python爬虫之字体反爬
一、什么是字体反爬?
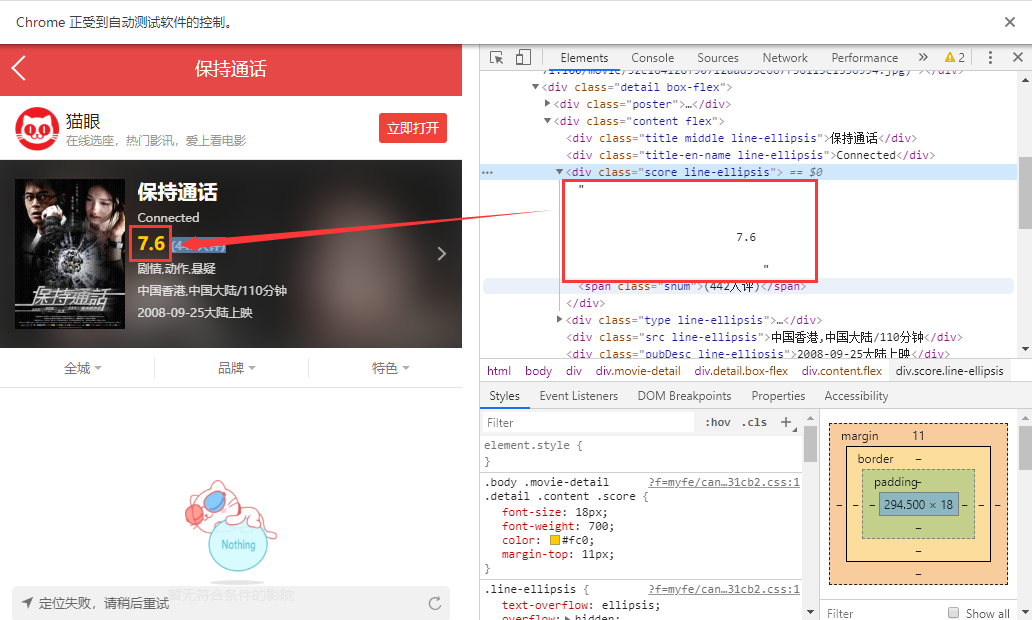
字体反爬就是将关键性数据对应于其他Unicode编码,浏览器使用该页面自带的字体文件加载关键性数据,正常显示,而当我们将数据进行复制粘贴、爬取操作时,使用的还是标准的Unicode字符映射,解析后就是干扰性数据,以猫眼电影为例:
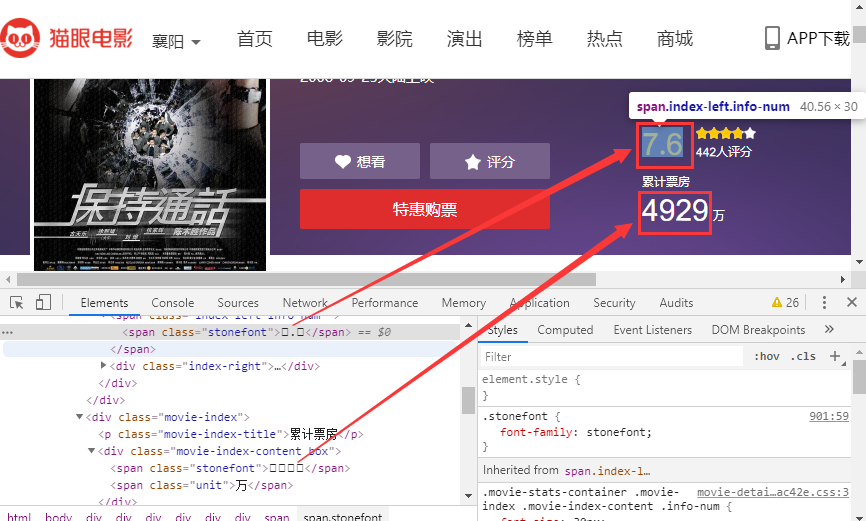
上图表明,浏览器正常渲染的数据在调试界面显示为错误的数据,即使我们复制粘贴也是这样(猜测复制粘贴的是Unicode编码)显示,这样就起到了反爬的效果。
二、解决方案
1、找到对应的字体文件

点击箭头指向的css文件
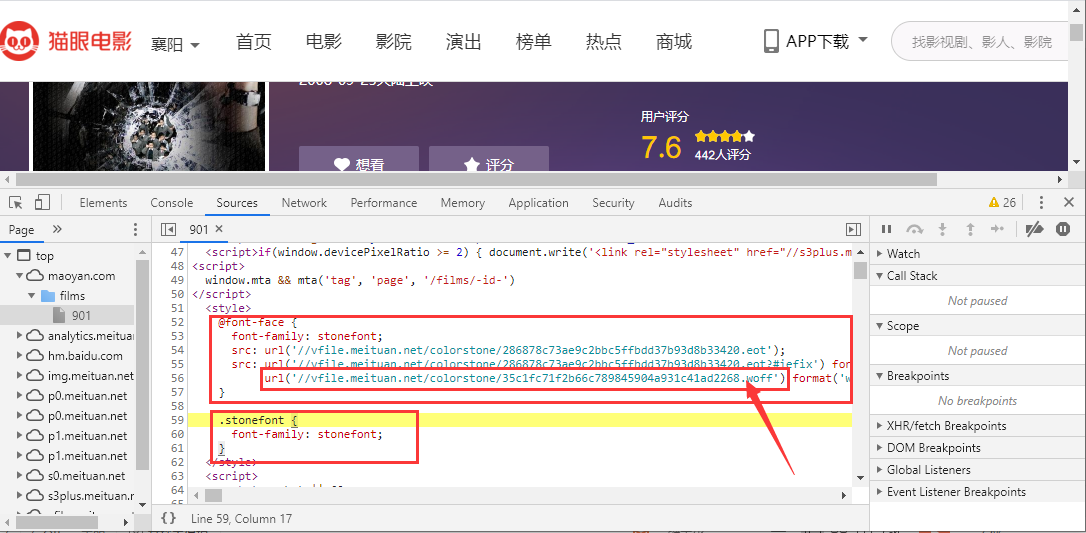
箭头指向的链接就是我们要寻找的字体文件,我们必须把这个字体文件下载下来进行分析,找到对应关系

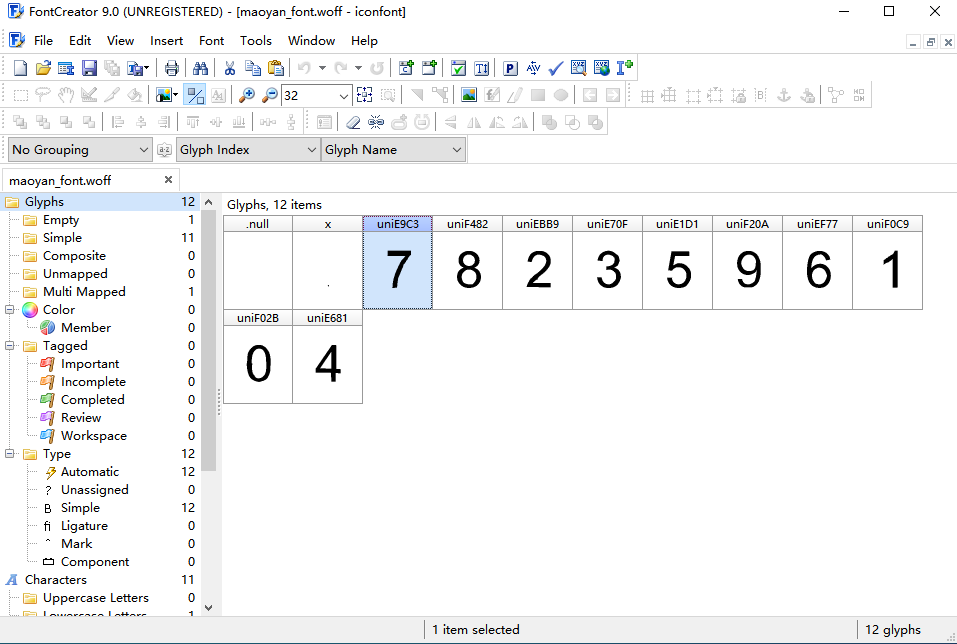

如果字体文件是固定的,我们可以手动分析,然后创建一个映射表就解决了,但是字体文件如果每请求一次就会变化,这种解决方式就不行了。
我们刷新一下链接,再下载一个字体文件对比一下,看是否变化了

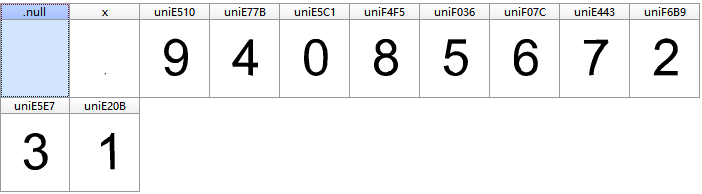
对比后,不难发现,字体文件完全不同了。
2、绕过字体反爬
目前为止,我爬过的数据从来源可以分为PC端数据、移动端Web数据和APP数据,既然PC端有字体反爬,我们可以从移动端尝试一下。
先从简单的移动端Web数据入手,可以先使用selenium,加一个手机浏览器的User-Agent,就可以在PC端浏览器显示与手机浏览器相同的效果,下图表示在移动端Web数据是没有使用字体反爬措施得。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
import time options = webdriver.ChromeOptions() options.add_argument('User-Agent="Mozilla/5.0 (Linux; U; android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1"') chrome = webdriver.Chrome(r"D:\chromedriver_win32\chromedriver.exe", options=options) chrome.get("https://m.maoyan.com")
当我们分析完成后,我们就可以使用requests+lxml来编写爬虫了。
移动端APP数据也就是常说的手机APP爬虫,参照:https://www.cnblogs.com/loveprogramme/p/12209172.html
python爬虫之字体反爬的更多相关文章
- Python爬虫入门教程 64-100 反爬教科书级别的网站-汽车之家,字体反爬之二
说说这个网站 汽车之家,反爬神一般的存在,字体反爬的鼻祖网站,这个网站的开发团队,一定擅长前端吧,2019年4月19日开始写这篇博客,不保证这个代码可以存活到月底,希望后来爬虫coder,继续和汽车之 ...
- Python爬虫入门教程 63-100 Python字体反爬之一,没办法,这个必须写,反爬第3篇
背景交代 在反爬圈子的一个大类,涉及的网站其实蛮多的,目前比较常被爬虫coder欺负的网站,猫眼影视,汽车之家,大众点评,58同城,天眼查......还是蛮多的,技术高手千千万,总有五花八门的反爬技术 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫-字体反爬-猫眼国内票房榜
偶然间知道到了字体反爬这个东西, 所以决定了解一下. 目标: https://maoyan.com/board/1 问题: 类似下图中的票房数字无法获取, 直接复制粘贴的话会显示 □ 等无法识别的字 ...
- python解析字体反爬
爬取一些网站的信息时,偶尔会碰到这样一种情况:网页浏览显示是正常的,用python爬取下来是乱码,F12用开发者模式查看网页源代码也是乱码.这种一般是网站设置了字体反爬 一.58同城 用谷歌浏览器打开 ...
- python爬取实习僧招聘信息字体反爬
参考博客:http://www.cnblogs.com/eastonliu/p/9925652.html 实习僧招聘的网站采用了字体反爬,在页面上显示正常,查看源码关键信息乱码,如下图所示: 查看网页 ...
- k 近邻算法解决字体反爬手段|效果非常好
字体反爬,是一种利用 CSS 特性和浏览器渲染规则实现的反爬虫手段.其高明之处在于,就算借助(Selenium 套件.Puppeteer 和 Splash)等渲染工具也无法拿到真实的文字内容. 这种反 ...
- 网络字体反爬之pyspider爬取起点中文小说
前几天跟同事聊到最近在看什么小说,想起之前看过一篇文章说的是网络十大水文,就想把起点上的小说信息爬一下,搞点可视化数据看看.这段时间正在看爬虫框架-pyspider,觉得这种网站用框架还是很方便的,所 ...
- 58 字体反爬攻略 python3
1.下载安装包 pip install fontTools 2.下载查看工具FontCreator 百度后一路傻瓜式安装即可 3.反爬虫机制 网页上看见的 后台源代码里面的 从上面可以看出,生这个字变 ...
随机推荐
- codeforce 1189C Candies! ----前缀和
题目大意:给你一个数组每个数不大于9,然后给你m个区间,每个区间的长度都是2的k次方(k=0 1 2.....) 有一种操作是把奇数位和偶数位相加 用和来代替之前的两个数,如果和大于等于10就要膜 ...
- AtCoder Grand Contest 033
为什么ABC那么多?建议Atcoder多出些ARC/AGC,好不容易才轮到AGC…… A 签到.就是以黑点为源点做多元最短路,由于边长是1直接bfs就好了,求最长路径. #include<bit ...
- C实现日志等级控制
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <stdarg.h&g ...
- 使用selenium模拟浏览器抓取淘宝信息
通过Selenium模拟浏览器抓取淘宝商品美食信息,并存储到MongoDB数据库中. from selenium import webdriver from selenium.common.excep ...
- 字典 -> model
1.使用KVC init(dict : [String : Any]) { super.init() setValuesForKeys(dict) } override func setValue(_ ...
- javaScript 面向对象 触发夫级构造函数
class Person{ constructor(name,age){ //直接写属性 this.name=name; this.age=age; console.log('a'); } showN ...
- Linux_列出文件和文件属性
ls +文件名:列出该文件 ls +目录名:列出该目录下的文件 ls 什么也不加:列出当前工作目录下的文件 ls -a 列出包括隐藏文件,即所有文件名 ls -l 列出文件名+详细信息 ls -al ...
- mysql关键字汇总
ADD ALL ALTER ANALYZE AND AS ASC ASENSITIVE BEFORE BETWEEN BIGINT BINARY BLOB BOTH BY CALL CASCADE C ...
- day29-struct模块解决黏包问题
#struct模块可以把一个数据类型,例如数字int,转化成固定长度(4个字节)的bytes.int转为4个bytes. #在大量传输数据之前先告诉接收端即将接收数据的大小,方可解决黏包问题: #利用 ...
- day20-双下new方法,单例模式
# 1. __new__:构造方法,它创造对象,程序员口头语:new一个对象.先执行__new__方法再执行___init__方法. class Goods: def __init__(self):# ...