS用于对数据访问要求低延迟的场景 由于HDFS是为高数据吞吐量应用而设计的,必然以高延迟为代价。
2、存储大量小文件 HDFS中元数据(文件的基本信息)存储在namenode的内存中,而namenode为单点,小文件 数量大到一定程度,namenode内存就吃不消了
HDFS分布式文件系统
hdfs:分布式文件系统
hdfs有着文件系统共同的特征:
1、有目录结构,顶层目录是: /
2、系统中存放的就是文件
3、系统可以提供对文件的:创建、删除、修改、查看、移动等功能 hdfs跟普通的单机文件系统有区别:
1、单机文件系统中存放的文件,是在一台机器的操作系统中
2、hdfs的文件系统会横跨N多的机器
3、单机文件系统中存放的文件,是在一台机器的磁盘上
4、hdfs文件系统中存放的文件,是落在n多机器的本地单机文件系统中(hdfs是一个基于linux本地文件系统之上的文件系统) hdfs的工作机制:
1、客户把一个文件存入hdfs,其实hdfs会把这个文件切块后,分散存储在N台linux机器系统中(负责存储文件块的角色:data node)<准确来说:切块的行为是由客户端决定的> 2、一旦文件被切块存储,那么,hdfs中就必须有一个机制,来记录用户的每一个文件的切块信息,及每一块的具体存储机器(负责记录块信息的角色是:name node) 3、为了保证数据的安全性,hdfs可以将每一个文件块在集群中存放多个副本(到底存几个副本,是由当时存入该文件的客户端指定的) 综述:一个hdfs系统,由一台运行了namenode的服务器,和N台运行了datanode的服务器组成!
搭建hdfs分布式集群
一、首先需要准备N台linux服务器
学习阶段,用虚拟机即可!
先准备4台虚拟机:1个namenode节点 + 3 个datanode 节点
二、修改各台机器的主机名和ip地址
主机名: hdp-01 对应的ip地址: 192.168.11.25
主机名: hdp-02 对应的ip地址: 192.168.11.26
主机名: hdp-03 对应的ip地址: 192.168.11.27
主机名: hdp-04 对应的ip地址: 192.168.11.28
三、从windows中用CRT软件进行远程连接
在windows中将各台linux机器的主机名配置到的windows的本地域名映射文件中:
c:/windows/system32/drivers/etc/hosts
192.168.11.25 hdp-01
192.168.11.26 hdp-02
192.168.11.27 hdp-03
192.168.11.28 hdp-04
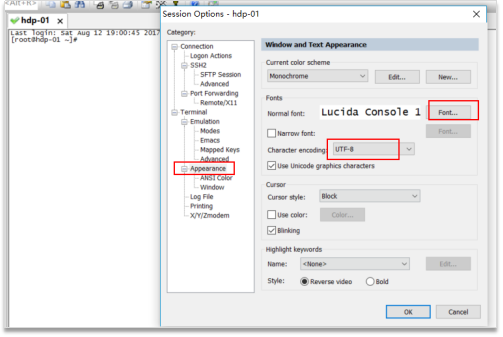
用crt连接上后,修改一下crt的显示配置(字号,编码集改为UTF-8):
四、配置linux服务器的基础软件环境
关闭防火墙
关闭防火墙:systemctl stop firewalld
关闭防火墙自启动: systemctl disable firewalld
安装JDK
1)利用alt+p 打开sftp窗口,然后将jdk压缩包拖入sftp窗口 2)然后在linux中将jdk压缩包解压到/root/apps 下 3)配置环境变量:JAVA_HOME PATH
vi /etc/profile 在文件的最后,加入:
export JAVA_HOME=/root/apps/jdk1.8.0_60
export PATH=$PATH:$JAVA_HOME/bin 4)修改完成后,记得 source /etc/profile使配置生效 5)检验:在任意目录下输入命令: java -version 看是否成功执行 6)将安装好的jdk目录用scp命令拷贝到其他机器 7)将/etc/profile配置文件也用scp命令拷贝到其他机器并分别执行source命令
在hdp-01上,vi /etc/hosts
192.168.11.25 hdp-01
192.168.11.26 hdp-02
192.168.11.27 hdp-03
192.168.11.28 hdp-04
将hosts文件拷贝到集群中的所有其他机器上
scp /etc/hosts hdp-02:/etc/
scp /etc/hosts hdp-03:/etc/
scp /etc/hosts hdp-04:/etc/
五、 安装hdfs集群
1、上传hadoop安装包到hdp-01
1)利用alt+p 打开sftp窗口,然后将jdk压缩包拖入sftp窗口
2)然后在linux中将hadoop-2.8.0压缩包解压到/root/apps下
2、修改配置文件
核心配置参数:
1)指定hadoop的默认文件系统为:hdfs 2)指定hdfs的namenode节点为哪台机器 3)指定namenode软件存储元数据的本地目录 4)指定datanode软件存放文件块的本地目录
hadoop的配置文件在:/root/apps/hadoop安装目录/etc/hadoop/
1)修改hadoop-env.sh
export JAVA_HOME=/root/apps/jdk1.8.0_60
2) 修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdp01:9000</value>
</property>
</configuration>
3) 修改hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/dfs/name</value>
</property> <property>
<name>dfs.datanode.data.dir</name>
<value>/root/dfs/data</value>
</property> </configuration>
4) 拷贝整个hadoop安装目录到其他机器
scp -r /root/apps/hadoop-2.8.0 hdp02:/root/apps/
scp -r /root/apps/hadoop-2.8.0 hdp03:/root/apps/
scp -r /root/apps/hadoop-2.8.0 hdp04:/root/apps/
5) 启动HDFS
首先,初始化namenode的元数据目录
要在hdp-01上执行hadoop的一个命令来初始化namenode的元数据存储目录
hadoop namenode -format
创建一个全新的元数据存储目录
生成记录元数据的文件fsimage
生成集群的相关标识:如:集群id——clusterID 然后,启动namenode进程(在hdp-01上)
hadoop-daemon.sh start namenode
启动完后,首先用jps查看一下namenode的进程是否存在 然后,在windows中用浏览器访问namenode提供的web端口:50070
http://hdp-01:50070 然后,启动众datanode们(在任意地方)
hadoop-daemon.sh start datanode
6) 用自动批量启动脚本来启动HDFS
a.先配置hdp01到集群中所有机器(包含自己)的免密登陆
b.配完免密后,可以执行一次 ssh 0.0.0.0
c.修改hadoop安装目录中/etc/hadoop/slaves(把需要启动datanode进程的节点列入)
hdp-01
hdp-02
hdp-03
hdp-04
d.在hdp01上用脚本:start-dfs.sh 来自动启动整个集群
e.如果要停止,则用脚本:stop-dfs.sh
02 HDFS 分布式环境实战的更多相关文章
- 【转】Hadoop HDFS分布式环境搭建
原文地址 http://blog.sina.com.cn/s/blog_7060fb5a0101cson.html Hadoop HDFS分布式环境搭建 最近选择给大家介绍Hadoop HDFS系统 ...
- HDFS 分布式环境搭建
HDFS 分布式环境搭建 作者:Grey 原文地址: 博客园:HDFS 分布式环境搭建 CSDN:HDFS 分布式环境搭建 准备四个Linux实例 每个实例对应的 host 和 ip 地址如下 nod ...
- Alluxio1.0.1最新版(Tachyon为其前身)介绍,+HDFS分布式环境搭建
Alluxio(之前名为Tachyon)是世界上第一个以内存为中心的虚拟的分布式存储系统.它统一了数据访问的方式,为上层计算框架和底层存储系统构建了桥梁. 应用只需要连接Alluxio即可访问存储在底 ...
- 《OD大数据实战》Hadoop伪分布式环境搭建
一.安装并配置Linux 8. 使用当前root用户创建文件夹,并给/opt/下的所有文件夹及文件赋予775权限,修改用户组为当前用户 mkdir -p /opt/modules mkdir -p / ...
- 大数据:Hadoop(JDK安装、HDFS伪分布式环境搭建、HDFS 的shell操作)
所有的内容都来源与 Hadoop 官方文档 一.Hadoop 伪分布式安装步骤 1)JDK安装 解压:tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app 添加到系 ...
- HDFS 伪分布式环境搭建
HDFS 伪分布式环境搭建 作者:Grey 原文地址: 博客园:HDFS 伪分布式环境搭建 CSDN:HDFS 伪分布式环境搭建 相关软件版本 Hadoop 2.6.5 CentOS 7 Oracle ...
- HDFS 高可用分布式环境搭建
HDFS 高可用分布式环境搭建 作者:Grey 原文地址: 博客园:HDFS 高可用分布式环境搭建 CSDN:HDFS 高可用分布式环境搭建 首先,一定要先完成分布式环境搭建 并验证成功 然后在 no ...
- Hadoop框架:集群模式下分布式环境搭建
本文源码:GitHub·点这里 || GitEE·点这里 一.基础环境配置 1.三台服务 准备三台Centos7服务,基础环境从伪分布式环境克隆过来. 133 hop01,134 hop02,136 ...
- ZooKeeper学习第五期--ZooKeeper管理分布式环境中的数据
引言 本节本来是要介绍ZooKeeper的实现原理,但是ZooKeeper的原理比较复杂,它涉及到了paxos算法.Zab协议.通信协议等相关知识,理解起来比较抽象所以还需要借助一些应用场景,来帮我们 ...
随机推荐
- php 二维码
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- F5 BIG-IP之二LTM术语
Node : Pool:中有设置负载均衡方式 Virtual Server :监听客户端请求的 根据 IP 和 端口号 Profile: VS 调用 Profile
- derby数据库
derby数据库 https://www.cnblogs.com/zuzZ/p/8107915.html Derby数据库的使用 https://www.cnblogs.com/wkfvawl/p/1 ...
- java中的锁——列队同步器
队列同步器 队列同步器(AbstractQueuedSynchronizer)为实现依赖于先进先出 (FIFO) 等待队列的阻塞锁和相关同步器(信号量.事件,等等)提供一个框架.此类的设计目标是成为依 ...
- Fault Domain深入分析
- fiddler模拟返回响应数据
通过find查找修改指定内容 选择find a file 保存后重新发起请求
- SpringBoot自动配置的原理
Spring Boot的运行是由注解@EnableAutoConfiguration提供的它的关键功能是@Import注解. EnableAutoConfigurationImportS ...
- C++入门级小算法
反序输出一个整数 #include <iostream> using namespace std; int main() { int n; while (cin >> n)// ...
- [洛谷P3386] [模板] 二分图匹配 (匈牙利算法)
题目传送门 毒瘤出题人zzk出了个二分图匹配的题(18.10.04模拟赛T2),逼我来学二分图匹配. 网络流什么的llx讲完之后有点懵,还是匈牙利比较好理解(绿与被绿). 对于左边的点一个一个匹配,记 ...
- 【转】蛋糕尺寸(寸)、尺寸(CM)、重量(磅)、食用人数对照换算参考表
转自:https://www.douban.com/note/324832054/ 蛋糕尺寸(寸).尺寸(CM).重量(磅).食用人数对照换算参考表 馋嘴猫DIY烘焙 2014-01-04 12:15 ...