机器学习(ML)一之 Linear Regression
一、线性回归
1、模型
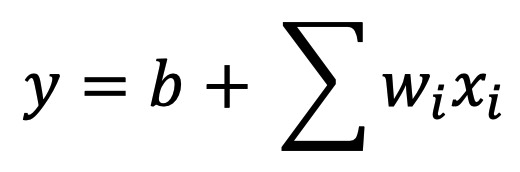
2、损失函数

3、优化函数-梯度下降

#!/usr/bin/env python
# coding: utf-8
import torch
import time # init variable a, b as 1000 dimension vector
n = 1000
a = torch.ones(n)
b = torch.ones(n)
# define a timer class to record time
class Timer(object):
"""Record multiple running times."""
def __init__(self):
self.times = []
self.start() def start(self):
# start the timer
self.start_time = time.time() def stop(self):
# stop the timer and record time into a list
self.times.append(time.time() - self.start_time)
return self.times[-1] def avg(self):
# calculate the average and return
return sum(self.times)/len(self.times) def sum(self):
# return the sum of recorded time
return sum(self.times)
timer = Timer()
c = torch.zeros(n)
for i in range(n):
c[i] = a[i] + b[i]
'%.5f sec' % timer.stop() timer.start()
d = a + b
'%.5f sec' % timer.stop() # import packages and modules
get_ipython().run_line_magic('matplotlib', 'inline')
import torch
from IPython import display
from matplotlib import pyplot as plt
import numpy as np
import random print(torch.__version__) # ### 线性回归模型从零开始的实现 # set input feature number
num_inputs = 2
# set example number
num_examples = 1000 # set true weight and bias in order to generate corresponded label
true_w = [2, -3.4]
true_b = 4.2 features = torch.randn(num_examples, num_inputs,
dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),
dtype=torch.float32) # ### 使用图像来展示生成的数据 plt.scatter(features[:, 1].numpy(), labels.numpy(), 1); # ### 读取数据集 def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices) # random read 10 samples
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) # the last time may be not enough for a whole batch
yield features.index_select(0, j), labels.index_select(0, j) batch_size = 10 for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
break # ### 模型初始化 w = torch.tensor(np.random.normal(0, 0.01, (num_inputs, 1)), dtype=torch.float32)
b = torch.zeros(1, dtype=torch.float32) w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True) # ### 定义模型
# 定义用来训练参数的训练模型:
# $$ \mathrm{price} = w_{\mathrm{area}} \cdot \mathrm{area} + w_{\mathrm{age}} \cdot \mathrm{age} + b $$ # In[19]: def linreg(X, w, b):
return torch.mm(X, w) + b # ### 定义损失函数
# 我们使用的是均方误差损失函数:
# $$l^{(i)}(\mathbf{w}, b) = \frac{1}{2} \left(\hat{y}^{(i)} - y^{(i)}\right)^2,$$ # In[16]: def squared_loss(y_hat, y):
return (y_hat - y.view(y_hat.size())) ** 2 / 2 # ### 定义优化函数
# 在这里优化函数使用的是小批量随机梯度下降:
# $$(\mathbf{w},b) \leftarrow (\mathbf{w},b) - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \partial_{(\mathbf{w},b)} l^{(i)}(\mathbf{w},b)$$ # In[17]: def sgd(params, lr, batch_size):
for param in params:
param.data -= lr * param.grad / batch_size # ues .data to operate param without gradient track # ### 训练
# 当数据集、模型、损失函数和优化函数定义完了之后就可来准备进行模型的训练了。 # In[20]: # super parameters init
lr = 0.03
num_epochs = 5 net = linreg
loss = squared_loss # training
for epoch in range(num_epochs): # training repeats num_epochs times
# in each epoch, all the samples in dataset will be used once # X is the feature and y is the label of a batch sample
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y).sum()
# calculate the gradient of batch sample loss
l.backward()
# using small batch random gradient descent to iter model parameters
sgd([w, b], lr, batch_size)
# reset parameter gradient
w.grad.data.zero_()
b.grad.data.zero_()
train_l = loss(net(features, w, b), labels)
print('epoch %d, loss %f' % (epoch + 1, train_l.mean().item())) # In[21]: w, true_w, b, true_b # ### 线性回归模型使用pytorch的简洁实现 # In[22]: import torch
from torch import nn
import numpy as np
torch.manual_seed(1) print(torch.__version__)
torch.set_default_tensor_type('torch.FloatTensor') # ### 生成数据集
# 在这里生成数据集跟从零开始的实现中是完全一样的。 # In[23]: num_inputs = 2
num_examples = 1000 true_w = [2, -3.4]
true_b = 4.2 features = torch.tensor(np.random.normal(0, 1, (num_examples, num_inputs)), dtype=torch.float)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()), dtype=torch.float) # ### 读取数据集 # In[24]: import torch.utils.data as Data batch_size = 10 # combine featues and labels of dataset
dataset = Data.TensorDataset(features, labels) # put dataset into DataLoader
data_iter = Data.DataLoader(
dataset=dataset, # torch TensorDataset format
batch_size=batch_size, # mini batch size
shuffle=True, # whether shuffle the data or not
num_workers=2, # read data in multithreading
) # In[27]: for X, y in data_iter:
print(X, '\n', y)
break # ### 定义模型 # In[28]: class LinearNet(nn.Module):
def __init__(self, n_feature):
super(LinearNet, self).__init__() # call father function to init
self.linear = nn.Linear(n_feature, 1) # function prototype: `torch.nn.Linear(in_features, out_features, bias=True)` def forward(self, x):
y = self.linear(x)
return y net = LinearNet(num_inputs)
print(net) # In[29]: # ways to init a multilayer network
# method one
net = nn.Sequential(
nn.Linear(num_inputs, 1)
# other layers can be added here
) # method two
net = nn.Sequential()
net.add_module('linear', nn.Linear(num_inputs, 1))
# net.add_module ...... # method three
from collections import OrderedDict
net = nn.Sequential(OrderedDict([
('linear', nn.Linear(num_inputs, 1))
# ......
])) print(net)
print(net[0]) # ### 初始化模型参数 # In[30]: from torch.nn import init init.normal_(net[0].weight, mean=0.0, std=0.01)
init.constant_(net[0].bias, val=0.0) # or you can use `net[0].bias.data.fill_(0)` to modify it directly # In[31]: for param in net.parameters():
print(param) # ### 定义损失函数 # In[32]: loss = nn.MSELoss() # nn built-in squared loss function
# function prototype: `torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')` # ### 定义优化函数 # In[33]: import torch.optim as optim optimizer = optim.SGD(net.parameters(), lr=0.03) # built-in random gradient descent function
print(optimizer) # function prototype: `torch.optim.SGD(params, lr=, momentum=0, dampening=0, weight_decay=0, nesterov=False)` # In[34]: ##trainning
num_epochs = 3
for epoch in range(1, num_epochs + 1):
for X, y in data_iter:
output = net(X)
l = loss(output, y.view(-1, 1))
optimizer.zero_grad() # reset gradient, equal to net.zero_grad()
l.backward()
optimizer.step()
print('epoch %d, loss: %f' % (epoch, l.item())) # In[35]: # result comparision
dense = net[0]
print(true_w, dense.weight.data)
print(true_b, dense.bias.data) # In[ ]:
机器学习(ML)一之 Linear Regression的更多相关文章
- Coursera台大机器学习课程笔记8 -- Linear Regression
之前一直在讲机器为什么能够学习,从这节课开始讲一些基本的机器学习算法,也就是机器如何学习. 这节课讲的是线性回归,从使Ein最小化出发来,介绍了 Hat Matrix,要理解其中的几何意义.最后对比了 ...
- 斯坦福机器学习视频笔记 Week1 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- 机器学习 (二) 多变量线性回归 Linear Regression with Multiple Variables
文章内容均来自斯坦福大学的Andrew Ng教授讲解的Machine Learning课程,本文是针对该课程的个人学习笔记,如有疏漏,请以原课程所讲述内容为准.感谢博主Rachel Zhang 的个人 ...
- 从零单排入门机器学习:线性回归(linear regression)实践篇
线性回归(linear regression)实践篇 之前一段时间在coursera看了Andrew ng的机器学习的课程,感觉还不错,算是入门了. 这次打算以该课程的作业为主线,对机器学习基本知识做 ...
- 机器学习-TensorFlow建模过程 Linear Regression线性拟合应用
TensorFlow是咱们机器学习领域非常常用的一个组件,它在数据处理,模型建立,模型验证等等关于机器学习方面的领域都有很好的表现,前面的一节我已经简单介绍了一下TensorFlow里面基础的数据结构 ...
- 【原】Coursera—Andrew Ng机器学习—Week 1 习题—Linear Regression with One Variable 单变量线性回归
Question 1 Consider the problem of predicting how well a student does in her second year of college/ ...
- 【原】Coursera—Andrew Ng机器学习—Week 2 习题—Linear Regression with Multiple Variables 多变量线性回归
Gradient Descent for Multiple Variables [1]多变量线性模型 代价函数 Answer:AB [2]Feature Scaling 特征缩放 Answer:D ...
- Andrew Ng机器学习 五:Regularized Linear Regression and Bias v.s. Variance
背景:实现一个线性回归模型,根据这个模型去预测一个水库的水位变化而流出的水量. 加载数据集ex5.data1后,数据集分为三部分: 1,训练集(training set)X与y: 2,交叉验证集(cr ...
- Andrew Ng机器学习编程作业:Regularized Linear Regression and Bias/Variance
作业文件: machine-learning-ex5 1. 正则化线性回归 在本次练习的前半部分,我们将会正则化的线性回归模型来利用水库中水位的变化预测流出大坝的水量,后半部分我们对调试的学习算法进行 ...
- 机器学习基石:09 Linear Regression
线性回归假设: 代价函数------均方误差: 最小化样本内代价函数: 只有满秩方阵才有逆矩阵. 线性回归算法流程: 线性回归算法是隐式迭代的. 线性回归算法泛化可能的保证: 根据矩阵的迹的性质:tr ...
随机推荐
- 通过Java创建XML(中文乱码已解决)
package com.zyb.xml; import java.io.FileOutputStream; import java.io.OutputStream; import java.io.Ou ...
- SpringMVC 接收表单数据、数据绑定、解决请求参数中文乱码
接收表单数据有3种方式. 1.使用简单类型接收表单数据(绑定简单数据类型) 表单: <form action="${pageContext.request.contextPath}/u ...
- 「CH6201」走廊泼水节
「CH6201」走廊泼水节 传送门 考虑 \(\text{Kruskal}\) 的过程以及用到一个最小生成树的性质即可. 在联通两个联通块时,我们肯定会选择最小的一条边来连接这两个联通块,那么这两个联 ...
- 设计模式课程 设计模式精讲 8-8 单例设计模式-Enum枚举单例、原理源码解析以及反编译实战
1 课堂解析 2 代码演练 2.1 枚举类单例解决序列化破坏demo 2.2 枚举类单例解决序列化破坏原理 2.3 枚举类单例解决反射攻击demo 2.4 枚举类单例解决反射攻击原理 3 jad的使用 ...
- JAVA培训—线程同步--卖票问题
线程同步方法: (1).同步代码块,格式: synchronized (同步对象){ //同步代码 } (2).同步方法,格式: 在方法前加synchronized修饰 问题: 多个人同时买票. 1. ...
- Js为Dom元素绑定事件须知
为异步加载的Dom 元素绑定事件必须在加载完成之后绑定: $('body').load('LearnClickBinding.ashx');$('a').click(function () { ale ...
- RabbitMq学习笔记——RabbitMQ C的使用
1.需要用到的参数: 主机名:hostname.端口号:port.交换器:exchange.路由key:routingkey .绑定路由:bindingkey.用户名:user.密码:psw,默认用户 ...
- Time Series_1_BRKA Case
Berkshire Hathaway (The most expensive stock ever in the world) 1.1 Download data require(quantmod) ...
- IOS 常用View属性设置
设置按钮属性 1.设置按钮背景颜色 backgroundColor @property (weak, nonatomic) IBOutlet UIButton *deleteButton; self. ...
- 使用Zabbix监控Nginx服务实战案例
使用Zabbix监控Nginx服务实战案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编译安装nginx步骤详解并开启状态页 博主推荐阅读: https://www.cn ...