TensorFlow从0到1之TensorFlow优化器(13)
高中数学学过,函数在一阶导数为零的地方达到其最大值和最小值。梯度下降算法基于相同的原理,即调整系数(权重和偏置)使损失函数的梯度下降。
在回归中,使用梯度下降来优化损失函数并获得系数。本节将介绍如何使用 TensorFlow 的梯度下降优化器及其变体。
按照损失函数的负梯度成比例地对系数(W 和 b)进行更新。根据训练样本的大小,有三种梯度下降的变体:
- Vanilla 梯度下降:在 Vanilla 梯度下降(也称作批梯度下降)中,在每个循环中计算整个训练集的损失函数的梯度。该方法可能很慢并且难以处理非常大的数据集。该方法能保证收敛到凸损失函数的全局最小值,但对于非凸损失函数可能会稳定在局部极小值处。
- 随机梯度下降:在随机梯度下降中,一次提供一个训练样本用于更新权重和偏置,从而使损失函数的梯度减小,然后再转向下一个训练样本。整个过程重复了若干个循环。由于每次更新一次,所以它比 Vanilla 快,但由于频繁更新,所以损失函数值的方差会比较大。
- 小批量梯度下降:该方法结合了前两者的优点,利用一批训练样本来更新参数。
TensorFlow优化器的使用
首先确定想用的优化器。TensorFlow 为你提供了各种各样的优化器:
- 这里从最流行、最简单的梯度下降优化器开始:
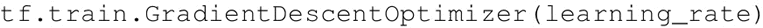
GradientDescentOptimizer 中的 learning_rate 参数可以是一个常数或张量。它的值介于 0 和 1 之间。
必须为优化器给定要优化的函数。使用它的方法实现最小化。该方法计算梯度并将梯度应用于系数的学习。该函数在 TensorFlow 文档中的定义如下:

综上所述,这里定义计算图:

馈送给 feed_dict 的 X 和 Y 数据可以是 X 和 Y 个点(随机梯度)、整个训练集(Vanilla)或成批次的。
- 梯度下降中的另一个变化是增加了动量项。为此,使用优化器 tf.train.MomentumOptimizer()。它可以把 learning_rate 和 momentum 作为初始化参数:
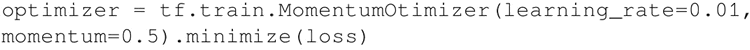
- 可以使用 tf.train.AdadeltaOptimizer() 来实现一个自适应的、单调递减的学习率,它使用两个初始化参数 learning_rate 和衰减因子 rho:

- TensorFlow 也支持 Hinton 的 RMSprop,其工作方式类似于 Adadelta 的 tf.train.RMSpropOptimizer():
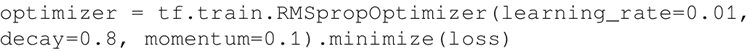
Adadelta 和 RMSprop 之间的细微不同可参考 http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf 和 https://arxiv.org/pdf/1212.5701.pdf。
- 另一种 TensorFlow 支持的常用优化器是 Adam 优化器。该方法利用梯度的一阶和二阶矩对不同的系数计算不同的自适应学习率:
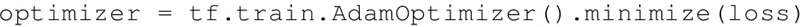
- 除此之外,TensorFlow 还提供了以下优化器:

通常建议你从较大学习率开始,并在学习过程中将其降低。这有助于对训练进行微调。可以使用 TensorFlow 中的 tf.train.exponential_decay 方法来实现这一点。
根据 TensorFlow 文档,在训练模型时,通常建议在训练过程中降低学习率。该函数利用指数衰减函数初始化学习率。需要一个 global_step 值来计算衰减的学习率。可以传递一个在每个训练步骤中递增的 TensorFlow 变量。函数返回衰减的学习率。
变量:
- learning_rate:标量float32或float64张量或者Python数字。初始学习率。
- global_step:标量int32或int64张量或者Python数字。用于衰减计算的全局步数,非负。
- decay_steps:标量int32或int64张量或者Python数字。正数,参考之前所述的衰减计算。
- decay_rate:标量float32或float64张量或者Python数字。衰减率。
- staircase:布尔值。若为真则以离散的间隔衰减学习率。
- name:字符串。可选的操作名。默认为ExponentialDecay。
返回:
- 与learning_rate类型相同的标量张量。衰减的学习率。
实现指数衰减学习率的代码如下:

推荐阅读
下面是讲解不同优化器的链接:
- https://arxiv.org/pdf/1609.04747.pdf:该文章提供了不同优化器算法的综述。
- https://www.tensorflow.org/api_guides/python/train#Optimizers:这是 TensorFlow.org 链接,详述了 TensorFlow 中优化器的使用方法。
- https://arxiv.org/pdf/1412.6980.pdf:关于 Adam 优化器的论文。
TensorFlow从0到1之TensorFlow优化器(13)的更多相关文章
- TensorFlow从0到1之TensorFlow Keras及其用法(25)
Keras 是与 TensorFlow 一起使用的更高级别的作为后端的 API.添加层就像添加一行代码一样简单.在模型架构之后,使用一行代码,你可以编译和拟合模型.之后,它可以用于预测.变量声明.占位 ...
- TensorFlow从0到1之TensorFlow多层感知机函数逼近过程(23)
Hornik 等人的工作(http://www.cs.cmu.edu/~bhiksha/courses/deeplearning/Fall.2016/notes/Sonia_Hornik.pdf)证明 ...
- TensorFlow从0到1之TensorFlow实现反向传播算法(21)
反向传播(BPN)算法是神经网络中研究最多.使用最多的算法之一,它用于将输出层中的误差传播到隐藏层的神经元,然后用于更新权重. 学习 BPN 算法可以分成以下两个过程: 正向传播:输入被馈送到网络,信 ...
- TensorFlow从0到1之TensorFlow超参数及其调整(24)
正如你目前所看到的,神经网络的性能非常依赖超参数.因此,了解这些参数如何影响网络变得至关重要. 常见的超参数是学习率.正则化器.正则化系数.隐藏层的维数.初始权重值,甚至选择什么样的优化器优化权重和偏 ...
- TensorFlow从0到1之TensorFlow多层感知机实现MINIST分类(22)
TensorFlow 支持自动求导,可以使用 TensorFlow 优化器来计算和使用梯度.它使用梯度自动更新用变量定义的张量.本节将使用 TensorFlow 优化器来训练网络. 前面章节中,我们定 ...
- TensorFlow从0到1之TensorFlow实现单层感知机(20)
简单感知机是一个单层神经网络.它使用阈值激活函数,正如 Marvin Minsky 在论文中所证明的,它只能解决线性可分的问题.虽然这限制了单层感知机只能应用于线性可分问题,但它具有学习能力已经很好了 ...
- TensorFlow从0到1之TensorFlow实现多元线性回归(16)
在 TensorFlow 实现简单线性回归的基础上,可通过在权重和占位符的声明中稍作修改来对相同的数据进行多元线性回归. 在多元线性回归的情况下,由于每个特征具有不同的值范围,归一化变得至关重要.这里 ...
- TensorFlow从0到1之TensorFlow实现简单线性回归(15)
本节将针对波士顿房价数据集的房间数量(RM)采用简单线性回归,目标是预测在最后一列(MEDV)给出的房价. 波士顿房价数据集可从http://lib.stat.cmu.edu/datasets/bos ...
- TensorFlow从0到1之TensorFlow常用激活函数(19)
每个神经元都必须有激活函数.它们为神经元提供了模拟复杂非线性数据集所必需的非线性特性.该函数取所有输入的加权和,进而生成一个输出信号.你可以把它看作输入和输出之间的转换.使用适当的激活函数,可以将输出 ...
随机推荐
- CF861D
题目链接:http://codeforces.com/contest/861/problem/D 解题思路: 优雅的暴力. 对于输入的每一个号码,从短到长找出它的所有子串,用 vector 保存每个号 ...
- 设计模式系列之单例模式(Singleton Pattern)——确保对象的唯一性
模式概述 模式定义 模式结构图 饿汉式单例与懒汉式单例 饿汉式单例 懒汉式单例 模式应用 模式在JDK中的应用 模式在开源项目中的应用 模式总结 主要优点 适用场景 说明:设计模式系列文章是读刘伟所著 ...
- Excel中遇到的一些问题——持续更新
Q1:excel2007表格里的数字在表格关闭后再打开经常会变成日期格式,怎么解决? A1: 1)打开Excel,选中任意单元格,单击鼠标右键,选择设置单元格格式2)在数字自定义类型中,找到类似[$- ...
- 公众号使用微信sdk的正确姿势
当我们做微信登录授权,微信公众号的分享,微信的h5支付等等等等的时候难免会用到微信sdk,当我们用react或vue做的spa应用,直接引入后会发现,在按安卓上可以正常调试,而ios上一直报签名错误( ...
- Mysql与Mysqli的区别及特点
1)PHP-MySQL 是 PHP 操作 MySQL 资料库最原始的 Extension ,PHP-MySQLi 的 i 代表 Improvement ,提更了相对进阶的功能,就 Extension ...
- docker的file内容解释
关键字---重点啊) FROM 基础镜像,当前新镜像是基于哪个镜像的 MAINTAINER 镜像维护者的姓名和邮箱地址 RUN 容器构建时需要运行的命令 EXPOSE 当前容器对外暴露的端口 WO ...
- Kubernetes学习笔记(八):Deployment--声明式的升级应用
概述 本文核心问题是:如何升级应用. 对于Pod的更新有两种策略: 一是删除全部旧Pod之后再创建新Pod.好处是,同一时间只会有一个版本的应用存在:缺点是,应用有一段时间不可用. 二是先创建新Pod ...
- NO.4 CCS运行第一个demo(本地)
前面介绍了基本的SDK内容,这次主要是本地实际应用CCS实现程序的运行. 首先我们进入CCS,我简单介绍下界面: 界面很简洁,通俗易懂(怎么跟STM32IDE这么像) 由于我们还不会写程序,我们先导入 ...
- 【Gabor】基于多尺度多方向Gabor融合+分块直方图的表情识别
Topic:表情识别Env: win10 + Pycharm2018 + Python3.6.8Date: 2019/6/23~25 by hw_Chen2018 ...
- ReentrantLock解析及源码分析
本文结构 Tips:说明一部分概念及阅读源码需要的基础内容 ReentrantLock简介 公平机制:对于公平机制和非公平机制进行介绍,包含对比 实现:Sync源码解析额,公平和非公平模式的加锁.解锁 ...